AI研究员必看:手把手教你选对GPU,租用算力不再花冤枉钱
要确保算力资源精准匹配 AI 研究需求,需遵循 “需求量化→资源匹配→实测验证→动态适配” 的逻辑,从基础资源、配合调度(实际性能)、运营维护、应用服务等多维度层层把关,具体可拆解为以下 5 个核心步骤:
一、第一步:精准量化 AI 研究的 “算力需求基线”
在租用前,必须先将模糊的 “研究需求” 转化为可量化的技术指标,避免因需求不明确导致资源过剩或不足。核心需明确以下 4 类关键需求:
1. 模型与任务维度(核心驱动因素)
不同 AI 任务(训练 / 推理、大模型 / 小模型)对算力的需求差异极大,需先明确:
- 任务类型:是模型训练(需高算力、大显存,支持反向传播)还是推理(算力需求较低,更关注延迟)?
- 例:训练一个 10 亿参数的 LLM(如 Llama-2-7B)需高算力 GPU 集群;而基于预训练模型做图像分类推理,单块中端 GPU 即可。
- 模型规模:模型参数数量、层数、激活函数复杂度(如 Transformer 架构比 CNN 更耗算力)。
- 参考:10 亿参数以下模型(如 ResNet-50、BERT-base)可单卡训练;10-100 亿参数(如 Llama-2-13B)需 4-8 块中端 GPU(如 A100 40GB);100 亿以上(如 GPT-3)需数十块高端 GPU(如 H100 80GB)+ 高速互联。
- 数据规模与处理方式:数据集大小(如百万级图像、TB 级文本)、 batch size(批次越大,显存需求越高)、数据预处理复杂度(如实时图像增强、文本 tokenize)。
2. 核心算力指标(量化硬件需求)
将上述需求转化为可落地的硬件参数指标,避免 “只看 GPU 型号,不看实际能力”:
- 算力(FLOPs):训练任务关注FP32/FP16/BF16 算力(AI 训练常用混合精度,BF16 比 FP16 更稳定),推理任务可关注INT8/FP8 算力(量化推理更高效)。
- 例:训练 Llama-2-7B 需约 100 TFLOPs-days(即 1 块 A100 40GB(算力 312 TFLOPs FP16)需连续运行约 8 小时)。
- 显存(VRAM):显存不足会直接导致 “OOM(Out of Memory)”,需满足 “模型参数占用 + 批次数据占用 + 中间激活值占用”:
- 估算公式:模型显存占用 ≈ 模型参数数 × 2(FP16)/ 4(FP32);若用模型并行(如 Megatron-LM),可按 GPU 数量分摊显存。
- 例:Llama-2-7B(70 亿参数)用 FP16 训练,单卡需约 14GB 显存(70 亿 ×2 字节),若 batch size=32,需额外预留 10-15GB,故至少需 32GB 显存(如 A100 40GB、RTX 4090)。
- 计算效率:关注 GPU 的Tensor Core 利用率(NVIDIA GPU 的核心加速单元,需框架支持如 PyTorch AMP)、是否支持 “模型并行 / 数据并行”(多卡协同能力)。
3. 辅助资源需求(避免瓶颈)
除 GPU 外,CPU、内存、存储、网络若不匹配,会成为 “算力瓶颈”,需同步明确:
- CPU 与系统内存(RAM):负责数据加载、任务调度,若 RAM 不足,数据无法快速传入 GPU,导致 GPU 空闲(“算力浪费”)。
- 建议:训练任务中,RAM ≥ 2×GPU 显存(如单卡 A100 40GB,RAM 至少 64GB;8 卡集群 RAM 至少 256GB);CPU 选多核高频(如 Intel Xeon Gold、AMD EPYC,核心数≥16)。
- 存储性能:数据读取速度直接影响训练效率,尤其是大规模数据集:
- 小规模任务:NVMe SSD(读写速度≥3000MB/s);
- 大规模任务:分布式存储(如 Ceph)+ NVMe SSD 缓存,支持 TB 级吞吐量。
- 网络带宽(多卡 / 多机场景):多卡并行训练时,GPU 间需频繁传输梯度数据,网络延迟会严重拖慢速度:
- 单节点多卡:需支持 PCIe 4.0/5.0 或 NVIDIA NVLink(如 A100 支持 NVLink,多卡通信速度是 PCIe 的 5 倍以上);
- 多节点集群:需 InfiniBand 网络(带宽≥100Gbps,延迟≤1 微秒),避免用普通以太网(延迟高,多机训练效率骤降)。
二、第二步:基于需求基线,精准匹配算力资源
明确需求后,需从算力平台的 “硬件配置、软件兼容性、服务稳定性” 三方面筛选,确保资源 “不超额、不缺配”:
1. 匹配参数:
-
- 模型参数<10B:24GB 显存(RTX 4090)足够。
- 模型参数 10B-100B:40-80GB 显存(A100 80GB)。
- 模型参数>100B:多卡 H100 集群(依赖 NVLink 互联)。
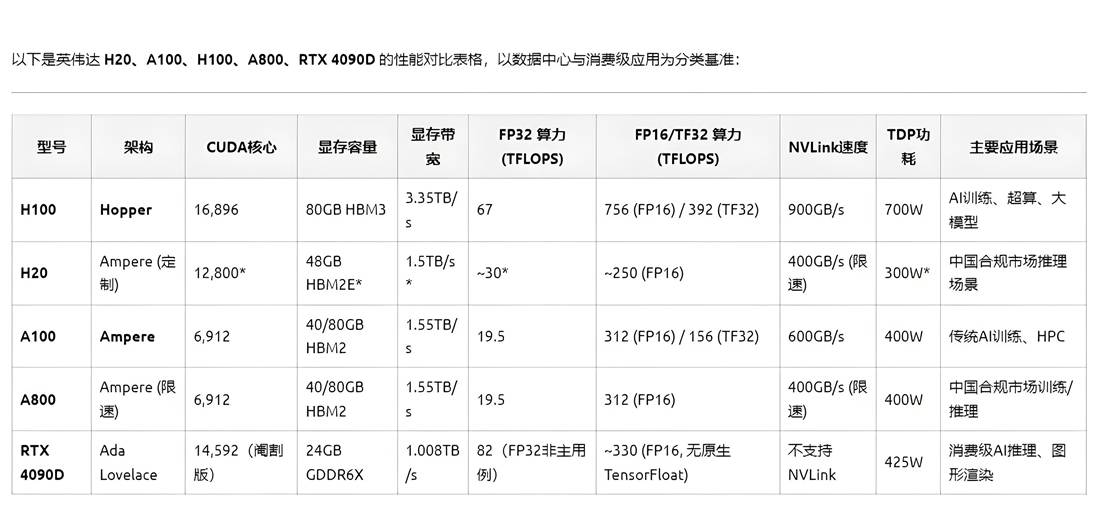
2. 硬件配置匹配:拒绝 “型号陷阱”
- GPU 型号精准筛选:根据 “算力 - 显存” 需求选择 GPU,避免盲目追求 “最新款”(如 H100 虽强,但小模型用 A100 更划算):
|
需求场景 |
推荐 GPU 型号 |
核心优势 |
|
小模型训练 / 推理(如 CNN、BERT-base) |
RTX 4090、A5000、T4 |
显存足(24-48GB)、性价比高 |
|
中规模模型训练(如 Llama-2-7B/13B) |
A100(40GB/80GB)、A800 |
算力强、支持 NVLink |
|
大规模模型训练(如 GPT-3、LLaMA 2-70B) |
H100、H800 |
支持 FP8、算力是 A100 的 3 倍 + |
|
低成本推理(如边缘部署) |
Jetson AGX Orin、RTX 3080 |
低功耗、适合轻量任务 |
- 确认硬件真实性:部分平台可能存在 “GPU 虚拟化超售”(如 1 块物理 GPU 分割给多个用户),需确认:
1、是否提供 “独占 GPU”(确保算力不被共享);
2、查看 GPU 型号是否可通过nvidia-smi命令验证(租用后第一时间执行,确认型号、显存、算力是否与宣传一致)。
3. 软件环境匹配:避免 “兼容性坑”
AI 训练依赖特定框架和驱动,需确保平台支持:
- 基础环境:操作系统(优先 Linux Ubuntu 20.04/22.04,兼容性最佳)、NVIDIA 驱动版本(需匹配 CUDA 版本,如 CUDA 12.2 需驱动≥535.86.05)。
- 框架与工具:是否预装常用 AI 框架(PyTorch、TensorFlow、Megatron-LM、DeepSpeed)、并行计算工具(MPI、NCCL)、容器化支持(Docker、Singularity,方便环境复刻)。
- 自定义需求:若需特殊库(如 CUDA 扩展、自定义算子),需确认平台是否允许安装 root 权限软件,或是否提供 “自定义镜像” 功能。
4. 服务稳定性匹配:保障研究连续性
AI 训练常需数小时至数天,稳定性至关重要:
- SLA(服务等级协议):优先选择承诺 “可用性≥99.9%” 的平台,避免因硬件故障、网络中断导致训练中断(尤其是多卡集群,单卡故障可能导致整个任务失败)。
- 故障恢复机制:询问平台是否支持 “checkpoint 自动备份”(训练中断后可从最近 checkpoint 恢复,而非从头开始)、硬件故障时的 “快速换机” 服务(如 1 小时内替换故障 GPU)。
- 数据安全:若研究涉及敏感数据(如医疗、隐私文本),需确认平台是否提供:
- 数据加密(传输加密 SSL/TLS、存储加密 AES);
- 访问控制(如 VPC 私有网络、IAM 权限管理,避免数据泄露);
- 合规认证(如 ISO 27001、等保三级,尤其企业 / 学术研究需符合数据合规要求)。
三、第三步:实测验证算力性能,排除 “纸面参数陷阱”
即使参数匹配,实际性能也可能因平台优化、硬件老化、资源超售等问题不达标,需通过小成本测试验证:
1. 基础性能测试:确认硬件达标
租用后第一时间执行基础命令,验证硬件真实性和基础性能:
- GPU 信息验证:执行nvidia-smi,确认:
- 型号(如 “Tesla A100” 而非 “Virtual GPU”);
- 显存(如 40GB/40960MiB,无共享显存);
- 算力状态(“Volatile GPU-Util” 是否正常,无异常占用)。
- 算力 benchmark 测试:用工具测试实际算力是否达标:
- 用nvidia-smi -l 1观察 GPU 利用率(跑一个小任务如 PyTorch 的矩阵乘法,看利用率是否能达到 90% 以上,若持续低于 50%,可能存在资源限制);
- 用专业工具(如 MLPerf、GPU-Burn)测试 FP16/BF16 算力,对比官方标称值(如 A100 40GB 官方 FP16 算力 312 TFLOPs,实测应接近该值,误差不超过 10%)。
2. 任务适配测试:模拟真实研究场景
用简化版研究任务测试算力是否满足需求,避免直接跑完整任务导致浪费:
- 小数据 + 小批次测试:用 10% 的数据集、较小的 batch size(如原计划 batch size=32,先测 batch size=8),运行 1-2 个 epoch,观察:
- 训练速度:记录每秒迭代次数(iter/s),估算完整任务所需时间(若比预期慢 50% 以上,需排查原因:是 GPU 性能不足、还是数据加载瓶颈?);
- 显存占用:用nvidia-smi观察峰值显存(若峰值接近 GPU 显存上限,需减小 batch size 或启用梯度检查点(Gradient Checkpointing),避免正式训练 OOM);
- 稳定性:连续运行 1 小时,查看是否出现 GPU 掉卡、网络断连、算力波动(如 util 忽高忽低)。
- 多卡并行测试(多卡场景):若用多卡训练,需测试并行效率(并行效率 = 多卡总速度 / 单卡速度 × 卡数):
- 单节点多卡:效率应≥80%(如 2 卡效率≥1.6,4 卡≥3.2),若低于 70%,可能是 NVLink/PCIe 带宽不足;
- 多节点集群:效率应≥70%(如 2 节点 8 卡效率≥5.6),若过低,需检查 InfiniBand 网络是否正常。
四、第四步:关注弹性与成本,适配研究动态需求
AI 研究可能因模型迭代、数据扩充调整算力需求,需确保平台支持 “动态适配”:
- 弹性扩展:确认平台是否支持 “按需加卡 / 减卡”(如原租 4 卡,训练中发现不够,能否临时加 4 卡,且支持多卡任务无缝衔接);
- 成本可控:选择 “按秒 / 按小时计费” 的平台(如 AutoDL、RunPod),避免长期包机(若研究中途调整方案,可及时停租,减少浪费);同时关注 “闲置资源折扣”(如夜间、凌晨算力价格更低,可调度非关键任务在低价时段运行);
-
如 “智算云扉 GPU算力云租赁平台|AI大模型训练|按需付费|专业稳定|智算云扉、算吧 https://www.suanba.cc/index”等租赁平台,支持按量计费。
- 资源监控:通过平台提供的监控工具(如 GPU 利用率、网络带宽、存储 IO),实时查看资源是否闲置(如 GPU 利用率长期低于 30%,说明算力过剩,可减卡)。
五、第五步:锁定服务支持,应对突发问题
AI 研究中可能遇到硬件故障、软件兼容性问题,需平台提供及时支持:
- 技术支持响应速度:优先选择 “7×24 小时在线客服 + 工程师对接” 的平台,避免仅靠工单(响应慢,可能延误研究);
- 文档与社区:查看平台是否提供 “AI 训练最佳实践” 文档(如多卡并行配置、OOM 解决方案)、用户社区(如论坛、微信群),方便快速解决常见问题;
- 定制化支持:若研究涉及特殊需求(如自定义 GPU 集群、专用存储方案),需确认平台是否提供 “定制化部署” 服务(如华为云 ModelArts、AWS SageMaker 的专属集群服务)。
总结:确保算力匹配的核心逻辑
最终,“满足需求” 的本质是 “需求量化→精准匹配→实测验证→动态调整” 的闭环:
先通过模型、数据明确 “算力 - 显存 - 辅助资源” 的量化指标,再基于指标筛选硬件真实、软件兼容的平台,用小任务实测性能,最后通过弹性服务和及时支持,应对研究中的动态需求。通过这一流程,可最大程度避免 “算力不足导致任务失败” 或 “算力过剩导致成本浪费”,确保租用的算力精准服务于 AI 研究。

纵情码海钱塘涌,杭州开发者创新动! 属于杭州的开发者社区!致力于为杭州地区的开发者提供学习、合作和成长的机会;同时也为企业交流招聘提供舞台!
更多推荐


 31
31 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)