基于AI Agent的智能决策支持系统建模方法与优化策略研究
在复杂环境中,决策往往受到多种因素的影响。传统的决策支持系统(Decision Support System, DSS)依赖于专家经验和固定规则,难以应对动态变化的场景。随着人工智能(AI)的快速发展,基于AI Agent的智能决策支持系统逐渐成为提升决策效率与准确性的核心技术。
基于AI Agent的智能决策支持系统建模方法与优化策略研究
一、引言
在复杂环境中,决策往往受到多种因素的影响。传统的决策支持系统(Decision Support System, DSS)依赖于专家经验和固定规则,难以应对动态变化的场景。随着人工智能(AI)的快速发展,基于AI Agent的智能决策支持系统逐渐成为提升决策效率与准确性的核心技术。
AI Agent通过感知环境、推理和自适应优化,实现了从 数据驱动 → 知识建模 → 策略优化 的完整闭环,为金融、医疗、交通、供应链等行业提供了强大的智能化支撑。
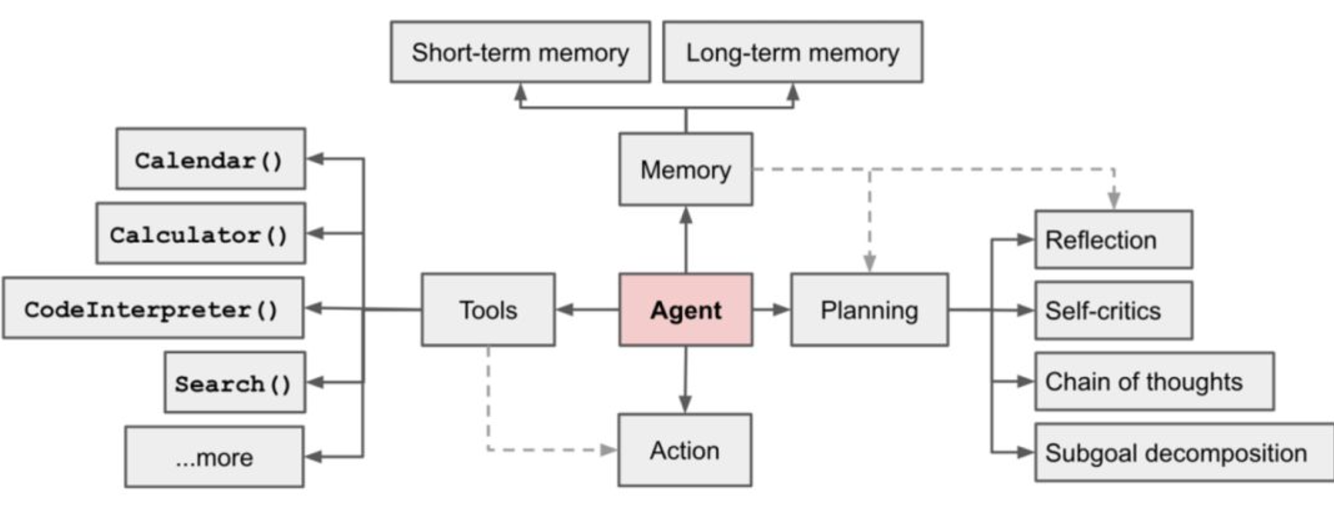
二、AI Agent决策支持系统的架构
一个典型的基于AI Agent的决策支持系统主要包括以下模块:
- 感知层:负责数据采集与环境建模(如传感器数据、业务系统日志、市场行情)。
- 认知层:利用机器学习和知识图谱进行语义理解和推理。
- 决策层:基于强化学习、博弈论等方法生成最优策略。
- 执行层:将决策结果应用于实际业务流程,并进行反馈。
架构示意:
数据源 → 感知层 → 认知层 → 决策层 → 执行层 → 环境反馈
三、智能决策的建模方法
3.1 基于规则的建模
早期DSS主要依靠规则库(if-else逻辑),适合于静态和低复杂度场景。
3.2 基于机器学习的建模
利用监督学习或无监督学习模型(如分类、聚类、预测),实现数据驱动的决策。
3.3 基于强化学习的建模
强化学习(Reinforcement Learning, RL)特别适合需要动态交互与长期最优收益的场景,如自动驾驶、智能调度。
四、AI Agent的优化方法
4.1 策略优化
采用强化学习中的 策略梯度(Policy Gradient) 或 价值迭代(Value Iteration) 提升Agent的决策性能。
4.2 多Agent协同优化
在复杂场景(如交通网络、供应链),多个AI Agent需要博弈与协同,通过**多智能体强化学习(MARL)**实现整体最优。
4.3 元学习与迁移学习
让AI Agent具备跨场景迁移能力,减少新环境下的训练成本。
五、代码实战:基于强化学习的AI Agent决策支持示例
下面给出一个简化的 Python 示例,模拟一个 库存管理决策支持系统:
- Agent 需要决定每天的进货量。
- 目标是 最大化利润,同时避免缺货和库存积压。
import numpy as np
import random
# 环境定义:库存管理
class InventoryEnv:
def __init__(self, max_inventory=50, demand_mean=20):
self.max_inventory = max_inventory
self.demand_mean = demand_mean
self.reset()
def reset(self):
self.inventory = self.max_inventory // 2
return self.inventory
def step(self, action):
# action = 当日进货量
self.inventory += action
demand = np.random.poisson(self.demand_mean) # 随机需求
sales = min(self.inventory, demand)
self.inventory -= sales
# 奖励函数 = 销售利润 - 库存成本
reward = sales * 10 - self.inventory * 2
return self.inventory, reward
# 简单Q-learning Agent
class QLearningAgent:
def __init__(self, state_size, action_size, lr=0.1, gamma=0.9, epsilon=0.2):
self.q_table = np.zeros((state_size, action_size))
self.lr = lr
self.gamma = gamma
self.epsilon = epsilon
self.action_size = action_size
def choose_action(self, state):
if random.uniform(0,1) < self.epsilon:
return random.randint(0, self.action_size-1)
return np.argmax(self.q_table[state])
def learn(self, state, action, reward, next_state):
predict = self.q_table[state, action]
target = reward + self.gamma * np.max(self.q_table[next_state])
self.q_table[state, action] += self.lr * (target - predict)
# 训练过程
env = InventoryEnv()
agent = QLearningAgent(state_size=51, action_size=6) # 动作为进货0~5单位
episodes = 200
for ep in range(episodes):
state = env.reset()
total_reward = 0
for _ in range(30): # 模拟30天
action = agent.choose_action(state)
next_state, reward = env.step(action)
agent.learn(state, action, reward, next_state)
state = next_state
total_reward += reward
if ep % 20 == 0:
print(f"Episode {ep}, Total Reward: {total_reward}")
print("训练完成,Q表前5行:")
print(agent.q_table[:5])
代码解析:
- InventoryEnv:定义库存环境,包括进货、需求、销售逻辑。
- QLearningAgent:基于Q-learning算法的决策Agent。
- 训练过程:模拟多个周期,Agent不断学习最优的进货策略。
六、应用场景
- 医疗:辅助医生选择最佳诊疗方案。
- 金融:为投资组合优化提供策略建议。
- 交通:实现智能交通信号控制,缓解拥堵。
- 供应链:动态优化库存与物流调度。
七、结论与展望
基于AI Agent的智能决策支持系统正在逐步取代传统规则驱动的DSS,在动态、复杂和不确定性环境中展现出强大的适应性。未来,随着 大模型+强化学习+多智能体博弈 的结合,智能决策支持系统将更加自主化、精准化与可信化。

纵情码海钱塘涌,杭州开发者创新动! 属于杭州的开发者社区!致力于为杭州地区的开发者提供学习、合作和成长的机会;同时也为企业交流招聘提供舞台!
更多推荐

 10
10 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)