Kubernetes基础
Pod 容器组 是一个k8s中一个抽象的概念,用于存放一组 container(可包含一个或多个 container 容器,即图上正方体),以及这些 container (容器)的一些共享资源。这些资源包括:共享存储,称为卷(Volumes),即图上紫色圆柱网络,每个 Pod(容器组)在集群中有个唯一的 IP,pod(容器组)中的 container(容器)共享该IP地址container(容器)
一.k8s的概念
Kubernetes(简称 k8s)是一个开源的容器编排引擎,它可以自动化部署、扩展和管理容器化应用。它提供了强大的功能,如自动调度、弹性伸缩、服务发现、负载均衡等,使得容器化应用的部署和管理更加高效、可靠和便捷。通过 k8s,你可以轻松地在不同的环境中运行和管理大规模的容器化应用,提高开发和运维效率。
在Docker 作为高级容器引擎快速发展的同时,在Google内部,容器技术已经应用了很多年
Borg系统运行管理着成千上万的容器应用。
Kubernetes项目来源于Borg,可以说是集结了Borg设计思想的精华,并且吸收了Borg系统中的经验和教训。
Kubernetes对计算资源进行了更高层次的抽象,通过将容器进行细致的组合,将最终的应用服务交给用户。
kubernetes的本质是一组服务器集群,它可以在集群的每个节点上运行特定的程序,来对节点中的容器进行管理。目的是实现资源管理的自动化,主要提供了如下的主要功能:
自我修复:一旦某一个容器崩溃,能够在1秒中左右迅速启动新的容器
弹性伸缩:可以根据需要,自动对集群中正在运行的容器数量进行调整
服务发现:服务可以通过自动发现的形式找到它所依赖的服务
负载均衡:如果一个服务起动了多个容器,能够自动实现请求的负载均衡
版本回退:如果发现新发布的程序版本有问题,可以立即回退到原来的版本
存储编排:可以根据容器自身的需求自动创建存储卷
k8s各个组件及用途
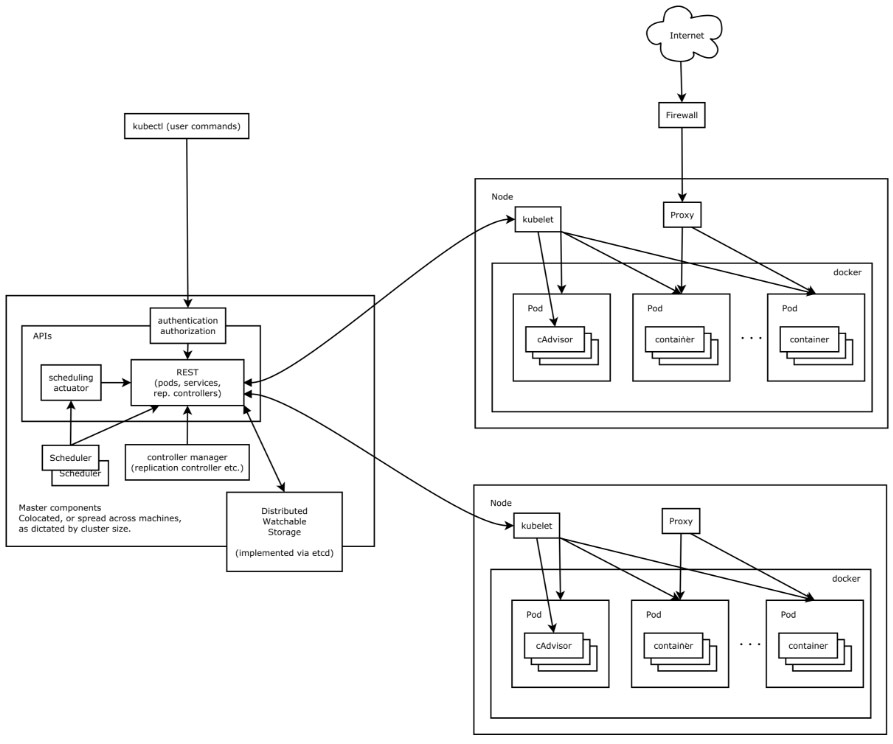
一个kubernetes集群主要是由控制节点(master)、工作节点(node)构成,每个节点上都会安装不同的组件。
1 、master:集群的控制平面,负责集群的决策
ApiServer : 资源操作的唯一入口,接收用户输入的命令,提供认证、授权、API注册和发现等机制
Scheduler : 负责集群资源调度,按照预定的调度策略将Pod调度到相应的node节点上
ControllerManager : 负责维护集群的状态,比如程序部署安排、故障检测、自动扩展、滚动更新等
Etcd :负责存储集群中各种资源对象的信息
2 、node:集群的数据平面,负责为容器提供运行环境
kubelet:负责维护容器的生命周期,同时也负责Volume(CVI)和网络(CNI)的管理
Container runtime:负责镜像管理以及Pod和容器的真正运行(CRI)
kube-proxy:负责为Service提供cluster内部的服务发现和负载均衡
k8s各组件之间的调用关系
当我们要运行一个web服务时:
kubernetes环境启动之后,master和node都会将自身的信息存储到etcd数据库中
web服务的安装请求会首先被发送到master节点的apiServer组件
apiServer组件会调用scheduler组件来决定到底应该把这个服务安装到哪个node节点上
在此时,它会从etcd中读取各个node节点的信息,然后按照一定的算法进行选择,并将结果告知apiServer
apiServer调用controller-manager去调度Node节点安装web服务
kubelet接收到指令后,会通知docker,然后由docker来启动一个web服务的pod
如果需要访问web服务,就需要通过kube-proxy来对pod产生访问的代理
k8s常用名词概念
Master:集群控制节点,每个集群需要至少一个master节点负责集群的管控
Node:工作负载节点,由master分配容器到这些node工作节点上,然后node节点上的
Pod:kubernetes的最小控制单元,容器都是运行在pod中的,一个pod中可以有1个或者多个容器
Controller:控制器,通过它来实现对pod的管理,比如启动pod、停止pod、伸缩pod的数量等等
Service:pod对外服务的统一入口,下面可以维护者同一类的多个pod
Label:标签,用于对pod进行分类,同一类pod会拥有相同的标签
NameSpace:命名空间,用来隔离pod的运行环境
k8s的分层架构
核心层:Kubernetes最核心的功能,对外提供API构建高层的应用,对内提供插件式应用执行环境
应用层:部署(无状态应用、有状态应用、批处理任务、集群应用等)和路由(服务发现、DNS解析等)
管理层:系统度量(如基础设施、容器和网络的度量),自动化(如自动扩展、动态Provision等)以及策略管理(RBAC、Quota、PSP、NetworkPolicy等)
接口层:kubectl命令行工具、客户端SDK以及集群联邦
生态系统:在接口层之上的庞大容器集群管理调度的生态系统,可以划分为两个范畴
Kubernetes外部:日志、监控、配置管理、CI、CD、Workflow、FaaS、OTS应用、ChatOps等
Kubernetes内部:CRI、CNI、CVI、镜像仓库、Cloud Provider、集群自身的配置和管理等
Kubernetes 架构图
分层架构
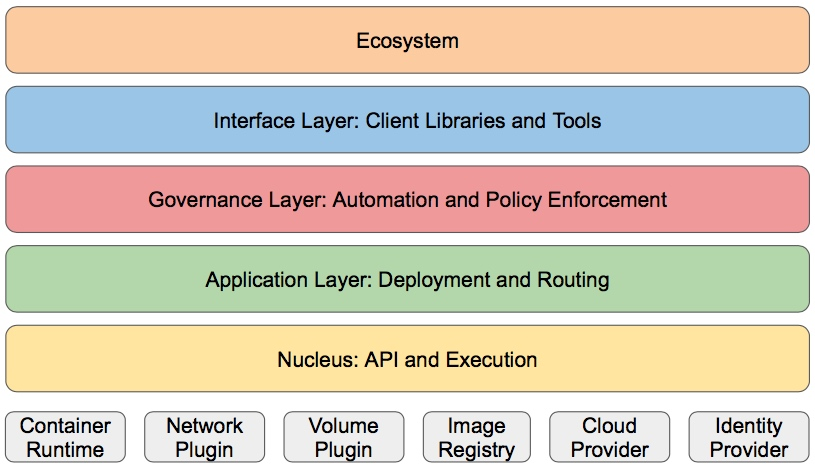
生态系统
在接口层之上的庞大容器集群管理调度的生态系统,可以划分为两个范畴:
Kubernetes 外部:日志、监控、配置管理、CI、CD、Workflow、FaaS、OTS 应用、ChatOps 等
Kubernetes 内部:CRI、CNI、CVI、镜像仓库、Cloud Provider、集群自身的配置和管理等
接口层: kubectl 命令行工具、客户端 SDK 以及集群联邦
管理层 : 系统度量(如基础设施、容器和网络的度量),自动化(如自动扩展、动态 Provision 等)以及策略管理(RBAC、Quota、PSP、NetworkPolicy 等)
应用层:部署(无状态应用、有状态应用、批处理任务、集群应用等)和路由(服务发现、DNS 解析等)
核心层:Kubernetes 最核心的功能,对外提供 API 构建高层的应用,对内提供插件式应用执行环境
二.K8s部署说明
1、主机操作系统说明
| 序号 | 操作系统及版本 | |
|---|---|---|
| 1 | RHEL9 |
2、主机硬件配置说明
| 主机名 | ip | 角色 |
| reg.timinglee.org | 192.168.163.10 | harbor仓库 |
| master | 192.168.163.11 | master,k8s集群控制节点 |
| node1 | 192.168.163.12 | worker,k8s集群工作节点 |
|
node2 |
192.168.163.13 | worker,k8s集群工作节点 |
七、操作准备(四台机器·同时操作)
-
所有节点禁用selinux和防火墙
-
所有节点同步时间和解析
-
所有节点安装docker-ce
-
所有节点禁用swap,注意注释掉/etc/fstab文件中的定义
所有k8s集群节点执行以下步骤
1.所有禁用swap和本地解析
systemctl mask swap.target
swapoff -a
vim /etc/fstab
#
# /etc/fstab
# Created by anaconda on Sun Feb 19 17:38:40 2023
#
# Accessible filesystems, by reference, are maintained under '/dev/disk'
# See man pages fstab(5), findfs(8), mount(8) and/or blkid(8) for more info
#
/dev/mapper/rhel-root / xfs defaults 0 0
UUID=ddb06c77-c9da-4e92-afd7-53cd76e6a94a /boot xfs defaults 0 0
#/dev/mapper/rhel-swap swap swap defaults 0 0
/dev/cdrom /media iso9660 defaults 0 0
所有主机安装docker
[root@k8s-master ~]# vim /etc/yum.repos.d/docker.repo
[docker]
name=docker
baseurl=https://mirrors.aliyun.com/docker-ce/linux/rhel/9/x86_64/stable/
gpgcheck=0
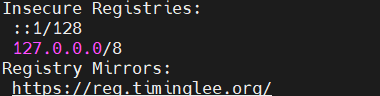
所有节点设定harbor仓库的域名地址为默认仓库源
vim /etc/docker/daemon.json
{
"registry-mirrors":["https://reg.timinglee.org"]
} [root@master ~]# vim /lib/systemd/system/docker.service
harbor仓库配置
[root@reg packages]# tar -zxf harbor-offline-installer-v2.5.4.tgz
[root@reg packages]# mkdir -p /data/certs[root@reg packages]# openssl req -newkey rsa:4096 -nodes -sha256 -keyout /data/certs/timinglee.org.key -addext "subjectAltName = DNS:reg.timinglee.org" -x509 -days 365 -out /data/certs/timinglee.org.crt
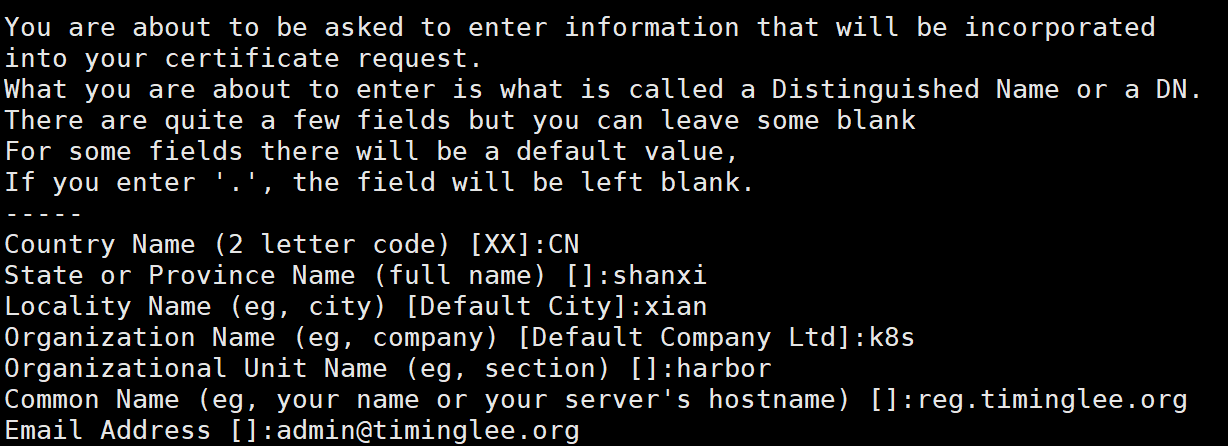
[root@reg harbor]# cp harbor.yml.tmpl harbor.yml
[root@reg harbor]# vim harbor.yml
复制harbor仓库中的证书并启动docker
[root@k8s-harbor ~]# cp /etc/docker/certs.d/reg.timinglee.org/ca.crt root@192.168.234.10:/etc/docker/certs.d/reg.timinglee.org/ca.crt
[root@k8s-harbor ~]# cp /etc/docker/certs.d/reg.timinglee.org/ca.crt root@192.168.234.20:/etc/docker/certs.d/reg.timinglee.org/ca.crt
[root@k8s-harbor ~]# cp /etc/docker/certs.d/reg.timinglee.org/ca.crt root@192.168.234.100:/etc/docker/certs.d/reg.timinglee.org/ca.crt
[root@k8s-harbor ~]# systemctl enable --now docker
#登陆harbor仓库
[root@k8s-master ~]# docker login reg.timinglee.org
[root@master ~]# docker info
三台主机上都要安装K8S部署工具
[root@master ~]# ls
anaconda-ks.cfg
cri-dockerd-0.3.14-3.el8.x86_64.rpm
k8s-1.30.tar.gz
libcgroup-0.41-19.el8.x86_64.rpm
[root@k8s-master ~]# vim /lib/systemd/system/cri-docker.service
[root@master ~]# systemctl enable --now cri-docker.service
Created symlink
/etc/systemd/system/multi-user.target.wants/cri-docker.service → /u
sr/lib/systemd/system/cri-docker.service.
[root@master ~]# 设置kubectl命令补齐功能
[root@k8s-master ~]# dnf install bash-completion -y
[root@k8s-master ~]# echo "source <(kubectl completion bash)" >> ~/.bashrc
[root@k8s-master ~]# source ~/.bashrc上传镜像到harbor仓库
[root@master ~]# docker load -i k8s_docker_images-1.30.tar
3d6fa0469044: Loading layer 327.7kB/327.7kB
49626df344c9: Loading layer 40.96kB/40.96kB
945d17be9a3e: Loading layer 2.396MB/2.396MB
4d049f83d9cf: Loading layer 1.536kB/1.536kB
af5aa97ebe6c: Loading layer 2.56kB/2.56kB
ac805962e479: Loading layer 2.56kB/2.56kB
bbb6cacb8c82: Loading layer 2.56kB/2.56kB
2a92d6ac9e4f: Loading layer 1.536kB/1.536kB
1a73b54f556b: Loading layer 10.24kB/10.24kB
f4aee9e53c42: Loading layer 3.072kB/3.072kB
b336e209998f: Loading layer 238.6kB/238.6kB
06ddf169d3f3: Loading layer 1.69MB/1.69MB
c0cb02961a3c: Loading layer 112.9MB/112.9MB
Loaded image: registry.aliyuncs.com/google_containers/kube-apiserver:v1.30.0 [root@master ~]# docker images
REPOSITORY
ED SIZE
registry.aliyuncs.com/google_containers/kube-apiserver TAG IMAG
nths ago 117MB v1.30.0 c42f
registry.aliyuncs.com/google_containers/kube-controller-manager
nths ago 111MB v1.30.0 c7aa
registry.aliyuncs.com/google_containers/kube-scheduler
nths ago 62MB v1.30.0 259c
registry.aliyuncs.com/google_containers/kube-proxy
nths ago 84.7MB v1.30.0 a0bf
registry.aliyuncs.com/google_containers/etcd 3.5.12-0 3861
nths ago 149MB
registry.aliyuncs.com/google_containers/coredns v1.11.1 cbb0
nths ago 59.8MB
registry.aliyuncs.com/google_containers/pause 3.9 e6f1
rs ago 744kB
[root@master ~]# [root@k8s-master ~]# docker images | awk '/google/{ print $1":"$2}' \
| awk -F "/" '{system("docker tag "$0" reg.timinglee.org/k8s/"$3)}'
[root@master ~]# docker images | awk '/reg/{print $1":"$2}'
reg.timinglee.org/k8s/kube-apiserver:v1.30.0
registry.aliyuncs.com/google_containers/kube-apiserver:v1.30.0
reg.timinglee.org/k8s/kube-controller-manager:v1.30.0
registry.aliyuncs.com/google_containers/kube-controller-manager:v1.30.0
registry.aliyuncs.com/google_containers/kube-scheduler:v1.30.0
reg.timinglee.org/k8s/kube-scheduler:v1.30.0
reg.timinglee.org/k8s/kube-proxy:v1.30.0
registry.aliyuncs.com/google_containers/kube-proxy:v1.30.0
reg.timinglee.org/k8s/etcd:3.5.12-0
registry.aliyuncs.com/google_containers/etcd:3.5.12-0
registry.aliyuncs.com/google_containers/coredns:v1.11.1
reg.timinglee.org/k8s/coredns:v1.11.1
reg.timinglee.org/k8s/pause:3.9
registry.aliyuncs.com/google_containers/pause:3.9
[root@master ~]# 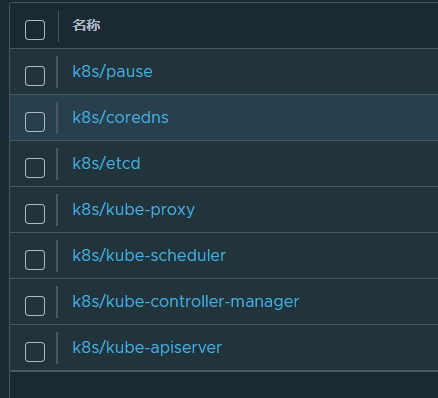
[root@master ~]# systemctl enable kubelet --now #所有主机都要记得重启
集群初始化
#执行初始化命令
[root@k8s-master ~]# kubeadm init --pod-network-cidr=10.244.0.0/16 \
--image-repository reg.timinglee.org/k8s \
--kubernetes-version v1.30.0 \
--cri-socket=unix:///var/run/cri-dockerd.sock
#指定集群配置文件变量
[root@k8s-master ~]# echo "export KUBECONFIG=/etc/kubernetes/admin.conf" >> ~/.bash_profile#当前节点没有就绪,因为还没有安装网络插件,容器没有运行
安装flannel网络插件
[root@master ~]# docker load -i flannel-0.25.5.tag.gz
ef7a14b43c43: Loading layer 8.079MB/8.079MB
1d9375ff0a15: Loading layer 9.222MB/9.222MB
4af63c5dc42d: Loading layer
16.61MB/16.61MB
2b1d26302574: Loading layer 1.544MB/1.544MB
d3dd49a2e686: Loading layer 42.11MB/42.11MB
7278dc615b95: Loading layer 5.632kB/5.632kB
c09744fc6e92: Loading layer 6.144kB/6.144kB
0a2b46a5555f: Loading layer 1.923MB/1.923MB
5f70bf18a086: Loading layer
1.024kB/1.024kB
601effcb7aab: Loading layer
1.928MB/1.928MB
21692b7dc30c:
Loading layer
Loaded image: flannel/flannel:v0.25.5
Loaded image: flannel/flannel-cni-plugin:v1.5.1-flannel1
2.634MB/2.634MB
[root@master ~]# 在harbor仓库上创建一个flannel
#上传镜像到仓库
[root@k8s-master ~]# docker tag flannel/flannel:v0.25.5 \
reg.timinglee.org/flannel/flannel:v0.25.5
[root@k8s-master ~]# docker push reg.timinglee.org/flannel/flannel:v0.25.5
[root@k8s-master ~]# docker tag flannel/flannel-cni-plugin:v1.5.1-flannel1 \
reg.timinglee.org/flannel/flannel-cni-plugin:v1.5.1-flannel1
[root@k8s-master ~]# docker push reg.timinglee.org/flannel/flannel-cni-plugin:v1.5.1-flannel1
#编辑kube-flannel.yml 修改镜像下载位置
[root@k8s-master ~]# vim kube-flannel.yml
146: image: reg.timinglee.org/flannel/flannel:v0.25.5
173: image: reg.timinglee.org/flannel/flannel-cni-plugin:v1.5.1-flannel1
184: image: reg.timinglee.org/flannel/flannel:v0.25.5
[root@k8s-master ~]# kubectl apply -f kube-flannel.yml节点扩容
#在此阶段如果生成的集群token找不到了可以重新生成
[root@k8s-master ~]# kubeadm token create --print-join-command
kubeadm join 172.25.254.100:6443 --token 5hwptm.zwn7epa6pvatbpwf --discovery-token-ca-cert-hash sha256:52f1a83b70ffc8744db5570288ab51987ef2b563bf906ba4244a300f61e9db23[root@k8s-node1 & 2 ~]# kubeadm join 192.168.234.10:6443 --token 5hwptm.zwn7epa6pvatbpwf --discovery-token-ca-cert-hash sha256:52f1a83b70ffc8744db5570288ab51987ef2b563bf906ba4244a300f61e9db23 --cri-socket=unix:///var/run/cri-dockerd.sock #在node1和node2上操作
部署完成!!!
服务部署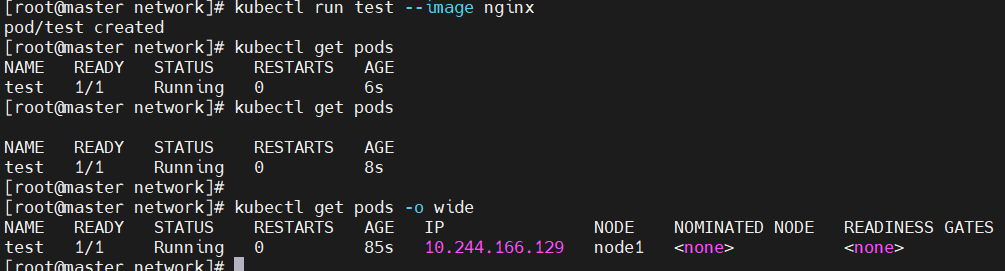
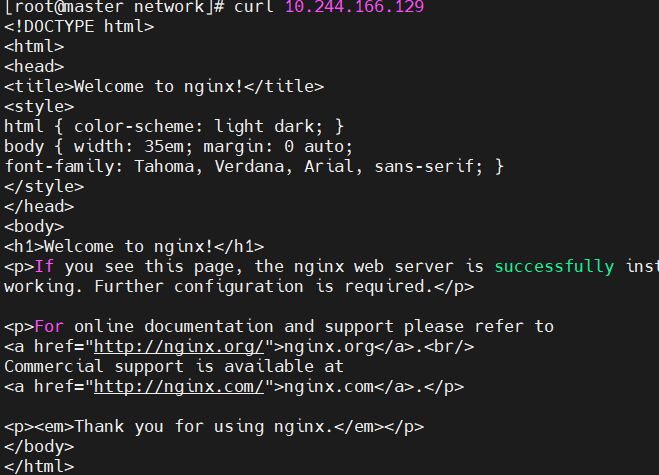
四、K8s的pod概述和配置
Pod 容器组 是一个k8s中一个抽象的概念,用于存放一组 container(可包含一个或多个 container 容器,即图上正方体),以及这些 container (容器)的一些共享资源。这些资源包括:
共享存储,称为卷(Volumes),即图上紫色圆柱
网络,每个 Pod(容器组)在集群中有个唯一的 IP,pod(容器组)中的 container(容器)共享该IP地址
container(容器)的基本信息,例如容器的镜像版本,对外暴露的端口等
每个Pod中都可以包含一个或者多个容器,这些容器可以分为两类:
用户程序所在的容器,数量可多可少
Pause容器,这是每个Pod都会有的一个根容器,它的作用有两个:
可以以它为依据,评估整个Pod的健康状态
可以在根容器上设置Ip地址,其它容器都此Ip(Pod IP),以实现Pod内部的网路通信
pod的定义
apiVersion: v1 #必选,版本号,例如v1
kind: Pod #必选,资源类型,例如 Pod
metadata: #必选,元数据
name: string #必选,Pod名称
namespace: string #Pod所属的命名空间,默认为"default"
labels: #自定义标签列表
- name: string
spec: #必选,Pod中容器的详细定义
containers: #必选,Pod中容器列表
- name: string #必选,容器名称
image: string #必选,容器的镜像名称
imagePullPolicy: [ Always|Never|IfNotPresent ] #获取镜像的策略
command: [string] #容器的启动命令列表,如不指定,使用打包时使用的启动命令
args: [string] #容器的启动命令参数列表
workingDir: string #容器的工作目录
volumeMounts: #挂载到容器内部的存储卷配置
- name: string #引用pod定义的共享存储卷的名称,需用volumes[]部分定义的的卷名
mountPath: string #存储卷在容器内mount的绝对路径,应少于512字符
readOnly: boolean #是否为只读模式
ports: #需要暴露的端口库号列表
- name: string #端口的名称
containerPort: int #容器需要监听的端口号
hostPort: int #容器所在主机需要监听的端口号,默认与Container相同
protocol: string #端口协议,支持TCP和UDP,默认TCP
env: #容器运行前需设置的环境变量列表
- name: string #环境变量名称
value: string #环境变量的值
resources: #资源限制和请求的设置
limits: #资源限制的设置
cpu: string #Cpu的限制,单位为core数,将用于docker run --cpu-shares参数
memory: string #内存限制,单位可以为Mib/Gib,将用于docker run --memory参数
requests: #资源请求的设置
cpu: string #Cpu请求,容器启动的初始可用数量
memory: string #内存请求,容器启动的初始可用数量
lifecycle: #生命周期钩子
postStart: #容器启动后立即执行此钩子,如果执行失败,会根据重启策略进行重启
preStop: #容器终止前执行此钩子,无论结果如何,容器都会终止
livenessProbe: #对Pod内各容器健康检查的设置,当探测无响应几次后将自动重启该容器
exec: #对Pod容器内检查方式设置为exec方式
command: [string] #exec方式需要制定的命令或脚本
httpGet: #对Pod内个容器健康检查方法设置为HttpGet,需要制定Path、port
path: string
port: number
host: string
scheme: string
HttpHeaders:
- name: string
value: string
tcpSocket: #对Pod内个容器健康检查方式设置为tcpSocket方式
port: number
initialDelaySeconds: 0 #容器启动完成后首次探测的时间,单位为秒
timeoutSeconds: 0 #对容器健康检查探测等待响应的超时时间,单位秒,默认1秒
periodSeconds: 0 #对容器监控检查的定期探测时间设置,单位秒,默认10秒一
次
successThreshold: 0
failureThreshold: 0
securityContext:
privileged: false
restartPolicy: [Always | Never | OnFailure] #Pod的重启策略
nodeName: <string> #设置NodeName表示将该Pod调度到指定到名称的node节点上
nodeSelector: obeject #设置NodeSelector表示将该Pod调度到包含这个label的node上
imagePullSecrets: #Pull镜像时使用的secret名称,以key:secretkey格式指定
- name: string
hostNetwork: false #是否使用主机网络模式,默认为false,如果设置为true,表示使用宿主机
网络
volumes: #在该pod上定义共享存储卷列表
- name: string #共享存储卷名称 (volumes类型有很多种)
emptyDir: {} #类型为emtyDir的存储卷,与Pod同生命周期的一个临时目录。为空值
hostPath: string #类型为hostPath的存储卷,表示挂载Pod所在宿主机的目录
path: string #Pod所在宿主机的目录,将被用于同期中mount的目录
secret: #类型为secret的存储卷,挂载集群与定义的secret对象到容器内部
scretname: string
items:
- key: string
path: string
configMap: #类型为configMap的存储卷,挂载预定义的configMap对象到容器内部
name: string
items:
- key: string
path: string配置
基本配置
创建nginxpod.yaml,写入
apiVersion: v1
kind: Namespace
metadata:
name: dev
---
apiVersion: v1
kind: Pod
metadata:
name: nginxpod
namespace: dev
spec:
containers:
- name: nginx-containers
image: nginx:1.17.1镜像拉取
在nginxpod.yaml添加
apiVersion: v1
kind: Namespace
metadata:
name: dev
---
apiVersion: v1
kind: Pod
metadata:
name: nginxpod
namespace: dev
spec:
containers:
- name: nginx-containers
image: nginx:1.17.1
imagePullPolicy: Always #设置镜像拉取策略为alwaysimagePullPolicy,用于设置镜像拉取策略,kubernetes支持配置三种拉取策略:
Always:总是从远程仓库拉取镜像(一直远程下载)
IfNotPresent:本地有则使用本地镜像,本地没有则从远程仓库拉取镜像(本地有就本地 本地没远程下载)
Never:只使用本地镜像,从不去远程仓库拉取,本地没有就报错 (一直使用本地)
[root@k8s-master01 nginx]# kubectl delete -f nginxpod.yaml #先删除
namespace "dev" deleted
pod "nginxpod" deleted
[root@k8s-master01 nginx]# kubectl create -f nginxpod.yaml #再创建
namespace/dev created
pod/nginxpod created
[root@k8s-master01 nginx]# kubectl describe pod nginxpod -n dev #查看创建pod详情
Name: nginxpod
Namespace: dev
Priority: 0
Service Account: default
Node: k8s-worker02/192.168.234.14
Start Time: Sun, 23 Mar 2025 21:34:57 +0800
Labels: <none>
Annotations: cni.projectcalico.org/containerID: b3e8244aebfa692ac22dfc5a2bb e17931600f1253537454a521adb4da7d547dd
cni.projectcalico.org/podIP: 100.73.45.88/32
cni.projectcalico.org/podIPs: 100.73.45.88/32
Status: Running
IP: 100.73.45.88
IPs:
IP: 100.73.45.88
Containers:
nginx-containers:
Container ID: docker://f24c8c0bff883217f8730d42669a47acbc8800a1e8ca44738b4 fb285eb2a5f4a
Image: nginx:1.17.1
Image ID: docker-pullable://nginx@sha256:b4b9b3eee194703fc2fa8afa5b751 0c77ae70cfba567af1376a573a967c03dbb
Port: <none>
Host Port: <none>
State: Running
Started: Sun, 23 Mar 2025 21:35:01 +0800
Ready: True
Restart Count: 0
Environment: <none>
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from kube-api-access-dn4zd ( ro)
Conditions:
Type Status
PodReadyToStartContainers True
Initialized True
Ready True
ContainersReady True
PodScheduled True
Volumes:
kube-api-access-dn4zd:
Type: Projected (a volume that contains injected data fro m multiple sources)
TokenExpirationSeconds: 3607
ConfigMapName: kube-root-ca.crt
ConfigMapOptional: <nil>
DownwardAPI: true
QoS Class: BestEffort
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute op=Exists fo r 300s
node.kubernetes.io/unreachable:NoExecute op=Exists for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 50s default-scheduler Successfully assigned dev/nginxpod to k8s-worker02
Normal Pulling 22m kubelet Pulling image "nginx:1.17.1"
Normal Pulled 22m kubelet Successfully pulled image "nginx:1 .17.1" in 2.636s (2.636s including waiting). Image size: 109357455 bytes.
Normal Created 22m kubelet Created container nginx-containers
Normal Started 22m kubelet Started container nginx-containers端口设置
[root@k8s-master01 nginx]# kubectl explain pod.spec.containers.ports
KIND: Pod
VERSION: v1
RESOURCE: ports <[]Object>
FIELDS:
name <string> # 端口名称,如果指定,必须保证name在pod中是唯一的
containerPort<integer> # 容器要监听的端口(0<x<65536)
hostPort <integer> # 容器要在主机上公开的端口,如果设置,主机上只能运行容器的一个副
本(一般省略)
hostIP <string> # 要将外部端口绑定到的主机IP(一般省略)
protocol <string> # 端口协议。必须是UDP、TCP或SCTP。默认为“TCP”创建pod-ports.yam
apiVersion: v1
kind: Pod
metadata:
name: pod-ports
namespace: dev
spec:
containers:
- name: nginx
image: nginx:1.17.1
ports: # 设置容器暴露的端口列表
- name: nginx-port
containerPort: 80
protocol: TCP资源配额
容器中的程序要运行,肯定是要占用一定资源的,比如cpu和内存等,如果不对某个容器的资源做限
制,那么它就可能吃掉大量资源,导致其它容器无法运行。针对这种情况,kubernetes提供了对内存和
cpu的资源进行配额的机制,这种机制主要通过resources选项实现,他有两个子选项:
limits:用于限制运行时容器的最大占用资源,当容器占用资源超过limits时会被终止,并进行重启
requests :用于设置容器需要的最小资源,如果环境资源不够,容器将无法启动
可以通过上面两个选项设置资源的上下限。
创建pod-resources.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-resources
namespace: dev
spec:
containers:
- name: nginx
image: nginx:1.17.1
resources:
limits:
cpu: "2"
memory: "2Gi" # 调整后的内存限制
requests:
cpu: "1"
memory: "10Mi" # 调整后的内存请求
- cpu:core数,可以为整数或小数 memory:
- 内存大小,可以使用Gi、Mi、G、M等形式
# 运行Pod [root@master ~]# kubectl create -f pod-resources.yaml pod/pod-resources created # 查看发现pod运行正常 [root@master ~]# kubectl get pod pod-resources -n dev NAME READY STATUS RESTARTS AGE pod-resources 1/1 Running 0 39s # 接下来,停止Pod [root@master ~]# kubectl delete -f pod-resources.yaml pod "pod-resources" deleted # 编辑pod,修改resources.requests.memory的值为10Gi [root@master ~]# vim pod-resources.yaml # 再次启动pod [root@master ~]# kubectl create -f pod-resources.yaml pod/pod-resources created # 查看Pod状态,发现Pod启动失败 [root@master ~]# kubectl get pod pod-resources -n dev -o wide NAME READY STATUS RESTARTS AGE pod-resources 0/2 Pending 0 20s # 查看pod详情会发现,如下提示 [root@master ~]# kubectl describe pod pod-resources -n dev ...... Warning FailedScheduling <unknown> default-scheduler 0/2 nodes are available: 2 Insufficient memory.(内存不足)K8s控制器之Deployment
概述Deployment 是最常用的用于部署无状态服务的方式。Deployment 控制器使得您能够以声明的方式更新 Pod(容器组)和 ReplicaSet(副本集)。该控制器并不直接管理pod,而是通过管理ReplicaSet来间接管理Pod,即:Deployment管 理ReplicaSet,ReplicaSet管理Pod。所以Deployment比ReplicaSet功能更加强大。
Deployment 为我们确定了如下几种运维场景:
创建 Deployment : 创建 Deployment 后,Deployment 控制器将立刻创建一个 ReplicaSet 副本集,并由 ReplicaSet 创建所需要的 Pod。
更新 Deployment: 更新 Deployment 中 Pod 的定义(例如,发布新版本的容器镜像)。此时 Deployment 控制器将为该 Deployment 创建一个新的 ReplicaSet 副本集,并且逐步在新的副本集中创建 Pod,在旧的副本集中删除 Pod,以达到滚动更新的效果。
回滚Deployment: 回滚到一个早期 Deployment 版本。
伸缩Deployment: 水平扩展 Deployment,以便支持更大的负载,或者水平收缩 Deployment,以便节省服务器资源。
暂停和继续Deployment
查看Deployment状态
清理策略
金丝雀发布
Deployment配置详情
apiVersion: apps/v1 # 版本号
kind: Deployment # 类型
metadata: # 元数据
name: # rs名称
namespace: # 所属命名空间
labels: #标签
controller: deploy
spec: # 详情描述
replicas: 3 # 副本数量
revisionHistoryLimit: 3 # 保留历史版本
paused: false # 暂停部署,默认是false
progressDeadlineSeconds: 600 # 部署超时时间(s),默认是600
strategy: # 策略
type: RollingUpdate # 滚动更新策略
rollingUpdate: # 滚动更新
maxSurge: 30% # 最大额外可以存在的副本数,可以为百分比,也可以为整数
maxUnavailable: 30% # 最大不可用状态的 Pod 的最大值,可以为百分比,也可以为整数
selector: # 选择器,通过它指定该控制器管理哪些pod
matchLabels: # Labels匹配规则
app: nginx-pod
matchExpressions: # Expressions匹配规则
- {key: app, operator: In, values: [nginx-pod]}
template: # 模板,当副本数量不足时,会根据下面的模板创建pod副本
metadata:
labels:
app: nginx-pod
spec:
containers:
- name: nginx
image: nginx:1.17.1
ports:
- containerPort: 80创建Deployment
下面的 yaml 文件定义了一个 Deployment,该 Deployment 将创建一个有 3 个 nginx Pod 副本的 ReplicaSet(副本集):
apiVersion: apps/v1
kind: Deployment
metadata:
name: deployment
namespace: dev
spec:
replicas: 3
selector:
matchLabels:
app: nginx-pod
template:
metadata:
labels:
app: nginx-pod
spec:
containers:
- name: nginx
image: nginx:1.17.1在这个例子中:
将创建一个名为 deployment 的 Deployment(部署),名称由 .metadata.name 字段指定
该 Deployment 将创建 3 个 Pod 副本,副本数量由 .spec.replicas 字段指定
.spec.selector 字段指定了 Deployment 如何找到由它管理的 Pod。此案例中,我们使用了 Pod template 中定义的一个标签(app: nginx-pod)。对于极少数的情况,这个字段也可以定义更加复杂的规则
.template 字段包含了如下字段:
.template.metadata.labels 字段,指定了 Pod 的标签(app: nginx-pod)
.template.spec.containers[].image 字段,表明该 Pod 运行一个容器 nginx:1.17.1
.template.spec.containers[].name 字段,表明该容器的名字是 nginx
# 创建deployment
[root@k8s-master01 dev]# kubectl create -f deployment.yaml
deployment.apps/deployment created
# 查看deployment
[root@k8s-master01 dev]# kubectl get deployments.apps -n dev
NAME READY UP-TO-DATE AVAILABLE AGE
deployment 3/3 3 3 6m37s
#查看rs
[root@k8s-master01 dev]# kubectl get rs -n dev
NAME DESIRED CURRENT READY AGE
deployment-7cffcbf558 3 3 3 8m36s
# 发现rs的名称是在原来deployment的名字后面添加了一个10位数的随机串
# 查看pod
[root@k8s-master01 dev]# kubectl get pod -n dev
NAME READY STATUS RESTARTS AGE
deployment-7cffcbf558-m8qw7 1/1 Running 0 10m
deployment-7cffcbf558-nhhth 1/1 Running 0 10m
deployment-7cffcbf558-xwxhw 1/1 Running 0 10m伸缩 Deployment
# 变更副本数量为5个
[root@k8s-master01 dev]# kubectl scale deployment deployment-test --replicas 5 -n dev
deployment.apps/deployment-test scaled
# 查看deployment
[root@k8s-master01 dev]# kubectl get deployments.apps deployment-test -n dev
NAME READY UP-TO-DATE AVAILABLE AGE
deployment-test 5/5 5 5 5m26s
# 查看pod
[root@k8s-master01 dev]# kubectl get pod -n dev
NAME READY STATUS RESTARTS AGE
deployment-test-7cffcbf558-46hg7 1/1 Running 0 6m16s
deployment-test-7cffcbf558-5vjqw 1/1 Running 0 6m16s
deployment-test-7cffcbf558-fj846 1/1 Running 0 114s
deployment-test-7cffcbf558-mdz8q 1/1 Running 0 114s
deployment-test-7cffcbf558-ws965 1/1 Running 0 6m16s
# 编辑deployment的副本数量,修改spec:replicas: 3
[root@k8s-master01 dev]# kubectl edit deployments.apps deployment-test -n dev
deployment.apps/deployment-test edited
# 查看pod
[root@k8s-master01 dev]# kubectl get pod -n dev
NAME READY STATUS RESTARTS AGE
deployment-test-7cffcbf558-46hg7 1/1 Running 0 8m37s
deployment-test-7cffcbf558-5vjqw 1/1 Running 0 8m37s
deployment-test-7cffcbf558-mdz8q 1/1 Running 0 4m15s更新 Deployment
deployment支持两种更新策略: 重建更新 和 滚动更新 ,可以通过 strategy 指定策略类型,支持两个属性:
strategy:指定新的Pod替换旧的Pod的策略, 支持两个属性:
type:指定策略类型,支持两种策略
Recreate:在创建出新的Pod之前会先杀掉所有已存在的Pod
RollingUpdate:滚动更新,就是杀死一部分,就启动一部分,在更新过程中,存在两个版本Pod
rollingUpdate:当type为RollingUpdate时生效,用于为RollingUpdate设置参数,支持两个属
性:
maxUnavailable:用来指定在升级过程中不可用Pod的最大数量,默认为25%。
maxSurge: 用来指定在升级过程中可以超过期望的Pod的最大数量,默认为25%重建更新
重建部署策略是先把旧的pod全部停掉,然后新建pod。由于部署期间出现服务中断,这种部署策略很少用。
在spec节点下添加更新策略
spec:
strategy: # 策略
type: Recreate # 重建更新创建deploy进行验证
#修改镜像
[root@k8s-master01 dev]# kubectl set image deployment deployment-test nginx=nginx:1.17.2 -n dev
deployment.apps/deployment-test image updated
#查看更新后的 Deployment 的详情
[root@k8s-master01 dev]# kubectl get deployments.apps -n dev -o wide
NAME READY UP-TO-DATE AVAILABLE AGE CONTAINERS IMAGES SELECTOR
deployment-test 3/3 3 3 39m nginx nginx:1.17.2 app=nginx-pod
滚动更新
在spec节点下添加更新策略
spec:
strategy: # 策略
type: RollingUpdate # 滚动更新策略
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%创建deploy进行验证
#修改镜像
[root@k8s-master01 dev]# kubectl set image deployment deployment-test nginx=nginx:1.17.3 -n dev
deployment.apps/deployment-test image updated
[root@k8s-master01 dev]# kubectl get deployments.apps -n dev -o wide
NAME READY UP-TO-DATE AVAILABLE AGE CONTAINERS IMAGES SELECTOR
deployment-test 3/3 3 3 55m nginx nginx:1.17.3 app=nginx-pod
#滚动更新是通过创建一个新的 3 个副本数的 ReplicaSet 并同时将旧的 Replicaset 的副本数缩容到 0 个副本 来达成的。
[root@k8s-master01 dev]# kubectl get rs -n dev
NAME DESIRED CURRENT READY AGE
deployment-test-5b6ffdcd8d 3 3 3 5m37s
deployment-test-79dbdc995f 0 0 0 30m
deployment-test-7cffcbf558 0 0 0 56m
Deployment 将确保更新过程中,任意时刻只有一定数量的 Pod 被关闭。默认情况下,Deployment 确保至少 .spec.replicas 的 75% 的 Pod 保持可用(25% max unavailable)
Deployment 将确保更新过程中,任意时刻只有一定数量的 Pod 被创建。默认情况下,Deployment 确保最多 .spec.replicas 的 25% 的 Pod 被创建(25% max surge)
Deployment Controller 先创建一个新 Pod,然后删除一个旧 Pod,然后再创建新的,如此循环,直到全部更新。Deployment Controller 不会 kill 旧的 Pod,除非足够数量的新 Pod 已经就绪,Deployment Controller 也不会创新新 Pod 直到足够数量的旧 Pod 已经被 kill。
#查看 Deployment 详情
[root@k8s-master01 dev]# kubectl describe deployments.apps
Name: deployment-test
Namespace: dev
CreationTimestamp: Sat, 05 Apr 2025 19:28:48 +0800
Labels: <none>
Annotations: deployment.kubernetes.io/revision: 3
Selector: app=nginx-pod
Replicas: 3 desired | 3 updated | 3 total | 3 available | 0 unavailable
StrategyType: RollingUpdate
MinReadySeconds: 0
RollingUpdateStrategy: 25% max unavailable, 25% max surge
Pod Template:
Labels: app=nginx-pod
Containers:
nginx:
Image: nginx:1.17.3
Port: <none>
Host Port: <none>
Environment: <none>
Mounts: <none>
Volumes: <none>
Node-Selectors: <none>
Tolerations: <none>
Conditions:
Type Status Reason
---- ------ ------
Available True MinimumReplicasAvailable
Progressing True NewReplicaSetAvailable
OldReplicaSets: deployment-test-7cffcbf558 (0/0 replicas created), deployment-test-79dbdc995f (0/0 replicas created)
NewReplicaSet: deployment-test-5b6ffdcd8d (3/3 replicas created)
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal ScalingReplicaSet 60m deployment-controller Scaled up replica set deployment-test-7cffcbf558 to 3
Normal ScalingReplicaSet 55m deployment-controller Scaled up replica set deployment-test-7cffcbf558 to 5 from 3
Normal ScalingReplicaSet 52m deployment-controller Scaled down replica set deployment-test-7cffcbf558 to 3 from 5
Normal ScalingReplicaSet 34m deployment-controller Scaled down replica set deployment-test-7cffcbf558 to 0 from 3
Normal ScalingReplicaSet 34m deployment-controller Scaled up replica set deployment-test-79dbdc995f to 3
Normal ScalingReplicaSet 9m5s deployment-controller Scaled up replica set deployment-test-5b6ffdcd8d to 1
Normal ScalingReplicaSet 7m37s deployment-controller Scaled down replica set deployment-test-79dbdc995f to 2 from 3
Normal ScalingReplicaSet 7m37s deployment-controller Scaled up replica set deployment-test-5b6ffdcd8d to 2 from 1
Normal ScalingReplicaSet 6m8s deployment-controller Scaled down replica set deployment-test-79dbdc995f to 1 from 2
Normal ScalingReplicaSet 6m8s deployment-controller Scaled up replica set deployment-test-5b6ffdcd8d to 3 from 2
Normal ScalingReplicaSet 6m6s deployment-controller Scaled down replica set deployment-test-79dbdc995f to 0 from 1
在 Events 中,可以看到:
创建 Deployment 时,Deployment Controller 创建了一个 ReplicaSet并直接将其scale up 到 3 个副本。
当更新 Deployment 时,Deployment Controller 先创建一个新的 ReplicaSet并将其 scale up 到 1 个副本,然后 scale down 旧的 ReplicaSet 到 2。
Deployment Controller 继续 scale up 新的 ReplicaSet 并 scale down 旧的 ReplicaSet,直到最后,新旧两个 ReplicaSet,一个副本数为 3,另一个副本数为 0。回滚 Deployment
当想要回滚(rollback)Deployment,例如:Deployment 不稳定(可能是不断地崩溃)。默认情况下,kubernetes 将保存 Deployment 的所有更新(rollout)历史。
kubectl rollout: 版本升级相关功能,支持下面的选项:
status 显示当前升级状态
history 显示 升级历史记录
pause 暂停版本升级过程
resume 继续已经暂停的版本升级过程
restart 重启版本升级过程
undo 回滚到上一级版本(可以使用--to-revision回滚到指定版本)
————————————————
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
原文链接:https://blog.csdn.net/2302_81107022/article/details/150764644
# 查看当前升级版本的状态
[root@k8s-master01 dev]# kubectl rollout status deploy deployment-test -n dev
deployment "deployment-test" successfully rolled out
# 查看升级历史记录
[root@k8s-master01 dev]# kubectl rollout history deploy deployment-test -n dev
deployment.apps/deployment-test
REVISION CHANGE-CAUSE
1 kubectl create --filename=deployment.yaml --record=true
2 kubectl create --filename=deployment.yaml --record=true
3 kubectl create --filename=deployment.yaml --record=true
# 可以发现有三次版本记录,说明完成过两次升级
#使用--to-revision=1回滚到了1版本, 如果省略这个选项,就是回退到上个版本,就是2版本
[root@k8s-master01 dev]# kubectl rollout undo deployment deployment-test --to-revision=1 -n dev
deployment.apps/deployment-test rolled back
# 查看,nginx镜像版本到了第一版
[root@k8s-master01 dev]# kubectl get deployments.apps -n dev -o wide
NAME READY UP-TO-DATE AVAILABLE AGE CONTAINERS IMAGES SELECTOR
deployment-test 3/3 3 3 7m31s nginx nginx:1.17.1 app=nginx-pod
# 查看rs,发现第3个rs中有3个pod运行,前面两个版本的rs中pod为运行
[root@k8s-master01 dev]# kubectl get rs -n dev
NAME DESIRED CURRENT READY AGE
deployment-test-5b6ffdcd8d 0 0 0 6m20s
deployment-test-79dbdc995f 0 0 0 6m39s
deployment-test-7cffcbf558 3 3 3 9m33s 其实deployment之所以可是实现版本的回滚,就是通过记录下历史rs来实现的
一旦想回滚到哪个版本,只需要将当前版本pod数量降为0,然后将回滚版本的pod提升为目标数量就可以了
金丝雀发布(灰度发布)
Deployment控制器支持控制更新过程中的控制,如“暂停(pause)”或“继续(resume)”更新操作。 比如有一批新的Pod资源创建完成后立即暂停更新过程,此时,仅存在一部分新版本的应用,主体部 分还是旧的版本。然后,再筛选一小部分的用户请求路由到新版本的Pod应用,继续观察能否稳定地按 期望的方式运行。确定没问题之后再继续完成余下的Pod资源滚动更新,否则立即回滚更新操作。这就是所谓的金丝雀发布。
# 更新deployment的版本,并配置暂停deployment
[root@k8s-master01 dev]# kubectl set image deploy deployment-test nginx=nginx:1.17.5 -n dev && kubectl rollout pause deployment deployment-test -n dev
deployment.apps/deployment-test image updated
deployment.apps/deployment-test paused
#观察更新状态
[root@k8s-master01 dev]# kubectl rollout status deploy deployment-test -n dev
Waiting for deployment "deployment-test" rollout to finish: 0 out of 3 new replicas have been updated...
# 监控更新的过程,可以看到已经新增了一个资源,但是并未按照预期的状态去删除一个旧的资源,就是因为使用了pause暂停命令
[root@k8s-master01 dev]# kubectl get rs -n dev -o wide
NAME DESIRED CURRENT READY AGE CONTAINERS IMAGES SELECTOR
deployment-test-5b6ffdcd8d 0 0 0 20m nginx nginx:1.17.3 app=nginx-pod,pod-template-hash=5b6ffdcd8d
deployment-test-79dbdc995f 0 0 0 20m nginx nginx:1.17.2 app=nginx-pod,pod-template-hash=79dbdc995f
deployment-test-7cffcbf558 2 2 2 23m nginx nginx:1.17.1 app=nginx-pod,pod-template-hash=7cffcbf558
deployment-test-845cbff7c8 1 1 0 60s nginx nginx:1.17.5 app=nginx-pod,pod-template-hash=845cbff7c8
deployment-test-f5b4bdd49 1 1 1 6m53s nginx nginx:1.17.4 app=nginx-pod,pod-template-hash=f5b4bdd49
[root@k8s-master01 dev]# kubectl get pod -n dev
NAME READY STATUS RESTARTS AGE
deployment-test-7cffcbf558-6xj55 1/1 Running 0 15m
deployment-test-7cffcbf558-mg8dm 1/1 Running 0 15m
deployment-test-7cffcbf558-nd6ld 1/1 Running 0 15m
deployment-test-f5b4bdd49-r2f5m 1/1 Running 0 4m55s
# 确保更新的pod没问题了,继续更新
[root@k8s-master01 dev]# kubectl rollout resume deploy deployment-test -n dev
deployment.apps/deployment-test resumed
# 查看更新情况
[root@k8s-master01 dev]# kubectl get rs -n dev -o wide
NAME DESIRED CURRENT READY AGE CONTAINERS IMAGES SELECTOR
deployment-test-5b6ffdcd8d 0 0 0 22m nginx nginx:1.17.3 app=nginx-pod,pod-template-hash=5b6ffdcd8d
deployment-test-79dbdc995f 0 0 0 23m nginx nginx:1.17.2 app=nginx-pod,pod-template-hash=79dbdc995f
deployment-test-7cffcbf558 0 0 0 26m nginx nginx:1.17.1 app=nginx-pod,pod-template-hash=7cffcbf558
deployment-test-845cbff7c8 3 3 3 3m39s nginx nginx:1.17.5 app=nginx-pod,pod-template-hash=845cbff7c8
deployment-test-f5b4bdd49 0 0 0 9m32s nginx nginx:1.17.4 app=nginx-pod,pod-template-hash=f5b4bdd49
[root@k8s-master01 dev]# kubectl get pod -n dev
NAME READY STATUS RESTARTS AGE
deployment-test-845cbff7c8-2fm7r 1/1 Running 0 4m23s
deployment-test-845cbff7c8-8fbvx 1/1 Running 0 4m57s
deployment-test-845cbff7c8-wb62j 1/1 Running 0 6m6s局限性
按照 Kubernetes 默认支持的这种方式进行金丝雀发布,有一定的局限性:
不能根据用户注册时间、地区等请求中的内容属性进行流量分配
同一个用户如果多次调用该 Service,有可能第一次请求到了旧版本的 Pod,第二次请求到了新版本的 Pod
TIP
在 Kubernetes 中不能解决上述局限性的原因是:Kubernetes Service 只在 TCP 层面解决负载均衡的问题,并不对请求响应的消息内容做任何解析和识别。如果想要更完善地实现金丝雀发布,可以考虑如下三种选择:
业务代码编码实现
Spring Cloud 灰度发布
Istio 灰度发布
删除Deployment
# 删除deployment,其下的rs和pod也将被删除
[root@k8s-master01 dev]# kubectl delete -f deployment.yaml
deployment.apps "deployment-test" deleted Service详解与使用
详解
在kubernetes中,pod是应用程序的载体,我们可以通过pod的ip来访问应用程序,但是pod的ip地址 不是固定的,这也就意味着不方便直接采用pod的ip对服务进行访问。 为了解决这个问题,
kubernetes提供了Service资源,Service会对提供同一个服务的多个pod进行聚 合,并且提供一个统一的入口地址。通过访问Service的入口地址就能访问到后面的pod服务。
Service在很多情况下只是一个概念,真正起作用的其实是kube-proxy服务进程,每个Node节点上都 运行着一个kube-proxy服务进程。当创建Service的时候会通过api-server向etcd写入创建的service的信 息,而kube-proxy会基于监听的机制发现这种Service的变动,然后它会将最新的Service信息转换成对 应的访问规则。
kube-proxy目前支持三种工作模式:
User space 代理模式
在 user space proxy mode 下:
kube-proxy 监听 kubernetes master 以获得添加和移除 Service / Endpoint 的事件
kube-proxy 在其所在的节点(每个节点都有 kube-proxy)上为每一个 Service 打开一个随机端口
kube-proxy 安装 iptables 规则,将发送到该 Service 的 ClusterIP(虚拟 IP)/ Port 的请求重定向到该随机端口
任何发送到该随机端口的请求将被代理转发到该 Service 的后端 Pod 上(kube-proxy 从 Endpoint 信息中获得可用 Pod)
kube-proxy 在决定将请求转发到后端哪一个 Pod 时,默认使用 round-robin(轮询)算法,并会考虑到 Service 中的 SessionAffinity 的设定
Iptables 代理模式
在 iptables proxy mode 下:
kube-proxy 监听 kubernetes master 以获得添加和移除 Service / Endpoint 的事件
kube-proxy 在其所在的节点(每个节点都有 kube-proxy)上为每一个 Service 安装 iptable规则
iptables 将发送到 Service 的 ClusterIP / Port 的请求重定向到 Service 的后端 Pod 上
对于 Service 中的每一个 Endpoint,kube-proxy 安装一个 iptable 规则
默认情况下,kube-proxy 随机选择一个 Service 的后端 Pod
iptables proxy mode 的优点:
更低的系统开销:在 linux netfilter 处理请求,无需在 userspace 和 kernel space 之间切换更稳定
与 user space mode 的差异:
使用 iptables mode 时,如果第一个 Pod 没有响应,则创建连接失败
使用 user space mode 时,如果第一个 Pod 没有响应,kube-proxy 会自动尝试连接另外一后端 Pod
可以配置 Pod 就绪检查(readiness probe)确保后端 Pod 正常工作,此时,在 iptables 模式kube-proxy 将只使用健康的后端 Pod,从而避免了 kube-proxy 将请求转发到已经存在问题的 Pod 上。
IPVS 代理模式
在 IPVS proxy mode 下:
kube-proxy 监听 kubernetes master 以获得添加和移除 Service / Endpoint 的事件
kube-proxy 根据监听到的事件,调用 netlink 接口,创建 IPVS 规则;并且将Service/Endpoint 的变化同步到 IPVS 规则中
当访问一个 Service 时,IPVS 将请求重定向到后端 Pod
IPVS 模式的优点
IPVS proxy mode 基于 netfilter 的 hook 功能,与 iptables 代理模式相似,但是 IPVS 代理模式使用 hash table 作为底层的数据结构,并在 kernel space 运作。这就意味着
IPVS 代理模式可以比 iptables 代理模式有更低的网络延迟,在同步代理规则时,也有更高的效率
与 user space 代理模式 / iptables 代理模式相比,IPVS 模式可以支持更大的网络流量
IPVS 提供更多的负载均衡选项:
rr: round-robin
lc: least connection (最小打开的连接数)
dh: destination hashing
sh: source hashing
sed: shortest expected delay
nq: never queue
注意:
如果要使用 IPVS 模式,您必须在启动 kube-proxy 前为节点的 linux 启用 IPVS
kube-proxy 以 IPVS 模式启动时,如果发现节点的 linux 未启用 IPVS,则退回到 iptables 模式
Service类型
kind: Service # 资源类型
apiVersion: v1 # 资源版本
metadata: # 元数据
name: service # 资源名称
namespace: dev # 命名空间
spec: # 描述
selector: # 标签选择器,用于确定当前service代理哪些pod
app: nginx
type: # Service类型,指定service的访问方式
clusterIP: # 虚拟服务的ip地址
sessionAffinity: # session亲和性,支持ClientIP、None两个选项
ports: # 端口信息
- protocol: TCP
port: 3017 # service端口
targetPort: 5003 # pod端口
nodePort: 31122 # 主机端口ClusterIP:默认值,它是Kubernetes系统自动分配的虚拟IP,只能在集群内部访问
NodePort:将Service通过指定的Node上的端口暴露给外部,通过此方法,就可以在集群外部访问服务
LoadBalancer:使用外接负载均衡器完成到服务的负载分发,注意此模式需要外部云环境支持
ExternalName: 把集群外部的服务引入集群内部,直接使用
Service使用
使用service之前,首先利用Deployment创建出3个pod,注意要为pod设置 app=nginx-pod 的标签
创建deployment.yaml写入
apiVersion: apps/v1
kind: Deployment
metadata:
name: deployment
namespace: dev
spec:
replicas: 3
selector:
matchLabels:
app: nginx-pod
template:
metadata:
labels:
app: nginx-pod
spec:
containers:
- name: nginx
image: nginx:1.17.1[root@k8s-master01 dev]# kubectl apply -f deployment.yaml
deployment.apps/nginx-deployment created
[root@k8s-master01 dev]# kubectl get pod -n dev -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-deployment-7cffcbf558-7z6hs 1/1 Running 0 107s 100.119.84.73 k8s-worker01 <none> <none>
nginx-deployment-7cffcbf558-9fpc2 1/1 Running 0 107s 100.73.45.71 k8s-worker02 <none> <none>
nginx-deployment-7cffcbf558-hjlqv 1/1 Running 0 107s 100.73.45.72 k8s-worker02 <none> <none>
修改下三台nginx的index.html页面(三台修改的IP地址不一致)
[root@k8s-master01 dev]# kubectl exec -it nginx-deployment-7cffcbf558-7z6hs -n dev /bin/bash
kubectl exec [POD] [COMMAND] is DEPRECATED and will be removed in a future version. Use kubectl exec [POD] -- [COMMAND] instead.
root@nginx-deployment-7cffcbf558-7z6hs:/# echo "`hostname -I`,web1 test page" > /usr/share/nginx/html/index.html
三个全部修改完毕后,访问
[root@k8s-master01 dev]# curl 100.119.84.73
100.119.84.73 ,web1 test page
[root@k8s-master01 dev]# curl 100.73.45.71
100.73.45.71 ,web2 test page
[root@k8s-master01 dev]# curl 100.73.45.72
100.73.45.72 ,web3 test page
[root@k8s-master01 dev]# kubectl expose deployment nginx-deployment --type ClusterIP --port 80 --target-port 80 --name=nginx-svc1 -n dev -o yaml --dry-run=client
apiVersion: v1
kind: Service
metadata:
creationTimestamp: null
name: nginx-svc1
namespace: dev
spec:
ports:
- port: 80
protocol: TCP
targetPort: 80
selector:
app: nginx-pod
type: ClusterIP
status:
loadBalancer: {}可以基于以上,创建service-clusterip.yaml
apiVersion: v1
kind: Service
metadata:
name: nginx-svc1
namespace: dev
spec:
ports:
- port: 80
protocol: TCP
targetPort: 80
selector:
app: nginx-pod
type: ClusterIP
clusterIP: 10.96.0.8 # service的ip地址,如果不写,默认会生成一个[root@k8s-master01 dev]# kubectl create -f svc-clusterip.yaml
service/nginx-svc1 created
[root@k8s-master01 dev]# kubectl get svc -n dev
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
nginx-svc1 ClusterIP 10.96.0.8 <none> 80/TCP 8s
# 查看service的详细信息
# 在这里有一个Endpoints列表,里面就是当前service可以负载到的服务入口
[root@k8s-master01 dev]# kubectl describe svc nginx-svc1 -n dev
Name: nginx-svc1
Namespace: dev
Labels: <none>
Annotations: <none>
Selector: app=nginx-pod
Type: ClusterIP
IP Family Policy: SingleStack
IP Families: IPv4
IP: 10.96.0.8
IPs: 10.96.0.8
Port: <unset> 80/TCP
TargetPort: 80/TCP
Endpoints: 100.119.84.73:80,100.73.45.71:80,100.73.45.72:80
Session Affinity: None
Events: <none>
[root@k8s-master01 dev]# ipvsadm -Ln | grep 10.96.0.8 -w3
TCP 10.96.0.8:80 rr
-> 100.73.45.71:80 Masq 1 0 0
-> 100.73.45.72:80 Masq 1 0 0
-> 100.119.84.73:80 Masq 1 0 0
[root@k8s-master01 dev]# curl 10.96.0.8
100.73.45.72 ,web3 test page
[root@k8s-master01 dev]# curl 10.96.0.8
100.73.45.71 ,web2 test page
[root@k8s-master01 dev]# curl 10.96.0.8
Service的HeadLiness
在某些场景中,开发人员可能不想使用Service提供的负载均衡功能,而希望自己来控制负载均衡策 略,针对这种情况,kubernetes提供了HeadLiness Service,这类Service不会分配Cluster IP,如果想 要访问service,只能通过service的域名进行查询。
创建service-headliness.yaml
apiVersion: v1
kind: Service
metadata:
name: nginx-svc-headliness
namespace: dev
spec:
ports:
- port: 80
protocol: TCP
targetPort: 80
selector:
app: nginx-pod
type: ClusterIP
clusterIP: None
[root@k8s-master01 dev]# kubectl create -f svc-headliness.yaml #创建service
service/nginx-svc-headliness created
[root@k8s-master01 dev]# kubectl get service -n dev # 获取service, 发现CLUSTER-IP未分配
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
nginx-svc-headliness ClusterIP None <none> 80/TCP 36s
[root@k8s-master01 dev]# kubectl describe svc nginx-svc-headliness -n dev #查看service详情
Name: nginx-svc-headliness
Namespace: dev
Labels: <none>
Annotations: <none>
Selector: app=nginx-pod
Type: ClusterIP
IP Family Policy: SingleStack
IP Families: IPv4
IP: None
IPs: None
Port: <unset> 80/TCP
TargetPort: 80/TCP
Endpoints: 100.119.84.73:80,100.73.45.71:80,100.73.45.72:80
Session Affinity: None
Events: <none>
#查看域名的解析情况
[root@k8s-master01 dev]# kubectl exec -it nginx-deployment-7cffcbf558-7z6hs -n dev /bin/bash
kubectl exec [POD] [COMMAND] is DEPRECATED and will be removed in a future version. Use kubectl exec [POD] -- [COMMAND] instead.
root@nginx-deployment-7cffcbf558-7z6hs:/# cat /etc/resolv.conf
nameserver 10.96.0.10
search dev.svc.cluster.local svc.cluster.local cluster.local
options ndots:5
[root@k8s-master01 dev]# dig @10.96.0.10 nginx-svc-headliness.dev.svc.cluster.local
nginx-svc-headliness.dev.svc.cluster.local. 30 IN A 100.119.84.73
nginx-svc-headliness.dev.svc.cluster.local. 30 IN A 100.73.45.71
nginx-svc-headliness.dev.svc.cluster.local. 30 IN A 100.73.45.72
Service的NodePort
在之前的例子中,创建的Service的ip地址只有集群内部才可以访问,如果希望将Service暴露给集群外 部使用,那么就要使用到另外一种类型的Service,称为NodePort类型。NodePort的工作原理其实就是 将service的端口映射到Node的一个端口上,然后就可以通过 NodeIp:NodePort 来访问service。
创建service-nodeport.yaml
apiVersion: v1
kind: Service
metadata:
name: nginx-svc-nodeport
namespace: dev
spec:
ports:
- port: 80
protocol: TCP
targetPort: 80
nodePort: 30088 #指定绑定的node端口(默认取值范围是:30000-32767), 如果不指定,会默认分配
selector:
app: nginx-pod
type: NodePort
[root@k8s-master01 dev]# kubectl create -f svc-nodeport.yaml
service/nginx-svc-nodeport created
[root@k8s-master01 dev]# kubectl get svc -n dev
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
nginx-svc-nodeport NodePort 10.96.0.221 <none> 80:30088/TCP 14s# 可以通过电脑主机的浏览器去访问集群中任意一个nodeip的30088端口,即可访问到pod
Service的LoadBalancer
LoadBalancer和NodePort很相似,目的都是向外部暴露一个端口,区别在于LoadBalancer会在集群 的外部再来做一个负载均衡设备,而这个设备需要外部环境支持的,外部服务发送到这个设备上的请 求,会被设备负载之后转发到集群中。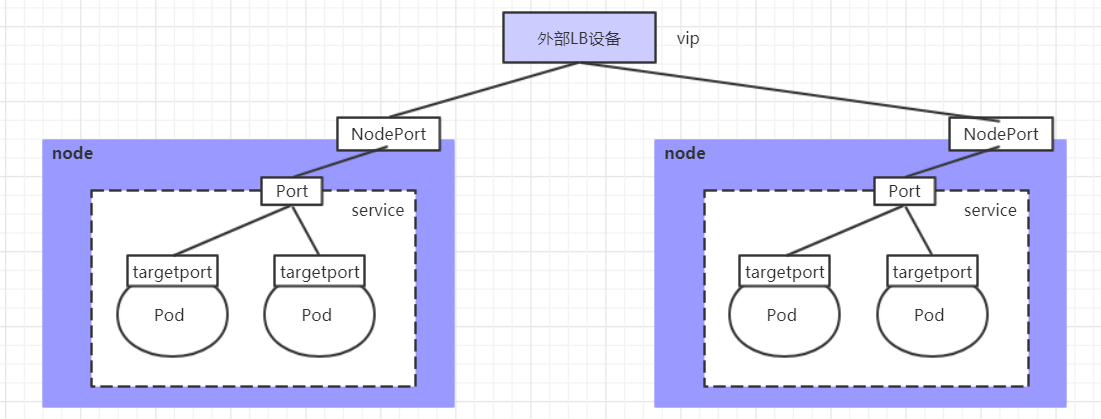
三款开源 Kubernetes 负载均衡器: MetalLB vs PureLB vs OpenELB
1. 什么是 OpenELB
K8S 对集群外暴露服务有三种方式:NodePort,Ingress和 Loadbalancer。NodePort 用于暴露TCP 服务(4层),但限于对集群节点主机端口的占用,不适合大规模使用;Ingress 用于暴露 HTTP 服务(7层),可对域名地址做路由分发;Loadbalancer 则专属于云服务,可动态分配公网网关。
对于私有云集群,没有用到公有云服务,能否使用 LoadBalancer 对外暴露服务呢?
答案当然是肯定的,OpenELB 正是为裸金属服务器提供 LoadBalancer 服务而生的!
由青云科技 KubeSphere 容器团队开源的负载均衡器插件 OpenELB 正式通过 CNCF(云原生计算基金会)TOC 技术委员会审核.
2.安装 OpenELB
前提:
首先需要为 kube-proxy 启用 strictARP ,以便 Kubernetes 集群中的所有网卡停止响应其他网卡的 ARP 请求,而由 OpenELB 处理 ARP 请求。
# 注意:是修改,默认strictARP 是 false
# kubectl edit configmap kube-proxy -n kube-system
......
ipvs:
strictARP: true
......
# wget -c https://raw.githubusercontent.com/openelb/openelb/master/deploy/openelb.yaml
修改镜像地址:修改两处
image: k8s.gcr.io/ingress-nginx/kube-webhook-certgen:v1.1.1 为 image: registry.cn-hangzhou.aliyuncs.com/google_containers/kube-webhookcertgen:v1.1.1
#安装
[root@k8s-master01 dev]# kubectl create -f svc-nodeport.yaml
[root@k8s-master01 dev]# kubectl get pod -n openelb-system
NAME READY STATUS RESTARTS AGE
openelb-admission-create-vdn9v 0/1 Completed 0 3m38s
openelb-admission-patch-6mj7p 0/1 Completed 2 3m38s
openelb-controller-7b9bffd796-tp4hn 1/1 Running 0 3m39s
openelb-speaker-68lr4 1/1 Running 0 3m39s
openelb-speaker-bljh5 1/1 Running 0 3m39s
openelb-speaker-d4kp2 1/1 Running 0 3m39s添加 EIP 池
EIP 地址要与集群主机节点在同一网段内,且不可绑定任何网卡;
创建ip-pool.yaml
apiVersion: network.kubesphere.io/v1alpha2
kind: Eip
metadata:
name: eip-pool
spec:
address: 192.168.234.200-192.168.234.234
protocol: layer2
disable: false
interface: ens160
[root@k8s-master01 dev]# kubectl create -f ip-pool.yaml
eip.network.kubesphere.io/eip-pool created
[root@k8s-master01 dev]# kubectl get eip
NAME CIDR USAGE TOTAL
eip-pool 192.168.234.200-192.168.234.234 35创建svc-lb.yaml
apiVersion: v1
kind: Service
metadata:
name: svc-lb
namespace: dev
annotations:
lb.kubesphere.io/v1alpha1: openelb
protocol.openelb.kubesphere.io/v1alpha2: layer2
eip.openelb.kubesphere.io/v1alpha2: eip-pool
spec:
selector:
app: nginx-pod
type: LoadBalancer
ports:
- port: 80 # 服务监听的端口
targetPort: 80 # 容器端口(与 Pod 定义一致)
[root@k8s-master01 dev]# kubectl apply -f svc-lb.yaml
service/svc-lb created
[root@k8s-master01 dev]# kubectl get svc svc-lb -n dev
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
svc-lb LoadBalancer 10.96.3.126 192.168.234.200 80:32376/TCP 72s
#测试
[root@k8s-master01 dev]# curl 192.168.234.200
100.73.45.72 ,web3 test page
[root@k8s-master01 dev]# curl 192.168.234.200
100.73.45.71 ,web2 test page
[root@k8s-master01 dev]# curl 192.168.234.200
100.119.84.73 ,web1 test page
Service的ExternalName
ExternalName类型的Service用于引入集群外部的服务,它通过 externalName 属性指定外部一个服务的地址,然后在集群内部访问此service就可以访问到外部的服务。
创建svc-externalname.yaml
apiVersion: v1
kind: Service
metadata:
name: svc-externalname
namespace: dev
spec:
type: ExternalName # service类型
externalName: www.aa.com
[root@k8s-master01 dev]# kubectl apply -f svc-externalname.yaml
service/svc-externalname created
#域名解析
[root@k8s-master01 dev]# dig @10.96.0.10 svc-externalname.dev.svc.cluster.local
svc-externalname.dev.svc.cluster.local. 5 IN CNAME www.aa.com.
www.aa.com. 5 IN A 23.210.42.80Ingress的使用
Service对集群之外暴露服务的主要方式有两种:NotdePort和 LoadBalancer,但是这两种方式,都有一定的缺点:
NodePort方式的缺点是会占用很多集群机器的端口,那么当集群服务变多的时候,这个缺点就愈 发明显
LB方式的缺点是每个service需要一个LB,浪费、麻烦,并且需要kubernetes之外设备的支持
基于这种现状,kubernetes提供了Ingress资源对象,Ingress只需要一个NodePort或者一个LB就可 以满足暴露多个Service的需求。工作机制大致如下图表示:
实际上,Ingress相当于一个7层的负载均衡器,是kubernetes对反向代理的一个抽象,它的工作原理 类似于Nginx,可以理解成在Ingress里建立诸多映射规则,Ingress Controller通过监听这些配置规则 并转化成Nginx的反向代理配置 , 然后对外部提供服务。在这里有两个核心概念:
ingress:kubernetes中的一个对象,作用是定义请求如何转发到service的规则
ingress controller:具体实现反向代理及负载均衡的程序,对ingress定义的规则进行解析,根据 配置的规则来实现请求转发,实现方式有很多,比如Nginx, Contour, Haproxy等等
Ingress(以Nginx为例)的工作原理如下:
1. 用户编写Ingress规则,说明哪个域名对应kubernetes集群中的哪个Service
2. Ingress控制器动态感知Ingress服务规则的变化,然后生成一段对应的Nginx反向代理配置
3. Ingress控制器会将生成的Nginx配置写入到一个运行着的Nginx服务中,并动态更新
4. 到此为止,其实真正在工作的就是一个Nginx了,内部配置了用户定义的请求转发规则
环境准备
下载ingress部署的yaml文件
wget https://github.com/kubernetes/ingressnginx/blob/main/deploy/static/provider/cloud/deploy.yaml
修改镜像地址为阿里云地址,总三处
registry.k8s.io/ingress-nginx/controller:v1.12.1
改为 registry.cnhangzhou.aliyuncs.com/google_containers/nginx-ingresscontroller:v1.12.1
k8s.gcr.io/ingress-nginx/kube-webhook-certgen:v1.1.1 改为(有两处需要修改) registry.cn-hangzhou.aliyuncs.com/google_containers/kube-webhook-certgen:v1.5.2
apiVersion: v1
kind: Service
metadata:
labels:
app.kubernetes.io/component: controller
app.kubernetes.io/instance: ingress-nginx
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/part-of: ingress-nginx
app.kubernetes.io/version: 1.12.1
name: ingress-nginx-controller
namespace: ingress-nginx
annotations: #添加注解
lb.kubesphere.io/v1alpha1: openelb
protocol.openelb.kubesphere.io/v1alpha1: layer2
eip.openelb.kubesphere.io/v1alpha2: eip-pool
spec:
externalTrafficPolicy: Local
ipFamilies:
- IPv4
ipFamilyPolicy: SingleStack
ports:
- appProtocol: http
name: http
port: 80
protocol: TCP
targetPort: http
- appProtocol: https
name: https
port: 443
protocol: TCP
targetPort: https
selector:
app.kubernetes.io/component: controller
app.kubernetes.io/instance: ingress-nginx
app.kubernetes.io/name: ingress-nginx
type: LoadBalancer
---
apiVersion: v1
kind: Service
metadata:
labels:
app.kubernetes.io/component: controller
app.kubernetes.io/instance: ingress-nginx
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/part-of: ingress-nginx
app.kubernetes.io/version: 1.12.1
name: ingress-nginx-controller-admission
namespace: ingress-nginx
spec:
ports:
- appProtocol: http
name: http
port: 80
protocol: TCP
targetPort: http
- appProtocol: https
name: https-webhook
port: 443
targetPort: webhook
selector:
app.kubernetes.io/component: controller
app.kubernetes.io/instance: ingress-nginx
app.kubernetes.io/name: ingress-nginx
#type: ClusterIP
type: NodePort #添加修改[root@k8s-master01 dev]# kubectl apply -f deploy.yaml
namespace/ingress-nginx created
serviceaccount/ingress-nginx created
serviceaccount/ingress-nginx-admission created
role.rbac.authorization.k8s.io/ingress-nginx created
role.rbac.authorization.k8s.io/ingress-nginx-admission created
clusterrole.rbac.authorization.k8s.io/ingress-nginx created
clusterrole.rbac.authorization.k8s.io/ingress-nginx-admission created
rolebinding.rbac.authorization.k8s.io/ingress-nginx created
rolebinding.rbac.authorization.k8s.io/ingress-nginx-admission created
clusterrolebinding.rbac.authorization.k8s.io/ingress-nginx created
clusterrolebinding.rbac.authorization.k8s.io/ingress-nginx-admission created
configmap/ingress-nginx-controller created
service/ingress-nginx-controller created
service/ingress-nginx-controller-admission created
deployment.apps/ingress-nginx-controller created
job.batch/ingress-nginx-admission-create created
job.batch/ingress-nginx-admission-patch created
ingressclass.networking.k8s.io/nginx created
validatingwebhookconfiguration.admissionregistration.k8s.io/ingress-nginx-admission created
[root@k8s-master01 dev]# kubectl get svc -n ingress-nginx
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
ingress-nginx-controller LoadBalancer 10.96.0.243 192.168.234.201 80:31527/TCP,443:30862/TCP 51s
ingress-nginx-controller-admission NodePort 10.96.3.118 <none> 80:30689/TCP,443:32072/TCP 51s
[root@k8s-master01 dev]# kubectl get pod -n ingress-nginx
NAME READY STATUS RESTARTS AGE
ingress-nginx-admission-create-8bqd4 0/1 Completed 0 6m31s
ingress-nginx-admission-patch-vxx2h 0/1 Completed 3 6m31s
ingress-nginx-controller-75cdf6c95-wxgk6 1/1 Running 0 6m31sIngress暴露服务的方式
方式一:Deployment+LoadBalancer模式的Service
如果要把ingress部署在公有云,那用这种方式比较合适。用Deployment部署ingresscontroller,创建一个type为 LoadBalancer的 service关联这组pod。大部分公有云,都会为 LoadBalancer的 service自动创建一个负载均衡器,通常还绑定了公网地址。只要把域名解析指向 该地址,就实现了集群服务的对外暴露
方式二:DaemonSet+HostNetwork+nodeselector
用DaemonSet结合nodeselector来部署ingress-controller到特定的node 上,然后使用 HostNetwork直接把该pod与宿主机node的网络打通,直接使用宿主机的80/433端口就能访问服 务。这时,ingress-controller所在的node机器就很类似传统架构的边缘节点,比如机房入口的 nginx服务器。该方式整个请求链路最简单,性能相对NodePort模式更好。缺点是由于直接利用 宿主机节点的网络和端口,一个node只能部署一个ingress-controller pod。比较适合大并发的生 产环境使用
优点
该方式整个请求链路最简单,性能相对NodePort模式更好
缺点
由于直接利用宿主机节点的网络和端口,一个node只能部署一个 ingress-controller pod
方式三:Deployment+NodePort模式的Service
同样用deployment模式部署ingres-controller,并创建对应的服务,但是type为NodePort。这 样,ingress就会暴露在集群节点ip的特定端口上。由于nodeport暴露的端口是随机端口,一般会 在前面再搭建一套负载均衡器来转发请求。该方式一般用于宿主机是相对固定的环境ip地址不变的 场景。NodePort方式暴露ingress虽然简单方便,但是NodePort多了一层NAT,在请求量级很大 时可能对性能会有一定影响
K8s的存储
容器的生命周期可能很短,会被频繁地创建和销毁。那么容器在销毁时,保存在容 器中的数据也会被清除。这种结果对用户来说,在某些情况下是不乐意看到的。为了持久化保存容器的 数据,kubernetes引入了Volume的概念。
Volume是Pod中能够被多个容器访问的共享目录,它被定义在Pod上,然后被一个Pod里的多个容器 挂载到具体的文件目录下,kubernetes通过Volume实现同一个Pod中不同容器之间的数据共享以及数 据的持久化存储。Volume的生命容器不与Pod中单个容器的生命周期相关,当容器终止或者重启时, Volume中的数据也不会丢失。
kubernetes的Volume支持多种类型,比较常见的有下面几个:
基本存储:EmptyDir、HostPath、NFS
高级存储:PV、PVC
配置存储:ConfigMap、Secret
configmap
configmap的功能
configMap用于保存配置数据,以键值对形式存储。
configMap 资源提供了向 Pod 注入配置数据的方法。
镜像和配置文件解耦,以便实现镜像的可移植性和可复用性。
etcd限制了文件大小不能超过1M
configmap创建方式
字面值创建

通过文件创建
[root@master storage]# vim nginx.conf
server{
listen 8080;
root /usr/share/nginx/html;
index index.html;
}
[root@master storage]# kubectl create cm nginxconf --from-file nginx.conf
configmap/nginxconf created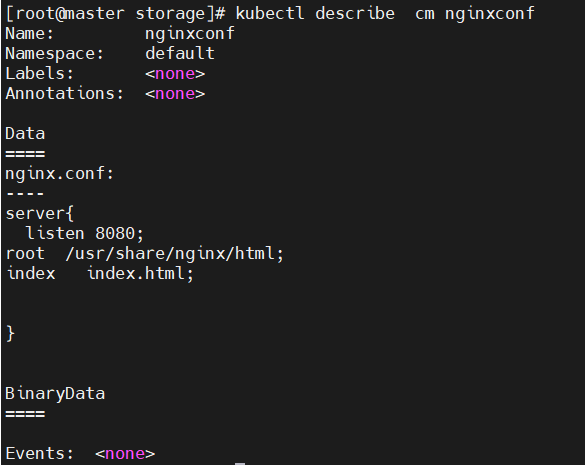
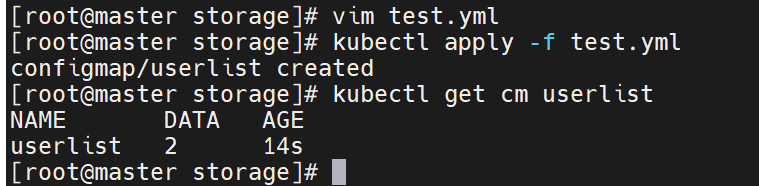
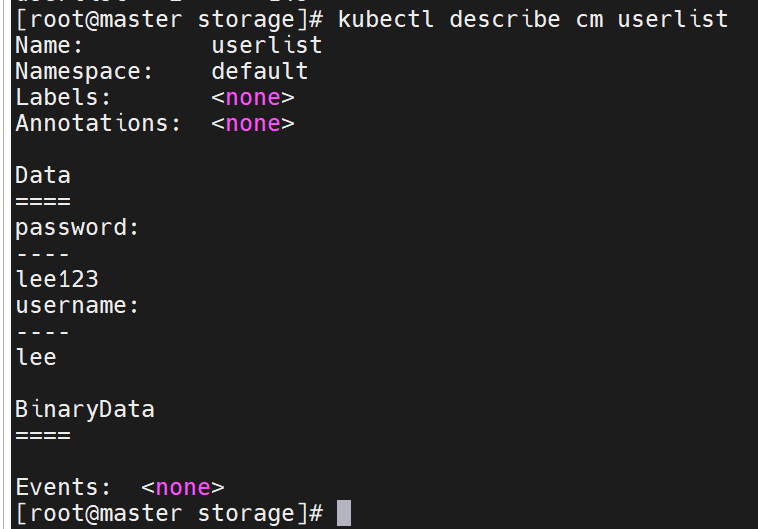
通过yaml文件创建
[root@master storage]# vim test.yml
利用configMap填充pod的配置文件
[root@master storage]# vim nginx.conf
server{
listen 8080;
root /usr/share/nginx/html;
index index.html;
}
[root@master storage]# kubectl create cm nginx-conf --from-file nginx.conf
configmap/nginx-conf created#建立nginx控制器文件
[root@k8s-master storage]# kubectl run nginx --image nginx:latest --dry-run=client -o yaml > nginx.yml
#设定nginx.yml中的卷
[root@k8s-master storage]# vim nginx.yml
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:latest
volumeMounts:
- name: config
mountPath: /etc/nginx/conf.d
volumes:
- name: config
configMap:
name: nginx-confsecret功能介绍
Secret 对象类型用来保存敏感信息,例如密码、OAuth 令牌和 ssh key。
敏感信息放在 secret 中比放在 Pod 的定义或者容器镜像中来说更加安全和灵活
Pod 可以用两种方式使用 secret:
作为 volume 中的文件被挂载到 pod 中的一个或者多个容器里。
当 kubelet 为 pod 拉取镜像时使用。
Secret的类型:
Service Account:Kubernetes 自动创建包含访问 API 凭据的 secret,并自动修改 pod 以使用此类型的 secret。
Opaque:使用base64编码存储信息,可以通过base64 --decode解码获得原始数据,因此安全性弱。
kubernetes.io/dockerconfigjson:用于存储docker registry的认证信息
secrets的创建
从文件创建
[root@k8s-master secrets]# echo -n timinglee > username.txt
[root@k8s-master secrets]# echo -n lee > password.txt
root@k8s-master secrets]# kubectl create secret generic userlist --from-file username.txt --from-file password.txt
secret/userlist created
编写yaml文件
[root@k8s-master secrets]# echo -n timinglee | base64
dGltaW5nbGVl
[root@k8s-master secrets]# echo -n lee | base64
bGVl
[root@k8s-master secrets]# kubectl create secret generic userlist --dry-run=client -o yaml > userlist.yml
apiVersion: v1
kind: Secret
metadata:
creationTimestamp: null
name: userlist
type: Opaque
data:
username: dGltaW5nbGVl
password: bGVlSecret的使用方法
将Secret挂载到Volume中
[root@master storage]# vim pod1.yml
apiVersion: v1
kind: Pod
metadata:
labels:nginx
run: nginx
name: nginx
spec:
containers:
- image: nginx
name: nginx
volumeMounts:
- name: secrets
mountPath: /secret
readOnly: true
volumes:
- name: secrets
secret:
secretName: userlist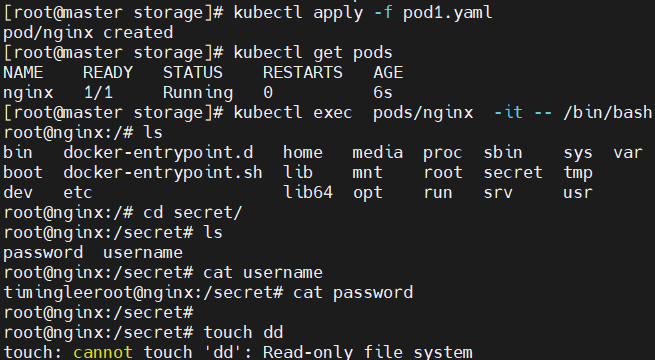
将Secret设置为环境变量
[root@master storage]# vim testsc.yml
apiVersion: v1
kind: Pod
metadata:
labels:
run: testsc
name: testsc
spec:
containers:
- image: busybox
name: testsc
command:
- /bin/sh
- -c
- env
env:
- name: username
valueFrom:
secretKeyRef:
name: userlist
key: username
- name: password
valueFrom:
secretKeyRef:
name: userlist
key: password
restartPolicy: Nevervolumes配置管理
EmptyDir
EmptyDir是最基础的Volume类型,一个EmptyDir就是Host上的一个空目录。
EmptyDir是在Pod被分配到Node时创建的,它的初始内容为空,并且无须指定宿主机上对应的目录文件,因为kubernetes会自动分配一个目录,当Pod销毁时, EmptyDir中的数据也会被永久删除。
EmptyDir用途如下:
临时空间,例如用于某些应用程序运行时所需的临时目录,且无须永久保留
一个容器需要从另一个容器中获取数据的目录(多容器共享目录)
实例:
在一个Pod中准备两个容器nginx和busybox,然后声明一个Volume分别挂在到两个容器的目录中,然后nginx容器负责向Volume中写日志,busybox中通过命令将日志内容读到控制台。
创建volume-emptydir.yaml
apiVersion: v1
kind: Pod
metadata:
name: volume-emptydir
namespace: dev
spec:
volumes:
- name: logs-volume
emptyDir: {}
containers:
- name: nginx
image: nginx:1.17.1
ports:
- containerPort: 80
volumeMounts:
- name: logs-volume
mountPath: /var/log/nginx
- name: busybox
image: busybox:1.30
command: ["/bin/sh","-c","tail -f /logs/access.log"]
volumeMounts:
- name: logs-volume
mountPath: /logs
HostPath
因为EmptyDir中数据不会被持久化,它会随着Pod的结束而销毁,如果想简单的将数据持久 化到主机中,可以选择HostPath。
HostPath就是将Node主机中一个实际目录挂在到Pod中,以供容器使用,这样的设计就可以保证Pod 销毁了,但是数据依据可以存在于Node主机上。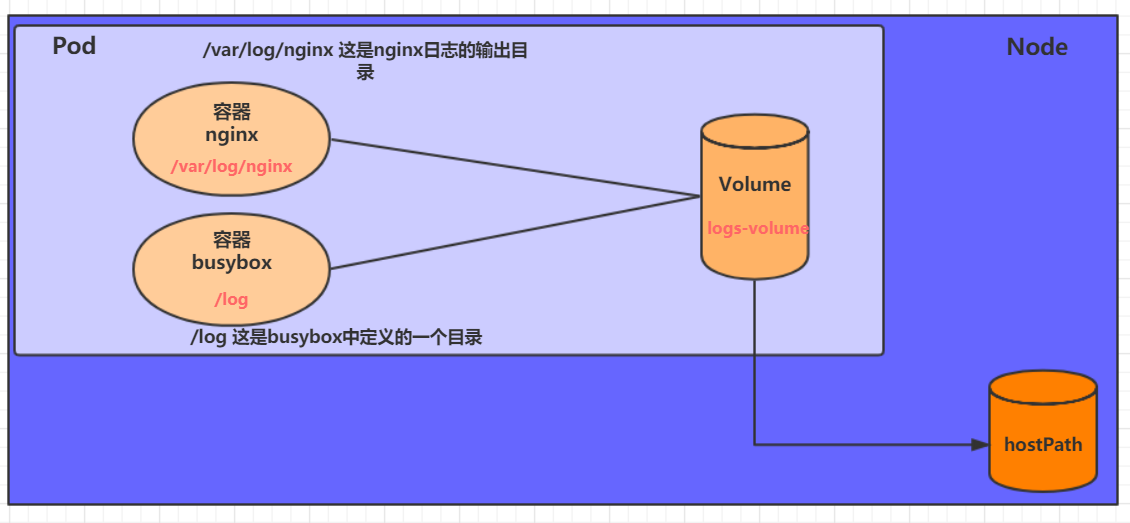
创建volume-hostpath.yaml:
apiVersion: v1
kind: Pod
metadata:
name: volume-hostpath
namespace: dev
spec:
volumes:
- name: logs-volume
hostPath:
path: /opt/logs
type: DirectoryOrCreate
containers:
- name: nginx
image: nginx:1.17.1
ports:
- containerPort: 80
volumeMounts:
- name: logs-volume
mountPath: /var/log/nginx
- name: busybox
image: busybox:1.30
command: ["/bin/sh","-c","tail -f /logs/access.log"]
volumeMounts:
- name: logs-volume
mountPath: /logs
type值说明:
DirectoryOrCreate 目录存在就使用,不存在就先创建后使用
Directory 目录必须存在
FileOrCreate 文件存在就使用,不存在就先创建后使用
File 文件必须存在
Socket unix套接字必须存在
CharDevice 字符设备必须存在
BlockDevice 块设备必须存在
[root@k8s-master01 dev]# kubectl create -f volume-hostpath.yaml
pod/volume-hostpath created
[root@k8s-master01 dev]# kubectl get pod -n dev -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
volume-hostpath 2/2 Running 0 20s 100.119.84.92 k8s-worker01 <none> <none>
[root@k8s-master01 dev]# kubectl exec -it volume-hostpath -n dev -c nginx /bin/bash
kubectl exec [POD] [COMMAND] is DEPRECATED and will be removed in a future version. Use kubectl exec [POD] -- [COMMAND] instead.
root@volume-hostpath:/# echo "this is test page2" > /usr/share/nginx/html/index.html
[root@k8s-master01 dev]# curl 100.119.84.92
this is test page2
# 接下来就可以去host的/opt/logs目录下查看存储的文件了
# 注意: 下面的操作需要到Pod所在的节点运行(k8s-worker01 )
[root@k8s-worker01 ~]# ll /opt/logs/
total 4
-rw-r--r-- 1 root root 189 Apr 11 22:20 access.log
-rw-r--r-- 1 root root 0 Apr 11 22:15 error.log
[root@k8s-worker01 ~]# cat /opt/logs/access.log
100.124.32.128 - - [11/Apr/2025:14:19:02 +0000] "GET / HTTP/1.1" 200 612 "-" "curl/7.79.1" "-"
100.124.32.128 - - [11/Apr/2025:14:20:56 +0000] "GET / HTTP/1.1" 200 20 "-" "curl/7.79.1" "-"
# 同样的道理,如果在此目录下创建一个文件,到容器中也是可以看到的
# 删除文件
[root@k8s-master01 dev]# kubectl delete -f volume-hostpath.yaml
pod "volume-hostpath" deleted
#挂载目录还存在
[root@k8s-worker01 ~]# ll /opt/logs/
total 4
-rw-r--r-- 1 root root 189 Apr 11 22:20 access.log
-rw-r--r-- 1 root root 0 Apr 11 22:15 error.logNFS
HostPath可以解决数据持久化的问题,但是一旦Node节点故障了,Pod如果转移到了别的节点,又会出现问题了,此时需要准备单独的网络存储系统,比较常用的用NFS、CIFS。
NFS是一个网络文件存储系统,可以搭建一台NFS服务器,然后将Pod中的存储直接连接到NFS系统上,这样的话,无论Pod在节点上怎么转移,只要Node跟NFS的对接没问题,数据都可以成功访问。 首先要准备nfs的服务器,这里为了简单,直接是master节点做nfs服务器
# 在master上安装nfs服务
[root@k8s-master01 dev]# yum install nfs-utils -y
# 准备一个共享目录
[root@k8s-master01 ~]# mkdir /nfstest
# 将共享目录以读写权限暴露给192.168.234.0/24网段中的所有主机
[root@k8s-master01 ~]# vim /etc/exports
/nfstest 192.168.234.0/24(rw,no_root_squash)
[root@k8s-worker01 ~]# showmount -e 192.168.234.11
Export list for 192.168.234.11:
/nfstest 192.168.234.0/24
# 启动nfs服务
[root@k8s-master01 ~]# systemctl start nfs
#在的每个node节点上都安装下nfs-utils,这样的目的是为了node节点可以驱动nfs设备
[root@k8s-worker01 ~]# yum install nfs-utils -y
[root@k8s-worker02 ~]# yum install nfs-utils -y
创建volume-nfs.yaml
apiVersion: v1
kind: Pod
metadata:
name: volume-nfs
namespace: dev
spec:
volumes:
- name: logs-volume
nfs:
server: master #nfs服务器地址
path: /nfstest #共享文件路径
containers:
- name: nginx
image: nginx:1.17.1
ports:
- containerPort: 80
volumeMounts:
- name: logs-volume
mountPath: /var/log/nginx
- name: busybox
image: busybox:1.30
command: ["/bin/sh","-c","tail -f /logs/access.log"]
volumeMounts:
- name: logs-volume
[root@k8s-master01 dev]# kubectl create -f volume-nfs.yaml
pod/volume-nfs created
[root@k8s-master01 dev]# kubectl get pod -n dev -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
volume-nfs 2/2 Running 0 2m27s 100.119.84.95 k8s-worker01 <none> <none>
[root@k8s-master01 dev]# kubectl exec -it volume-nfs -n dev /bin/bash
kubectl exec [POD] [COMMAND] is DEPRECATED and will be removed in a future version. Use kubectl exec [POD] -- [COMMAND] instead.
Defaulted container "nginx" out of: nginx, busybox
root@volume-nfs:/# echo "this is nfs test page" > /usr/share/nginx/html/index.html
[root@k8s-master01 dev]# curl 100.119.84.95
this is nfs test page
# 查看nfs服务器上的共享目录
[root@k8s-master01 dev]# ll /nfstest/
total 4
-rw-r--r-- 1 root root 188 Apr 11 23:22 access.log
-rw-r--r-- 1 root root 0 Apr 11 23:17 error.log
[root@k8s-master01 dev]# cat /nfstest/access.log
100.124.32.128 - - [11/Apr/2025:15:22:56 +0000] "GET / HTTP/1.1" 200 22 "-" "curl/7.79.1" "-"
100.124.32.128 - - [11/Apr/2025:15:22:57 +0000] "GET / HTTP/1.1" 200 22 "-" "curl/7.79.1" "-"
PersistentVolume持久卷(pv)
pv是集群内由管理员提供的网络存储的一部分。
PV也是集群中的一种资源。是一种volume插件,
但是它的生命周期却是和使用它的Pod相互独立的。
PV这个API对象,捕获了诸如NFS、ISCSI、或其他云存储系统的实现细节
pv有两种提供方式:静态和动态
静态PV:集群管理员创建多个PV,它们携带着真实存储的详细信息,它们存在于Kubernetes API中,并可用于存储使用
动态PV:当管理员创建的静态PV都不匹配用户的PVC时,集群可能会尝试专门地供给volume给PVC。这种供给基于StorageClass
PersistentVolumeClaim(pvc)
是用户的一种存储请求
它和Pod类似,Pod消耗Node资源,而PVC消耗PV资源
Pod能够请求特定的资源(如CPU和内存)。PVC能够请求指定的大小和访问的模式持久卷配置
PVC与PV的绑定是一对一的映射。没找到匹配的PV,那么PVC会无限期得处于unbound未绑定状态
volumes访问模式
ReadWriteOnce -- 该volume只能被单个节点以读写的方式映射
ReadOnlyMany -- 该volume可以被多个节点以只读方式映射
ReadWriteMany -- 该volume可以被多个节点以读写的方式映射
在命令行中,访问模式可以简写为:
RWO - ReadWriteOnce
ROX - ReadOnlyMany
RWX – ReadWriteMany
volumes回收策略
Retain:保留,需要手动回收
Recycle:回收,自动删除卷中数据(在当前版本中已经废弃)
Delete:删除,相关联的存储资产,如AWS EBS,GCE PD,Azure Disk,or OpenStack Cinder卷都会被删除
[root@reg ~]# mkdir /pod-data/pv{1..3}
[root@master storage]# vim pv.yml
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv1
spec:
capacity:
storage: 5Gi
volumeMode: Filesystem
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Retain
storageClassName: nfs
nfs:
path: /pod-date/pv1
server: 192.168.234.10
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv2
spec:
capacity:
storage: 10Gi
volumeMode: Filesystem
accessModes:
- ReadOnlyMany
persistentVolumeReclaimPolicy: Retain
storageClassName: nfs
nfs:
path: /pod-date/pv2
server: 192.168.234.10
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv3
spec:
capacity:
storage: 15Gi
volumeMode: Filesystem
accessModes:
- ReadWriteMany
persistentVolumeReclaimPolicy: Retain
storageClassName: nfs
nfs:
path: /pod-date/pv3
server: 192.168.234.10#建立pvc,pvc是pv使用的申请,需要保证和pod在一个namesapce中
[root@master storage]# vim pvc.yml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc1
spec:
storageClassName: nfs-client
accessModes:
- ReadWriteMany
resources:
requests:
storage: 1G
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc2
spec:
storageClassName: nfs-client
accessModes:
- ReadWriteMany
resources:
requests:
storage: 10Gi
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc3
spec:
storageClassName: nfs-client
accessModes:
- ReadOnlyMany
resources:
requests:
storage: 15Gi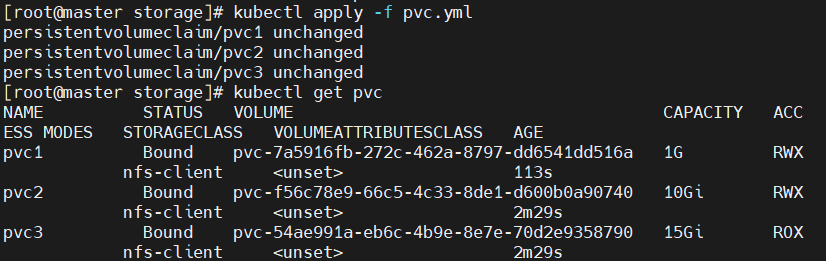
存储类storageclass
StorageClass提供了一种描述存储类(class)的方法,不同的class可能会映射到不同的服务质量等级和备份策略或其他策略等。
每个 StorageClass 都包含 provisioner、parameters 和 reclaimPolicy 字段, 这些字段会在StorageClass需要动态分配 PersistentVolume 时会使用到
StorageClass的属性
Provisioner(存储分配器):用来决定使用哪个卷插件分配 PV,该字段必须指定。可以指定内部分配器,也可以指定外部分配器。外部分配器的代码地址为: kubernetes-incubator/external-storage,其中包括NFS和Ceph等。
Reclaim Policy(回收策略):通过reclaimPolicy字段指定创建的Persistent Volume的回收策略,回收策略包括:Delete 或者 Retain,没有指定默认为Delete。
存储分配器NFS Client Provisioner
NFS Client Provisioner是一个automatic provisioner,使用NFS作为存储,自动创建PV和对应的PVC,本身不提供NFS存储,需要外部先有一套NFS存储服务。
PV以 ${namespace}-${pvcName}-${pvName}的命名格式提供(在NFS服务器上)
PV回收的时候以 archieved-${namespace}-${pvcName}-${pvName} 的命名格式(在NFS服务器上)
部署NFS Client Provisioner
创建sa并授权
[root@master storage]# vim rbac.yml
apiVersion: v1
kind: Namespace
metadata:
name: nfs-client-provisioner
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: nfs-client-provisioner
namespace: nfs-client-provisioner
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: nfs-client-provisioner-runner
rules:
- apiGroups: [""]
resources: ["nodes"]
verbs: ["get", "list", "watch"]
- apiGroups: [""]
resources: ["persistentvolumes"]
verbs: ["get", "list", "watch", "create", "delete"]
- apiGroups: [""]
resources: ["persistentvolumeclaims"]
verbs: ["get", "list", "watch", "update"]
- apiGroups: ["storage.k8s.io"]
resources: ["storageclasses"]
verbs: ["get", "list", "watch"]
- apiGroups: [""]
resources: ["events"]
verbs: ["create", "update", "patch"]
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: run-nfs-client-provisioner
subjects:
- kind: ServiceAccount
name: nfs-client-provisioner
namespace: nfs-client-provisioner
roleRef:
kind: ClusterRole
name: nfs-client-provisioner-runner
apiGroup: rbac.authorization.k8s.io
---
kind: Role
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: leader-locking-nfs-client-provisioner
namespace: nfs-client-provisioner
rules:
- apiGroups: [""]
resources: ["endpoints"]
verbs: ["get", "list", "watch", "create", "update", "patch"]
---
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: leader-locking-nfs-client-provisioner
namespace: nfs-client-provisioner
subjects:
- kind: ServiceAccount
name: nfs-client-provisioner
namespace: nfs-client-provisioner
roleRef:
kind: Role
name: leader-locking-nfs-client-provisioner
apiGroup: rbac.authorization.k8s.io[root@master storage]# vim deployment.yml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nfs-client-provisioner
labels:
app: nfs-client-provisioner
namespace: nfs-client-provisioner
spec:
replicas: 1
strategy:
type: Recreate
selector:
matchLabels:
app: nfs-client-provisioner
template:
metadata:
labels:
app: nfs-client-provisioner
spec:
serviceAccountName: nfs-client-provisioner
containers:
- name: nfs-client-provisioner
image: sig-storage/nfs-subdir-external-provisioner:v4.0.2
volumeMounts:
- name: nfs-client-root
mountPath: /persistentvolumes
env:
- name: PROVISIONER_NAME
value: k8s-sigs.io/nfs-subdir-external-provisioner
- name: NFS_SERVER
value: 192.168.234.10
- name: NFS_PATH
value: /pod-date
volumes:
- name: nfs-client-root
nfs:
server: 192.168.234.10
path: /pod-date
~创建存储类
[root@master storage]# vim class.yml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: nfs-client
provisioner: k8s-sigs.io/nfs-subdir-external-provisioner
parameters:
archiveOnDelete: "false"创建pvc
statefulset控制器
功能特性
Statefulset是为了管理有状态服务的问提设计的
StatefulSet将应用状态抽象成了两种情况:
拓扑状态:应用实例必须按照某种顺序启动。新创建的Pod必须和原来Pod的网络标识一样
存储状态:应用的多个实例分别绑定了不同存储数据。
StatefulSet给所有的Pod进行了编号,编号规则是:$(statefulset名称)-$(序号),从0开始。
Pod被删除后重建,重建Pod的网络标识也不会改变,Pod的拓扑状态按照Pod的“名字+编号”的方式固定下来,并且为每个Pod提供了一个固定且唯一的访问入口,Pod对应的DNS记录。
StatefulSet的组成部分
Headless Service:用来定义pod网络标识,生成可解析的DNS记录
volumeClaimTemplates:创建pvc,指定pvc名称大小,自动创建pvc且pvc由存储类供应。
StatefulSet:管理pod的
#建立无头服务
[root@master storage]# vim headless.yml
apiVersion: v1
kind: Service
metadata:
labels:
app: nginx
name: nginx-svc
spec:
clusterIP: None
selector:
app: nginx
type: ClusterIP
[root@master storage]# kubectl apply -f headless.yml
service/nginx-svc created
#建立statefulset
[root@master storage]# vim stateful.yml
apiVersion: apps/v1
kind: StatefulSet
metadata:
labels:
app: nginx
name: nginx
spec:
serviceName: "nginx-svc"
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- image: nginx
name: nginx
volumeMounts:
- name: www
mountPath: /usr/share/nginx/html
volumeClaimTemplates:
- metadata:
name: www
spec:
storageClassName: nfs-client
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi

#为每个pod建立index.html文件

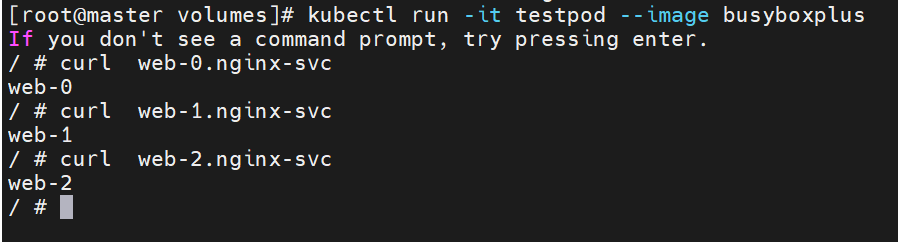
K8s的调度
在默认情况下,一个Pod在哪个Node节点上运行,是由Scheduler组件采用相应的算法计算出来的,这个过程是不受人工控制的。但是在实际使用中,这并不满足的需求,因为很多情况下,我们想控制某些Pod到达某些节点上,那么应该怎么做呢?这就要求了解kubernetes对Pod的调度规则,kubernetes提供了四大类调度方式:
自动调度:运行在哪个节点上完全由Scheduler经过一系列的算法计算得出
定向调度:NodeName、NodeSelector
亲和性调度:NodeAffinity、PodAffinity、PodAntiAffinity
污点(容忍)调度:Taints、Toleration
定向调度
定向调度,指的是利用在pod上声明nodeName或者nodeSelector,以此将Pod调度到期望的node节点上。注意,这里的调度是强制的,这就意味着即使要调度的目标Node不存在,也会向上面进行调度,只不过pod运行失败而已。
NodeName
NodeName用于强制约束将Pod调度到指定的Name的Node节点上。这种方式,其实是直接跳过 Scheduler的调度逻辑,直接将Pod调度到指定名称的节点。
创建一个pod-nodename.yaml文件
apiVersion: v1
kind: Pod
metadata:
name: pod-nodename
namespace: dev
spec:
containers:
- name: nginx
image: nginx:1.17.1
nodeName: k8s-worker01 # 指定调度到k8s-worker01节点上#创建Pod
[root@master ~]# kubectl create -f pod-nodename.yaml
pod/pod-nodename created
#查看Pod调度到NODE属性,确实是调度到了node1节点上
[root@master ~]# kubectl get pod pod-nodename -n dev -o wide
NAME READY STATUS RESTARTS AGE IP NODE ......
pod-nodename 1/1 Running 0 56s 10.244.1.87 k8s-worker01 ......
# 接下来,删除pod,修改nodeName的值为k8s-worker03(并没有k8s-worker03节点)
[root@master ~]# kubectl delete -f pod-nodename.yaml
pod "pod-nodename" deleted
[root@master ~]# vim pod-nodename.yaml
[root@master ~]# kubectl create -f pod-nodename.yaml
pod/pod-nodename created
#再次查看,发现已经向Node3节点调度,但是由于不存在k8s-worker03节点,所以pod无法正常运行
[root@master ~]# kubectl get pods pod-nodename -n dev -o wide
NAME READY STATUS RESTARTS AGE IP NODE ......
pod-nodename 0/1 Pending 0 6s <none> k8s-worker03 ...... NodeSelector
NodeSelector用于将pod调度到添加了指定标签的node节点上。它是通过kubernetes的labelselector机制实现的,也就是说,在pod创建之前,会由scheduler使用MatchNodeSelector调度策略进 行label匹配,找出目标node,然后将pod调度到目标节点,该匹配规则是强制约束。创建一个pod-nodeselector.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-nodeselector
namespace: dev
spec:
containers:
- name: nginx
image: nginx:1.17.1
nodeSelector:
nodeenv: pro # 指定调度到具有nodeenv=pro标签的节点上#创建Pod
[root@master ~]# kubectl create -f pod-nodeselector.yaml
pod/pod-nodeselector created
#查看Pod调度到NODE属性,确实是调度到了node1节点上
[root@master ~]# kubectl get pods pod-nodeselector -n dev -o wide
NAME READY STATUS RESTARTS AGE IP NODE
......
pod-nodeselector 1/1 Running 0 47s 100.119.84.73 k8s-worker01
......
# 接下来,删除pod,修改nodeSelector的值为nodeenv: hhh(不存在打有此标签的节点)
[root@master ~]# kubectl delete -f pod-nodeselector.yaml
pod "pod-nodeselector" deleted
[root@master ~]# vim pod-nodeselector.yaml
[root@master ~]# kubectl create -f pod-nodeselector.yaml
pod/pod-nodeselector created
#再次查看,发现pod无法正常运行,Node的值为none
[root@master ~]# kubectl get pods -n dev -o wide
NAME READY STATUS RESTARTS AGE IP NODE
pod-nodeselector 0/1 Pending 0 2m20s <none> <none>
# 查看详情,发现node selector匹配失败的提示
[root@master ~]# kubectl describe pods pod-nodeselector -n dev
.......
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling <unknown> default-scheduler 0/3 nodes are
available: 3 node(s) didn't match node selector.
Warning FailedScheduling <unknown> default-scheduler 0/3 nodes are
available: 3 node(s) didn't match node selector.亲和性调度
亲和性调度在NodeSelector的基础之上进行了扩展,可以通过配置的形式,实现优先选择满足条件的Node进行调度,如果没有,也可以调度到不满足条件的节点上,使调度更加灵活。
Affinity主要分为三类:
nodeAffinity(node亲和性): 以node为目标,解决pod可以调度到哪些node的问题
podAffinity(pod亲和性) : 以pod为目标,解决pod可以和哪些已存在的pod部署在同一个拓扑域中的问题
podAntiAffinity(pod反亲和性) : 以pod为目标,解决pod不能和哪些已存在pod部署在同一个拓扑域中的问题
pod.spec.affinity.nodeAffinity
requiredDuringSchedulingIgnoredDuringExecution Node节点必须满足指定的所有规则才可
以,相当于硬限制
nodeSelectorTerms 节点选择列表
matchFields 按节点字段列出的节点选择器要求列表
matchExpressions 按节点标签列出的节点选择器要求列表(推荐)
key 键
values 值
operator 关系符 支持Exists, DoesNotExist, In, NotIn, Gt, Lt
preferredDuringSchedulingIgnoredDuringExecution 优先调度到满足指定的规则的Node,相当
于软限制 (倾向)
preference 一个节点选择器项,与相应的权重相关联
matchFields 按节点字段列出的节点选择器要求列表
matchExpressions 按节点标签列出的节点选择器要求列表(推荐)
key 键
values 值
operator 关系符 支持In, NotIn, Exists, DoesNotExist, Gt, Lt
weight 倾向权重,在范围1-100。
关系符的使用说明:
- matchExpressions:
- key: nodeenv # 匹配存在标签的key为nodeenv的节点
operator: Exists
- key: nodeenv # 匹配标签的key为nodeenv,且value是"xxx"或"yyy"的节点
operator: In
values: ["xxx","yyy"]
- key: nodeenv # 匹配标签的key为nodeenv,且value大于"xxx"的节点
operator: Gt
values: "xxx"pod.spec.affinity.nodeAffinity
requiredDuringSchedulingIgnoredDuringExecution Node节点必须满足指定的所有规则才可
以,相当于硬限制
nodeSelectorTerms 节点选择列表
matchFields 按节点字段列出的节点选择器要求列表
matchExpressions 按节点标签列出的节点选择器要求列表(推荐)
key 键
values 值
operator 关系符 支持Exists, DoesNotExist, In, NotIn, Gt, Lt
preferredDuringSchedulingIgnoredDuringExecution 优先调度到满足指定的规则的Node,相当
于软限制 (倾向)
preference 一个节点选择器项,与相应的权重相关联
matchFields 按节点字段列出的节点选择器要求列表
matchExpressions 按节点标签列出的节点选择器要求列表(推荐)
key 键
values 值
operator 关系符 支持In, NotIn, Exists, DoesNotExist, Gt, Lt
weight 倾向权重,在范围1-100。
关系符的使用说明:
- matchExpressions:
- key: nodeenv # 匹配存在标签的key为nodeenv的节点
operator: Exists
- key: nodeenv # 匹配标签的key为nodeenv,且value是"xxx"或"yyy"的节点
operator: In
values: ["xxx","yyy"]
- key: nodeenv # 匹配标签的key为nodeenv,且value大于"xxx"的节点
operator: Gt
values: "xxx"NodeAffinity规则设置的注意事项:
1 如果同时定义了nodeSelector和nodeAffinity,那么必须两个条件都得到满足,Pod才能运行在指定的Node上
2 如果nodeAffinity指定了多个nodeSelectorTerms,那么只需要其中一个能够匹配成功即可
3 如果一个nodeSelectorTerms中有多个matchExpressions ,则一个节点必须满足所有的才能匹配成功
4 如果一个pod所在的Node在Pod运行期间其标签发生了改变,不再符合该Pod的节点亲和性需求,则系统将忽略此变化
PodAffinity
首先来看一下 PodAffinity 的可配置项:
pod.spec.affinity.podAffinity
requiredDuringSchedulingIgnoredDuringExecution 硬限制
namespaces 指定参照pod的namespace
topologyKey 指定调度作用域
labelSelector 标签选择器
matchExpressions 按节点标签列出的节点选择器要求列表(推荐)
key 键
values 值
operator 关系符 支持In, NotIn, Exists, DoesNotExist.
matchLabels 指多个matchExpressions映射的内容
preferredDuringSchedulingIgnoredDuringExecution 软限制
podAffinityTerm 选项
namespaces
topologyKey
labelSelector
matchExpressions
key 键
values 值
operator
matchLabels
weight 倾向权重,在范围1-100
topologyKey用于指定调度时作用域,例如:
如果指定为kubernetes.io/hostname,那就是以Node节点为区分范围
如果指定为beta.kubernetes.io/os,则以Node节点的操作系统类型来区分创建一个参照Pod,pod-podaffinity-target.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-podaffinity-target
namespace: dev
labels:
podenv: pro #设置标签
spec:
containers:
- name: nginx
image: nginx:1.17.1
nodeName: node1 # 将目标pod名确指定到node1上# 启动目标pod
[root@master ~]# kubectl create -f pod-podaffinity-target.yaml
pod/pod-podaffinity-target created
# 查看pod状况
[root@master ~]# kubectl get pods pod-podaffinity-target -n dev
NAME READY STATUS RESTARTS AGE
pod-podaffinity-target 1/1 Running 0 4s
创建pod-podaffinity-required.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-podaffinity-required
namespace: dev
spec:
containers:
- name: nginx
image: nginx:1.17.1
affinity: #亲和性设置
podAffinity: #设置pod亲和性
requiredDuringSchedulingIgnoredDuringExecution: # 硬限制
- labelSelector:
matchExpressions: # 匹配env的值在["xxx","yyy"]中的标签
- key: podenv
operator: In
values: ["xxx","yyy"]
topologyKey: kubernetes.io/hostname新Pod必须要与拥有标签nodeenv=xxx或者nodeenv=yyy的pod在同一Node 上,显然现在没有这样pod
# 启动pod
[root@master ~]# kubectl create -f pod-podaffinity-required.yaml
pod/pod-podaffinity-required created
# 查看pod状态,发现未运行
[root@master ~]# kubectl get pods pod-podaffinity-required -n dev
NAME READY STATUS RESTARTS AGE
pod-podaffinity-required 0/1 Pending 0 9s
# 查看详细信息
[root@master ~]# kubectl describe pods pod-podaffinity-required -n dev
......
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling <unknown> default-scheduler 0/3 nodes are
available: 2 node(s) didn't match pod affinity rules, 1 node(s) had taints that
the pod didn't tolerate.
# 接下来修改 values: ["xxx","yyy"]----->values:["pro","yyy"]
# 意思是:新Pod必须要与拥有标签nodeenv=xxx或者nodeenv=yyy的pod在同一Node上
[root@master ~]# vim pod-podaffinity-required.yaml
# 然后重新创建pod,查看效果
[root@master ~]# kubectl delete -f pod-podaffinity-required.yaml
pod "pod-podaffinity-required" deleted
[root@master ~]# kubectl create -f pod-podaffinity-required.yaml
pod/pod-podaffinity-required created
# 发现此时Pod运行正常
[root@master ~]# kubectl get pods pod-podaffinity-required -n dev
NAME READY STATUS RESTARTS AGE LABELS
pod-podaffinity-required 1/1 Running 0 6s <none>PodAntiAffinity
创建pod-podantiaffinity-required.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-podantiaffinity-required
namespace: dev
spec:
containers:
- name: nginx
image: nginx:1.17.1
affinity: #亲和性设置
podAntiAffinity: #设置pod亲和性
requiredDuringSchedulingIgnoredDuringExecution: # 硬限制
- labelSelector:
matchExpressions: # 匹配podenv的值在["pro"]中的标签
- key: podenv
operator: In
values: ["pro"]
topologyKey: kubernetes.io/hostname新Pod必须要与拥有标签nodeenv=pro的pod不在同一Node上
# 创建pod
[root@master ~]# kubectl create -f pod-podantiaffinity-required.yaml
pod/pod-podantiaffinity-required created
# 查看pod
# 发现调度到了node2上
[root@master ~]# kubectl get pods pod-podantiaffinity-required -n dev -o wide
NAME READY STATUS RESTARTS AGE IP
NODE ..
pod-podantiaffinity-required 1/1 Running 0 30s 10.244.1.96
node2 ..污点和容忍
污点(Taints)
前面的调度方式都是站在Pod的角度上,通过在Pod上添加属性,来确定Pod是否要调度到指定的
Node上,其实我们也可以站在Node的角度上,通过在Node上添加污点属性,来决定是否允许Pod调度过来。
Node被设置上污点之后就和Pod之间存在了一种相斥的关系,进而拒绝Pod调度进来,甚至可以将已经存在的Pod驱逐出去。
污点的格式为: key=value:effect , key和value是污点的标签,effect描述污点的作用,支持如下三个选项:
PreferNoSchedule:kubernetes将尽量避免把Pod调度到具有该污点的Node上,除非没有其他节点可调度
NoSchedule:kubernetes将不会把Pod调度到具有该污点的Node上,但不会影响当前Node上已存在的Pod
NoExecute:kubernetes将不会把Pod调度到具有该污点的Node上,同时也会将Node上已存在的Pod驱离
#首先要暂停节点2
[root@k8s-worker02 ~]# systemctl stop kubelet.service
# 为node1设置污点(PreferNoSchedule)
[root@master ~]# kubectl taint nodes k8s-worker01 tag=openlab:PreferNoSchedule
# 创建pod1
[root@master ~]# kubectl run taint1 --image=nginx:1.17.1 -n dev
[root@master ~]# kubectl get pod -n dev -o wide
NAME READY STATUS RESTARTS AGE IP NODE
taint1 1/1 Running 0 22s 100.119.84.74 k8s-worker01
# 为node1设置污点(取消PreferNoSchedule,设置NoSchedule)
[root@master ~]# kubectl taint nodes k8s-worker01 tag:PreferNoSchedule-
[root@master ~]# kubectl taint nodes k8s-worker01 tag=openlab:NoSchedule
# 创建pod2
[root@master ~]# kubectl run taint2 --image=nginx:1.17.1 -n dev
[root@master ~]# kubectl get pod taint2 -n dev -o wide
NAME READY STATUS RESTARTS AGE IP NODE
taint2 0/1 Pending 0 15s <none> <none>
# 为node1设置污点(取消NoSchedule,设置NoExecute)
[root@master ~]# kubectl taint nodes k8s-worker01 tag:NoSchedule-
[root@master ~]# kubectl taint nodes k8s-worker01 tag=openlab:NoExecute
# 创建pod3
[root@master ~]# kubectl run taint3 --image=nginx:1.17.1 -n dev
[root@master ~]# kubectl get pod taint3 -n dev -o wide
NAME READY STATUS RESTARTS AGE IP NODE
taint3 0/1 Pending 0 8s <none> <none> 容忍(Toleration)
上面介绍了污点的作用,我们可以在node上添加污点用于拒绝pod调度上来,但是如果就是想将一个 pod调度到一个有污点的node上去,这时候应该怎么做呢?这就要使用到容忍。
污点就是拒绝,容忍就是忽略,Node通过污点拒绝pod调度上去,Pod通过容忍忽略拒绝
由于已经在节点1上打上了 NoExecute 的污点,此时pod是调度不上去的,可以通过给pod添加容忍,然后将其调度上去
容忍的详细配置:
[root@master ~]# kubectl explain pod.spec.tolerations
......
FIELDS:
key # 对应着要容忍的污点的键,空意味着匹配所有的键
value # 对应着要容忍的污点的值
operator # key-value的运算符,支持Equal和Exists(默认)
effect # 对应污点的effect,空意味着匹配所有影响
tolerationSeconds # 容忍时间, 当effect为NoExecute时生效,表示pod在Node上的停留时间Authentication(认证)
认证方式现共有8种,可以启用一种或多种认证方式,只要有一种认证方式通过,就不再进行其它方式的认证。通常启用X509 Client Certs和Service Accout Tokens两种认证方式。
Kubernetes集群有两类用户:由Kubernetes管理的Service Accounts (服务账户)和(Users Accounts) 普通账户。k8s中账号的概念不是我们理解的账号,它并不真的存在,它只是形式上存在。
Authorization(授权)
必须经过认证阶段,才到授权请求,根据所有授权策略匹配请求资源属性,决定允许或拒绝请求。授权方式现共有6种,AlwaysDeny、AlwaysAllow、ABAC、RBAC、Webhook、Node。默认集群强制开启RBAC。
Admission Control(准入控制)
用于拦截请求的一种方式,运行在认证、授权之后,是权限认证链上的最后一环,对请求API资源对象进行修改和校验。
ServiceAccount
服务账户控制器(Service account controller)
服务账户管理器管理各命名空间下的服务账户
每个活跃的命名空间下存在一个名为 “default” 的服务账户
服务账户准入控制器(Service account admission controller)
相似pod中 ServiceAccount默认设为 default。
保证 pod 所关联的 ServiceAccount 存在,否则拒绝该 pod。
如果pod不包含ImagePullSecrets设置那么ServiceAccount中的ImagePullSecrets 被添加到pod中
将挂载于 /var/run/secrets/kubernetes.io/serviceaccount 的 volumeSource 添加到 pod 下的每个容器中
将一个包含用于 API 访问的 token 的 volume 添加到 pod 中
认证(在k8s中建立认证用户)
创建UserAccount
#建立证书
[root@k8s-master auth]# cd /etc/kubernetes/pki/
[root@k8s-master pki]# openssl genrsa -out timinglee.key 2048
[root@k8s-master pki]# openssl req -new -key timinglee.key -out timinglee.csr -subj "/CN=timinglee"
[root@k8s-master pki]# openssl x509 -req -in timinglee.csr -CA ca.crt -CAkey ca.key -CAcreateserial -out timinglee.crt -days 365
Certificate request self-signature ok
[root@k8s-master pki]# openssl x509 -in timinglee.crt -text -noout
Certificate:
Data:
Version: 1 (0x0)
Serial Number:
76:06:6c:a7:36:53:b9:3f:5a:6a:93:3a:f2:e8:82:96:27:57:8e:58
Signature Algorithm: sha256WithRSAEncryption
Issuer: CN = kubernetes
Validity
Not Before: Sep 8 15:59:55 2024 GMT
Not After : Sep 8 15:59:55 2025 GMT
Subject: CN = timinglee
Subject Public Key Info:
Public Key Algorithm: rsaEncryption
Public-Key: (2048 bit)
Modulus:
00:a6:6d:be:5d:7f:4c:bf:36:96:dc:4e:1b:24:64:
f7:4b:57:d3:45:ad:e8:b5:07:e7:78:2b:9e:6e:53:
2f:16:ff:00:f4:c8:41:2c:89:3d:86:7c:1b:16:08:
2e:2c:bc:2c:1e:df:60:f0:80:60:f9:79:49:91:1d:
9f:47:16:9a:d1:86:c7:4f:02:55:27:12:93:b7:f4:
07:fe:13:64:fd:78:32:8d:12:d5:c2:0f:be:67:65:
f2:56:e4:d1:f6:fe:f6:d5:7c:2d:1d:c8:90:2a:ac:
3f:62:85:9f:4a:9d:85:73:33:26:5d:0f:4a:a9:14:
12:d4:fb:b3:b9:73:d0:a3:be:58:41:cb:a0:62:3e:
1b:44:ef:61:b5:7f:4a:92:5b:e3:71:77:99:b4:ea:
4d:27:80:14:e9:95:4c:d5:62:56:d6:54:7b:f7:c2:
ea:0e:47:b2:19:75:59:22:00:bd:ea:83:6b:cd:12:
46:7a:4a:79:83:ee:bc:59:6f:af:8e:1a:fd:aa:b4:
bd:84:4d:76:38:e3:1d:ea:56:b5:1e:07:f5:39:ef:
56:57:a2:3d:91:c0:3f:38:ce:36:5d:c7:fe:5e:0f:
53:75:5a:f0:6e:37:71:4b:90:03:2f:2e:11:bb:a1:
a1:5b:dc:89:b8:19:79:0a:ee:e9:b5:30:7d:16:44:
4a:53
Exponent: 65537 (0x10001)
Signature Algorithm: sha256WithRSAEncryption
Signature Value:
62:db:0b:58:a9:59:57:91:7e:de:9e:bb:20:2f:24:fe:b7:7f:
33:aa:d5:74:0e:f9:96:ce:1b:a9:65:08:7f:22:6b:45:ee:58:
68:d8:26:44:33:5e:45:e1:82:b2:5c:99:41:6b:1e:fa:e8:1a:
a2:f1:8f:44:22:e1:d6:58:5f:4c:28:3d:e0:78:21:ea:aa:85:
08:a5:c8:b3:34:19:d3:c7:e2:fe:a2:a4:f5:68:18:53:5f:ff:
7d:35:22:3c:97:3d:4e:ad:62:5f:bb:4d:88:fb:67:f4:d5:2d:
81:c8:2c:6c:5e:0e:e2:2c:f5:e9:07:34:16:01:e2:bf:1f:cd:
6a:66:db:b6:7b:92:df:13:a1:d0:58:d8:4d:68:96:66:e3:00:
6e:ce:11:99:36:9c:b3:b5:81:bf:d1:5b:d7:f2:08:5e:7d:ea:
97:fe:b3:80:d6:27:1c:89:e6:f2:f3:03:fc:dc:de:83:5e:24:
af:46:a6:2a:8e:b1:34:67:51:2b:19:eb:4c:78:12:ac:00:4e:
58:5e:fd:6b:4c:ce:73:dd:b3:91:73:4a:d6:6f:2c:86:25:f0:
6a:fb:96:66:b3:39:a4:b0:d9:46:c2:fc:6b:06:b2:90:9c:13:
e1:02:8b:6f:6e:ab:cf:e3:21:7e:a9:76:c1:38:15:eb:e6:2d:
a5:6f:e5:ab#建立k8s中的用户
[root@k8s-master pki]# kubectl config set-credentials timinglee --client-certificate /etc/kubernetes/pki/timinglee.crt --client-key /etc/kubernetes/pki/timinglee.key --embed-certs=true
User "timinglee" set.#为用户创建集群的安全上下文
root@k8s-master pki]# kubectl config set-context timinglee@kubernetes --cluster kubernetes --user timinglee
Context "timinglee@kubernetes" created.
#切换用户,用户在集群中只有用户身份没有授权
[root@k8s-master ~]# kubectl config use-context timinglee@kubernetes
Switched to context "timinglee@kubernetes".
[root@k8s-master ~]# kubectl get pods
Error from server (Forbidden): pods is forbidden: User "timinglee" cannot list resource "pods" in API group "" in the namespace "default"
#切换会集群管理
[root@k8s-master ~]# kubectl config use-context kubernetes-admin@kubernetes
Switched to context "kubernetes-admin@kubernetes".RBAC(Role Based Access Control)
基于角色访问控制授权:
允许管理员通过Kubernetes API动态配置授权策略。RBAC就是用户通过角色与权限进行关联。
RBAC只有授权,没有拒绝授权,所以只需要定义允许该用户做什么即可
RBAC的三个基本概念
Subject:被作用者,它表示k8s中的三类主体, user, group, serviceAccount
Role:角色,它其实是一组规则,定义了一组对 Kubernetes API 对象的操作权限。
RoleBinding:定义了“被作用者”和“角色”的绑定关系
RBAC包括四种类型:Role、ClusterRole、RoleBinding、ClusterRoleBinding
Role 和 ClusterRole
Role是一系列的权限的集合,Role只能授予单个namespace 中资源的访问权限。
ClusterRole 跟 Role 类似,但是可以在集群中全局使用。
Kubernetes 还提供了四个预先定义好的 ClusterRole 来供用户直接使用
cluster-amdin、admin、edit、view
role授权
[root@k8s-master rbac]# kubectl create role myrole --dry-run=client --verb=get --resource pods -o yaml > myrole.yml
[root@master rbac]# vim myrole.yml
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: myrole
rules:
- apiGroups:
- ""
resources:
- pods
verbs:
- get
- watch
- list
- create
- update
- path
- delete
- apiGroups:
- ""
resources:
- services
verbs:
- get
- watch
- list
- create
- update
- path
- delete
[root@k8s-master rbac]# kubectl apply -f myrole.yml
role.rbac.authorization.k8s.io/myrole configured
#建立角色绑定
[root@k8s-master rbac]# kubectl create rolebinding timinglee --role myrole --namespace default --user timinglee --dry-run=client -o yaml > rolebinding-myrole.yml
[root@k8s-master rbac]# vim rolebinding-myrole.yml
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: timinglee
namespace: default
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: myrole
subjects:
- apiGroup: rbac.authorization.k8s.io
kind: User
name: timinglee
[root@master schedule]# kubectl apply -f rolebinding-myrole.yml
rolebinding.rbac.authorization.k8s.io/timinglee created
#切换用户测试授权
[root@k8s-master rbac]# kubectl config use-context timinglee@kubernetes
Switched to context "timinglee@kubernetes".#切换回管理员
[root@k8s-master rbac]# kubectl config use-context kubernetes-admin@kubernetes
Switched to context "kubernetes-admin@kubernetes".
clusterrole授权实施
#建立集群角色
[root@k8s-master rbac]# kubectl create clusterrole myclusterrole --resource=deployment --verb get --dry-run=client -o yaml > myclusterrole.yml
[root@master schedule]# vim myclusterrole.yml
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: myclusterrole
rules:
- apiGroups:
- ""
resources:
- pods
verbs:
- get
- watch
- list
- create
- update
- path
- delete
- apiGroups:
- ""
resources:
- services
verbs:
- get
- watch
- list
- create
- update
- path
- delete
- apiGroups:
- ""
resources:
- deployments
verbs:
- get
- watch
- list
- create
- update
- path
- delete#建立集群角色绑定
[root@k8s-master rbac]# kubectl create clusterrolebinding clusterrolebind-myclusterrole --clusterrole myclusterrole --user timinglee --dry-run=client -o yaml > clusterrolebind-myclusterrole.yml
[root@k8s-master rbac]# vim clusterrolebind-myclusterrole.yml
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: clusterrolebind-myclusterrole
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: myclusterrole
subjects:
- apiGroup: rbac.authorization.k8s.io
kind: User
name: timinglee

纵情码海钱塘涌,杭州开发者创新动! 属于杭州的开发者社区!致力于为杭州地区的开发者提供学习、合作和成长的机会;同时也为企业交流招聘提供舞台!
更多推荐



 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)