




- @AIGCmagic
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
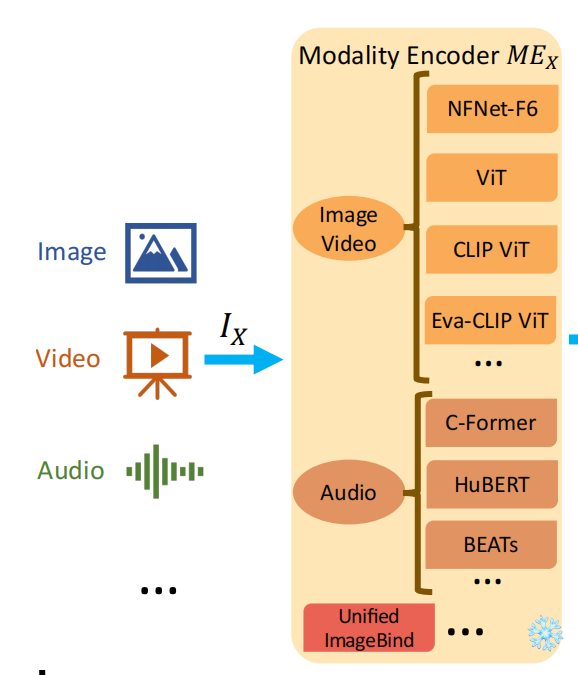
模态编码器(Modality Encoder, ME):负责将不同模态的输入编码成特征。常见的编码器包括图像的NFNet-F6、ViT、CLIP ViT等,音频的Whisper、CLAP等,视频编码器等。输入投影器(Input Projector):负责将其他模态的特征投影到文本特征空间,并与文本特征一起输入给语言模型。常用的投影器包括线性投影器、MLP、交叉注意力等。语言模型骨架(LLM Bac
中英文多模态大模型VisualGLM-6B微调部署全流程

LLaVA-CoT(Let Vision Language Models Reason Step-by-Step),一种旨在通过多阶段推理来增强视觉语言模型(VLM)系统性和结构性推理能力的新模型。LLaVA-CoT将答案生成过程分解为四个结构化推理阶段:总结、标题、推理和结论。模型提供问题的高层次总结,概述将要解决的问题的主要方面。如果存在图像,模型提供与问题相关的视觉元素的简洁概述,帮助理解多

提供研究背景、目的、方法、结果和结论的简要描述。

MiniCPM-V 2.0,这是MiniCPM系列的多模态版本。MiniCPM-V 2.0显示出强⼤的OCR和多模态理解能⼒,在开源模型中的OCRBench上表现出⾊,甚⾄在场景⽂本理解上可以与Gemini Pro相媲美。MiniCPM-V 系列是专为视觉-语⾔理解设计的多模态⼤型语⾔模型(MLLMs),提供⾼质量的⽂本输出,已发布4个版本。# 下载模型,以int4量化的MiniCPM-Llama

中英文多模态大模型VisualGLM-6B微调部署全流程
中英文多模态大模型VisualGLM-6B微调部署全流程
中英文多模态大模型VisualGLM-6B微调部署全流程
自研 MoE 模型,671B 参数,激活 37B,在 14.8T token 上进行了预训练,用于解决大语言模型的高效推理和训练问题。多头潜在注意力(MLAMLA架构通过低秩联合压缩注意力键和值来减少推理过程中的KV缓存,从而提高推理效率。DeepSeekMoE架构使用细粒度的专家并行和隔离一些专家作为共享专家,以提高训练效率。无辅助损失的负载均衡为了最小化辅助损失对模型性能的影响,提出了一种无辅

中英文多模态大模型VisualGLM-6B微调部署全流程