
写文章




- @2401_85568643
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
机器学习KNN算法(基于K近邻算法的分类器的实现)
本次实验为经典的海伦约会实验,在学习了KNN算法的基础上,选择样本数据集中前k个最相似的数据,就是KNN算法中k的出处。k值较小,那么预测的标签比较容易受到样本的影响。我们很容易发现,当计算样本之间的距离时数字差值最大的属性对计算结果的影响最大,也就是说,每年获取的飞行常客里程数对于计算结果的影响将远远大于上表中其他两个特征-玩视频游戏所耗时间占比和每周消费冰淇淋公斤数的影响。该网站现在需要尽可能
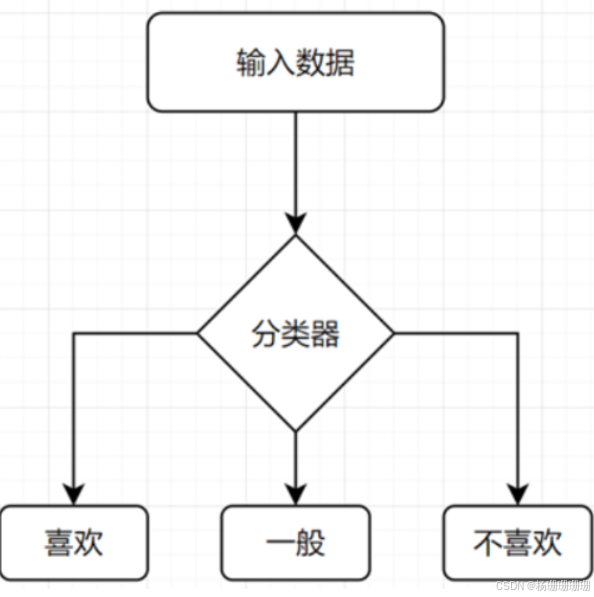
机器学习——决策树
优点简单易理解:决策树的结构类似于人类的决策过程,具有很好的可解释性。可以通过树状图直观地展示决策过程和规则,易于理解和解释。非线性关系:决策树能够处理线性和非线性关系,不要求数据线性可分。通过分裂节点,决策树可以捕捉复杂的模式和关系。特征选择:决策树可以自动进行特征选择,重要特征会被优先分裂,提高了模型的性能和效率。处理缺失值:决策树在处理缺失值时具有一定的鲁棒性,能够有效地处理部分缺失的数据。
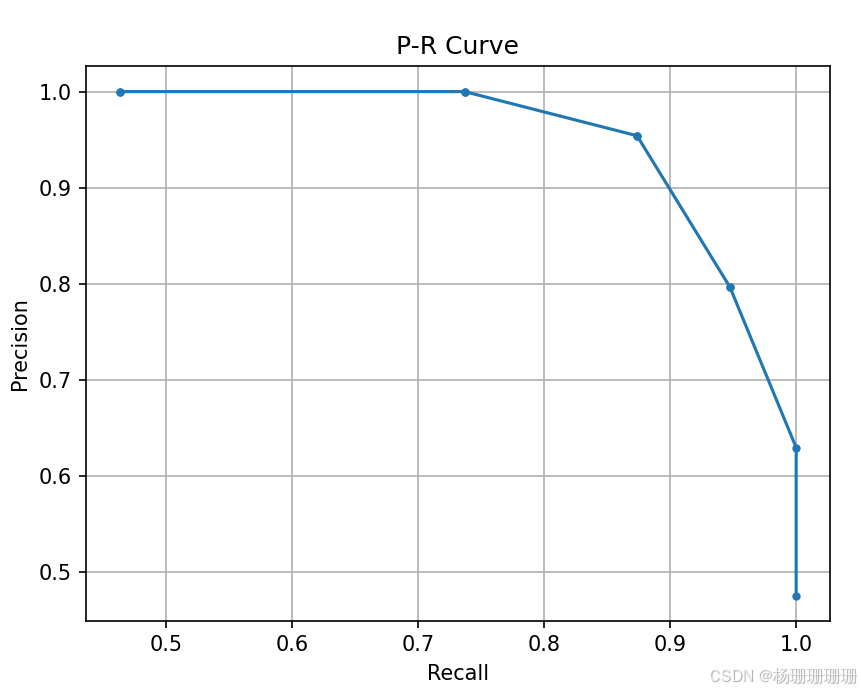
PR曲线和ROC曲线
这次实验学习了PR曲线和ROC曲线,包括它们的定义、作用,并学会了如何绘制他们,这两种曲线与我们的生活息息相关。
到底了