




- @MaoziYa
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
科技巨头们正斥资数十亿美元打造全自动的 AI Agent(智能体),期望它们能像人类员工一样,在解决新问题的过程中不断学习、积累经验。然而,一篇最新的学术论文《这篇论文不仅打破了业界对“全自动 AI 生态”的盲目乐观,还首次系统性地剖析了 AI 在持续学习(Continual Learning)过程中那些极其反直觉的失败模式。
科技巨头们正斥资数十亿美元打造全自动的 AI Agent(智能体),期望它们能像人类员工一样,在解决新问题的过程中不断学习、积累经验。然而,一篇最新的学术论文《这篇论文不仅打破了业界对“全自动 AI 生态”的盲目乐观,还首次系统性地剖析了 AI 在持续学习(Continual Learning)过程中那些极其反直觉的失败模式。
Agentic Web、多智能体协同、大语言模型、搜索引擎、信息检索你最近肯定遇到过这种令人抓狂的场景:你把一个新闻链接甩给你的AI助手,让它帮你总结一下深度报道,结果它冷冰冰地回复一句:“抱歉,该网站拒绝访问。这并非你的AI变笨了,而是整个互联网的底层逻辑正在发生剧变。过去几十年,互联网是一个开放的“万维网”(World Wide Web),搜索引擎像上帝一样爬取所有公开网页,为你提供一个中心化
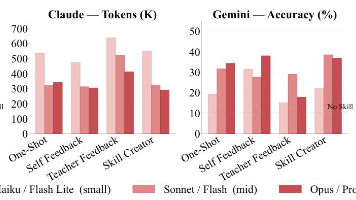
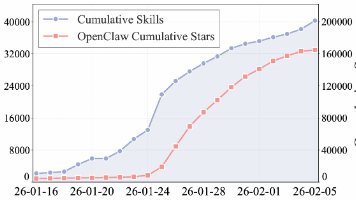
从爆发式增长规律、全维度功能分类到多等级安全审计,这份数据驱动的研究,清晰呈现 Agent Skills 的社区生态和发展现状,既为技术落地研发、搭建平台提供了硬核量化参考,也让入门者能清晰看懂这一领域的真实全貌。
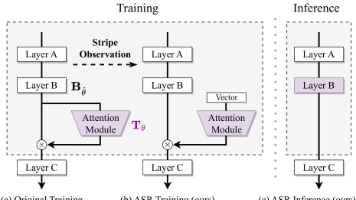
你可能见过这样的线上事故:同一个视觉模型,离线评测分数漂亮,一上手机端或摄像头端就“掉帧”,工程师只好把注意力模块(attention module)一刀切掉。,它们对不同图片给出的权重,竟然会。如果这是真的,那我们在部署端为“动态注意力”付出的算力和延迟,究竟是在买什么?ECCV 这篇论文《把这个冲突推到台前:一边是业界对 attention 的依赖(提升精度、增强表达),一边是它在推理阶段的昂
摘要:315晚会曝光「GEO」概念引发热议,但GEO(生成式引擎优化)本质是AI搜索时代的合理需求。卡内基梅隆大学提出的AutoGEO系统证明,对抗式GEO虽能提升内容可见度,却会损害AI搜索质量。AutoGEO通过分析AI引擎偏好自动提取优化规则,在提升可见度50.99%的同时保持搜索质量,且1.7B小模型版本成本仅为API的0.71%。研究发现不同AI引擎偏好高度一致,但领域差异显著。该研究为

在深入数据之前,我们需要先理解什么是。对于计算机专业的学生来说,你可以这样理解:如果 LLM 是操作系统(OS),那么 Agent Skill 就是应用程序(App)。在没有 Skill 之前,AI 只能生成文本;有了 Skill,AI 就能执行特定的程序逻辑、调用外部工具或 API。元数据 (Metadata):类似于 API 的签名(Signature),定义技能的名称和描述,用于 AI 在海
从爆发式增长规律、全维度功能分类到多等级安全审计,这份数据驱动的研究,清晰呈现 Agent Skills 的社区生态和发展现状,既为技术落地研发、搭建平台提供了硬核量化参考,也让入门者能清晰看懂这一领域的真实全貌。
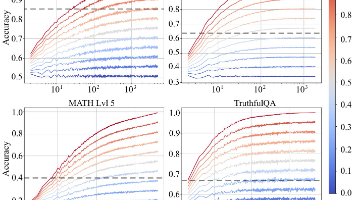
你可能也遇到过:同一个输入,换个 LLM 结果就像开盲盒——有的秒懂,有的胡编。直觉上,“那我就多接几个模型,总能撞上会的那个”似乎很合理。特别是:论文在 Limitations 里指出,;候选太多可能带来部署挑战。这形成了一个很现实的张力:Routing LLMs 被讲成“规模化”的新范式,但可落地的甜点区,反而可能要求你。
在深入数据之前,我们需要先理解什么是。对于计算机专业的学生来说,你可以这样理解:如果 LLM 是操作系统(OS),那么 Agent Skill 就是应用程序(App)。在没有 Skill 之前,AI 只能生成文本;有了 Skill,AI 就能执行特定的程序逻辑、调用外部工具或 API。元数据 (Metadata):类似于 API 的签名(Signature),定义技能的名称和描述,用于 AI 在海