




- @2301_77385325
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
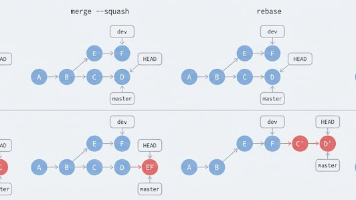
Git 中的 merge 可以理解为:把另一个分支上的修改合并到当前分支。不同合并模式的区别,是合并后提交历史如何呈现、是否保留分支痕迹,以及是否重写提交记录。下面以 main 分支和 feature 分支为例,对常见合并方式进行说明。其中,D、E 表示在 feature 分支上完成的两个提交。
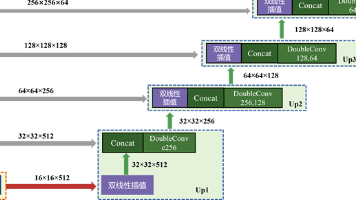
与x4进行拼接,通道数翻倍,最后经3×3卷积核(stride=1, padding=1)双层卷积DoubleConv,空间尺寸不变,通道被压到 256,最终输出特征图为32×32×256;与x2通道数翻倍(128×128×256),经双层卷积(256→64, mid=128)输出特征图为128×128×64;输入64×64×256, 2×2 最大池化输出32×32×256;输入256×256×1,
简单分类问题如使用自定义数据集,需要把FashionMNIST(...) 换成一个能返回 (图片, 标签)的 Dataset。可以按文件夹给数据集分好类,类似data/train/val/car/ a.jpg直接用 torchvision.datasets.ImageFolder即可,它默认一个文件夹是一个类别,文件夹名就是 类别名,而文件夹里的所有图片是该类别的样本。同样需要对图像进行统一尺寸、
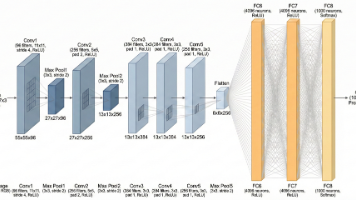
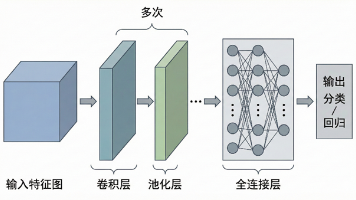
我们所看到的特征图,即卷积层的输出通常是一个二维矩阵。它有宽高,可以可视化成灰度图或热力图,像是一张新的图像。但这只是形式相似,含义完全不同。如果说一个卷积核对应一种特征,特征图表示某个卷积核的激活强度分布,即某个卷积核对应特征的强弱分布。比如一个竖直边缘卷积核,在竖直边缘处响应强,而在平坦区域响应弱。不同卷积核对应不同特征。在靠近输入的卷积层,它们的输入通道是RGB或原始像素,得到的浅层特征图感
直观上看,神经网络越深,其表达能力就越强。然而实践中发现,当网络深度增加到一定程度后,模型效果反而会明显下降。这种下降不仅体现在测试集上,在训练集上同样存在,这说明问题并非由过拟合引起,而是网络本身难以被有效优化。这被称为深层网络的问题。随着网络不断加深,误差信息在反向传播过程中难以有效传递,参数更新受阻。在这一背景下,提出了一种新的网络结构,使深层网络的训练变得更加容易,在当年的2015竞赛中获
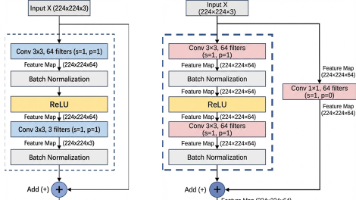
直观上看,神经网络越深,其表达能力就越强。然而实践中发现,当网络深度增加到一定程度后,模型效果反而会明显下降。这种下降不仅体现在测试集上,在训练集上同样存在,这说明问题并非由过拟合引起,而是网络本身难以被有效优化。这被称为深层网络的问题。随着网络不断加深,误差信息在反向传播过程中难以有效传递,参数更新受阻。在这一背景下,提出了一种新的网络结构,使深层网络的训练变得更加容易,在当年的2015竞赛中获
如果在不同电脑或服务器上手动安装这些环境,可能会遇到版本不一致、依赖冲突、CUDA 不兼容等问题。的作用就是将项目运行所需的系统环境、Python 环境和依赖库统一打包成镜像,使项目可以在不同机器上以相同环境运行。
Git 中的 merge 可以理解为:把另一个分支上的修改合并到当前分支。不同合并模式的区别,是合并后提交历史如何呈现、是否保留分支痕迹,以及是否重写提交记录。下面以 main 分支和 feature 分支为例,对常见合并方式进行说明。其中,D、E 表示在 feature 分支上完成的两个提交。
直观上看,神经网络越深,其表达能力就越强。然而实践中发现,当网络深度增加到一定程度后,模型效果反而会明显下降。这种下降不仅体现在测试集上,在训练集上同样存在,这说明问题并非由过拟合引起,而是网络本身难以被有效优化。这被称为深层网络的问题。随着网络不断加深,误差信息在反向传播过程中难以有效传递,参数更新受阻。在这一背景下,提出了一种新的网络结构,使深层网络的训练变得更加容易,在当年的2015竞赛中获
我们所看到的特征图,即卷积层的输出通常是一个二维矩阵。它有宽高,可以可视化成灰度图或热力图,像是一张新的图像。但这只是形式相似,含义完全不同。如果说一个卷积核对应一种特征,特征图表示某个卷积核的激活强度分布,即某个卷积核对应特征的强弱分布。比如一个竖直边缘卷积核,在竖直边缘处响应强,而在平坦区域响应弱。不同卷积核对应不同特征。在靠近输入的卷积层,它们的输入通道是RGB或原始像素,得到的浅层特征图感