- @A5522000
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
PyTorch是一个基于Python的深度学习框架,提供灵活高效的张量计算和自动微分功能。文章介绍了PyTorch的特点(如动态计算图、GPU加速)、发展历史,以及张量的创建方式(包括基本创建、随机生成和特殊值张量)。PyTorch因其直观的API设计和强大的功能,在学术界和工业界广泛应用。
文章摘要: 循环神经网络(RNN)是一种专门处理序列数据的神经网络,通过循环结构能够记忆历史信息,适用于时间序列和自然语言处理任务。RNN在文本生成、语音识别、时间序列预测等领域有广泛应用。词嵌入层是RNN处理文本的关键,将离散单词转换为连续向量表示(如使用PyTorch的nn.Embedding),捕捉语义关系并降低维度。RNN通过循环结构处理序列数据,保持文本的顺序特性,解决传统神经网络无法处
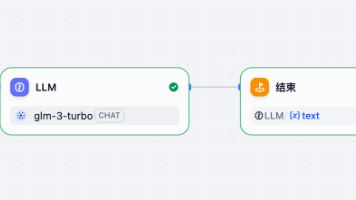
本文介绍了AI模型微调的基本步骤和工作流程实现方法。模型微调包括选择预训练模型、准备数据集、调整结构、设置参数、训练和评估部署等环节。针对数据集制作门槛高的问题,提出通过Dify工作流生成语料方案,该流程包含开始节点、文档解析、数据处理、LLM生成等阶段,最终输出符合要求的JSONL格式微调数据。测试结果显示,系统能成功生成包含system/user/assistant三角色的结构化训练数据,为普
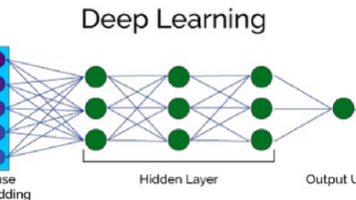
深度学习(Deep Learning)是机器学习的分支,是一种以人工神经网络为架构对数据进行特征学习的算法。深度学习中的形容词“深度”是指在网络中使用多层。深度学习核心思想是通过模仿人脑的神经网络来处理和分析复杂的数据,从大量数据中自动提取复杂特征,擅长处理高维数据,如图像、语音和文本。
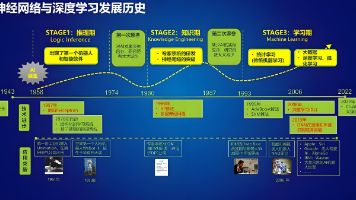
本文介绍了使用vLLM框架进行大模型本地化部署的完整流程。主要内容包括:1)环境安装与配置,推荐使用docker方式;2)两种模型部署方式(命令行参数和配置文件);3)通过OpenAI SDK进行API测试调用;4)性能测试脚本开发,评估首token时间、QPS等关键指标;5)在腾讯Cloud Studio平台上的实战操作演示。文章以Qwen2.5-1.5B模型为例,详细说明了从环境搭建到性能测试
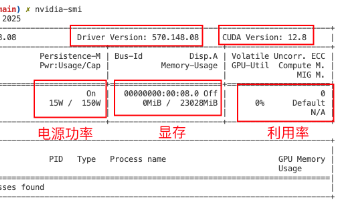
深度学习(Deep Learning)是机器学习的分支,是一种以人工神经网络为架构对数据进行特征学习的算法。深度学习中的形容词“深度”是指在网络中使用多层。深度学习核心思想是通过模仿人脑的神经网络来处理和分析复杂的数据,从大量数据中自动提取复杂特征,擅长处理高维数据,如图像、语音和文本。
文章摘要: 循环神经网络(RNN)是一种专门处理序列数据的神经网络,通过循环结构能够记忆历史信息,适用于时间序列和自然语言处理任务。RNN在文本生成、语音识别、时间序列预测等领域有广泛应用。词嵌入层是RNN处理文本的关键,将离散单词转换为连续向量表示(如使用PyTorch的nn.Embedding),捕捉语义关系并降低维度。RNN通过循环结构处理序列数据,保持文本的顺序特性,解决传统神经网络无法处
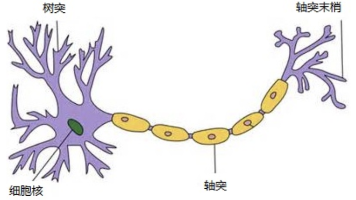
神经网络是一种模仿生物神经网络的机器学习模型,由输入层、隐藏层和输出层组成。前向传播过程中,数据通过各层神经元进行加权计算和激活函数变换,最终产生预测结果。激活函数(如Sigmoid、Tanh等)为网络引入非线性因素,使其能拟合复杂函数。合理设置神经元权重和激活函数对网络性能至关重要。全连接神经网络中,相邻层神经元两两相连,每个连接都有权重参数。网络通过调整这些参数来学习数据特征,实现分类或回归任
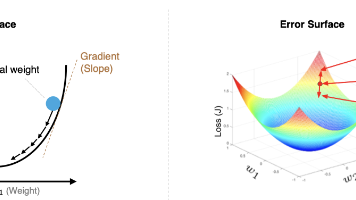
本文介绍了神经网络的核心优化方法。多层神经网络通过误差反向传播算法(BP)进行训练,BP算法利用链式法则计算梯度并更新权重。梯度下降法通过沿负梯度方向调整参数最小化损失函数,其变体包括批量、随机和Mini-Batch梯度下降。反向传播过程分为前向计算输出和反向传播误差两个阶段,文中通过具体示例详细解释了权值更新过程。针对梯度下降的局限性(如鞍点、局部最优),介绍了Momentum、AdaGrad等
本文介绍了线性回归的基本概念、分类及应用场景,并详细讲解了线性回归问题的求解方法。主要内容包括:一元与多元线性回归的区别;损失函数(MSE、MAE)的作用;导数和矩阵在回归分析中的应用;正规方程法和梯度下降算法两种求解方式。通过身高体重预测的实例演示了sklearn中线性回归API的使用流程,并阐述了梯度下降算法的核心思想——通过迭代寻找损失函数最小值。文章为机器学习初学者提供了线性回归的完整知识