




- @AIGCer
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
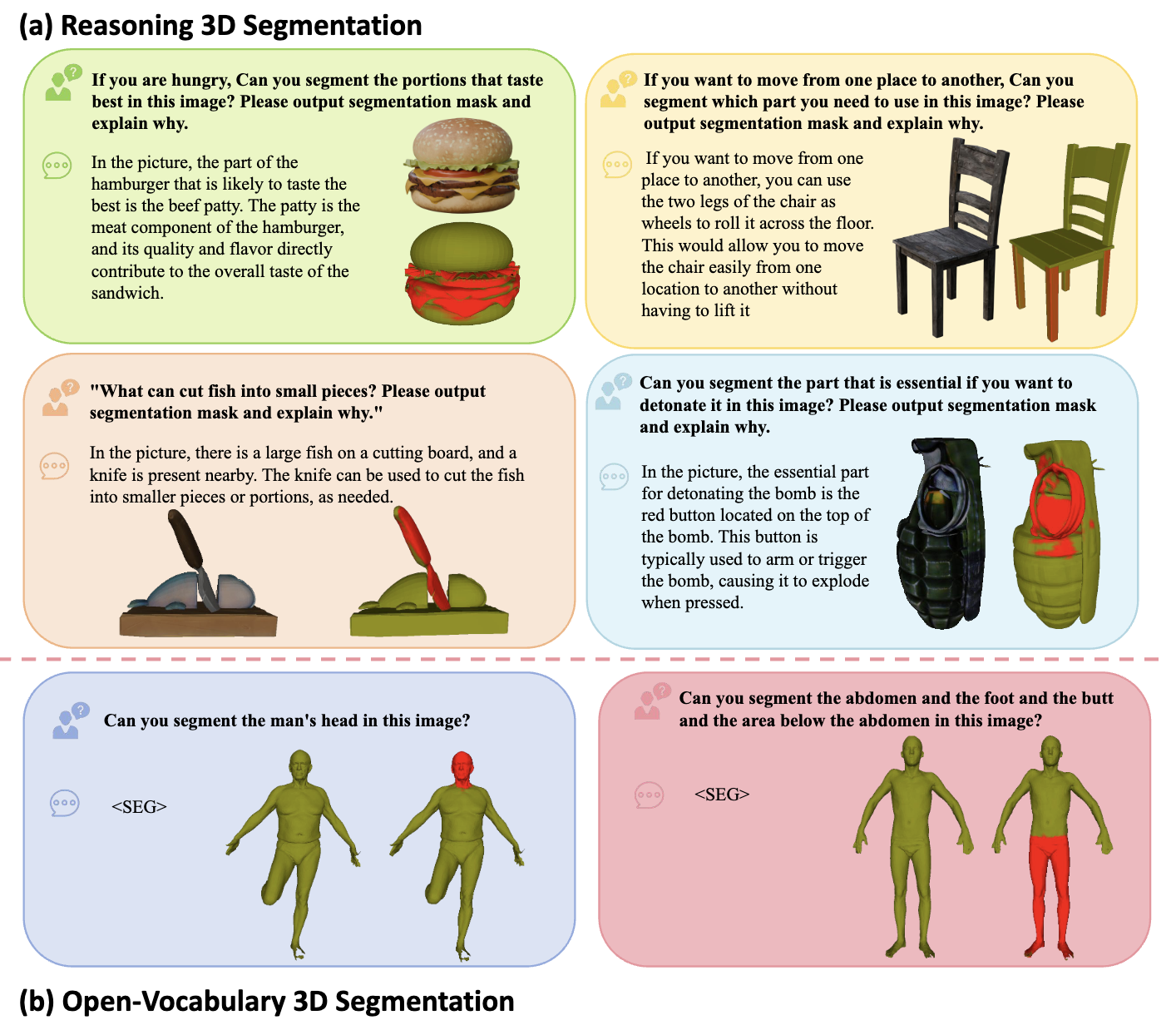
本文开发了Reasoning3D,一个简单而有效的基线方法,可以理解并执行复杂的命令,以对3D网格的特定部分进行分割,具有上下文理解和推理输出,用于交互式分割。随机收集了来自3D建模网站SketchFab的3D模型,并使用这些实际中的3D模型进行评估,并让志愿者给出“隐含”的分割命令。图6和图1展示了一些示例。在这里,受解决了3D生成中类似挑战的研究[16,17,52,54,60,72]的启发——
摘要:复旦大学等机构提出首个端到端多模态矢量动画生成框架OmniLottie,可直接从文本/图像/视频指令生成Lottie格式动画。创新点包括:1) 设计Lottie分词器将JSON压缩为高效指令序列,实现10倍数据压缩;2) 开源200万规模的MMLottie-2M数据集;3) 基于Qwen2.5-VL构建多模态模型,支持跨模态动画生成。实验表明其生成质量优于现有方法,在保持矢量特性的同时解决了

SoulX-LiveTalk提出了一种14B参数的实时音频驱动虚拟形象框架,通过创新的双向蒸馏策略和全栈优化实现高效生成。该框架摒弃传统单向范式,采用双向注意力机制增强运动连贯性,结合多步自校正机制防止长周期误差累积。通过混合序列并行、并行VAE等优化技术,系统在8个H800节点上实现0.87秒启动延迟和32FPS吞吐量。实验表明,该框架在视觉质量、唇音同步和长期稳定性上均优于现有方法,训练效率提

扩散模型通过噪声创建数据。它们被训练来反转数据向随机噪声的正向路径,因此,结合神经网络的近似和泛化性质,可以用来生成不在训练数据中但遵循训练数据分布的新数据点。这种生成建模技术已被证明在建模高维感知数据,如图像方面非常有效。近年来,扩散模型已成为从自然语言输入生成高分辨率图像和视频的事实标准方法,具有令人印象深刻的泛化能力。由于它们的迭代性质及相关的计算成本,以及推理期间的长时间采样,对这些模型进

摘要:复旦大学等机构提出首个端到端多模态矢量动画生成框架OmniLottie,可直接从文本/图像/视频指令生成Lottie格式动画。创新点包括:1) 设计Lottie分词器将JSON压缩为高效指令序列,实现10倍数据压缩;2) 开源200万规模的MMLottie-2M数据集;3) 基于Qwen2.5-VL构建多模态模型,支持跨模态动画生成。实验表明其生成质量优于现有方法,在保持矢量特性的同时解决了
智能体(agent)是一个能够感知其环境并根据这些感知做出决策以达到特定目标的系统。尽管在狭窄领域内表现出色,早期智能体往往缺乏适应性和泛化能力,与人类智能存在显著差异。最近大语言模型(LLMs)的进展开始弥合这一差距,LLMs增强了它们在命令解释、知识吸收和模拟人类推理和学习方面的能力。这些智能体使用LLMs作为它们的主要决策工具,并进一步增强了关键的类人特征,如记忆。这种增强使它们能够处理各种

Transformer,由Vaswani等人引入,以其强大的数据建模能力、可伸缩性以及出色的捕捉长距离依赖性的能力,彻底改变了机器学习。起源于自然语言处理(NLP)领域,取得了机器翻译和文本摘要等方面的成功,Transformer现在将其实用性扩展到计算机视觉任务,如图像分类和目标检测。最近,它们的能力已经在多模态情感分析领域得到了利用,其中它们整合和解释多样的数据流——文字、视觉和声音——以评估
生成式人工智能和工具在各个主要行业都有许多应用案例,如网络安全和制造业。随着时间的推移,将会发现更多的应用案例。尽管正面的例子比比皆是,但我们必须谨慎前行。即使有许多积极的例子,但生成式人工智能和其他模型的威力尚未完全被理解。对于决定在其组织中实施AI的人来说,战略性地进行实施,并严格遵守最佳实践是至关重要的。

《RynnVLA-002:统一视觉-语言-动作与世界模型的创新架构》 摘要:本文提出RynnVLA-002模型,首次将视觉-语言-动作(VLA)模型与世界模型统一于单一框架。该模型通过双向增强机制实现互补:世界模型利用物理规律优化动作生成,而VLA增强视觉理解以提升图像预测精度。创新性地采用混合动作生成策略,包括"动作注意力掩码"解决离散动作误差累积,以及连续ActionTra

摘要: 本文揭示了视觉自回归(AR)生成模型性能瓶颈的关键原因:生成器与分词器之间的不一致性,即生成的Token序列难以被分词器有效解码。为此,提出了一种即插即用的训练正则化方法reAR,通过噪声上下文正则化(缓解暴露偏差)和码本嵌入正则化(对齐生成器与分词器的视觉嵌入)来提升一致性。实验表明,reAR显著提升了生成质量(如VQGAN上FID从3.02降至1.86),甚至以更少参数超越复杂模型(如
