




- @CITY_OF_MO_GY
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
通过PULL命令只可以拉取官方商城维护的预训练模型,如果我们通过LLaMA-Factory等工具微调了一个垂类大模型,想通过Ollama来部署,该如何操作呢?

假设我们想要实现一个自定义的ReLU6操作符。ReLU6是一种常用的激活函数,它与标准的ReLU类似,但有一个上限值 6。首先,我们需要在 C++ 中实现这个自定义操作符,并编译成一个共享库。PyTorch 提供了接口来注册自定义操作符,而 ONNX 则提供了来注册自定义操作符。我们可以在 C++ 中实现ReLU6操作符,并通过 PyTorch 的// 定义自定义的 ReLU6 操作符// 注册自

Step-Audio 是业界首个集语音理解与生成控制一体化的产品级开源实时语音对话系统,支持多语言对话(如 中文,英文,日语),语音情感(如 开心,悲伤),方言(如 粤语,四川话)等功能;: 单模型能实现理解生成一体化完成语音识别、语义理解、对话、语音克隆、语音生成等功能,开源千亿参数多模态模型 Step-Audio-Chat;

前面我们介绍了,并通过Open-WebUI进行调用,相信大家对Ollama也有了一定的了解;这篇博文就结合Ollama工具和CherryStudio工具构建一个本地知识库(RAG);在进行接下来的操作之前,需要本地已经安装并配置好Ollama工具,还没有安装的小伙伴可以根据完成本地安装;

最后,我们再用通俗的话总结一下它的流程:1)输入语言文本给分词器;2)分词器拿到文本信息,根据具体的分词算法(例如:BPE)将文本划分为单个的词元(token);3)根据对应的词汇表将每个词元对应唯一编码(token ID);4)分词器输出这些唯一编码给Embeding词嵌入模型;到这里分词器的输入任务就完成了5)词嵌入模型将token ID映射到固定维度的语义空间,生成语义特征张量;6)将语义特

Spark TTS完全基于Qwen2.5构建,无需额外的生成模型,它不依赖于单独的模型来生成声学特征,而是直接从LLM预测的代码中重建音频。这种方法简化了流程,提高了效率并降低了复杂性;支持零样本语音克隆,它可以直接复制说话者的语音。这是跨语言和代码转换场景的理想选择,允许语言和语音之间的无缝转换,而不需要对每种语言进行单独的培训;支持中文和英文两种语言,使模型能够以高自然度和准确性合成多种语言的

FunASR是阿里巴巴达摩院开源的一款轻量级语音识别工具包,旨在为开发者提供高效、易用的语音处理解决方案。它集成了多种先进的语音识别技术和模型,支持语音识别(ASR)、语音端点检测(VAD)、标点恢复、语言模型、说话人验证、说话人分离和多人对话语音识别等功能;任务名称主要目标应用场景技术特点ASR将语音转为文本字幕生成、语音助手声学模型+语言模型VAD检测语音活动语音信号预处理时间域或频域特征分析

索引类型精度速度存储空间适用场景IVF_FLAT高中高大规模数据,内存充足IVF_SQ8中快中存储受限,中等精度需求IVF_PQ低快低高维向量,存储受限HNSW中快中高维向量,高速检索需求ANNOY中快低中低维向量,简单配置需求DISKANN中慢低超大规模数据,磁盘存储为主RNSG高快中高维向量,高效检索需求。

从代码出发,探索MoE架构的大模型与稠密模型的区别
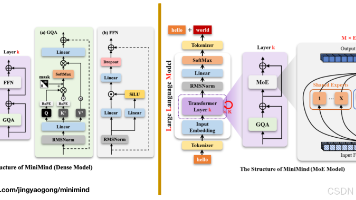
大语言模型的预训练过程源码分析
