- @Ever_____
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
【动手学强化学习】第二章 多臂老虎机问题本章知识点:探索与利用的含义、多臂老虎机问题、累积懊悔的定义、增量式更新期望奖励、经典探索策略(ϵ-贪婪算法、上置信界UCB算法、汤普森采样算法)

【强化学习】Q-learning,DQN,SARSA算法介绍强化学习算法分类基于价值的方法基于策略的方法Actor-Critic方法Q-learning算法DQN算法强化学习训练数据存在的问题经验回放机制备份网络机制Sarsa算法总结
这三个项目都是Stable Baselines3生态系统的一部分,它们共同提供了一个全面的工具集,用于强化学习的研究和开发。SB3提供了核心的强化学习算法实现,而RL Baselines3 Zoo提供了一个训练和评估这些算法的框架。SB3 Contrib则作为实验性功能的扩展库,SBX则探索了使用Jax来加速这些算法的可能性。

【强化学习】强化学习基础教程:基本概念、强化学习的定义,要素,方法分类 以及 Rollout、episode回合、transition转移、trajectory轨迹的概念1.基础概念1.1 强化学习的定义1.2 强化学习的基本要素2.强化学习分类2.1 根据agent学习方式分为基于策略的强化学习Policy based RL ,基于价值的强化学习Value based RL以及Actor-Cri
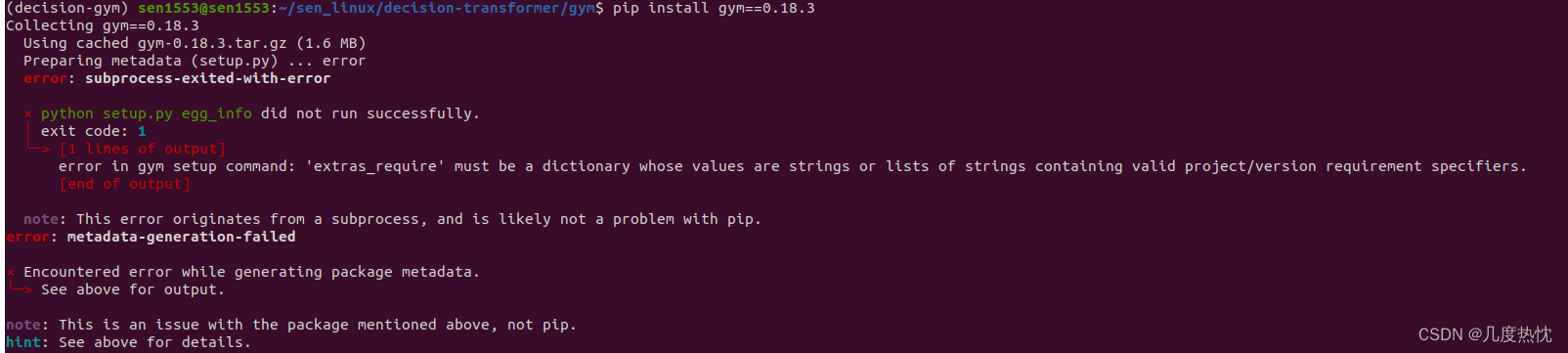
安装gym==0.18.3报错的解决方法Collecting gym==0.18.3Using cached gym-0.18.3.tar.gz (1.6 MB)Preparing metadata (setup.py) ... errorerror: subprocess-exited-with-error× python setup.py egg_info did not run succes
【强化学习】gymnasium自定义环境并封装学习笔记gym与gymnasium简介gymgymnasiumgymnasium的基本使用方法使用gymnasium封装自定义环境官方示例及代码编写环境文件__init__()方法reset()方法step()方法render()方法close()方法注册环境创建包 Package(最后一步)创建自定义环境示例

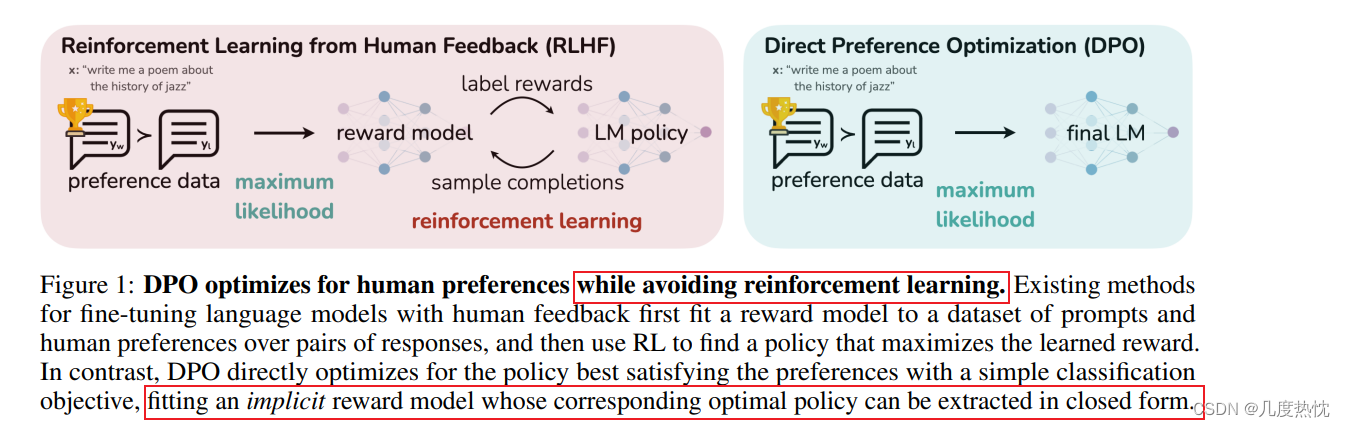
【强化学习】DPO(Direct Preference Optimization)算法学习笔记RLHF与DPO的关系KL散度Bradley-Terry模型DPO算法流程
在此记录两道计算机网络教材的课后题:1.要发送的数据为1101011011。采用CRC的生成多项式是P(X)=X^4+X+1。试求应添加在数据后面的余数。数据在传输过程中最后一个1变成了0,问接收端能否发现?若数据在传输过程中最后两个1都变成了0,问接收端能否发现?采用CRC检验后,数据链路层的传输是否就变成了可靠的传输?解题过程:依题得 数据为10位 除数为10011 为5位(p位冗余码=n+1
【强化学习环境搭建】mujoco,mujoco_py,d4rl等强化学习相关资源安装及使用的参考资料链接 持续更新ing1.安装mujoco2.安装mujoco_py3.安装d4rl4.安装gym或gymnasium在此博客中记录一些配置强化学习环境时 遇到的优质参考资料,持续更新ing~
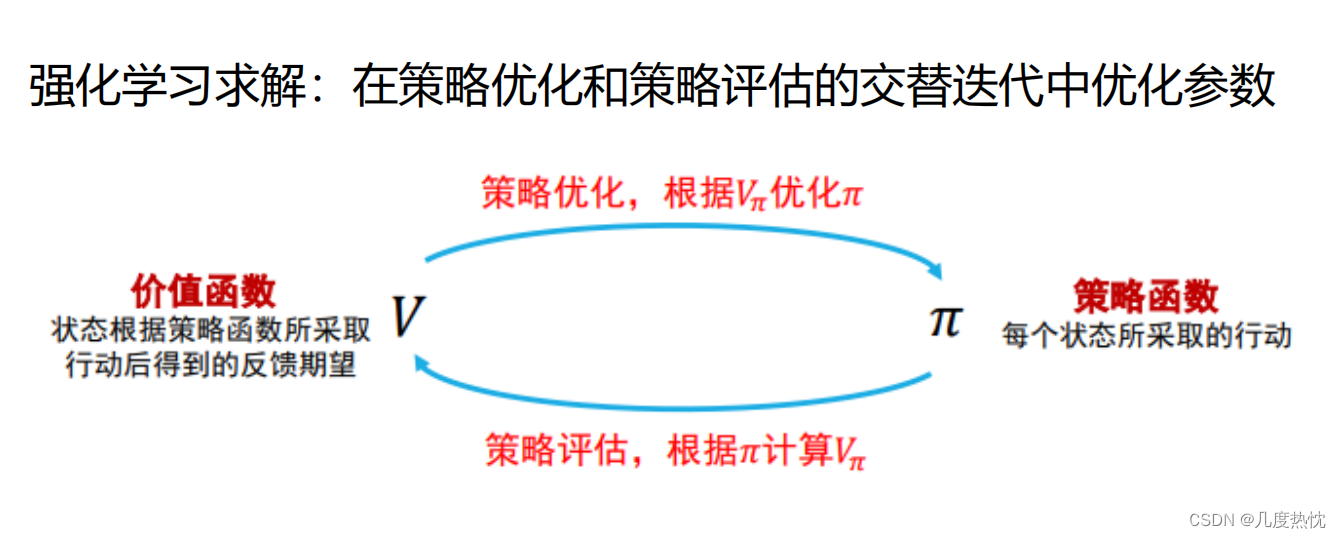
【动手学强化学习】第 6 章 Dyna-Q 算法知识点总结本章知识点基于模型的强化学习与无模型的强化学习方法简介无模型的强化学习方法基于模型的强化学习方法强化学习算法的评价指标Dyna-Q算法Dyna-Q 算法的具体流程Dyna-Q 代码实践