




- @K48932
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
我们生活在一个被AI浪潮席卷的时代。每一天,我们都能看到、听到关于大型语言模型(LLM)的突破性新闻。它们能写诗、能编程、能进行逻辑缜密的对话,其强大的能力似乎预示着一个全新的应用纪元即将到来。对于我们这些身处技术前沿的开发者、创业者和充满热情的爱好者来说,这无疑是一个激动人心的信号。我们脑中充满了各种奇思妙想:一个能自动分析财报的智能助手、一个能与用户进行深度情感交流的虚拟伙伴、一个能辅助我们进
长连接技术能够保持服务器与企业微信网关之间的持续会话,避免了频繁握手带来的网络开销,确保了在复杂群聊环境中,AI助手能够秒级响应成员的指令。当操作者输入指令,要求总结特定群组在特定时间段内的工作进展时,AI 会执行多步操作:首先检索相关群聊消息,接着利用其 235B 的大参数量进行语义分类,区分出“待办事项”、“已完成工作”以及“潜在风险”。这不仅是工具的升级,更是办公范式的重塑。针对非管理员身份
在云原生技术日益普及的当下,Nginx、Docker、Kubernetes 等基础设施的配置文件编写已成为运维工程师与后端开发者的日常痛点。这些配置不仅语法繁杂,且对安全性、性能参数有着极高的要求。手动编写不仅效率低下,且极易引入人为错误。随着大语言模型(LLM)能力的爆发,利用 AI 辅助生成高质量配置代码已成为必然趋势。本文将详细阐述如何利用 Rust 语言的高性能与安全性,结合 GLM-5
为了展示 OPS-CV 中算子是如何被形式化定义的,以下代码展示了一个典型的图像处理算子(如Resize)在底层 C++ 接口中的原型声明与校验逻辑。这部分代码属于算子开发层,用于指导系统如何构建图和分配内存。// 定义 Resize 算子的原型// 继承自 Operator 类,注册输入输出端口和属性.INPUT(x, TensorType({DT_FLOAT, DT_FLOAT16, DT_U
在分布式微服务架构日益复杂的今天,系统日志作为观测系统健康状态的核心数据源,其数据量呈指数级增长。传统的基于规则匹配(Rule-based)或简单的关键词搜索的日志分析手段,在面对非结构化数据和复杂级联故障时显得力不从心。本文详细阐述了一种融合 Rust 语言的高性能内存安全特性与 DeepSeek-V3.2 大语言模型推理能力的创新解决方案。通过构建一个 CLI 工具,实现对海量日志的毫秒级解析
随着大语言模型(LLM)技术的飞速迭代,应用开发范式正经历从"单一脚本调用"向"复杂系统工程"的转变。在构建企业级 LLM 应用时,开发者面临的核心挑战在于如何平衡系统的稳定性与灵活性:既要适配快速更迭的模型接口(如 DeepSeek V3.2),又要满足多样化的业务场景(如代码审计、日志分析、运维自动化)。本文将深入剖析如何利用 Rust 语言强大的类型系统与所有权机制,结合 DeepSeek
随着大语言模型(LLM)能力的飞速提升,将 AI 能力集成到终端命令行工具(CLI)中已成为提升开发效率的重要手段。Rust 语言凭借其内存安全、零成本抽象以及极其高效的异步运行时,成为构建此类高性能网络 IO 密集型应用的首选。本文将深度剖析如何使用 Rust 语言,结合智谱 AI 的 GLM-5 模型,从零构建一个支持流式输出、多语言切换及文件批处理的 AI 翻译引擎。本文将涵盖环境配置、依赖
在现代软件工程中,API 接口的开发与前端联调往往存在时间差。为了解耦前后端开发进度,Mock 数据(模拟数据)的生成显得尤为关键。传统的 Mock 数据生成依赖于静态 JSON 文件或简单的规则引擎,难以覆盖复杂的业务逻辑与语义关联。随着大语言模型(LLM)的兴起,利用 AI 根据 Schema 定义动态生成高保真的模拟数据成为可能。
大模型推理中的显存浪费问题,被一种借鉴操作系统思路的技术有效缓解了。在生成式AI领域,大语言模型的参数量和上下文长度持续增长。开发者将模型部署到生产环境时,常常遇到两个现实问题:推理成本高,以及显存溢出(OOM)。GPU 数量增加,吞吐量却未必成比例提升。vLLM 是当前比较流行的大模型推理加速框架之一。很多开发者切换到vLLM后,发现系统吞吐量有明显提升。据官方基准测试,相比 HuggingFa
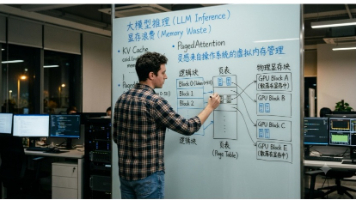
大模型推理中的显存浪费问题,被一种借鉴操作系统思路的技术有效缓解了。在生成式AI领域,大语言模型的参数量和上下文长度持续增长。开发者将模型部署到生产环境时,常常遇到两个现实问题:推理成本高,以及显存溢出(OOM)。GPU 数量增加,吞吐量却未必成比例提升。vLLM 是当前比较流行的大模型推理加速框架之一。很多开发者切换到vLLM后,发现系统吞吐量有明显提升。据官方基准测试,相比 HuggingFa