- @LLMliandanlu
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
架构革新(如Mamba在扩散模型中的应用、统一化基础模型设计)、效率提升(如知识蒸馏、无需训练框架)及垂直领域突破(如自动驾驶、医疗影像、遥感分析)等
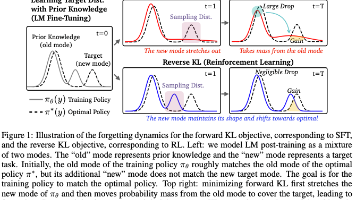
语言模型(Language Model, LM)在进行下游任务的后训练(Post-Training)时,常常面临灾难性遗忘(Catastrophic Forgetting)的问题,即模型在学习新任务的同时丢失了原有的知识能力。本文提出从策略数据(On-Policy Data) 的角度系统分析并缓解遗忘现象。通过在多类任务、多种模型上的实验,论文发现RL因其使用当前策略生成的数据进行训练,相较于SF
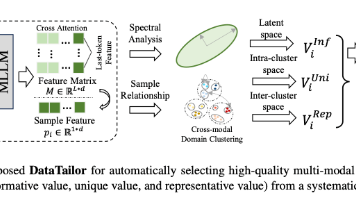
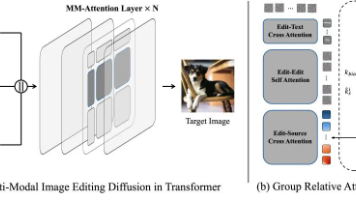
Diffusion Transformer、MM-Attention、可控图像编辑、GRAG、天津大学、快手Kolors、分组相对注意力引导(Group Relative Attention Guidance, GRAG)、多模态注意力(Multi-Modal Attention, MM-Attention)、图像编辑(Image Editing)、视觉语言模型(Vision-Language M
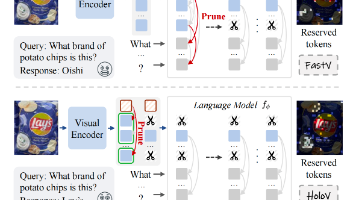
关键词:视觉令牌剪枝、多模态大语言模型、全局上下文保留、注意力机制偏差、HoloV框架、自适应令牌分配、视觉上下文重提取、位置偏差、注意力分散
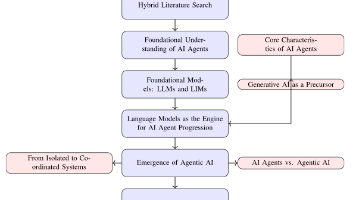
一文看懂AI 智能体与代理性 AI 的核心差异
从架构演进看,Transformer凭借自注意力机制擅长建模跨模态语义关联,扩散模型通过渐进去噪过程生成高保真连续数据。然而,传统融合方案面临根本性挑战——Transformer对离散token的依赖造成视觉细节损失,扩散模型缺乏对复杂语义的逻辑推理能力。CDiT通过因果扩散注意力机制与时变语义注入,在视频生成任务中不仅将时序一致性误差降低47%,更实现了文本-视频的精准语义对齐,为多模态大模型提
OCR 场景下的 LVLM 幻觉与感知不足: 生成式大视觉语言模型(LVLM)在端到端文档解析上虽统一优雅,但容易“看图添字”,即输出图像中不存在的内容;与此同时,通用 LVLM 更偏重推理而非细粒度感知,在文本/表格/公式等 OCR 任务上常不如面向单任务训练的“专家模型”。论文第 1 页摘要与第 1 节、以及表 1(第 2 页)给出了“印章识别”中的典型幻觉例子。

本论文提出了Lumine模型,它基于视觉语言模型构建,能够通过像素输入实时生成键盘鼠标操作,并自适应地进行推理。实验表明,Lumine在《原神》中完成了长达五小时的主线任务,并成功零样本泛化到其他游戏中,展现了强大的通用性。

关键词:大语言模型;幻觉;幻觉成因;幻觉检测;幻觉缓解;幻觉基准;幻觉指标
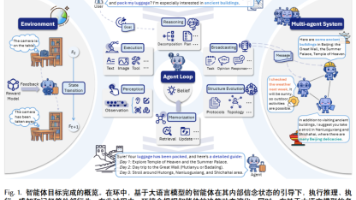
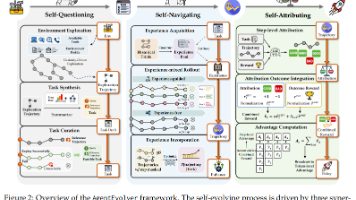
自进化代理(Self-Evolving Agent)、自我提问(Self-Questioning)、自我导航(Self-Navigating)、自我归因(Self-Attributing)、强化学习(Reinforcement Learning)、任务生成(Task Generation)