




- @Luu_uu_uu
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
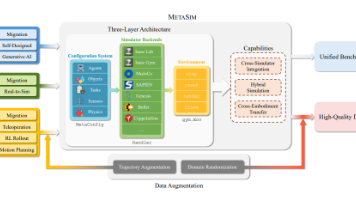
针对机器人学习中的问题,提出一个目标是打造机器人领域的“ImageNet”,支持高效的等,并改善转移。
传统模型直接从图像+语言指令预测动作,擅长语义理解,但对物理动态(如物体碰撞、摩擦、变形)的泛化能力较弱。世界模型则通过学习“未来预测”来弥补这一短板:它模拟环境如何随动作变化,从而支持规划、策略学习和零样本泛化。AC-WM(动作条件世界模型):传统世界模型的代表形式。WAM(世界动作模型):新兴统一框架,将“世界预测”和“动作生成”深度融合,常基于大规模预训练视频扩散模型。两者都源于视频生成技术
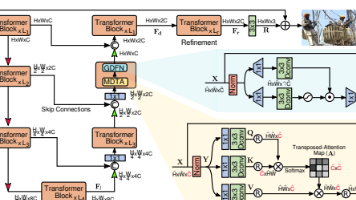
这篇论文提出了一种名为的高效 Transformer 模型,专门用于高分辨率图像恢复任务。核心目标是解决传统 Transformer 在图像恢复中计算复杂度随空间分辨率二次增长的问题,同时保留其捕捉长程像素依赖的优势,最终在多种图像恢复任务中实现 state-of-the-art(SOTA)性能。
本文提出了—— 一款功能通用的 4D 世界模型,可实现 4D 场景重建、新轨迹视频生成,并支持多种下游应用。现有 4D 世界建模方法普遍存在的问题:这类方法要么依赖采集成本高昂、场景受限的多视角 4D 数据,要么需要繁杂的训练预处理流程。与之不同,NeoVerse 以为核心设计思路。具体而言,该模型采用等一系列配套技术。上述设计赋予 NeoVerse 强大的通用性与跨场景泛化能力,同时模型在主流重
逻辑的终点是一个统一的世界模型:一个基础模型,能够渲染照片级真实视图、产生物理上准确的结构,并规划行动序列,根据下游消费者的需求在不同输出模态之间切换。这里不是化学家的状态(固态、液态、气态的区别),而是物理学家和机器人学家的状态:对世界在某一时刻发生的一切的完整描述,包括每个物体、每个位置、每个速度、每个属性。行动是智能体做出的回应。语言模型学习的是文本的统计结构,而世界模型学习的是空间和时间的

启用噪声共享。随着参数 K 增大,同一身份样本的纹路一致性会逐步提升,但图像风格的多样性会随之下降。本文针对不同 K 值开展对照实验,以选取最优配置。此外,该 K 步噪声共享采样属于即插即用模块,可直接迁移应用至其他扩散生成模型中。
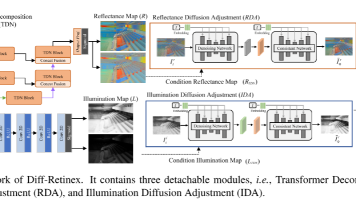
在本文中,我们重新思考了低光照图像增强任务,提出了一种兼具物理可解释性和生成能力的扩散模型,称为Diff-Retinex。我们的目标是整合物理模型与生成网络的优点,并通过生成网络补充甚至推断低光照图像中缺失的信息。因此,Diff-Retinex将低光照图像增强问题转化为Retinex分解和条件图像生成两个部分。在Retinex分解阶段,我们结合Transformer中注意力机制的优势,精心设计了R
这是一个“做—反馈—再做—再改进”的学习过程。
wandb (Weights & Biases) 是机器学习 / 强化学习领域最主流的 实验跟踪、可视化与协作平台,自动记录超参数、损失曲线、准确率、GPU / 内存占用、代码版本等所有训练细节。原项目的batch_size是128,感觉过大的话可以自行调整,在train/lewm.yaml里对batch_size进行修改即可。当然,WandB需要科学上网,如果服务器的条件不允许的话,也可以去tr
假设你没有见过犰狳和穿山甲。现在左边给了你四张图,并告诉你了左边两张是犰狳,右边两张是穿山甲。现在给你一张新的图,你可以仅通过已知的四张图判断,新的图是犰狳还是穿山甲吗?大多数人可能分不清犰狳和穿山甲,但是只要给出四张图片,都能进行正确的分类。既然人只要四张图片就能做出分类,那计算机是否可以呢?这里的。数据集只有四张图片,每个类只有两张图片。这么小的数据集,不足以拿去训练一个完整的神经网络。而少样
