用 Amazon Bedrock 与 Anthropic Claude 3 打造智能文档处理方案
本文介绍如何利用Amazon Bedrock与Anthropic Claude 3 Sonnet模型构建智能文档处理(IDP)解决方案。该方案通过S3存储扫描文档,触发Lambda函数调用Claude 3模型提取数据,通过SQS队列缓冲后存储至DynamoDB,实现文档数据自动提取和结构化存储。架构整合了AWS多个托管服务,包括Bedrock的AI模型调用能力、S3的对象存储、Lambda的无服务
用 Amazon Bedrock 与 Anthropic Claude 3 打造智能文档处理方案
在数字化时代,企业每天要处理海量扫描文档,手动提取数据不仅耗时还易出错。而借助生成式 AI 技术,这一难题得以破解。本文将详细介绍如何利用 Amazon Bedrock 上的 Anthropic Claude 3 Sonnet 模型,构建一套智能文档处理(IDP)解决方案,实现从扫描文档数据提取到数据库存储的自动化流程。
方案核心价值与技术栈
生成式 AI 为智能文档处理带来革命性变革,能实现高级文档理解、结构化数据提取等功能,助力企业提升效率、降低成本。本方案采用的技术栈如下:
-
Amazon Bedrock:完全托管服务,可调用多种领先 AI 模型,简化 AI 应用开发。
-
Anthropic Claude 3 Sonnet:具备高效多模态能力,擅长处理视觉格式文档,支持多语言。
-
Amazon S3:高扩展性对象存储服务,用于存储扫描文档。
-
AWS Lambda:无服务器计算服务,实现代码运行无需管理服务器。
-
Amazon SQS:托管消息队列服务,实现组件间可靠通信。
-
Amazon DynamoDB:无服务器 NoSQL 数据库服务,用于存储提取的数据。
方案架构与工作流程
架构 overview
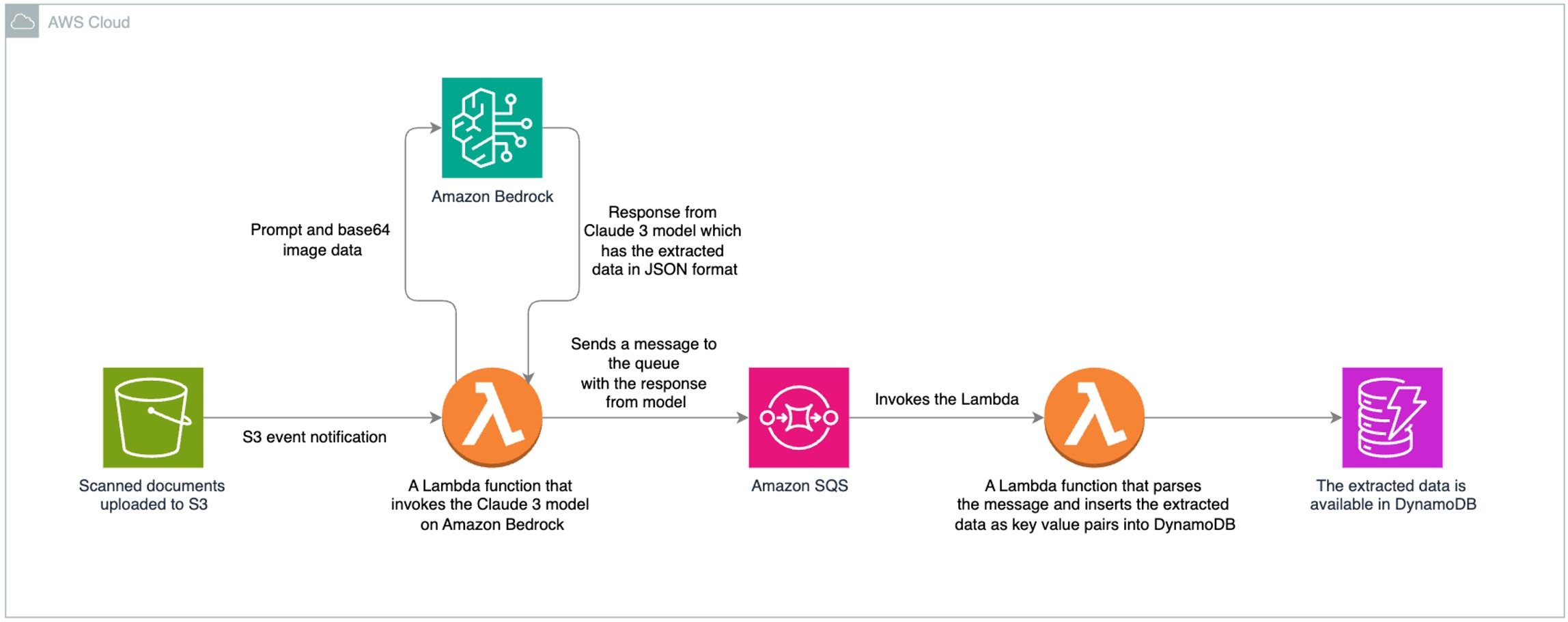
该方案架构通过各亚马逊云科技服务与 Anthropic Claude 3 Sonnet 模型的无缝集成,实现高效准确的文档数据处理。架构中,扫描文档上传至 S3 触发后续一系列自动化操作,最终将提取的数据存储到 DynamoDB。
详细工作步骤
-
文档上传与事件触发:将扫描文档上传到 Amazon S3 存储桶,上传操作会触发 S3 事件通知。
-
调用 AI 模型提取数据:S3 事件通知调用 Amazon Lambda 函数,该函数在 Amazon Bedrock 上调用 Anthropic Claude 3 Sonnet 模型,模型处理扫描文档并以 JSON 格式提取数据。
-
消息队列缓冲:提取的数据发送至 Amazon SQS 队列,SQS 作为缓冲区,保证组件间可靠通信,提升系统可扩展性与容错性。
-
数据存储到数据库:另一 Amazon Lambda 函数从 SQS 队列获取消息,解析 JSON 数据后,将提取的键值对存储到 Amazon DynamoDB 表。
方案实现步骤
前提条件
-
拥有亚马逊云科技账户,且 IAM 用户具备 DynamoDB、Lambda、Amazon Bedrock 等相关服务权限。
创建注册并登录亚马逊云科技账号:亚马逊云科技官网
亚马逊云科技近期推出了全新免费套餐(Free Tier 2.0),可以帮助开发者/企业用户更低成本、更轻松地上手云服务,新账户注册可领 $100 美元抵扣金,完成 5 个入门任务,每完成一项额外奖励 $20,最高再拿 $100,总抵扣金达 200 美元;
与旧版本对比,其优势如下,不过需要注意的是仅在海外区域可用哦(北京与宁夏为中国区域,其他为海外区域)
Free Tier 2.0(现行) Legacy Free Tier(旧版) 账户与支付 支持银联信用卡注册账户与人民币支付,无需外币信用卡。(2月份开始支持银联信用卡) 免费形态 账户分为两种计划:免费计划(确保 0 元,最长 6 个月或抵扣金用完)与付费计划(所有服务全量访问)。两种计划内均包括服务抵扣金,短期免费试用服务和永久免费服务。 三类优惠:Trials(短期试用)/ 12 个月免费 / 永久免费;到期或超额后按需计费。 金额机制 新用户最高 $200 亚马逊云科技抵扣金:注册 $100,完成 EC2/RDS/Lambda/Bedrock/Budgets 5个任务再得 $100。 以按服务配额为主(按月清零、不可跨服务挪用),没用到的配额会浪费。 误扣风险 免费计划不扣费(除非自愿升级),剩余抵扣金升级后在自注册起 12 个月内仍可用于合规服务。 容易因超出某服务配额而进入计费;新手对“超限”不敏感。 特点 专而深:抵扣金可集中投向你的刚需服务(示例:EC2 指定实例族、RDS、Lambda、Bedrock 等)。 广而浅:配额分布在很多服务,用不到的等于浪费,刚需服务的免费量相对有限。 -
获得 Amazon Bedrock 上 Anthropic Claude 3 Sonnet 模型的访问权限。
创建 S3 存储桶
-
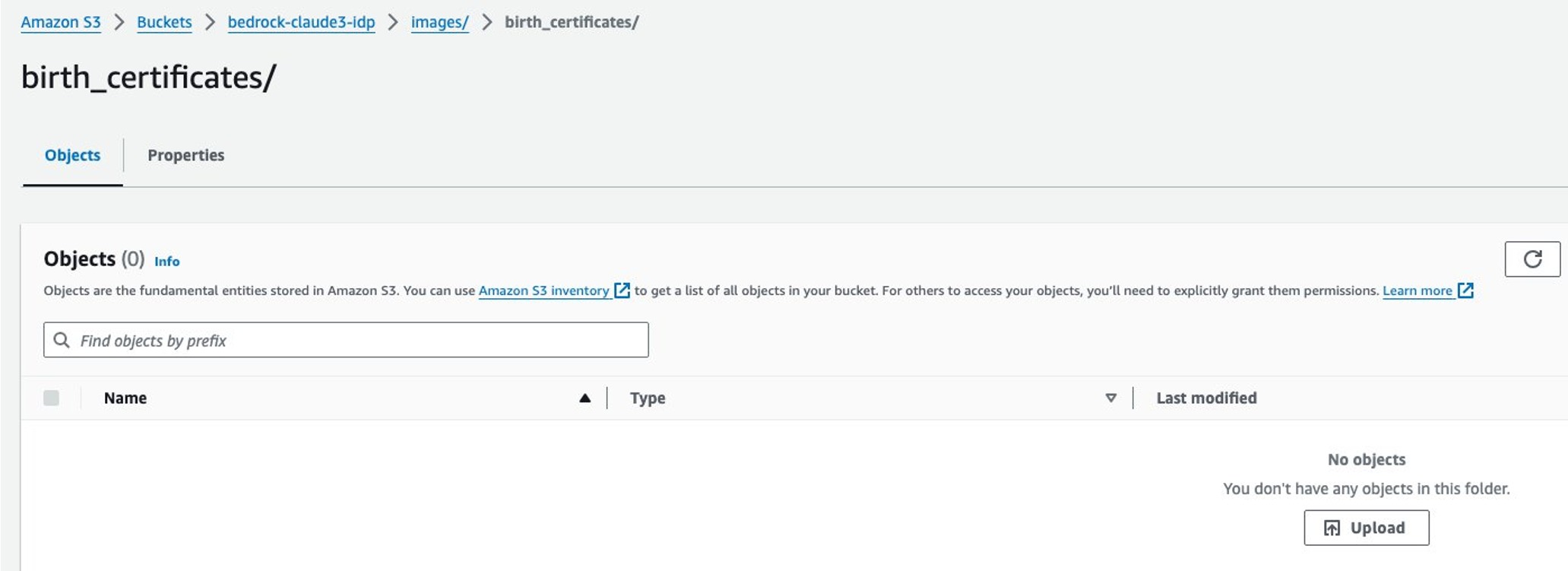
登录 Amazon S3 控制台,新建存储桶,名称需全局唯一(例如 bedrock-claude3-idp-872916),其他设置保持默认。
-
在新建的存储桶中,创建 “images” 文件夹,再在 “images” 文件夹下创建 “birth_certificates” 子文件夹,用于存放扫描文档。
创建 SQS 队列
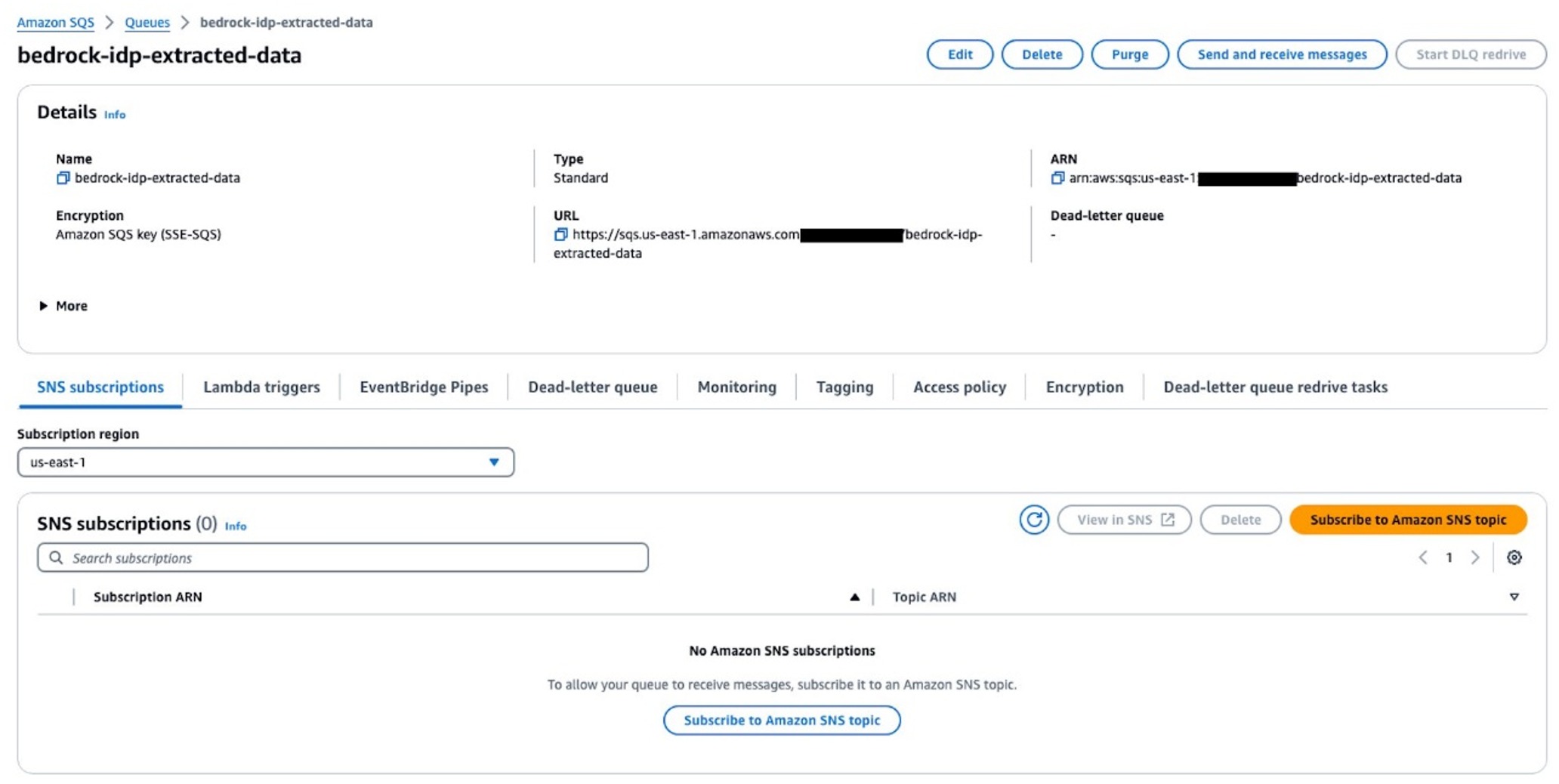
进入 Amazon SQS 控制台,创建标准队列,队列名称设为 “bedrock-idp-extracted-data”,其余设置默认,完成队列创建。
创建调用 Bedrock 模型的 Lambda 函数
-
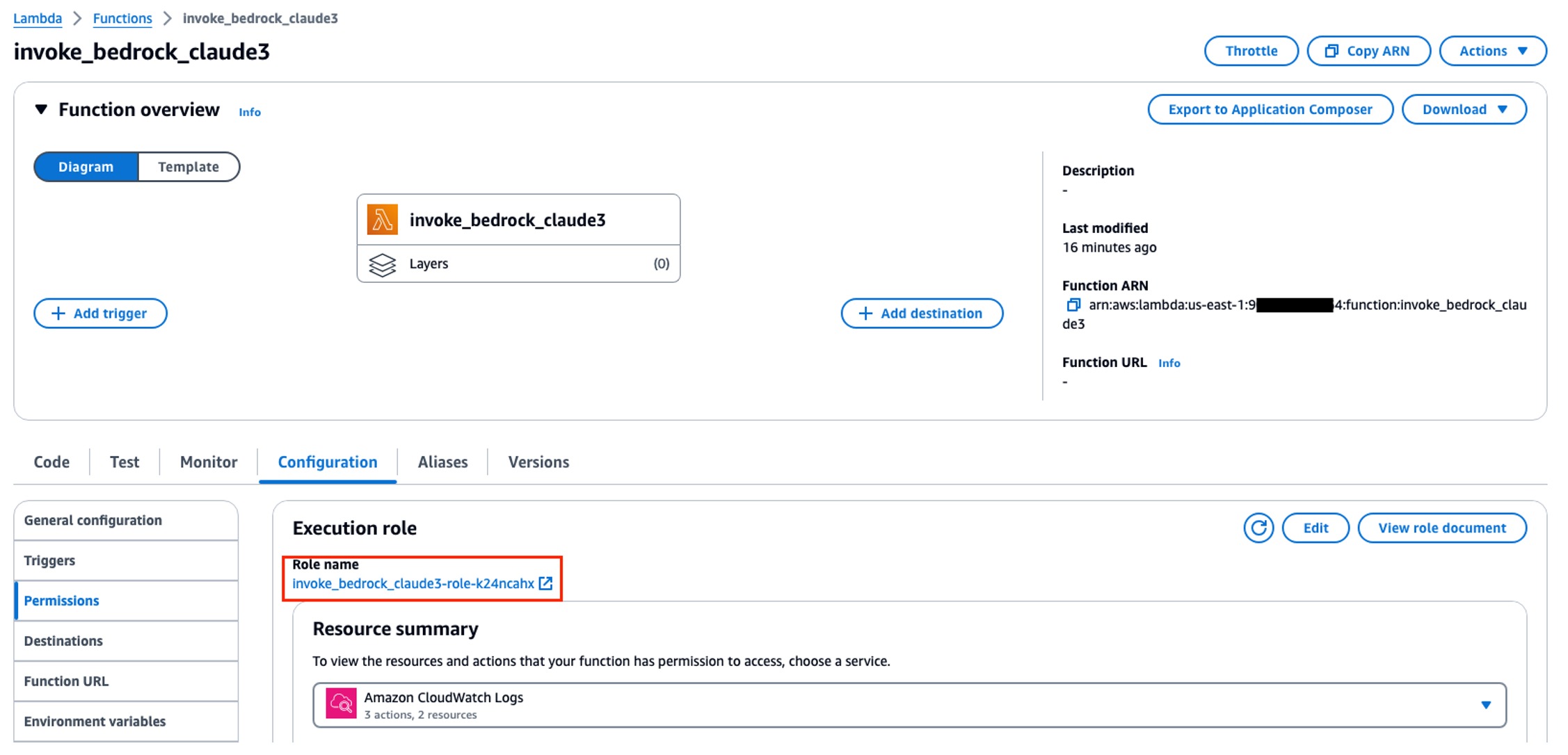
登录 Lambda 控制台,创建函数,名称为 “invoke_bedrock_claude3”,运行时选择 Python 3.12,其他设置默认。
-
替换函数代码:点击 “invoke_bedrock_claude3.py” 下载完整代码,将 lambda_function.py 文件内容替换为下载的代码,并将代码中的 “{SQS URL}” 替换为之前创建的 SQS 队列的 URL,然后点击 “部署”。核心代码如下:
import boto3
import base64
import json
# 初始化服务客户端
s3 = boto3.client('s3')
sqs = boto3.client('sqs')
bedrock = boto3.client('bedrock-runtime', region_name='us-east-1')
# 替换为你的SQS队列URL
QUEUE_URL = "https://sqs.us-east-1.amazonaws.com/123456789012/bedrock-idp-extracted-data"
MODEL_ID = "anthropic.claude-3-sonnet-20240229-v1:0"
def invoke_claude_3_multimodal(prompt, base64_image_data):
request_body = {
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": 2048,
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": prompt,
},
{
"type": "image",
"source": {
"type": "base64",
"media_type": "image/png",
"data": base64_image_data,
},
},
],
}
],
}
try:
response = bedrock.invoke_model(modelId=MODEL_ID, body=json.dumps(request_body))
return json.loads(response['body'].read())
except bedrock.exceptions.ClientError as err:
print(f"调用Claude 3 Sonnet失败,原因:{err.response['Error']['Code']}: {err.response['Error']['Message']}")
raise
def send_message_to_sqs(message_body):
try:
sqs.send_message(QueueUrl=QUEUE_URL, MessageBody=json.dumps(message_body))
except sqs.exceptions.ClientError as e:
print(f"向SQS发送消息错误:{e.response['Error']['Code']}: {e.response['Error']['Message']}")
def lambda_handler(event, context):
# 从事件中获取S3存储桶和对象信息
bucket_name = event['Records'][0]['s3']['bucket']['name']
object_key = event['Records'][0]['s3']['object']['key']
try:
# 从S3获取图像并转换为base64格式
image_data = s3.get_object(Bucket=bucket_name, Key=object_key)['Body'].read()
base64_image = base64.b64encode(image_data).decode('utf-8')
# 构建提示词
prompt = """
This image shows a birth certificate application form.
Please precisely copy all the relevant information from the form.
Leave the field blank if there is no information in corresponding field.
If the image is not a birth certificate application form, simply return an empty JSON object.
If the application form is not filled, leave the fees attributes blank.
Translate any non-English text to English.
Organize and return the extracted data in a JSON format with the following keys:
{
"applicantDetails":{
"applicantName": "",
"dayPhoneNumber": "",
"address": "",
"city": "",
"state": "",
"zipCode": "",
"email":""
},
"mailingAddress":{
"mailingAddressApplicantName": "",
"mailingAddress": "",
"mailingAddressCity": "",
"mailingAddressState": "",
"mailingAddressZipCode": ""
},
"relationToApplicant":[""],
"purposeOfRequest": "",
"BirthCertificateDetails":
{
"nameOnBirthCertificate": "",
"dateOfBirth": "",
"sex": "",
"cityOfBirth": "",
"countyOfBirth": "",
"mothersMaidenName": "",
"fathersName": "",
"mothersPlaceOfBirth": "",
"fathersPlaceOfBirth": "",
"parentsMarriedAtBirth": "",
"numberOfChildrenBornInSCToMother": "",
"diffNameAtBirth":""
},
"fees":{
"searchFee": "",
"eachAdditionalCopy": "",
"expediteFee": "",
"totalFees": ""
}
}
"""
# 调用Claude 3模型
model_response = invoke_claude_3_multimodal(prompt, base64_image)
# 将模型响应发送到SQS
send_message_to_sqs(model_response)
return {
'statusCode': 200,
'body': json.dumps('数据提取并发送到SQS成功')
}
except Exception as e:
print(f"处理过程中出现错误:{str(e)}")
return {
'statusCode': 500,
'body': json.dumps(f'处理失败:{str(e)}')
}
- 配置 Lambda 权限:
-
在 Lambda 控制台该函数页面,进入 “配置”->“权限”,选择对应的 IAM 角色。
-
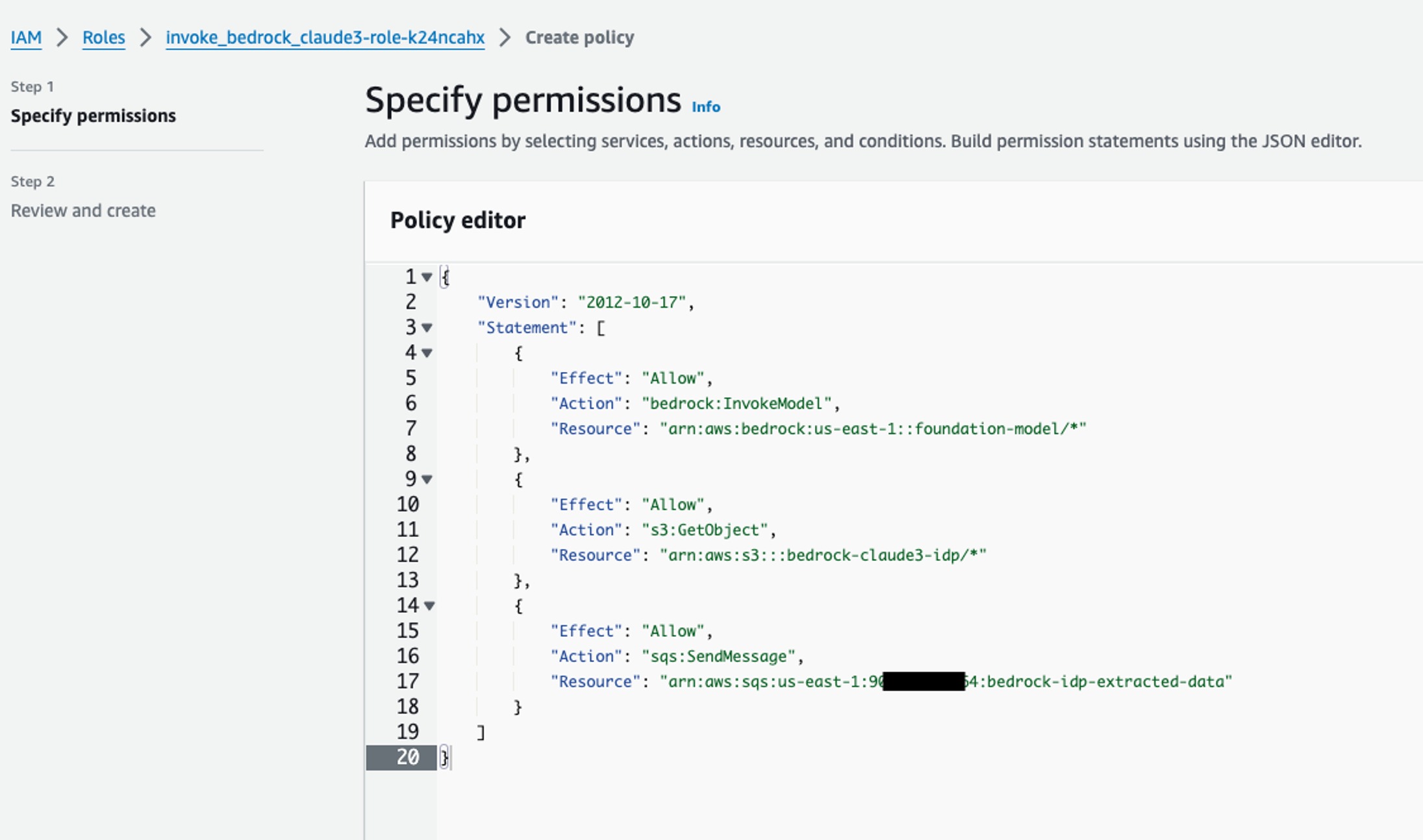
点击 “添加权限”->“创建内联策略”,在 JSON 编辑器中输入以下策略(将 {AWS Account ID} 和 {S3 Bucket Name} 替换为实际值):
{
"Version": "2012-10-17",
"Statement": \[{
"Effect": "Allow",
"Action": "bedrock:InvokeModel",
"Resource": "arn:aws:bedrock:us-east-1::foundation-model/\*"
}, {
"Effect": "Allow",
"Action": "s3:GetObject",
"Resource": "arn:aws:s3:::{S3 Bucket Name}/\*"
}, {
"Effect": "Allow",
"Action": "sqs:SendMessage",
"Resource": "arn:aws:sqs:us-east-1:{AWS Account ID}:bedrock-idp-extracted-data"
}]
}
- 输入策略名称(如 invoke_bedrock_claude3-role-policy),点击 “创建策略”。
- 修改 Lambda 超时时间:在 Lambda 函数 “配置”->“常规配置” 中,将超时时间修改为 2 分钟。
创建 S3 事件通知
-
进入之前创建的 S3 存储桶控制台,点击 “属性”。
-
在 “事件通知” 部分,点击 “创建事件通知”。
-
输入事件名称(如 bedrock-claude3-idp-event-notification),前缀输入 “images/birth_certificates/”,事件类型选择 “对象创建” 中的 “Put”,目标选择 “Lambda 函数” 并选择 “invoke_bedrock_claude3”,最后点击 “保存更改”。
创建 DynamoDB 表
登录 DynamoDB 控制台,创建表,表名为 “birth_certificates”,分区键设为 “Id”,其他设置默认,完成表的创建。
创建插入 DynamoDB 的 Lambda 函数
-
在 Lambda 控制台,创建函数,名称为 “insert_into_dynamodb”,运行时选择 Python 3.12,其他设置默认。
-
替换函数代码:点击 “insert_into_dynamodb.py” 下载完整代码,替换 lambda_function.py 文件内容,点击 “部署”。核心代码如下:
import boto3
import json
# 初始化DynamoDB资源
dynamodb = boto3.resource('dynamodb')
# 指定DynamoDB表
table = dynamodb.Table('birth_certificates')
# 初始化SQS客户端
sqs = boto3.client('sqs')
# 替换为你的SQS队列URL
SQS_QUEUE_URL = "https://sqs.us-east-1.amazonaws.com/123456789012/bedrock-idp-extracted-data"
def lambda_handler(event, context):
try:
# 从SQS事件中获取消息
for record in event['Records']:
# 解析SQS消息体
message_body = record['body']
message_id = record['messageId']
model_response = json.loads(message_body)
# 提取模型响应中的文本数据(JSON格式)
extracted_text = model_response['content'][0]['text']
extracted_data = json.loads(extracted_text)
# 从提取的数据中获取各字段信息
applicant_details = extracted_data.get('applicantDetails', {})
mailing_address = extracted_data.get('mailingAddress', {})
relation_to_applicant = extracted_data.get('relationToApplicant', [])
birth_certificate_details = extracted_data.get('BirthCertificateDetails', {})
fees = extracted_data.get('fees', {})
# 将数据插入DynamoDB表
table.put_item(
Item={
'Id': message_id,
'applicantName': applicant_details.get('applicantName', ''),
'dayPhoneNumber': applicant_details.get('dayPhoneNumber', ''),
'address': applicant_details.get('address', ''),
'city': applicant_details.get('city', ''),
'state': applicant_details.get('state', ''),
'zipCode': applicant_details.get('zipCode', ''),
'email': applicant_details.get('email', ''),
'mailingAddressApplicantName': mailing_address.get('mailingAddressApplicantName', ''),
'mailingAddress': mailing_address.get('mailingAddress', ''),
'mailingAddressCity': mailing_address.get('mailingAddressCity', ''),
'mailingAddressState': mailing_address.get('mailingAddressState', ''),
'mailingAddressZipCode': mailing_address.get('mailingAddressZipCode', ''),
'relationToApplicant': ', '.join(relation_to_applicant),
'purposeOfRequest': extracted_data.get('purposeOfRequest', ''),
'nameOnBirthCertificate': birth_certificate_details.get('nameOnBirthCertificate', ''),
'dateOfBirth': birth_certificate_details.get('dateOfBirth', ''),
'sex': birth_certificate_details.get('sex', ''),
'cityOfBirth': birth_certificate_details.get('cityOfBirth', ''),
'countyOfBirth': birth_certificate_details.get('countyOfBirth', ''),
'mothersMaidenName': birth_certificate_details.get('mothersMaidenName', ''),
'fathersName': birth_certificate_details.get('fathersName', ''),
'mothersPlaceOfBirth': birth_certificate_details.get('mothersPlaceOfBirth', ''),
'fathersPlaceOfBirth': birth_certificate_details.get('fathersPlaceOfBirth', ''),
'parentsMarriedAtBirth': birth_certificate_details.get('parentsMarriedAtBirth', ''),
'numberOfChildrenBornInSCToMother': birth_certificate_details.get('numberOfChildrenBornInSCToMother', ''),
'diffNameAtBirth': birth_certificate_details.get('diffNameAtBirth', ''),
'searchFee': fees.get('searchFee', ''),
'eachAdditionalCopy': fees.get('eachAdditionalCopy', ''),
'expediteFee': fees.get('expediteFee', ''),
'totalFees': fees.get('totalFees', '')
}
)
# 处理成功后删除SQS消息
sqs.delete_message(
QueueUrl=SQS_QUEUE_URL,
ReceiptHandle=record['receiptHandle']
)
return {
'statusCode': 200,
'body': json.dumps('数据成功插入DynamoDB并删除SQS消息')
}
except Exception as e:
print(f"处理过程中出现错误:{str(e)}")
return {
'statusCode': 500,
'body': json.dumps(f'处理失败:{str(e)}')
}
- 配置 Lambda 权限:
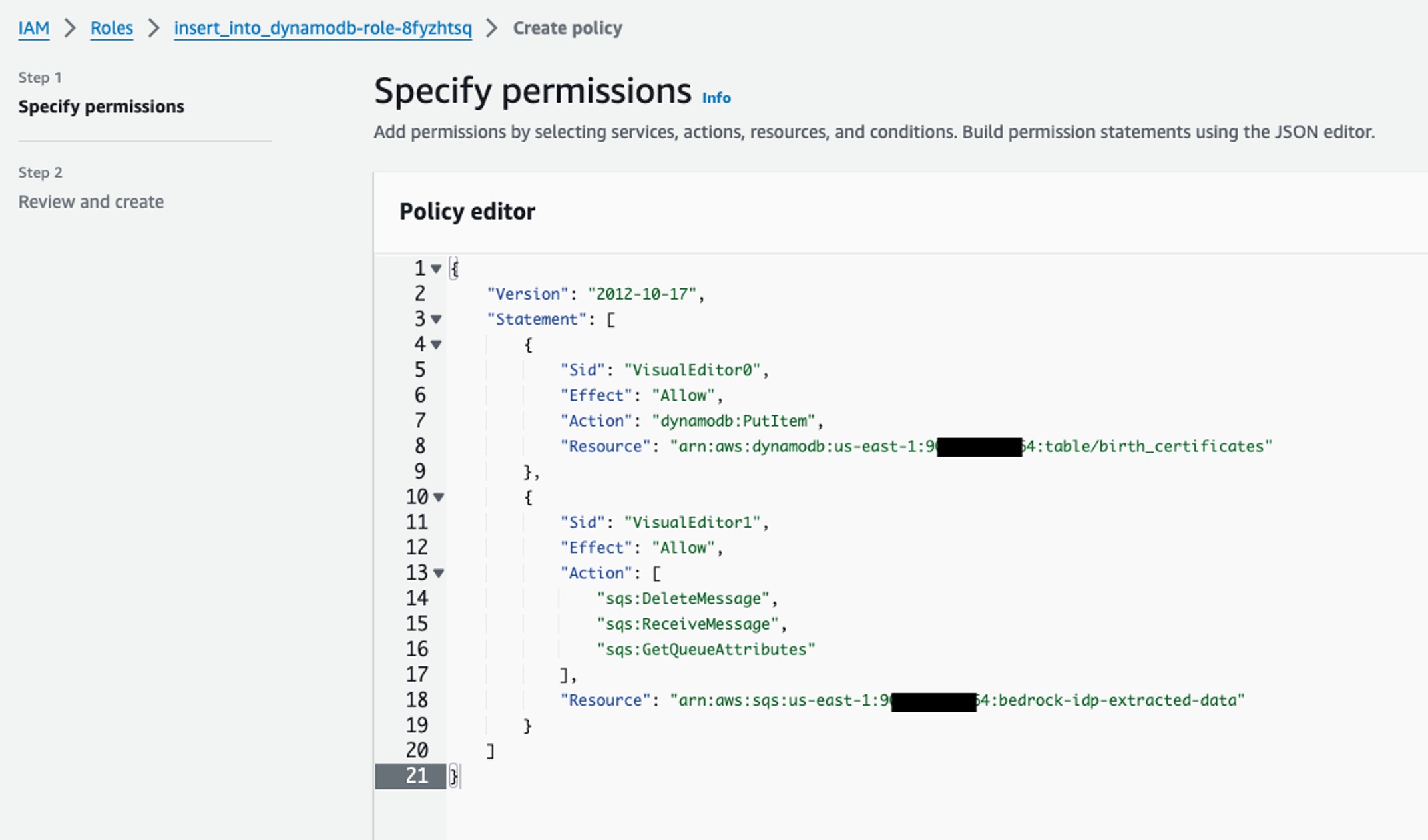
- 类似之前的操作,进入该 Lambda 函数的 IAM 角色页面,创建内联策略,输入以下 JSON(将 {AWS Account ID} 替换为实际值):
{
"Version": "2012-10-17",
"Statement": \[
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": "dynamodb:PutItem",
"Resource": "arn:aws:dynamodb:us-east-1:{AWS Account ID}:table/birth\_certificates"
},
{
"Sid": "VisualEditor1",
"Effect": "Allow",
"Action": \[
"sqs:DeleteMessage",
"sqs:ReceiveMessage",
"sqs:GetQueueAttributes"
],
"Resource": "arn:aws:sqs:us-east-1:{AWS Account ID}:bedrock-idp-extracted-data"
}
]
}
- 输入策略名称(如 insert_into_dynamodb-role-policy),点击 “创建策略”。
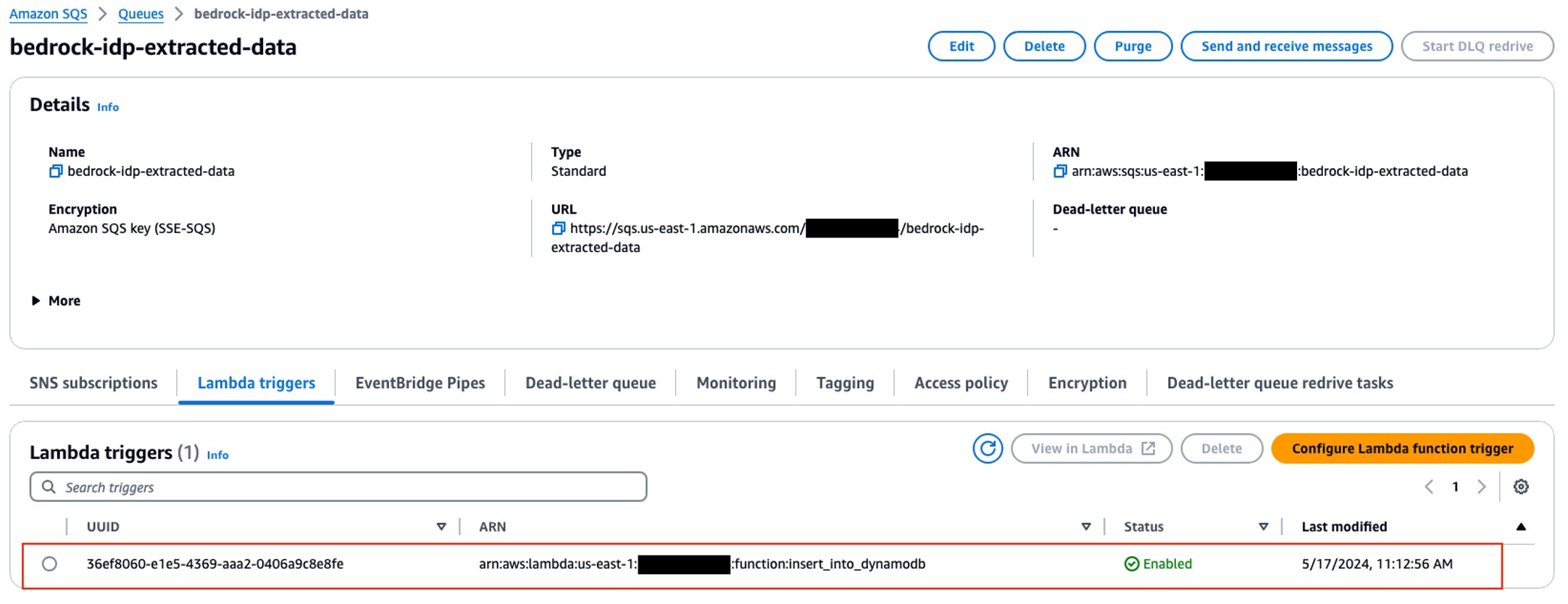
配置 Lambda 的 SQS 触发器
-
进入 Amazon SQS 控制台,打开 “bedrock-idp-extracted-data” 队列。
-
在 “Lambda 触发器” 选项卡,点击 “配置 Lambda 服务触发器”。
-
选择 “insert_into_dynamodb” Lambda 函数,点击 “保存”。
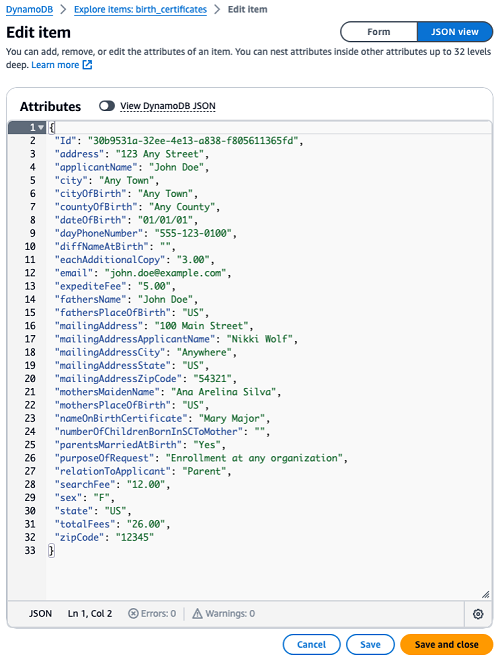
方案测试
-
准备测试文档:将英语手写版(english-hand-written.jpeg)和西班牙语打印版(spanish-printed.jpeg)的出生证明申请表图像保存到本地。
-
上传文档:在 S3 存储桶的 “images/birth_certificates” 文件夹中,上传上述两张图像。
-
查看结果:登录 DynamoDB 控制台,浏览 “birth_certificates” 表中的项目。若配置正确,数秒内会看到表中新增两个项目,且西班牙语表格的内容已自动翻译成英语。
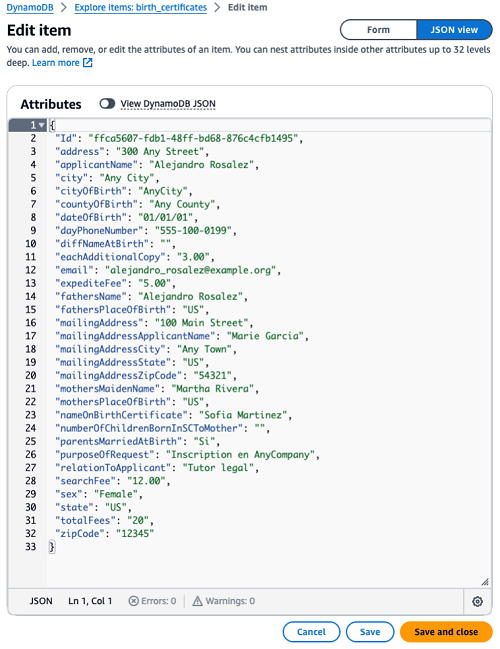
故障排除
若在 DynamoDB 表中未看到提取的数据,可按以下方法排查:
-
检查 CloudWatch 日志:查看相关 Lambda 函数的 Amazon CloudWatch 日志流,寻找错误消息或异常,定位问题根源。
-
检查权限:确认 Lambda 函数是否拥有访问 DynamoDB 表、S3 存储桶等相关资源的必要权限。
-
使用死信队列:在生产环境中,建议配置死信队列(DLQ),捕获处理失败的事件或消息,便于后续分析和处理。
总结与优化方向
本文展示了基于 Amazon Bedrock 和 Anthropic Claude 3 Sonnet 模型的 IDP 解决方案实现过程,该方案能有效实现扫描文档数据的自动化提取与存储。但方案效果受文档复杂度、质量等因素影响,并非适用于所有 IDP 场景。
后续可从以下方面优化方案:
-
引入人在环工作流:对于关键或敏感应用,加入人工审查环节,确保数据准确性,符合监管要求。
-
模型评估与选择:利用 Amazon Bedrock 的模型评估功能,对比不同模型输出,选择最适合自身应用的模型。
-
边缘场景测试:加强对复杂、特殊格式文档的测试,完善异常处理机制。
-
提示词优化与模型微调:通过优化提示词和微调模型,进一步提升数据提取准确性和效率。

一座年轻的奋斗人之城,一个温馨的开发者之家。在这里,代码改变人生,开发创造未来!
更多推荐


 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)