- @Master_oid
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
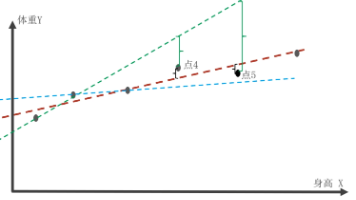
这个简单模型可以用于健康评估、服装尺码推荐等场景,不过需要注意,如果数据呈现出非线性特征(如儿童期与成年期生长规律不同),线性回归的效果就会受限,需要考虑更复杂的模型。算法计算出最优的w和b。从图中可以看出,红色的线更好地拟合了所有的点,也就是误差最小,误差之和最小。这时,只要求得一对w与b的值,使得损失函数最小,便可以得到最终的结果,从而根据已知的身高预测其对应的大致体重。上面说明的是一元线性回
在训练模型是也是先加载手写数字数据集,然后对数据进行预处理(归一化),然后参照y中各个数据的分布同等比例分割数据集,避免分割数据集后数据分布失衡(如分割后训练集中可能全是0、1、3、7),接着就是模型训练与模型评估,最后我们将模型经行保存。在实现手写数字识别时,先看看数据中的灰度图像。查看所有标签的分布情况:Counter({1: 4684, 7: 4401, 3: 4351, 9: 4188,
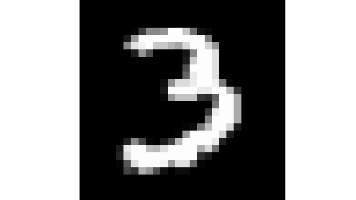
其中estimator是估计器对象,param_dict是估计器参数,cv是几折交叉验证,在结果中bestscore_是指在交叉验证中验证的最好的结果,bestestimator是指最好的参数模型,cvresult是指每次交叉验证后的验证集准确率结果和训练集准确结果。通过这四次训练集+验证集的评估,得到的四次结果取平均值作为模型的得分。通过前面我们知道了交叉验证解决模型的数据输入问题(数据集划分)

本文介绍了机器学习中常用的四种距离度量方法:欧氏距离、曼哈顿距离、切比雪夫距离以及闵可夫斯基距离,并解释了它们之间的数学关系与适用场景。此外,文章详细阐述了特征处理中的两种无量纲化技术——归一化与标准化,分析了各自的原理、计算公式、优缺点及适用条件,并通过代码展示了基于scikit-learn的具体实现。这些预处理方法对提升模型性能与稳定性具有重要意义。
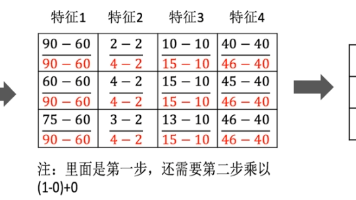
就如利用K近邻算法预测电影类型,如下表,其中1到9的电影名称以及三个不同类别的镜头为x_train,对应的电影类型为y_train,而第10个的电影名称以及三个不同类别的镜头为x_test,我们要预测的就是其对对应的电影类别y_test。若k值过小,也就是用较小领域中的训练实例进行预测,这时就容易受到异常点的影响,k值的减小就意味着整个模型变得复杂,容易发生过拟合。若k值过大,也就是用较大领域中的
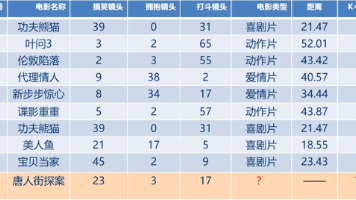
这包括处理缺失值(如填充、插值或删除缺失严重的记录)、识别并处理异常值(基于统计方法或业务规则),以及对数据进行划分,将数据集按比例拆分为训练集、验证集和测试集,保证模型评估的客观性。其中将前面部分的特征就称之为x_train,下面的部分就是用来测试的称之为x_test,训练集特征得到的标签就是y_train,最终希望得到的就是y_test。其实中训练数据我们可以看作是x_train,模型就是在找
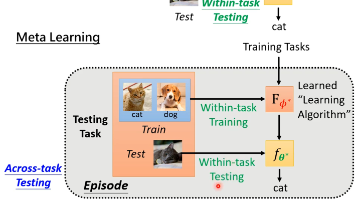
本文介绍了元学习在多个方面的具体应用。首先,通过MAML等方法学习最优的初始化参数,使模型能够快速适应新任务。其次,元学习可用于学习优化器,自动调整更新策略。此外,网络架构搜索(NAS)利用元学习自动设计网络结构。最后,文章还提及了元学习在数据处理、样本重加权等领域的延伸应用,展现了元学习在自动化机器学习中的广泛潜力。
本文介绍了元学习的基本概念与核心思想。元学习旨在让模型学会如何学习,通过在多任务上训练获得快速适应新任务的能力。文章阐述了元学习的三个步骤:定义待学习的算法组件、定义基于任务集的损失函数、优化得到最优学习算法。最后对比了机器学习与元学习在目标、训练资料、损失函数等方面的差异,并指出两者在过拟合等问题上的相似性。元学习为自动发现高效学习算法提供了重要途径。
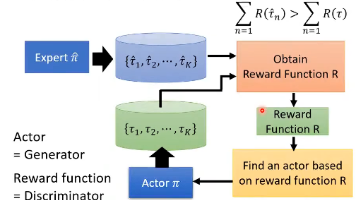
本次学习了深度强化学习中应对稀疏奖励与无明确奖励信号的核心方法。首先详细了解了奖励塑造的基本概念,分析了在稀疏奖励环境下通过引入基于领域知识的额外奖励以引导智能体学习的机制,并特别探讨了基于好奇心的奖励塑造方法。进一步,深入讨论了在完全缺乏奖励信号的情况下如何通过模仿学习与逆强化学习进行策略学习,重点剖析了逆强化学习通过专家示范反推奖励函数、并迭代优化智能体策略的工作原理,同时揭示了其与生成对抗网