




- @2301_79911329
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
Backbone 主要负责从输入图像中逐层提取特征,获得从浅层到深层的多级语义表示;Neck 主要负责将不同尺度的特征进行融合,增强模型对大中小目标的检测能力;Head 则在融合后的特征图上进行分类和边界框预测,最终输出检测结果。
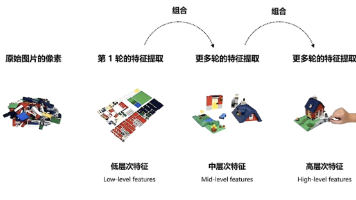
这一篇的目标是往里拆:Backbone 内部到底在做什么,为什么这样设计。光会说"Backbone 负责特征提取"是不够的,老师一追问——为什么这样提、为什么要下采样、通道数为什么越来越多、C2f 放这里是为了什么——就得能接住。
这才是最后展示在图片上的结果。原始预测 + 筛选 + 去重之后的结果你在预测图上看到的,通常就是这一步后的结果。原始预测 → 置信度筛选 → NMS 去重 → 最终结果这句话你最好记住。后面很多内容都建立在这条链上。

它通过特征拆分、部分分支继续变换、再拼接融合的方式,让不同处理深度的特征共同参与输出,有助于增强特征复用、改善信息流动,并在计算效率与表达能力之间取得平衡。结果是输出同时包含较浅、中间、较深三个层次的特征,表达更丰富,中间层信息不容易白白浪费。C2f 保留部分较浅特征的同时引入更深处理后的分支特征,最后统一融合,输出通常更丰富。这种结构的问题在于:中间层信息利用不充分,前面提取的特征在经过多层变换
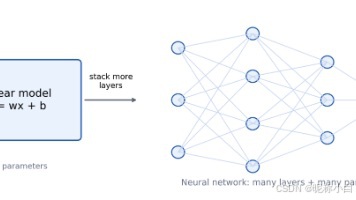
本文从最简单的线性模型y=wx+b出发,逐步解析深度学习核心概念:模型本质是函数,参数(w,b)是可调节的变量;通过预测值与真实值的比较计算loss;利用loss对参数的梯度指导参数更新;最终扩展到神经网络,指出其本质是更复杂的函数,但训练逻辑不变。文章着重区分了模型、参数、loss、梯度等易混淆概念,并通过具体示例演示了前向传播、反向传播和参数更新的完整流程,为理解YOLOv8等复杂模型奠定了理
目标检测面临的核心挑战在于处理不同尺度目标。浅层特征分辨率高但语义弱,适合小目标定位;深层特征语义强但分辨率低,适合大目标识别。仅用单层特征会导致小目标丢失或大目标定位不准。多尺度特征融合通过结合浅层细节与深层语义,使模型能同时处理不同尺寸目标。这一原理为理解YOLO等检测器的多尺度设计奠定了基础,也是现代目标检测网络的关键设计思想。
Backbone 主要负责从输入图像中逐层提取特征,获得从浅层到深层的多级语义表示;Neck 主要负责将不同尺度的特征进行融合,增强模型对大中小目标的检测能力;Head 则在融合后的特征图上进行分类和边界框预测,最终输出检测结果。
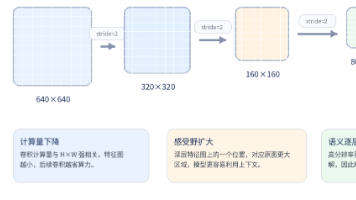
卷积神经网络通过逐层卷积操作从原始像素中提取多尺度特征,实现从低层边缘纹理到高层语义的渐进式理解。卷积核滑动计算生成多通道特征图,每个通道对应不同特征响应;下采样操作(如stride卷积或池化)缩小特征图尺寸并扩大感受野。浅层特征保留细节适合小目标检测,深层特征整合全局信息用于语义理解。这种层级结构是目标检测模型(如YOLO)多尺度预测的基础,三个核心公式分别描述卷积计算、输出尺寸变化和最大池化操
Ultralytics 的 YOLOv8 文档说明,YOLOv8 于 2023 年发布,并引入了 anchor-free split head,同时支持 detection、segmentation、classification、pose、OBB 等任务;而 Ultralytics 当前总文档与 models 页已经把 YOLO26 标为最新模型,说明 YOLOv8 今天更适合被看作“成熟学习入口
这一篇的重点不是模型结构,也不是代码,而是先把讲清楚。