- @Jason160918
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
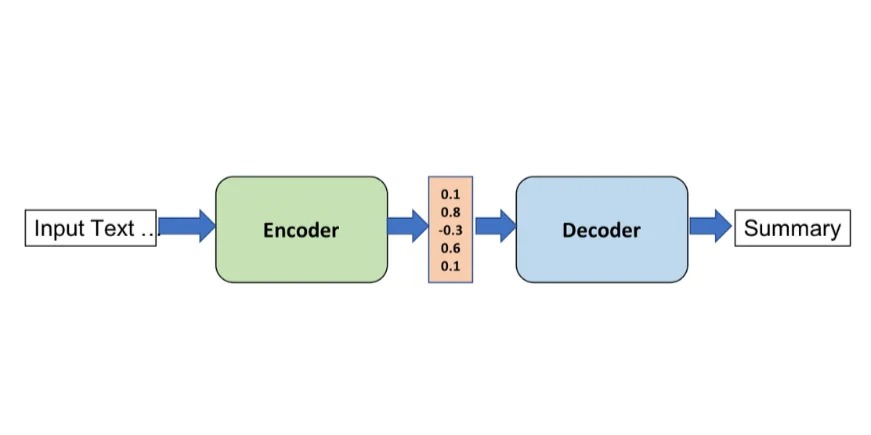
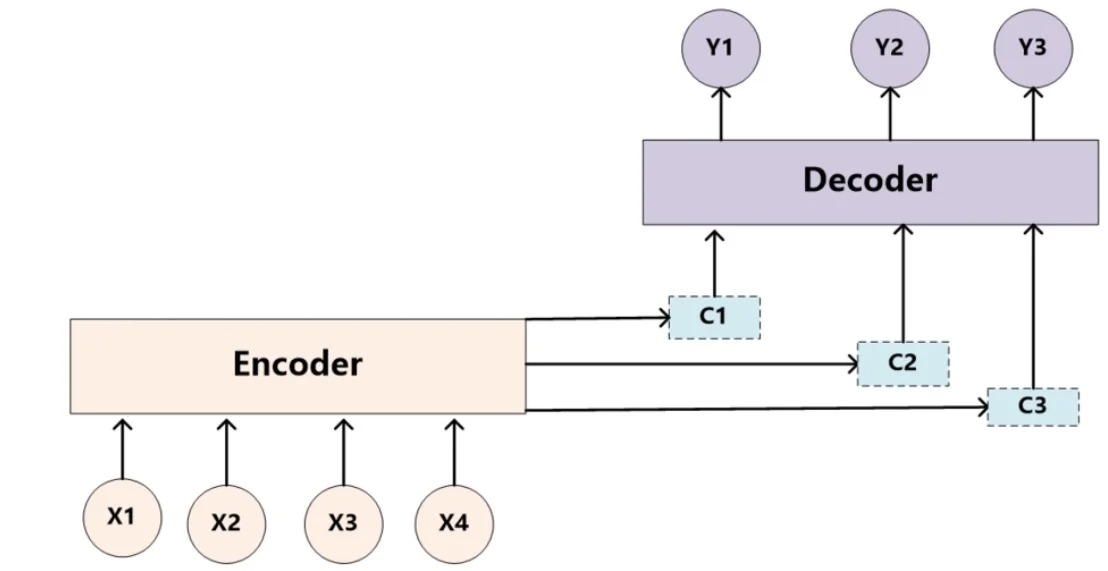
从Encoder-Decoder的本质、Encoder-Decoder的原理方面,带你搞懂Encoder-Decoder(编码器-解码器)。👉Encoder-Decoder(编码器-解码器):强调模型的实现方法——提供实现这一目的的具体方法或架构。在每个时间步,解码器会基于上一个时间步的输出、当前的隐藏状态和上下文向量来生成当前时间步的输出。👉Seq2Seq(序列到序列):强调模型的目的——将
不同神经网络特征的融合是深度学习中一个重要的研究领域,特别是在处理需要综合多种数据类型或不同视角的复杂任务时。适用情景:当不同特征在原始空间中具有相似的结构或性质时,例如多个传感器获取的时间序列数据。操作:构建多个并行的网络分支处理不同特征,然后在多个层级交叉融合这些分支的特征。操作:分别训练不同的神经网络,然后在网络的高层(如决策层)融合各自的输出特征。🕳️实验验证:通过实验来验证不同融合策略

题主因工作需要在笔记本和台式机上面同时登录了邮箱(foxmail),发现两个终端的已发送不同步,也就是说,我在笔记本发送邮件之后,台式机上面不会同步更新,这导致我回家后看不到我之前发送的邮件记录,这非常不适应,因此本人决定将pop3协议修改为imap协议。foxmail邮箱默认采用的是pop3协议,而且不支持pop3协议在线修改为imap协议,因此这里简单的介绍一种方法,可以使得原先所有的邮件原封
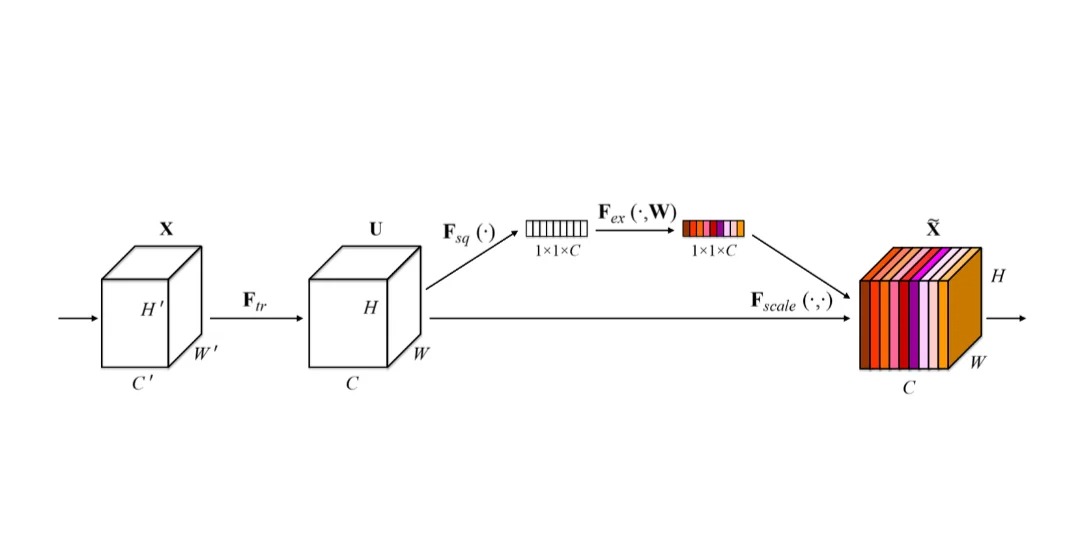
最新的变体可能结合空间注意力或其他形式的注意力机制,以适应更广泛的应用,比如图像识别或多模态学习。做法:CBAM先后应用空间注意力和通道注意力。做法:在如EfficientNet这类高效的网络架构中引入注意力机制,比如使用SE模块或其他形式的注意力来增强特征提取能力。策略:利用Transformer的强大序列处理能力,并通过额外的注意力机制来增强对特定类型数据(如图像、视频)的处理能力。3️⃣细粒
6️⃣层次注意力(Hierarchical Attention):在多层次结构(如文档、段落、句子)中使用,分别对不同层级的数据应用注意力。9️⃣协同注意力(Co-Attention):在多模态学习中使用,比如结合视觉和文本信息,模型在两种类型的数据上同时应用注意力。7️⃣时间注意力(Temporal Attention):用于处理时序数据,如视频分析或音频处理,关注时间序列的不同部分。Soft
9️⃣损失函数上也可以加,比如你的任务对边界很敏感,你就可以使用边界敏感的损失函数,来约束网络学习。3️⃣迁移学习、模型蒸馏(树模型蒸馏给transformer)5️⃣不同性质的特征作为不同的输入头。4️⃣重要的特征放得离输出近。
最新的变体可能结合空间注意力或其他形式的注意力机制,以适应更广泛的应用,比如图像识别或多模态学习。做法:CBAM先后应用空间注意力和通道注意力。做法:在如EfficientNet这类高效的网络架构中引入注意力机制,比如使用SE模块或其他形式的注意力来增强特征提取能力。策略:利用Transformer的强大序列处理能力,并通过额外的注意力机制来增强对特定类型数据(如图像、视频)的处理能力。3️⃣细粒
6️⃣层次注意力(Hierarchical Attention):在多层次结构(如文档、段落、句子)中使用,分别对不同层级的数据应用注意力。9️⃣协同注意力(Co-Attention):在多模态学习中使用,比如结合视觉和文本信息,模型在两种类型的数据上同时应用注意力。7️⃣时间注意力(Temporal Attention):用于处理时序数据,如视频分析或音频处理,关注时间序列的不同部分。Soft
9️⃣损失函数上也可以加,比如你的任务对边界很敏感,你就可以使用边界敏感的损失函数,来约束网络学习。3️⃣迁移学习、模型蒸馏(树模型蒸馏给transformer)5️⃣不同性质的特征作为不同的输入头。4️⃣重要的特征放得离输出近。
1️⃣基于预训练模型的微调: 微调是迁移学习中最常用的策略之一。可以利用在大规模数据集(如ImageNet)上预训练的深度神经网络(例如ResNet或BERT),然后将其微调以适应特定的任务或数据集。这种方法特别适用于数据量较少的任务,因为预训练模型已经学习了丰富的特征表示,可以显著提高新任务的学习效率和性能。2️⃣多任务学习与迁移学习的结合: 多任务学习旨在同时学习多个相关任务,从而改善每个单独