《第四届数字信任大会》精彩观点:腾讯经验-人工智能安全风险之应对与实践|从十大风险到企业级防护架构
AI安全风险与防护实践摘要:ISACA大会揭示了AI应用中的十大安全风险,包括数据污染、提示词注入等全生命周期威胁,并分析了三个典型漏洞案例。面对大模型越狱等新型威胁,专家提出企业级防护方案:构建全生命周期安全体系,采用LLM-WAF等专用工具,实施130+控制措施覆盖七大层次,通过统一安全水位消除生态薄弱点,为AI应用提供全方位防护。(149字)
背景
观点内容摘取自《第四届数字信任大会暨ISACA中国2025年度大会》嘉宾的演讲与分享,内容代表了演讲嘉宾的经验分享/意见观点。
详细版本PPT更新在ISACA中国区官网。

1. AI应用中的十大常见安全风险
-
样本投毒(数据污染)
-
Prompt注入攻击(恶意利用)
-
代码辅助工具数据泄露
-
第三方代码依赖污染
-
自动化Agent权限滥用
-
自建模型平台暴露面过大
-
模型数据和隐私泄露
-
模型推理劫持(对抗样本)
-
伦理与偏见放大
-
开源模型滥用(深度伪造/辅助犯罪)
这些风险贯穿从数据采集、模型训练到推理和部署的全生命周期,尤其在多智能体系统和开源生态中表现突出。

2. 三个典型安全漏洞案例
案例1:Anthropic SQLite注入漏洞
-
问题:SQL注入 → 存储式提示注入 → AI代理劫持
-
关键点:攻击从数据面升级到控制面,触发AI决策逻辑失控。
案例2:MCP Inspector RCE漏洞
-
CVE-2025-49596,CVSS评分9.4
-
开发者本地工具成为攻击入口,显示本地开发环境同样需严格防护。
案例3:mcp-remote命令注入漏洞
-
CVE-2025-6514,CVSS评分9.6
-
OAuth授权流程被劫持,导致跨平台任意命令执行。
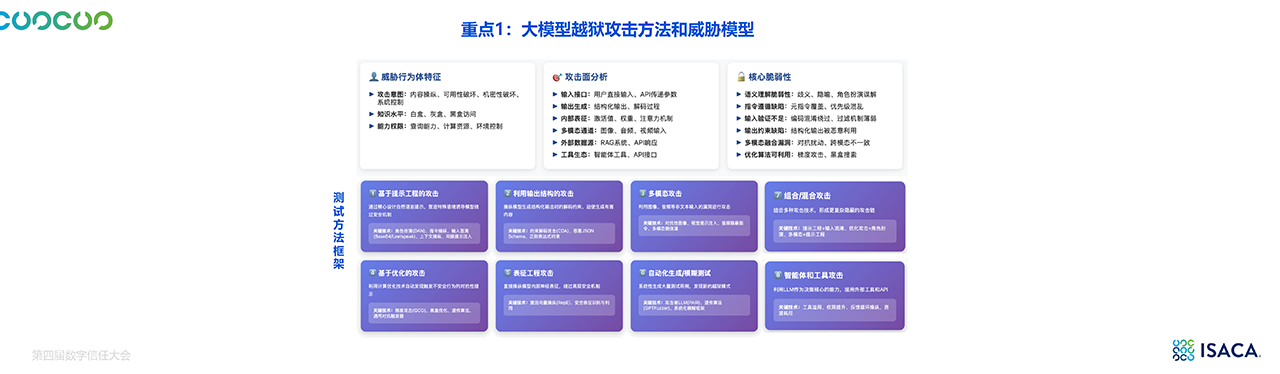
3. 新型威胁:大模型越狱与MCP生态风险
-
大模型越狱攻击:利用提示词和上下文污染绕过安全策略。
-
MCP协议生态问题:身份认证缺失、权限控制不足、审计追溯缺乏。
-
多智能体复杂性:权限传递不一致、身份仿冒、跨智能体越权访问。
4. 企业级防护实践
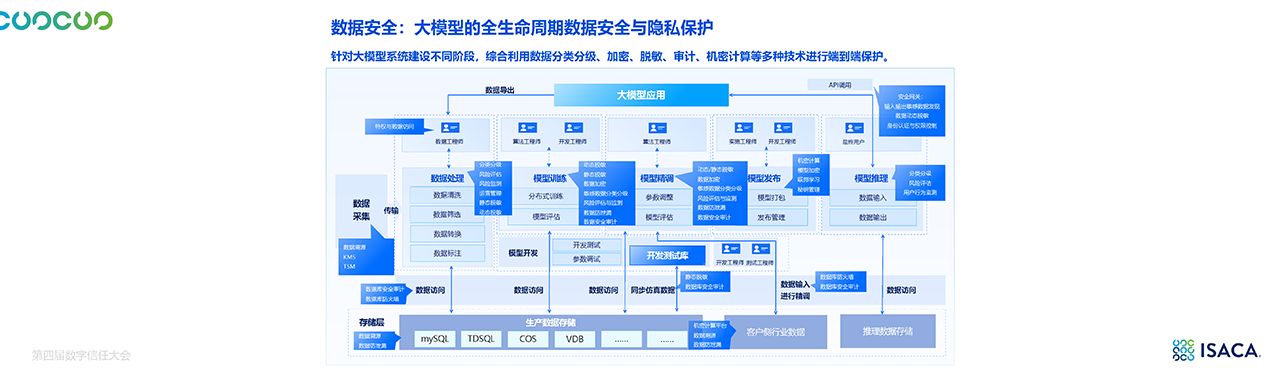
4.1 大模型全生命周期安全
-
数据安全:分类分级、加密、脱敏、数据溯源、机密计算。
-
模型安全:漏洞扫描、推理劫持检测、持续监控。
-
访问控制:统一身份认证、权限分级、跨平台授权。
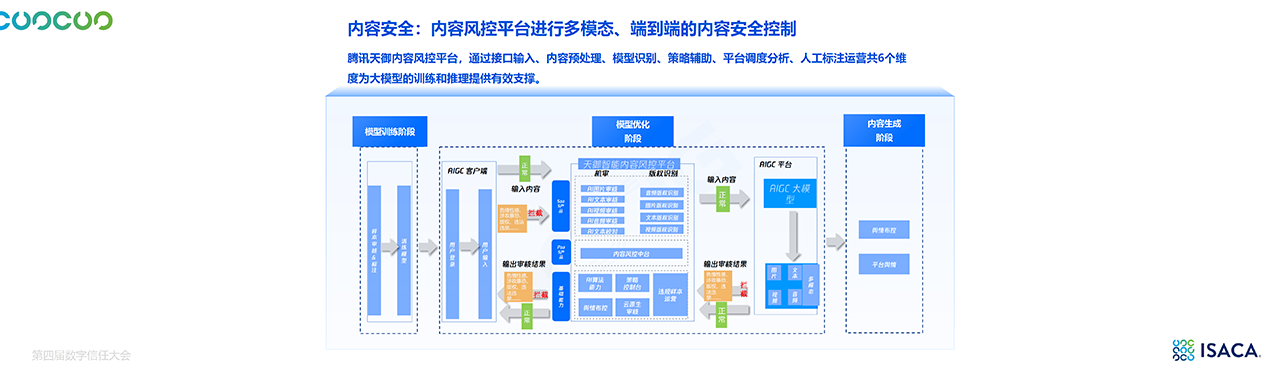
4.2 防护架构与工具
-
LLM-WAF(大模型防火墙):实时拦截算力滥用、提示词攻击与数据泄露。
-
AI-SPM(攻击面与漏洞管理):风险态势感知与漏洞修复。
-
天御大模型安全网关:统一身份和权限管控,连接智能体、模型与服务,实现决策链安全。
5. 风险评估与控制框架
-
130+ 控制措施:覆盖数据、模型、MCP服务、Agent系统七大层次。
-
测试与监控:从提示词攻击到工作流检测,形成多层次防线。
-
统一安全水位:消除生态碎片化带来的薄弱点。

一座年轻的奋斗人之城,一个温馨的开发者之家。在这里,代码改变人生,开发创造未来!
更多推荐


 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)