




- @2202_75674969
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
人工智能中的大模型(Large Model / Foundation Model),是指参数规模通常在数十亿甚至千亿以上的深度神经网络。它们依靠大规模数据和高算力平台训练而成,具备强泛化能力和跨任务迁移能力,能够在自然语言处理、计算机视觉、语音、多模态等多个领域展现出较强的性能。参数规模巨大:例如 GPT-3 拥有 1750 亿参数。预训练 + 微调:先在海量通用数据上进行预训练,再通过少量标注数
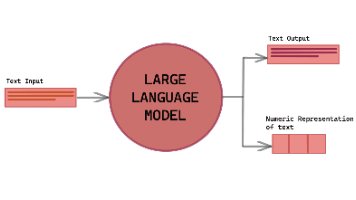
**摘要:**微调(Fine-tuning)**是在预训练模型基础上,使用特定任务或领域的数据进一步训练,使模型适应特定场景。主要方法包括: 全量微调:调整所有参数,性能最优但成本高; 参数高效微调(PEFT):如LoRA(低秩矩阵更新)、Prefix Tuning(前缀参数调整),仅微调少量参数,成本低且效果接近全量微调; 强化学习微调(RLHF):通过人类反馈优化模型行为,适用于价值观对齐和复
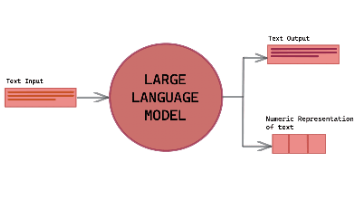
Tokenizer(分词器)是大模型处理文本的关键组件,负责将原始文本转换为模型可理解的数字格式。主要分为三类分词方法:基于词的分词(Word-based)简单高效但难以处理未登录词;基于字符的分词(Character-based)可处理任意字符但计算量大;基于子词的分词(Subword-based)通过BPE、WordPiece等算法平衡了词汇表大小和语义表达能力,成为现代大模型的主流方案。不同
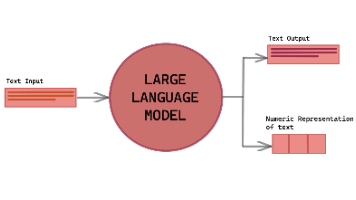
人工智能中的大模型(Large Model / Foundation Model),是指参数规模通常在数十亿甚至千亿以上的深度神经网络。它们依靠大规模数据和高算力平台训练而成,具备强泛化能力和跨任务迁移能力,能够在自然语言处理、计算机视觉、语音、多模态等多个领域展现出较强的性能。参数规模巨大:例如 GPT-3 拥有 1750 亿参数。预训练 + 微调:先在海量通用数据上进行预训练,再通过少量标注数
自注意力机制(Self-Attention)是现代深度学习尤其是NLP和CV领域的核心技术,最早由Transformer模型提出并应用于BERT、GPT等先进模型。其核心思想是让输入序列中的每个元素根据与其他元素的关系动态调整自身表示,从而有效捕捉长距离依赖,克服传统RNN/LSTM的局限性。该机制通过查询(Query)、键(Key)、值(Value)三个向量实现:Query用于查询其他元素信息,
YOLOv3是目标检测领域的经典模型,通过Darknet53主干网络实现高效特征提取,并引入残差连接缓解梯度消失。其核心创新在于多尺度检测机制,利用13×13、26×26、52×52三个不同分辨率的特征图分别检测大、中、小物体。通过FPN特征金字塔网络实现特征融合,结合自上而下的上采样和自下而上的卷积路径,将深层语义信息与浅层细节特征相结合,显著提升多尺度目标检测能力。模型采用CBL模块(卷积+批

摘要:本文系统介绍了机器学习中的欠拟合、过拟合问题及其解决方案。欠拟合源于模型过于简单或特征不足,而过拟合则因模型复杂度过高或数据噪声导致。正则化是解决过拟合的关键技术,包括L2正则化的岭回归(保持所有特征但降低权重)和L1正则化的拉索回归(自动特征选择)。逻辑回归部分重点阐述了Sigmoid函数和交叉熵损失函数的应用,并通过泰坦尼克号数据集示例展示了分类实践。全文通过数学公式和代码实例(skle
计算机视觉中的目标检测技术主要涉及三大任务:图像分类、目标检测和图像分割。目标检测算法YOLO(You Only Look Once)因其速度快、精度高而广受欢迎,其核心特点是单阶段检测,直接从图像同时预测目标类别和位置。训练过程需严格区分训练、验证和测试集,并使用标注工具(如labelimg)对数据进行边界框标注。评估指标包括交并比(IOU)、置信度、混淆矩阵、精确度、召回率以及PR曲线,其中m

YOLOv2是YOLO系列第二代目标检测算法,在YOLOv1基础上进行了多项改进。其核心思想是将目标检测转化为单次回归任务,通过卷积神经网络直接预测边界框和类别概率。主要优化包括:引入锚框机制提升小目标检测能力,采用多尺度训练增强模型鲁棒性,使用K-Means聚类选择更优先验框,以及细粒度特征融合提升检测效果。网络结构由轻量级主干Darknet-19和检测头组成,输出13×13特征图,每个网格预测

本文介绍了自动微分的核心概念与实现方法。主要内容包括:1)计算图构建,通过张量运算动态记录依赖关系;2)关键属性如requires_grad控制梯度跟踪,grad存储梯度值;3)反向传播机制,使用backward()计算梯度并应用链式法则;4)梯度计算类型,涵盖标量/向量/矩阵对向量的梯度计算;5)梯度上下文控制,包括no_grad()禁用梯度、梯度累加与清零操作;6)实际应用示例,如雅可比矩阵计
