
放假前搞大事!DeepSeek 开源 V3.2-Exp,带自主 DSA 稀疏注意力,降 API 价还可本地部署,开发者速冲!
DeepSeek-V3.2-Exp 集成的,是该模型的核心技术创新,其首次实现了细粒度稀疏注意力机制。作为提升大模型处理超长上下文窗口效率的关键技术之一,该机制专注于优化长文本场景下的模型性能。
1. 【前言】
你说说,怎么一放假Deepseek就要搞大事!!!
就在刚刚,DeepSeek-V3.2-Exp 终于开源啦!

该模型基于此前的 DeepSeek-V3.1-Terminus 升级而来,核心亮点是引入自主研发的 DeepSeek Sparse Attention(DSA)稀疏注意力机制。作为下一代架构探索的关键中间步骤,这一首次实现的细粒度稀疏注意力机制,旨在大幅优化长文本处理的训练与推理效率。
下面给大家讲一讲这个新发布的DeepSeek-V3.2-Exp!
2. 【论文基本信息】

论文标题:DeepSeek-V3.2-Exp: Boosting Long-Context Efficiency
with DeepSeek Sparse Attention
作者:DeepSeek-AI
论文链接:https://github.com/deepseek-ai/DeepSeek-V3.2-Exp/blob/main/DeepSeek_V3_2.pdf
项目链接:https://huggingface.co/deepseek-ai/DeepSeek-V3.2-Exp
3.【细粒度稀疏注意力机制】
3.1 机制核心定义
DeepSeek-V3.2-Exp 集成的 DeepSeek Sparse Attention(DSA),是该模型的核心技术创新,其首次实现了细粒度稀疏注意力机制。作为提升大模型处理超长上下文窗口效率的关键技术之一,该机制专注于优化长文本场景下的模型性能。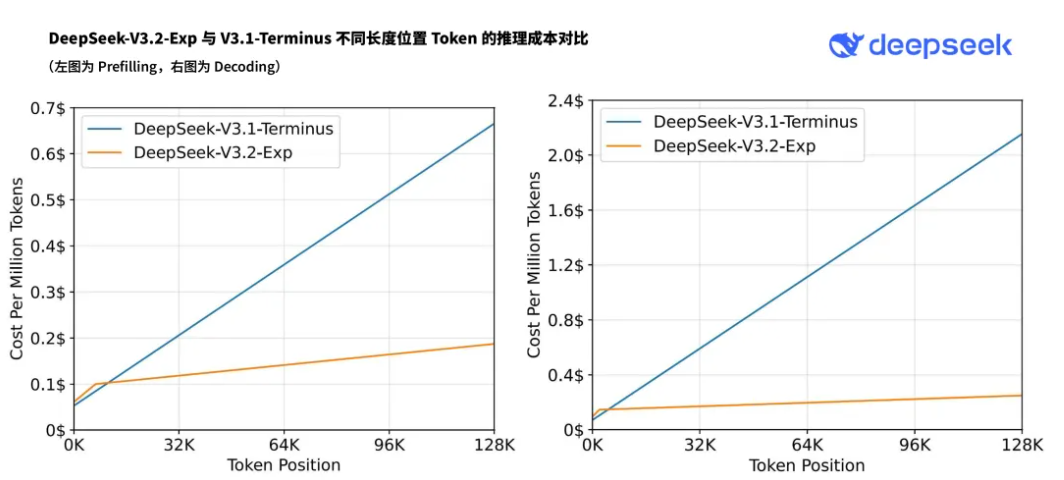
3.2 核心技术优势
DSA 的核心优势在于“效率提升”与“效果稳定”的平衡。在几乎不影响模型输出效果的前提下,它能显著提升长文本处理的训练效率与推理效率,解决了传统大模型在超长上下文场景中效率低下的关键痛点。
3.3 关联模型定位
DSA 是 DeepSeek-V3.2-Exp 相对于前代模型 DeepSeek-V3.1-Terminus 的核心升级点。该新机制的引入,也让 DeepSeek-V3.2-Exp 成为 DeepSeek 下一代架构探索过程中的关键中间步骤。
3.4 性能验证逻辑
为严谨评估 DSA 对模型的影响,DeepSeek 将 DeepSeek-V3.2-Exp 的训练配置与 V3.1-Terminus 进行了严格对齐。通过公开评测集数据验证,两者综合性能基本持平,直接证明了 DSA 在提升效率的同时,能有效维持模型原有输出效果。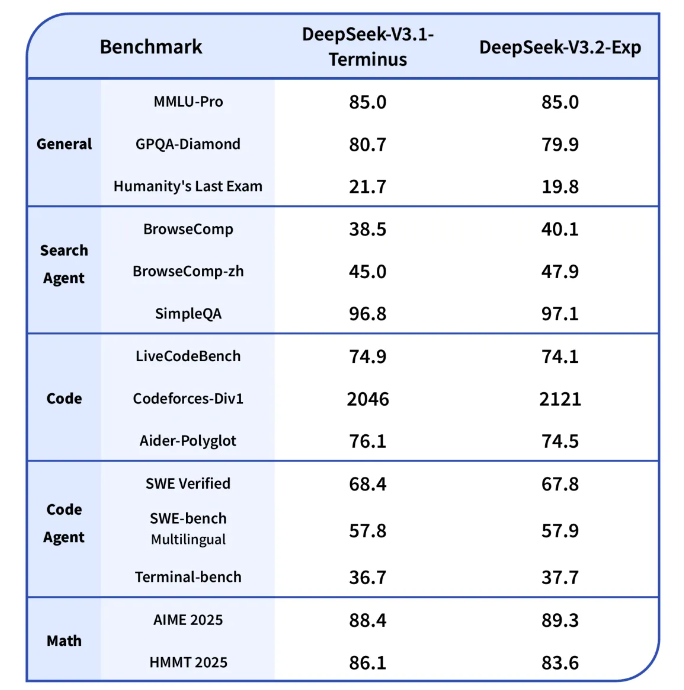
4.【架构】
4.1 架构核心变更
DeepSeek-V3.2-Exp 相较于前代模型 DeepSeek-V3.1-Terminus(DeepSeek-V3.1 系列的最终版本),唯一的架构修改是通过持续训练引入了 DeepSeek Sparse Attention(DSA,DeepSeek 稀疏注意力机制),未对模型其他基础架构模块进行调整。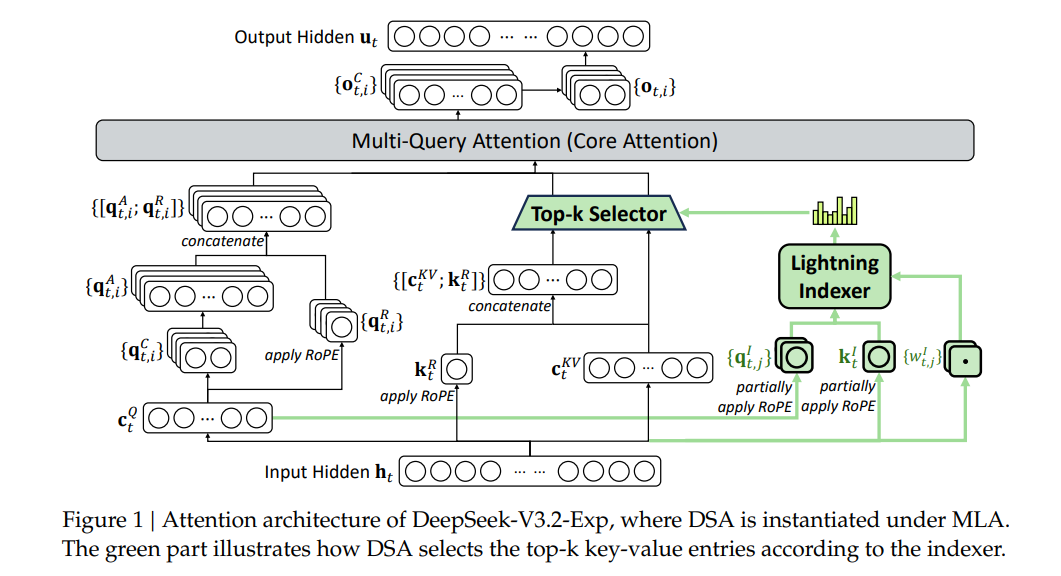
4.2 DSA 原型构成
DSA 原型主要包含两个核心组件,分别负责索引计算与token筛选,共同实现细粒度稀疏注意力功能:
-
组件1:Lightning Indexer(闪电索引器)
- 功能定位:计算查询token与前文token之间的索引分数,为后续token选择提供依据,核心目标是高效筛选关键token。
- 计算逻辑:针对查询token hth_{t}ht 与前文token hs∈Rdh_{s} \in \mathbb{R}^{d}hs∈Rd,通过以下公式计算索引分数 It,sI_{t, s}It,s:
It,s=∑j=1HIwt,jI⋅ReLU(qt,jI⋅ksI)I_{t, s}=\sum_{j=1}^{H^{I}} w_{t, j}^{I} \cdot ReLU\left(q_{t, j}^{I} \cdot k_{s}^{I}\right)It,s=∑j=1HIwt,jI⋅ReLU(qt,jI⋅ksI)
其中,HIH^{I}HI 代表索引器头数;wt,jI∈Rw_{t, j}^{I} \in \mathbb{R}wt,jI∈R 由查询token hth_{t}ht 推导得出;ksI∈RdIk_{s}^{I} \in \mathbb{R}^{d^{I}}ksI∈RdI 由前文token hsh_{s}hs 推导得出。 - 效率优化:选择 ReLU 作为激活函数以提升吞吐量;同时,索引器头数较少且支持以 FP8 精度实现,因此具备显著的计算效率优势。
-
组件2:Fine-Grained Token Selection Mechanism(细粒度token选择机制)
- 筛选逻辑:基于闪电索引器为每个查询token hth_{t}ht 计算的索引分数,仅筛选出索引分数排名前 kkk 的token对应的键值对(key-value entries)。
- 注意力计算:查询token hth_{t}ht 仅与筛选出的稀疏键值对 {cs}\{c_{s}\}{cs} 进行注意力计算,得到注意力输出 utu_{t}ut,公式如下:
ut=Attn(ht,{cs∣It,s∈Top−k(It,:)})u_{t}=Attn\left(h_{t},\left\{c_{s} | I_{t, s} \in Top-k\left(I_{t,:}\right)\right\}\right)ut=Attn(ht,{cs∣It,s∈Top−k(It,:)})
4.3 DSA 在 MLA 架构下的实例化
为实现从 DeepSeek-V3.1-Terminus 的平滑持续训练,DSA 基于 MLA(混合注意力架构,参考 DeepSeek-AI, 2024)进行实例化,具体设计如下:
- 核级实现逻辑:从计算效率角度出发,每个键值对需在多个查询之间共享(参考 Yuan et al., 2025),因此 DSA 基于 MLA 的 MQA(Multi-Query Attention,多查询注意力)模式(参考 Shazeer, 2019)实现——即 MLA 中的每个潜在向量(键值对)会在查询token的所有查询头之间共享。
- 可视化:基于 MLA 的 DSA 架构细节可参考论文中的 Figure 1(Attention architecture of DeepSeek-V3.2-Exp)
5.【模型训练】
5.1 训练整体框架
以上下文长度128K的DeepSeek-V3.1-Terminus为基础 checkpoint,采用“持续预训练+后续训练”两阶段流程,全程对齐前者128K长上下文扩展数据分布。
5.2 持续预训练(分两阶段适配DSA)
5.2.1 密集预热阶段
- 任务:初始化闪电索引器,保持密集注意力,冻结其他参数;
- 逻辑:汇总注意力头分数并L1归一化得目标分布pt,:∈Rtp_{t,:} \in \mathbb{R}^{t}pt,:∈Rt,以KL散度损失训练索引器
(公式:LI=∑tDKL(pt,:∥Softmax(It,:))\mathcal{L}^{I}=\sum_{t} \mathbb{D}_{KL}\left(p_{t,:} \| Softmax\left(I_{t,:}\right)\right)LI=∑tDKL(pt,:∥Softmax(It,:))); - 参数:学习率10−510^{-5}10−5,训练1000步(每步16个128K token序列),总训练量2.1B token。
5.2.2 稀疏训练阶段
- 任务:引入细粒度token选择,优化所有参数适配DSA;
- 逻辑:仅基于筛选token集St={s∣It,s∈Top−k(It,:)}S_{t}=\{s | I_{t, s} \in Top-k (I_{t,:})\}St={s∣It,s∈Top−k(It,:)}对齐分布(损失公式:LI=∑tDKL(pt,St∥Softmax(It,St))\mathcal{L}^{I}=\sum_{t} \mathbb{D}_{KL}\left(p_{t, S_{t}} \| Softmax\left(I_{t, S_{t}}\right)\right)LI=∑tDKL(pt,St∥Softmax(It,St))),索引器与计算图分离单独优化;
- 参数:学习率7.3×10−67.3 ×10^{-6}7.3×10−6,每查询token选2048个键值token,训练15000步(每步480个128K token序列),总训练量943.7B token。
5.3 后续训练
5.3.1 核心原则
沿用稀疏注意力模式,保持与DeepSeek-V3.1-Terminus一致的训练流程、算法及数据,以评估DSA影响。
5.3.2 关键模块
- 专家蒸馏:针对写作、通用问答及5个特定领域,微调专家模型并经大规模RL训练,生成两类训练数据,蒸馏后模型性能接近专家模型(后续RL可消除差距);
- 混合RL训练:用GRPO算法,将推理、智能体、人类对齐训练合并为单RL阶段,平衡多领域性能并避免灾难性遗忘,按任务类型设计奖励机制。
6.【模型评估】
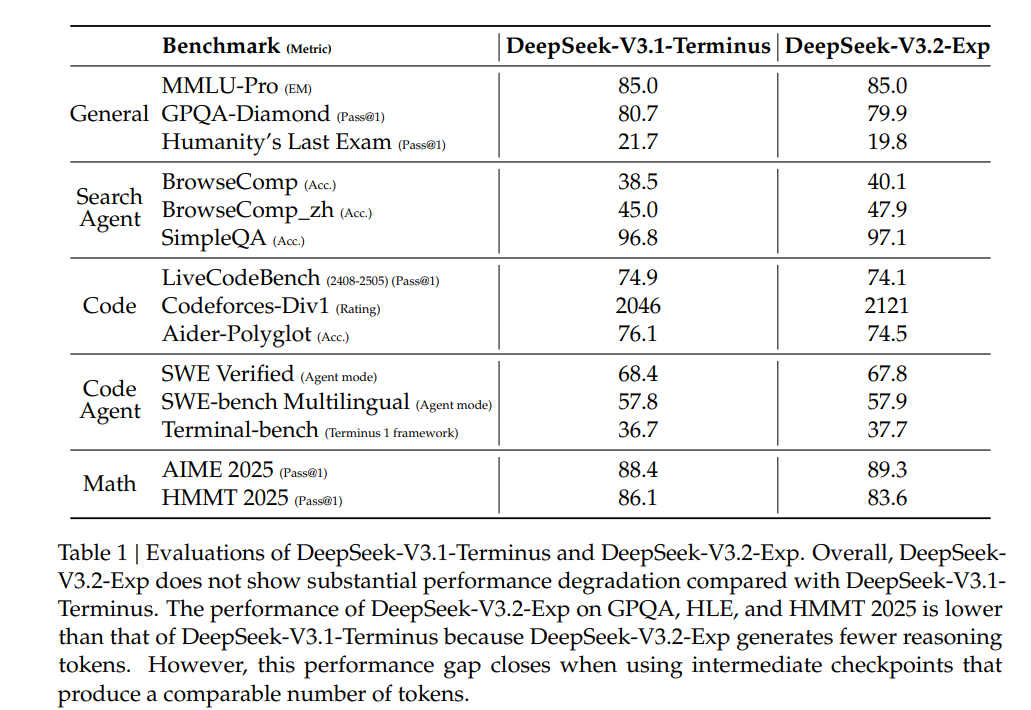
6.1 模型能力评估
- 方式:在通用、搜索智能体、代码、数学等多领域基准测试集对比DeepSeek-V3.2-Exp与V3.1-Terminus,同时对比两者RL训练曲线。
- 结论:V3.2-Exp长序列效率显著提升,短/长上下文性能无大幅下降;RL训练曲线对齐,印证DSA稳定性;部分任务性能略低因推理token少,中间checkpoint可消除差距。
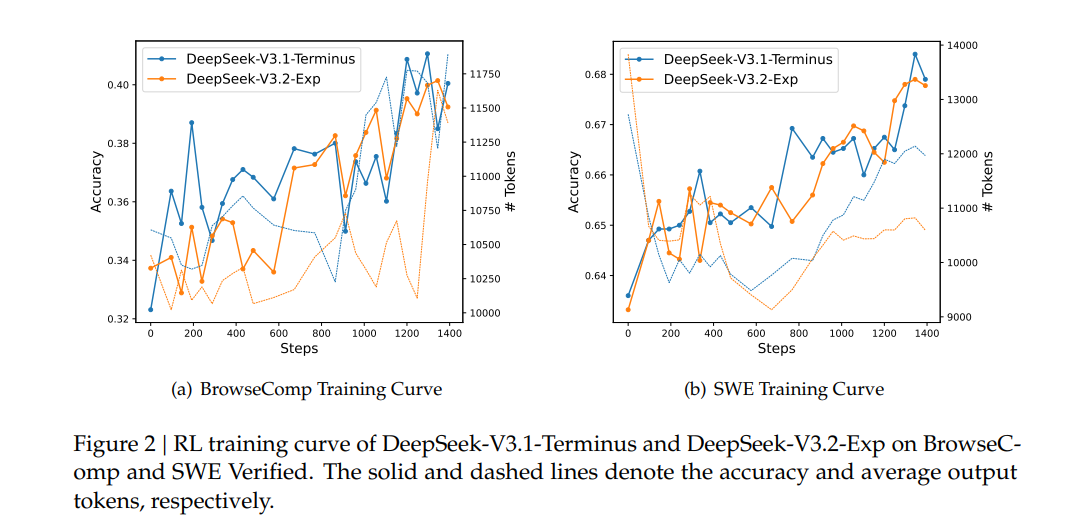
6.2 推理成本评估
- 复杂度:DSA将主模型核心注意力复杂度从O(L2)O(L^2)O(L2)降至O(Lk)O(Lk)O(Lk)(k≪Lk\ll Lk≪L),闪电索引器计算量远低于V3.1-Terminus的MLA,长上下文端到端速度提升。
- 实测:基于H800 GPU(时租2美元),展示预填充/解码阶段token成本随位置变化;短序列预填充用掩码MHA模拟DSA提效。
6.3 后续验证计划
内部评估效果良好,但将开展大规模真实场景测试,排查稀疏注意力架构潜在局限性。
7.【本地部署指南】
7.1 HuggingFace 部署方式
7.1.1 权重格式转换
- 进入推理代码所在文件夹,执行命令:
cd inference - 设置专家数量环境变量(固定值为256),执行命令:
export EXPERTS=256 - 运行转换脚本,将 HuggingFace 格式的模型权重转换为推理演示所需格式(需替换
${HF_CKPT_PATH}为 HuggingFace 模型权重路径、${SAVE_PATH}为转换后权重的保存路径、${MP}为与可用 GPU 数量匹配的值),执行命令:python convert.py --hf-ckpt-path ${HF_CKPT_PATH} --save-path ${SAVE_PATH} --n-experts ${EXPERTS} --model-parallel ${MP}
7.1.2 启动交互式聊天界面
- 设置配置文件环境变量(使用 671B 版本模型的配置文件),执行命令:
export CONFIG=config_671B_v3.2.json - 启动交互式聊天界面(
${MP}需与前文设置的 GPU 数量保持一致),执行命令:
启动成功后,即可通过界面交互探索模型功能。torchrun --nproc-per-node ${MP} generate.py --ckpt-path ${SAVE_PATH} --config ${CONFIG} --interactive
7.2 SGLang 部署方式
7.2.1 Docker 镜像安装
根据本地硬件型号,拉取对应版本的 Docker 镜像,执行对应命令:
- 若使用 H200 显卡:
docker pull lmsysorg/sglang:dsv32 - 若使用 MI350 显卡:
docker pull lmsysorg/sglang:dsv32-rocm - 若使用 NPU(A2 芯片):
docker pull lmsysorg/sglang:dsv32-a2 - 若使用 NPU(A3 芯片):
docker pull lmsysorg/sglang:dsv32-a3
7.2.2 启动服务
执行如下命令启动 SGLang 服务,用于模型部署:
python -m sglang.launch_server --model deepseek-ai/DeepSeek-V3.2-Exp --tp 8 --dp 8 --page-size 64
7.3 vLLM 部署方式
vLLM 对 DeepSeek-V3.2-Exp 提供“Day-0 支持”(模型发布即兼容),具体部署步骤需参考 vLLM 官方提供的最新指南(recipes)。由于官方指南会实时更新操作细节,建议通过 vLLM 官方渠道获取对应部署代码及步骤。
顺带提一嘴:
得益于新模型服务成本的大幅降低,官方 API 价格也相应下调,新价格即刻生效!!

大家快来尝试一下!!
更多推荐
 7
7 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)