- @2301_79595671
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本课题设计并实现了一个基于Hadoop的淘宝电商用户行为数据分析与可视化系统。系统利用Spark对海量用户日志进行高效处理,完成了流量统计、转化漏斗、用户价值(RFM)及商品热度等多维度分析,并结合Django与ECharts技术,将分析结果以动态图表形式直观展现,为电商运营决策提供了数据支持。

本项目基于Spark+Django构建了一套天猫订单交易数据可视化分析系统。系统利用Spark对海量订单数据进行高效处理,从总体销售、地域分布、用户行为及客户价值四个维度进行深度分析,并通过ECharts将结果以动态图表形式直观呈现,旨在为电商运营决策提供数据支持。
【25届计算机毕设选题推荐】基于深度学习的短视频内容理解与推荐系统的设计与实现 【附源码+数据库+部署】

当同学还在做学生管理系统,你的Hadoop电商物流分析毕设已经甩开他们半条街你的毕设还在用纯前端?你可知基于Hadoop的数据分析系统有多加分?选题难+数据少+没亮点?这套Hadoop电商物流数据分析系统一次性帮你解决

本系统是基于Hadoop+Spark构建的癌症数据分析与可视化平台。后端采用Python的Django框架,核心计算由Spark完成,前端使用Vue和Echarts进行展示。系统实现了患者人口统计学、临床特征、生存预后和时空模式四大分析模块,对大规模癌症数据进行多维度、深层次的统计与关联分析,旨在揭示数据背后的潜在规律,为相关研究提供高效、直观的数据分析工具。

本项目设计并实现了一个基于Hadoop+Django的肥胖风险分析与可视化系统。系统利用HDFS存储海量健康数据,通过Spark核心计算引擎,对人口统计学、饮食习惯及生活方式等多维度数据进行高效处理与关联分析。后端采用Django框架搭建服务,向前端提供API接口,最终通过Echarts等组件实现分析结果的动态可视化,为理解肥胖成因提供数据支持。

本项目聚焦于车辆碳排放分析,构建了一个基于Hadoop与Spark的大数据处理平台。系统采用Python与Django作为后端,Vue与Echarts作为前端,实现了对车辆品牌、类型、发动机技术等六大维度的CO2排放量进行统计、关联与预测分析。通过可视化图表直观展示分析结果,旨在为相关研究、政策制定及消费者购车提供数据驱动的决策支持,展现了大数据技术在环保领域的应用价值。

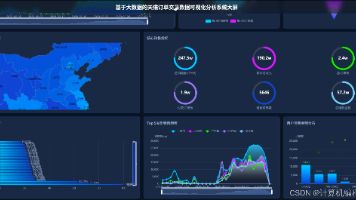
本项目基于Hadoop与Django构建,利用Spark处理上海二手房大数据,通过多维度分析揭示房价规律、区域差异及用户偏好。系统实现了从宏观市场概览到微观房源挖掘的可视化功能,旨在为用户提供直观、数据驱动的购房决策参考,是一个完整的大数据应用实践案例。
本设计实现了一个基于Hadoop与Django的全球咖啡消费与健康影响分析系统。系统利用HDFS存储海量数据,通过Spark进行高效的数据处理与关联分析,后端采用Django框架提供接口,前端则用Vue和Echarts实现数据可视化。核心功能包括多维度咖啡消费模式分析、睡眠质量影响因素探究、健康风险评估及生活方式聚类等,旨在为大众提供数据驱动的健康生活参考。

本课题基于Hadoop与Spark构建上海餐饮数据分析系统,利用Python+Django进行后端开发。系统从宏观市场、质量口碑、消费行为、空间分布和客群画像五个维度,对海量餐饮数据进行处理与可视化,旨在为市场参与者提供数据洞察与决策参考。