




- @2202_76097976
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
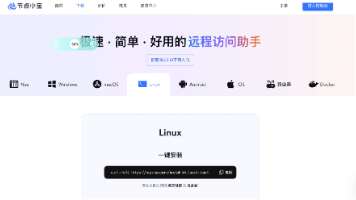
如果我们选择本地部署AI模型(如LLaMA、Stable Diffusion)的核心动机之一是对的绝对控制!但当我们需要从外部网络访问这些服务时,就面临两难选择:要么牺牲便利性(只能在内网使用),要么牺牲安全性(将服务暴露至公网)。我这边介绍一种折中的解决方案,实现的远程安全访问。将本地服务的端口通过路由器映射到公网(Port Forwarding),是常见的“暴力”解决方案。。这可以通过基于零信
在健身领域,大量应用仍停留在单向视频播放、静态指令推送的浅层应用层面:仅实现课程推送、文字任务下发,缺少真人化实时交互,无法动态指导、情绪陪伴,用户全程被动跟练,极易中途放弃。真正落地可用的健身 Agent,核心突破在于叠加 3D 具身数字人实时交互能力:以 Agent 逻辑完成训练任务规划、动作识别、数据闭环,同时依托 AI 人物实现实时动作示范、节奏引导、情绪鼓励陪伴,让训练从被动观看,升级为
Opus 4.7支持更高分辨率的视觉输入,加入自动化流程后,意味着模型可以像人一样操作电脑,例如使用浏览器、点击网页、填写表单、读取界面信息等。如果你身处非Claude官方指定支持的区域,那么Claude官网的套餐显然是不划算的,更别提国内用户还面临着注册、支付、封号的门槛。这里的文档推理指的是模型不仅能读取文档内容,还能理解其中的结构、表格、条款、上下文关系,并据此回答问题、提取信息或进行判断。

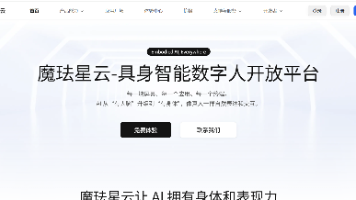
魔珐星云是魔珐科技推出的具身智能 3D 数字人开放平台,核心使命是为 AI 赋予 “身体” 与 “表达能力”。与传统数字人平台不同,它不只是提供单一的数字人形象,而是通过全栈式技术封装,让开发者无需关注复杂的 3D 渲染、动作生成等底层逻辑,只需简单调用 SDK,就能让大模型具备语音、表情、动作兼备的多模态交互能力。星云具身驱动能力,将 AI 的表达从“文本”升级为“ 3D 多模态”。它可基于文本
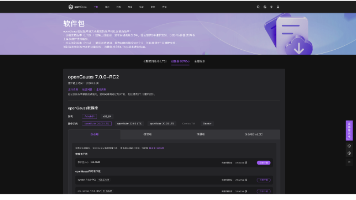
作为一名长期关注向量数据库和 RAG(检索增强生成)技术的开发者,我最近对 openGauss 7.0 的向量能力进行了深入测试。openGauss 作为开源数据库,在 AI 场景下的向量特性一直备受关注。本文将从实际使用角度,分享我在构建 RAG 系统过程中的真实体验。
Opus 4.7支持更高分辨率的视觉输入,加入自动化流程后,意味着模型可以像人一样操作电脑,例如使用浏览器、点击网页、填写表单、读取界面信息等。如果你身处非Claude官方指定支持的区域,那么Claude官网的套餐显然是不划算的,更别提国内用户还面临着注册、支付、封号的门槛。这里的文档推理指的是模型不仅能读取文档内容,还能理解其中的结构、表格、条款、上下文关系,并据此回答问题、提取信息或进行判断。
作为开发者,我深深感受到 Catlass 作为一个强大的模板库,虽然上手确实有一定门槛,但一旦掌握了它的调试和调优方法,我就能充分释放昇腾 NPU 的澎湃算力。每次调整 Tile 大小、优化流水线策略、精细控制缓存和指令调度,都能让我直观地看到性能提升带来的巨大差异。各位开发者在做Catlass的开发的时候,我强烈建议大家可以先掌握一下Catlass 的调试技术,我一直认为代码3分靠写,7分靠调。

CANN Runtime 不仅是执行环境,更是系统性能和稳定性的基石。其深度体现在对显存的定制化池化管理、基于 Event 的高效异步调度、对硬件对齐的严格遵守,以及对性能和错误的全面可观测性。Runtime 成功地将复杂的硬件资源管理和并发控制抽象化,为上层应用提供了高性能、隔离性强的计算基础。
在超大规模分布式 AI 集群中,通信模式的选择直接影响系统的可扩展性。库通过将 OpenSHMEM 标准与异构计算架构的物理特性相结合,为开发者提供了一种基于的高性能通信方案。其核心优势在于单边通信(One-sided Communication)机制,允许处理单元(PE)在不依赖目标 PE 任何软件参与的情况下,直接完成对远端显存的读写,从而实现极低延迟的数据交互。
在超大规模分布式 AI 计算中,集合通信(如 AllReduce)虽然高效,但其同步机制对于细粒度的、非规则的访存模式(如图计算、稀疏更新)显得过于僵硬。库正是为解决这一挑战而设计。它基于 OpenSHMEM 标准,引入了编程模型,实现了跨设备显存的直接单边通信(One-sided Communication),极大地降低了数据交互的延迟和同步开销。