- @LinkSLA
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
企业数据在量级上和安全性都有更高的要求,运维工作进一步细分,不仅需要专业的服务器管理员还需要专业的数据库管理员,但是这些工作还是建立在各自设备及软件的命令操作,工作方式没有发生根本性的变化。用户通过实时自动巡检功能,可在第一时间发现异常,根据容量指标的增长速度,发现潜在异常,提前预防,帮助运维工程师在日常工作中未雨绸缪,避免对业务系统的运行产生影响。过去十年,科技化进程飞速发展,作为保障企业信息安

如果你想返回用户及用户的分数,你需要这样执行:ZRANGE user_scores 0 10 WITHSCORES Agora Games 就是一个很好的例子,用 Ruby 实现的,它的排行榜就是使用 Redis 来存储数据的,你可以在这里看到。紧接着你需要抓一抓自己的脑袋,故作思考片刻,好像接下来的结果是你主动思考出来的,然后回答:我记得 set 指令有非常复杂的参数,这个应该是可以同时把 se
毕竟培训机构大多都是教开发,没多少技术的大多都转测试了,运维技术又杂又冷门(大学基本不教 linux 和服务器相关的),所以从业人数很少(坑也少),普遍水平也都不高(自学学不会,又没多少培训机构教),所以如果你选这条路,然后有个有经验的人带带你,也是可以混得很轻松的~工资涨幅比较慢,三年五年的运维和七年八年的运维工资区别不大,和开发一样,很多工资也用不到多么高端的运维技术,你最多的活就是部署个东西

在竞争激烈的商业环境中,运维指标对企业的重要性不言而喻。这些指标不仅帮助企业监控和优化其IT基础设施的性能,确保服务的连续性和可靠性,而且还提供了关键的洞察,使企业能够识别潜在的问题并迅速响应。通过精确地跟踪系统的稳定性、响应时间、故障率等关键性能指标,企业能够提高客户满意度,降低运营成本,并最终提升市场竞争力。此外,良好的运维管理还能助力企业更好地遵守法规要求,避免数据泄露和其他安全风险,保护企
近年来,面对不断涌现的新兴技术和架构转型的要求,如企业上云+中台+互联网、分布式、容器化、双中心双活,大数据、人工智能的应用。运维对象的数量激增:企业数字化转型导致应用系统数量增加,业务规模扩大带来系统细化和组件增多,微服务架构推广使得运维节点变得更加繁多。这些变化使得运维人员需要管理的服务器、容器等资源数量大幅增加,传统的手工运维方式难以应对规模化管理的需求,导致运维效率低下,管理成本上升。运维
数据上云只是轻松运维的开始,专业,可信,方便,快捷的统一运维监控平台才是云上运维顺利进行的保障。

检查应用端、服务器端、防火墙的MTU值是否一致,更改应用端、服务端的MTU值与防火墙一致,MTU默认值为1500,参考可调至9000(oracle原厂建议oracle服务器是 9000,同时参考了其他银行的MTU值),建议网络工程师可以用ping包的方式 测试出符合当前环境的最佳MTU。ORACLE官方针对这类错误明确:错误堆栈依次为TNS-12170/TNS-12535/TNS-12560/TN
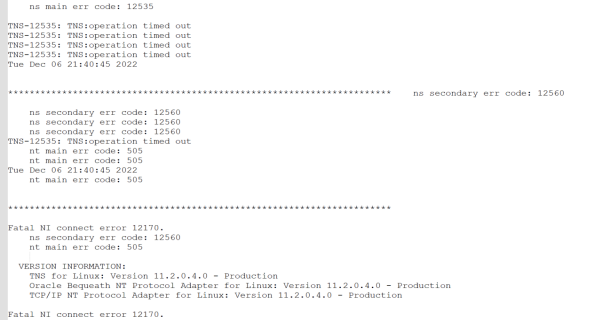
检查应用端、服务器端、防火墙的MTU值是否一致,更改应用端、服务端的MTU值与防火墙一致,MTU默认值为1500,参考可调至9000(oracle原厂建议oracle服务器是 9000,同时参考了其他银行的MTU值),建议网络工程师可以用ping包的方式 测试出符合当前环境的最佳MTU。ORACLE官方针对这类错误明确:错误堆栈依次为TNS-12170/TNS-12535/TNS-12560/TN

您可以将映像托管在 Docker Hub 上,或者使用 Amazon Web Services (AWS) 或 Azure 上的私有存储库。无论您需要什么,您都可以轻松创建自己的独特图像来解决您的问题。Docker Hub 上提供的公共映 供了一个很好的基础,您可以在此基础上进行构建。您可以使用 Kubernetes (K8s) 或 Docker Swarm 部署更复杂的应用程序,以获得更好的弹性
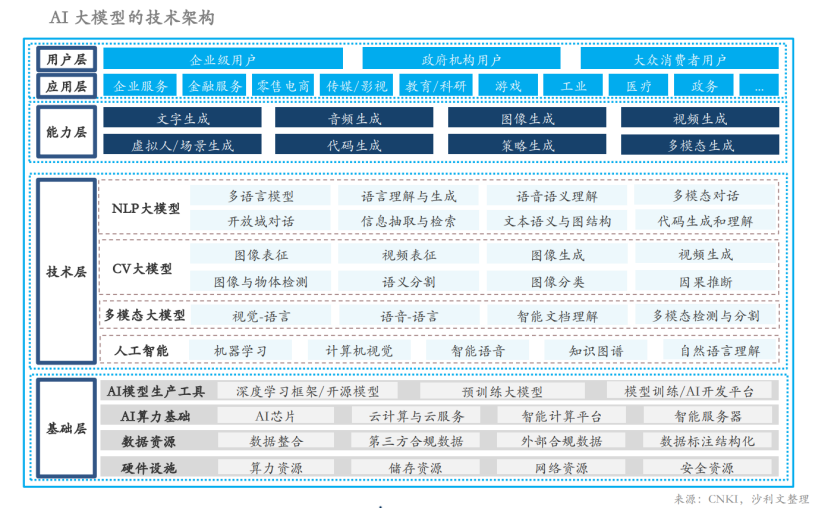
随着客户数量的不断增加,客户对客服中心服务的期望也会不断提高,银行客户服务中心如何交付功能强大的客户服务支持变得尤为重要,需要大规模深度学习和迁移学习在一定的场景下用来提升AI助手水平,并集成客服中心现有的自然语言处理、计算机视觉、智能语音、知识图谱等多个AI核心技术能力,打造银行业客服中心AI大语言模型能力体系。在数据标注方面,大模型已经从原来需要大量标注数据进化到运用海量非标注数据,越来越多数