- @Ichliebedich2020
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文介绍了pandas数据筛选与保存的进阶操作。主要内容包括:1)数据筛选的核心思想是通过条件语句快速提取目标数据,比Excel操作更高效;2)具体实现步骤为:先使用df[df['列名']>值]进行筛选,再通过.to_csv()保存结果;3)提供了完整代码示例,涵盖数据读取、统计分析(计算平均分和最高分)、筛选90分以上学生数据并保存为CSV文件。这些操作能帮助用户快速处理大规模数据,提高数
本文介绍了数据清洗中缺失值处理的两种基本方法。数据清洗的核心是处理表格中的空值(NaN),避免计算错误。主要方法包括删除含空值的行(dropna())或用固定值填充空值(fillna(0))。文章提供了Python代码示例,演示如何读取含缺失值的CSV文件,分别使用删除和填充方法处理缺失值,并将清洗后的数据保存为新文件。通过这两种简单有效的方法,可以确保数据完整性,为后续分析做好准备。
本文介绍了CSV文件的基础知识和创建方法。CSV(逗号分隔值)是一种通用的数据存储格式,具有体积小、跨平台的优势。文章详细讲解了CSV的结构特点(表头+数据行)、使用价值(实现自动化数据处理),并提供了创建CSV文件的实操步骤:新建文本文档→重命名为.csv→用英文逗号分隔数据→保存。特别强调了英文逗号的关键作用和文件存储位置建议。最后要求读者动手创建一个包含姓名和分数两列数据的CSV文件,为后续
《Pandas入门指南:12天学会数据处理》 本文介绍了Python数据处理库Pandas的基础使用方法。主要内容包括:1)Pandas的核心功能是将CSV/Excel等文件转换为DataFrame表格对象;2)安装方法:通过pip install pandas命令安装;3)基本操作:使用pd.read_csv()读取数据,并用head()方法查看前几行数据;4)注意事项:文件路径问题和大数据量处
这篇文章介绍了使用Python的pandas库进行数据处理的全流程,包含4个核心知识点:1)修改表格表头和数据格式;2)数据分组聚合计算;3)多表合并与关联;4)自动化办公数据处理流水线。通过具体代码示例演示了如何重命名列、转换数据类型、分组统计平均值/总和、多表关联合并,以及实现从数据读取、清洗、计算到保存的自动化处理。文章提供了完整的代码片段和示例数据,适合想要学习pandas数据处理基础操作
3.C计算,栅格计算函数。
Con("坡度数据" < 5,10.8 * Sin("坡度数据" * 3.1415926 / 180) + 0.03,Con("坡度数据" <= 10,16.8 * Sin("坡度数据" * 3.1415926 / 180)-0.5,21.91 * Sin("坡度数据" * 3.1415926 / 180) - 0.96))"水流长度"*Cos("坡度数据"*3.1415926/180)Power
(3)土地利用数据进行重分类(注意名称需要统一;nodate需要改成0)并把威胁源数据(tif文件转shp文件)导出。1、LUCC数据预处理:投影栅格数据(投影坐标系)、按掩膜提取、重采样(按掩膜提取中环境中设置)、设置数据对应格式。威胁源数据excel数据和敏感度数据对土地利用数据进行重分类。3、敏感源处理对应表格中生境适宜值(需要与Value相对应)判断研究区的威胁源是什么?假设是冰雪、裸地、
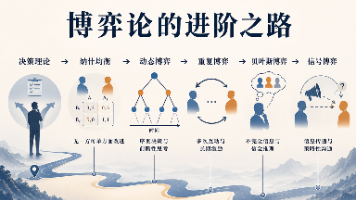
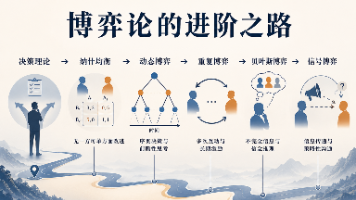
本文介绍了不完全信息博弈的基本概念和应对方法。核心问题在于参与者无法直接了解对方的真实情况(如求职者能力、二手车质量等),这种隐藏属性被称为"类型"。海萨尼转换通过将未知信息转化为概率分布,使问题可计算。贝叶斯纳什均衡要求玩家基于概率信念进行决策。信号博弈是重要应用,通过学历、证书等信号传递信息。典型案例包括斯宾塞的教育信号模型和阿克洛夫的柠檬市场理论,解释了信息不对称导致的市
本文介绍了静态博弈的基本概念及其关键分析方法。通过奶茶店定价案例,说明静态博弈中参与者同时决策且互不知情的特征。重点讲解了优势策略、理性化思维和最佳回应等核心概念,并以囚徒困境为例阐释纳什均衡的形成机制:当所有参与者的策略互为最佳回应时达到的稳定状态。文章指出,纳什均衡解释了为何个体理性决策可能导致集体非最优结果(如价格战),这正是静态博弈研究的核心价值。内容提炼自MIT博弈论课程,结合AI工具整