【机器学习】利用 Pipeline 提升工作流效率
机器学习项目通常需要执行一系列数据预处理步骤,然后再运行学习算法。逐一管理这些步骤可能既繁琐又容易出错。这正是 sklearn pipeline 发挥作用的地方。本文将探讨 pipeline 如何自动化机器学习工作流程中的关键环节,例如数据预处理、特征工程以及机器学习算法的整合。
【精选优质专栏推荐】
- 《AI 技术前沿》 —— 紧跟 AI 最新趋势与应用
- 《网络安全新手快速入门(附漏洞挖掘案例)》 —— 零基础安全入门必看
- 《BurpSuite 入门教程(附实战图文)》 —— 渗透测试必备工具详解
- 《网安渗透工具使用教程(全)》 —— 一站式工具手册
- 《CTF 新手入门实战教程》 —— 从题目讲解到实战技巧
- 《前后端项目开发(新手必知必会)》 —— 实战驱动快速上手
每个专栏均配有案例与图文讲解,循序渐进,适合新手与进阶学习者,欢迎订阅。

前言
机器学习项目通常需要执行一系列数据预处理步骤,然后再运行学习算法。逐一管理这些步骤可能既繁琐又容易出错。这正是 sklearn pipeline 发挥作用的地方。本文将探讨 pipeline 如何自动化机器学习工作流程中的关键环节,例如数据预处理、特征工程以及机器学习算法的整合。
什么是管道(Pipeline)?
pipeline 用于将各种转换步骤和最终的估计器按顺序自动化并封装为一个对象。通过定义 pipeline,可以确保相同的步骤顺序同时应用于训练数据和测试数据,从而提高模型的可复现性和可靠性。
下面我们将演示如何实现一个 pipeline,并与不使用 pipeline 的传统方法进行比较。考虑一个简单的场景:我们希望根据房屋的质量预测房价,使用 Ames Housing 数据集中的 OverallQual 特征。以下是使用和不使用 pipeline 进行 5 折交叉验证的对比:
# 导入必要的库
import pandas as pd
from sklearn.model_selection import cross_val_score
from sklearn.linear_model import LinearRegression
from sklearn.pipeline import Pipeline
# 准备数据并设置线性回归
Ames = pd.read_csv('Ames.csv')
y = Ames['SalePrice']
linear_model = LinearRegression()
# 不使用 Pipeline 的 5 折交叉验证
cv_score = cross_val_score(linear_model, Ames[['OverallQual']], y).mean()
print("Example Without Pipeline, Mean CV R² score for 'OverallQual': {:.3f}".format(cv_score))
# 使用 Pipeline 的 5 折交叉验证
pipeline = Pipeline([('regressor', linear_model)])
pipeline_score = cross_val_score(pipeline, Ames[['OverallQual']], y, cv=5).mean()
print("Example With Pipeline, Mean CV R² for 'OverallQual': {:.3f}".format(pipeline_score))
两种方法得到完全相同的结果:
Example Without Pipeline, Mean CV R² score for 'OverallQual': 0.618
Example With Pipeline, Mean CV R² for 'OverallQual': 0.618
下面有一个图示来展示这个基础 pipeline。

这个示例使用了一个只有单一特征的简单情况。然而,随着模型变得更复杂,pipeline 可以在应用模型之前处理多个预处理步骤,例如缩放、编码和降维。
在对 sklearn pipeline 有了基础理解的基础上,我们将扩展场景,加入特征工程——这是提升模型性能的重要步骤。特征工程指的是从现有数据中创建新的特征,这些特征可能与目标变量有更强的关系。在我们的例子中,我们怀疑房屋质量与居住面积的交互作用,可能比单独的特征更能预测房价。以下是使用和不使用 pipeline 进行 5 折交叉验证的并列比较:
# 导入必要的库
import pandas as pd
from sklearn.model_selection import cross_val_score
from sklearn.linear_model import LinearRegression
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import FunctionTransformer
# 准备数据并设置线性回归
Ames = pd.read_csv('Ames.csv')
y = Ames['SalePrice']
linear_model = LinearRegression()
# 不使用 Pipeline 的 5 折交叉验证
Ames['OWA'] = Ames['OverallQual'] * Ames['GrLivArea']
cv_score_2 = cross_val_score(linear_model, Ames[['OWA']], y).mean()
print("Example Without Pipeline, Mean CV R² score for 'Quality Weighted Area': {:.3f}".format(cv_score_2))
# 使用 Pipeline
# 定义生成 'QualityArea' 的转换函数
def create_quality_area(X):
X['QualityArea'] = X['OverallQual'] * X['GrLivArea']
return X[['QualityArea']].values
# 使用该函数设置 FunctionTransformer
quality_area_transformer = FunctionTransformer(create_quality_area)
# 使用工程特征 'QualityArea' 的 Pipeline
pipeline_2 = Pipeline([
('quality_area_transform', quality_area_transformer),
('regressor', linear_model)
])
pipeline_score_2 = cross_val_score(pipeline_2, Ames[['OverallQual', 'GrLivArea']], y, cv=5).mean()
# 输出保留四位小数的平均 CV 分数
print("Example With Pipeline, Mean CV R² score for 'Quality Weighted Area': {:.3f}".format(pipeline_score_2))
两种方法再次得到了相同的结果:
Example Without Pipeline, Mean CV R² score for 'Quality Weighted Area': 0.748
Example With Pipeline, Mean CV R² score for 'Quality Weighted Area': 0.748
这个输出表明,通过使用 pipeline,我们将特征工程封装进模型训练过程,使其成为交叉验证的一个组成部分。在 pipeline 中,每个交叉验证折都会生成 Quality Weighted Area 特征,确保特征工程步骤得到正确验证,避免数据泄漏,从而产生更可靠的模型性能估计。
下面有一个图示来展示我们如何在该 pipeline 的预处理步骤中使用 FunctionTransformer:
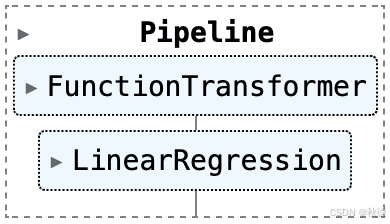
提升模型:高级特征变换
在下面的示例中,我们引入了三次变换(cubic transformation)、人工构造特征(engineered features)、类别编码(categorical encoding),并且同时保留了未经过任何变换的原始特征。这展示了管道(pipeline)如何处理不同数据类型与变换方式的组合,将预处理与建模步骤整合为一个有机的整体过程。
# 导入必要库
import pandas as pd
from sklearn.model_selection import cross_val_score
from sklearn.linear_model import LinearRegression
from sklearn.pipeline import Pipeline
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import FunctionTransformer, OneHotEncoder
# 准备数据并设置线性回归
Ames = pd.read_csv('Ames.csv')
y = Ames['SalePrice']
linear_model = LinearRegression()
# 定义三次变换函数
def cubic_transformation(x):
return x ** 3
# 定义构造“QualityArea”特征的函数
def create_quality_area(X):
X['QualityArea'] = X['OverallQual'] * X['GrLivArea']
return X[['QualityArea']].values
# 为三次变换和 QualityArea 变换设置 FunctionTransformer
cubic_transformer = FunctionTransformer(cubic_transformation)
quality_area_transformer = FunctionTransformer(create_quality_area)
# 设置 ColumnTransformer 进行预处理
preprocessor = ColumnTransformer(
transformers=[
('cubic', cubic_transformer, ['OverallQual']),
('quality_area_transform', quality_area_transformer, ['OverallQual', 'GrLivArea']),
('onehot', OneHotEncoder(drop='first', handle_unknown='ignore'), ['Neighborhood', 'ExterQual', 'KitchenQual']),
('passthrough', 'passthrough', ['YearBuilt'])
])
# 创建包含预处理器与线性回归的管道
pipeline_3 = Pipeline([
('preprocessor', preprocessor),
('regressor', linear_model)
])
# 使用 5 折交叉验证评估管道
pipeline_score_3 = cross_val_score(pipeline_3, Ames, y, cv=5).mean()
# 输出四位小数的平均交叉验证得分
print("Mean CV R² score with enhanced transformations: {:.3f}".format(pipeline_score_3))
特征工程是一门艺术,常常需要一定的创造性。在这里,我们将 OverallQual 特征进行三次变换,假设这样能够更好地捕捉质量与价格之间的非线性关系。此外,我们构造了一个新的 QualityArea 特征,我们认为它与售价的相关性可能比单独的特征更强。对于类别特征 Neighborhood、ExterQual 和 KitchenQual,我们采用独热编码(one-hot encoding),这是将文本型数据转化为模型可用格式的关键步骤。与此同时,我们直接将 YearBuilt 特征传入模型,以保留其中有价值的时间信息,而不做多余的变换。
上述管道的结果如下:
Mean CV R² score with enhanced transformations: 0.850
平均交叉验证 R² 分数达到 0.850,说明经过精心设计的特征工程与预处理能对模型性能产生显著提升。这进一步展示了管道在效率与可扩展性上的优势,并凸显了其在构建稳健预测模型中的战略价值。
下图展示了该管道的结构:

这种方法的真正优势在于其统一的工作流程。通过将特征工程、变换和模型评估优雅地整合到一个连贯的流程中,管道显著提升了预测模型的准确性和可靠性。这个高级示例进一步说明,使用管道时,工作流程的复杂性不会以牺牲清晰性或性能为代价。
在管道中处理缺失数据(Imputation)
大多数数据集,尤其是大型数据集,通常包含缺失值。忽略这些缺失值可能导致预测模型产生显著偏差或错误。本节展示如何将数据填补(imputation)无缝整合到管道中,确保线性回归模型能够稳健应对缺失数据问题。
在之前的文章中,我们探讨了缺失数据,手动对 Ames 数据集中的缺失值进行了填补,而未使用管道。在此基础上,我们演示如何在管道框架中自动化和简化填补操作,这种方法更高效、减少出错,甚至对新手也适用。
我们选择使用 SimpleImputer 来处理 BsmtQual(地下室质量)特征的缺失值,该特征为类别型变量。SimpleImputer 会将缺失值替换为常量 ‘None’,表示地下室不存在。填补后,我们使用 OneHotEncoder 将类别数据转换为线性模型可用的数值格式。通过将填补操作嵌入管道,我们保证了训练和测试阶段均正确应用填补策略,从而避免数据泄露,并在交叉验证中保持模型评估的完整性。
以下为管道实现方式:
# 导入必要库
import pandas as pd
from sklearn.model_selection import cross_val_score
from sklearn.linear_model import LinearRegression
from sklearn.pipeline import Pipeline
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import FunctionTransformer, OneHotEncoder
from sklearn.impute import SimpleImputer
# 载入数据
Ames = pd.read_csv('Ames.csv')
y = Ames['SalePrice']
linear_model = LinearRegression()
# 三次变换函数
def cubic_transformation(x):
return x ** 3
# 构造 QualityArea 特征函数
def create_quality_area(X):
X['QualityArea'] = X['OverallQual'] * X['GrLivArea']
return X[['QualityArea']].values
# 设置 FunctionTransformer
cubic_transformer = FunctionTransformer(cubic_transformation)
quality_area_transformer = FunctionTransformer(create_quality_area)
# 为 BsmtQual 填补和编码设置嵌套管道
bsmt_qual_transformer = Pipeline([
('imputer', SimpleImputer(strategy='constant', fill_value='None')),
('encoder', OneHotEncoder(handle_unknown='ignore'))
])
# 设置 ColumnTransformer 进行所有预处理
preprocessor = ColumnTransformer(
transformers=[
('cubic', cubic_transformer, ['OverallQual']),
('quality_area_transform', quality_area_transformer, ['OverallQual', 'GrLivArea']),
('onehot', OneHotEncoder(drop='first', handle_unknown='ignore'), ['Neighborhood', 'ExterQual', 'KitchenQual']),
('bsmt_qual', bsmt_qual_transformer, ['BsmtQual']), # 添加 BsmtQual 处理
('passthrough', 'passthrough', ['YearBuilt'])
])
# 创建包含预处理器和线性回归的管道
pipeline_4 = Pipeline([
('preprocessor', preprocessor),
('regressor', linear_model)
])
# 使用 5 折交叉验证评估管道
pipeline_score = cross_val_score(pipeline_4, Ames, y, cv=5).mean()
# 输出平均交叉验证得分
print("Mean CV R² score with imputing & transformations: {:.3f}".format(pipeline_score))
在管道中使用 SimpleImputer 可高效处理缺失数据。结合其他预处理步骤与线性回归模型,整个流程能够真实评估预处理选择对模型性能的影响。
Mean CV R² score with imputing & transformations: 0.856
下图展示了包含缺失数据填补的管道结构。

这种集成展示了 sklearn 管道的灵活性,并强调了诸如缺失值填补等关键预处理步骤如何无缝嵌入机器学习工作流,从而提升模型的可靠性和准确性。
总结
在本文中,我们探讨了 sklearn 管道的应用,并最终展示了在处理线性回归缺失值时,数据填补的高级集成。我们演示了数据预处理步骤、特征工程以及高级变换的无缝自动化,从而优化模型性能。本文强调的方法不仅保持了工作流的高效性,也确保了预测模型的一致性和准确性。

欢迎加入我们的广州开发者社区,与优秀的开发者共同成长!
更多推荐
 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)