
零基础本地部署DEEPSEEK大模型教程(LM Studio版)
上面两部主要是看CUDA是否成功加载,不然是CPU跑可能就很慢,一般来说都没有问题,有问题可能需要安装CUDA的库。在框中输入刚才搜的模型,因为你搜的模型会告诉你这个模型是否符合你的电脑配置,注:DEEPSEEK R1的GGUF量化版(如Q4_K_M)约需8GB显存。国内网盘镜像(含DEEPSEEK R1各量化版本): 暂未上传。:消费级显卡即可运行(实测NVIDIA 4060s流畅运行)(使用V
一、部署优势
-
无需代码基础:全程可视化操作
-
低硬件门槛:消费级显卡即可运行(实测NVIDIA 4060s流畅运行)
-
即装即用:模型加载后可直接对话
-
隐私安全:数据完全本地运行
二、准备工作
1. 硬件要求
| 组件 | 最低配置 | 推荐配置 |
|---|---|---|
| GPU | NVIDIA GTX 1060(6GB显存) | RTX 3060及以上 |
| 内存 | 8GB | 16GB |
| 存储 | 固态硬盘剩余空间≥20GB | NVMe固态硬盘 |
注:DEEPSEEK R1的GGUF量化版(如Q4_K_M)约需8GB显存
2. 软件准备
-
LM Studio安装包:官网下载地址
(支持Windows/macOS/Linux) -
CUDA驱动验证(Windows):
nvidia-smi # 查看CUDA版本是否≥11.8三、部署全流程
▶ 步骤1:加速下载配置(关键!)
(不做这步骤的化进入LM studio后搜索模型会无法下载)
-
退出LM Studio客户端
-
定位安装目录:
# Windows默认路径
C:\Users\[用户名]\AppData\Local\Programs\lm-studio3. 修改核心文件:
-
用文本编辑器打开:
\resources\app.webpack\main\index.js
\resources\app.webpack\renderer\main_window.js-
全局替换
huggingface.co→hf-mirror.com
(使用VS Code/VSCode的批量替换功能更高效)
▶ 步骤2:模型获取
方式一:客户端直装(推荐)
打开LM Studio
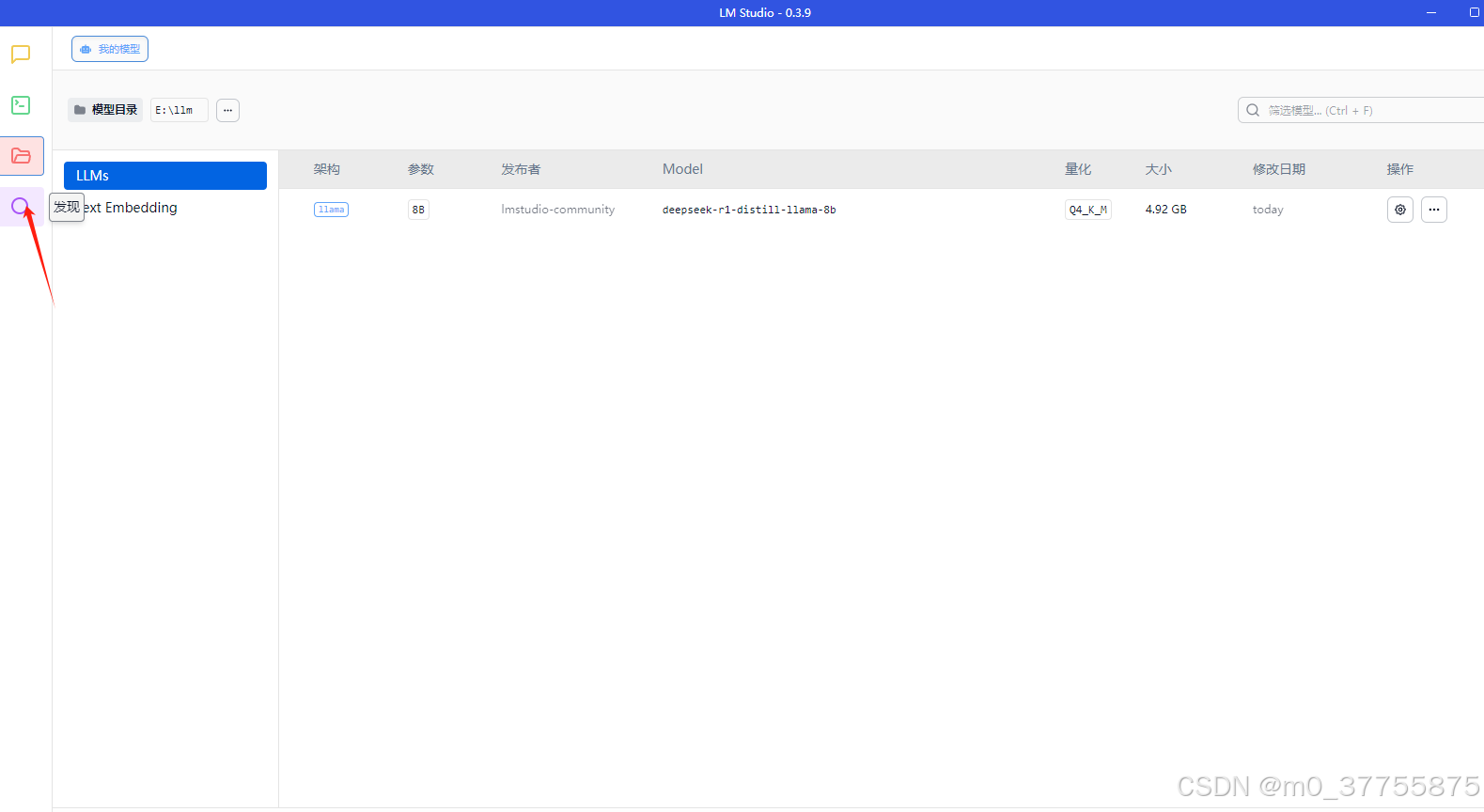
查看电脑硬件情况
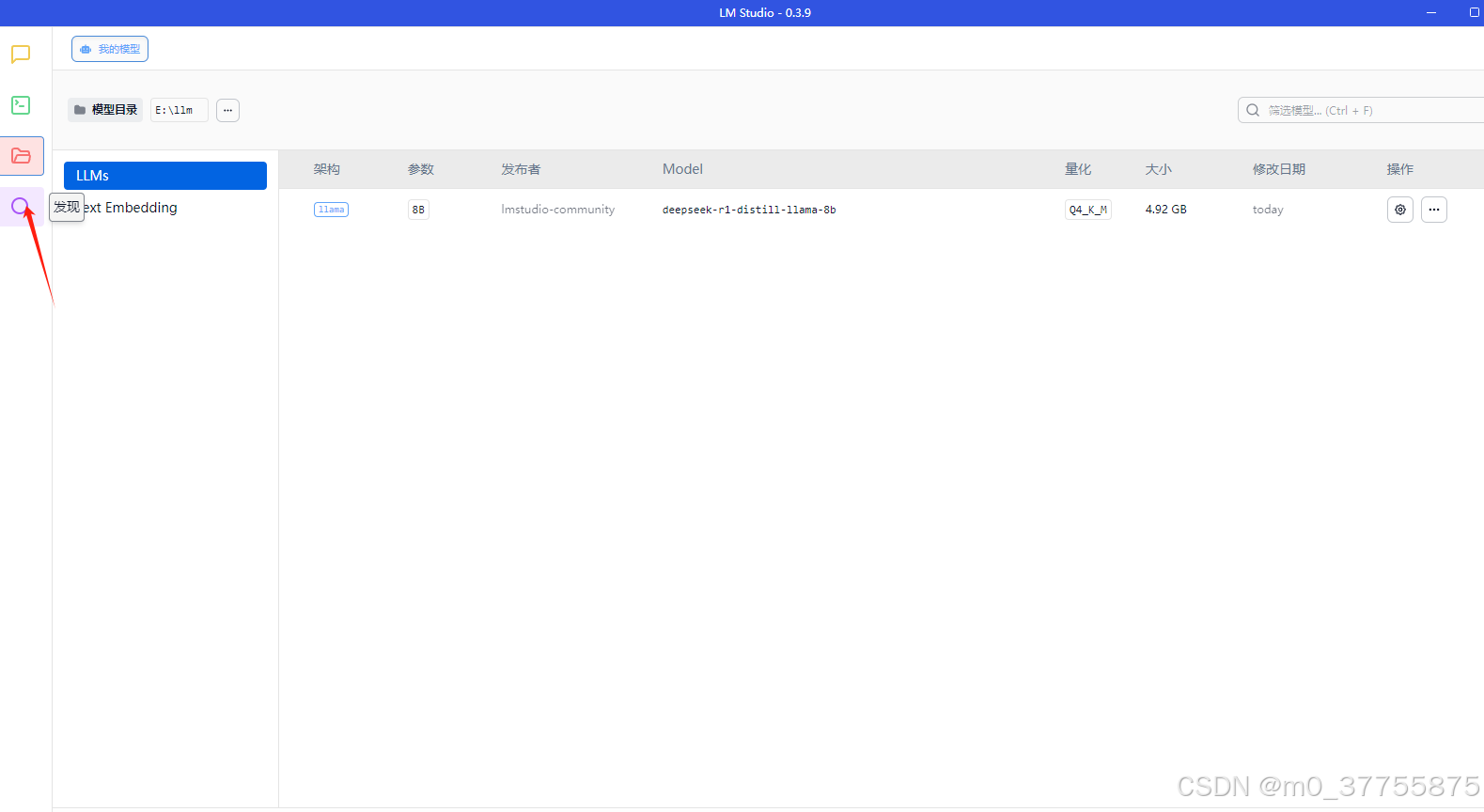
查看runtime情况
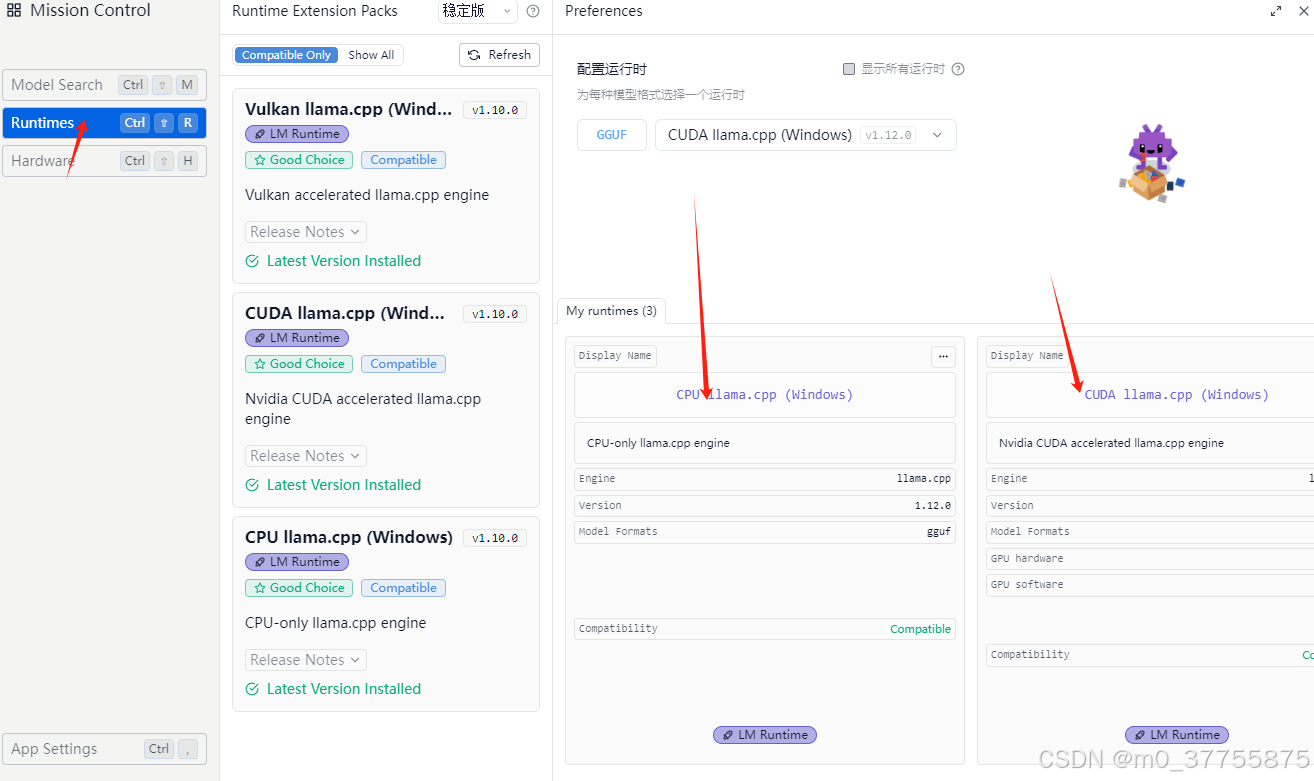
上面两部主要是看CUDA是否成功加载,不然是CPU跑可能就很慢,一般来说都没有问题,有问题可能需要安装CUDA的库
搜索想要的模型
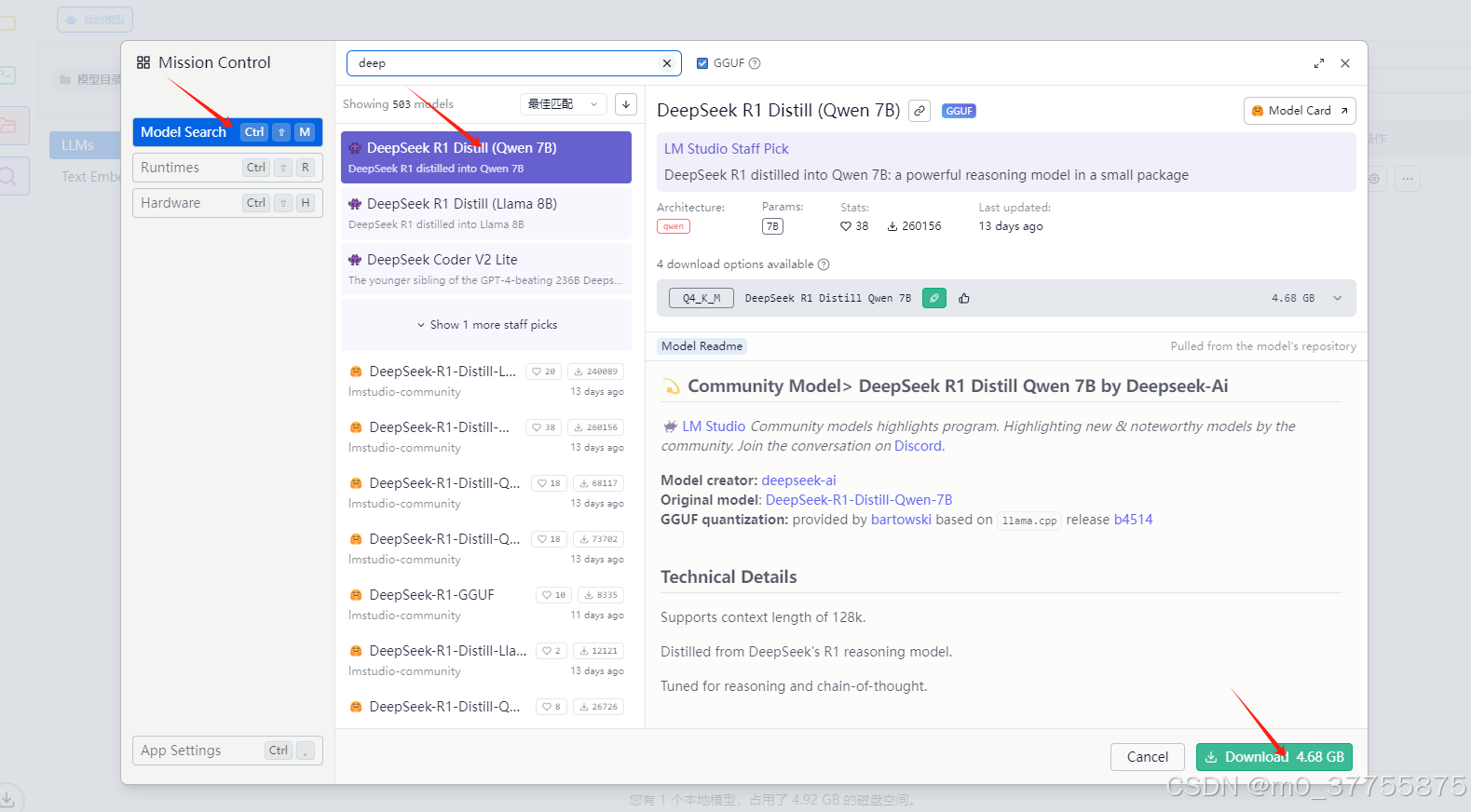
如果没有downlowad图标则说明没有做好2 替换本地镜像工作
点击下载
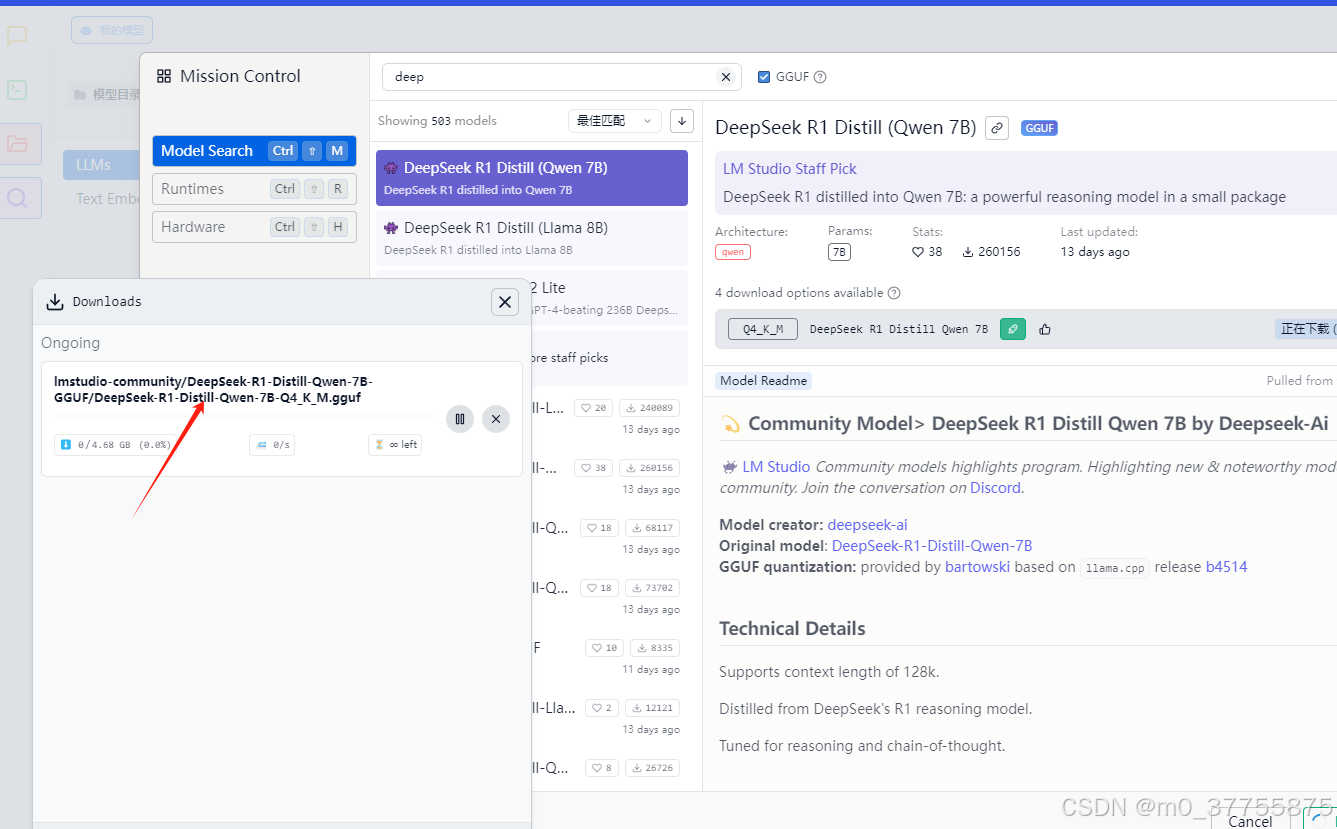
方式二:手动下载(备用方案,可能更快)
打开网址https://huggingface.co/lmstudio-community
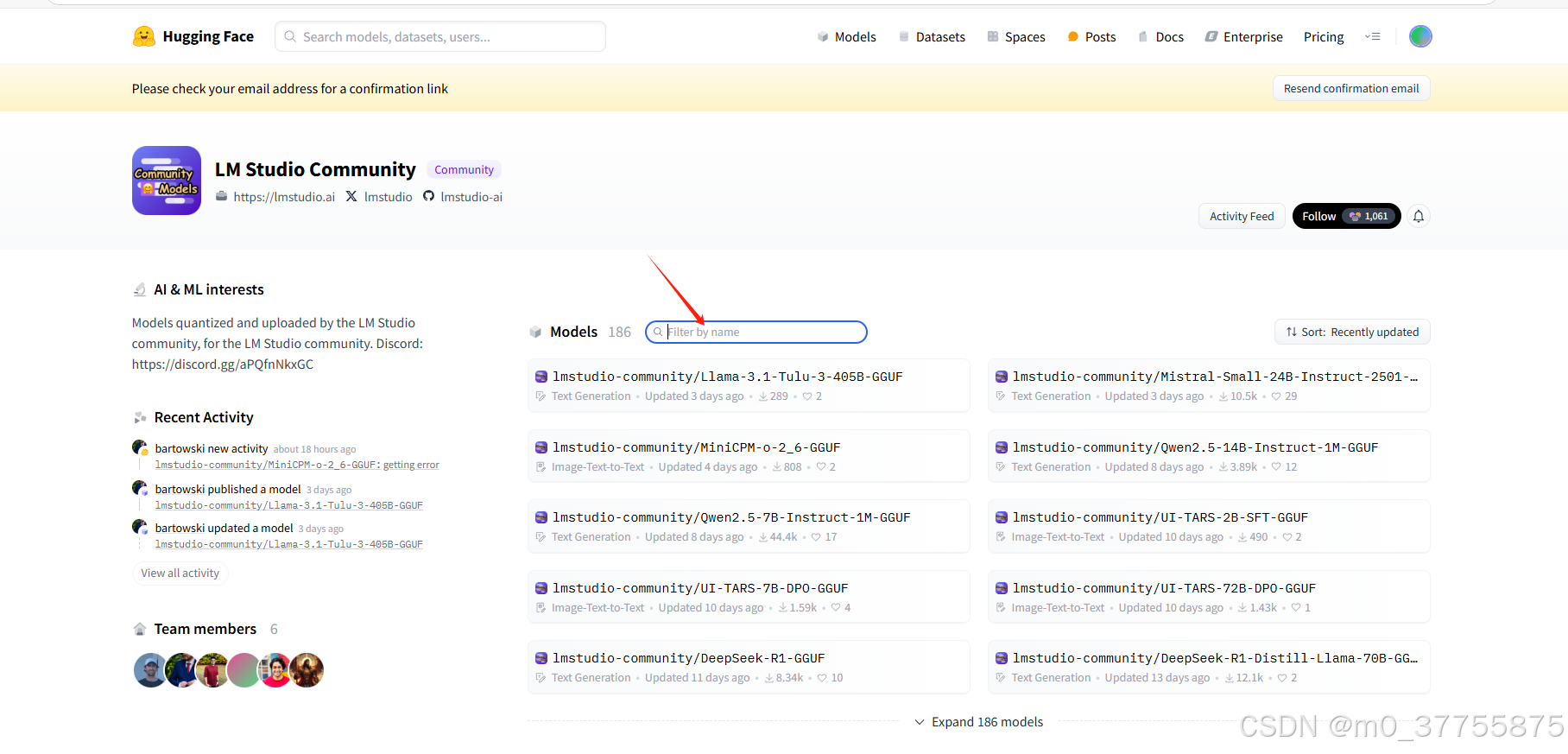
在框中输入刚才搜的模型,因为你搜的模型会告诉你这个模型是否符合你的电脑配置,
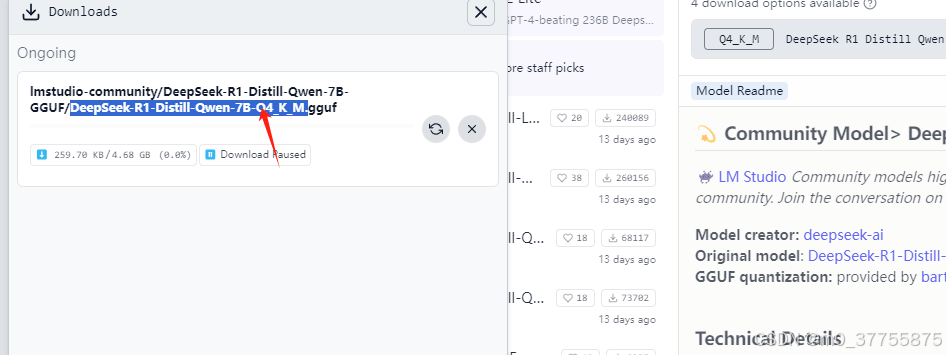
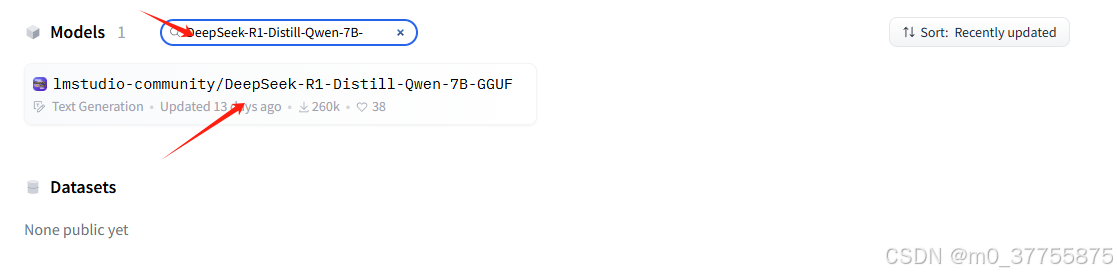
点击进去后下载模型
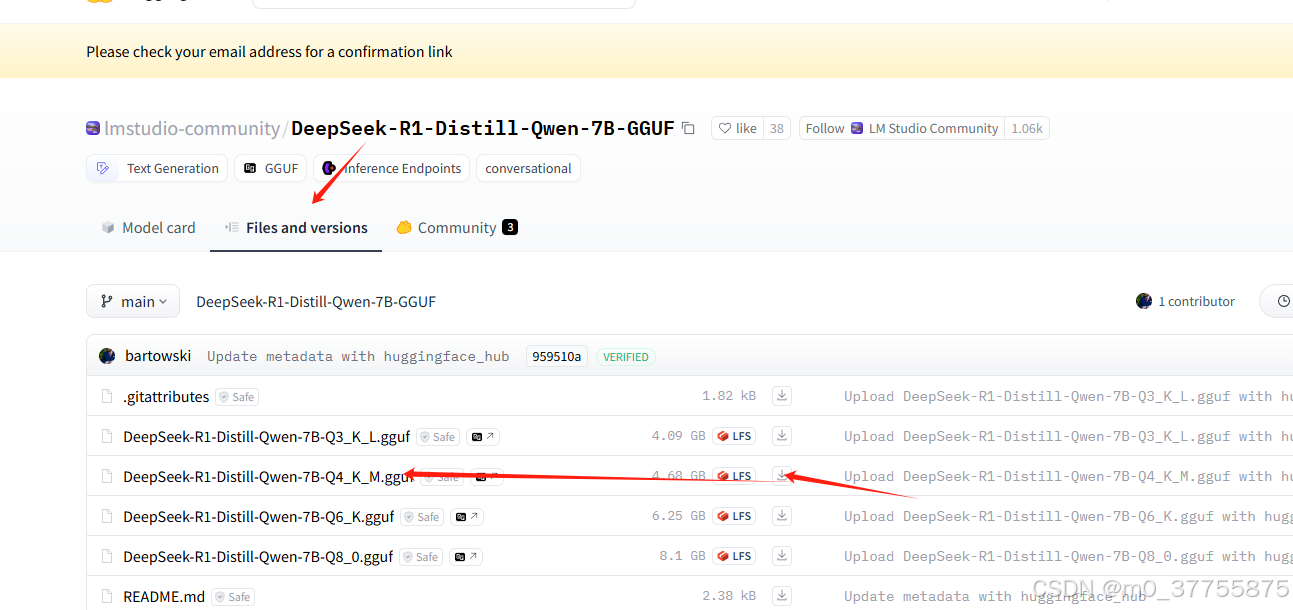
下载到本地后,放到
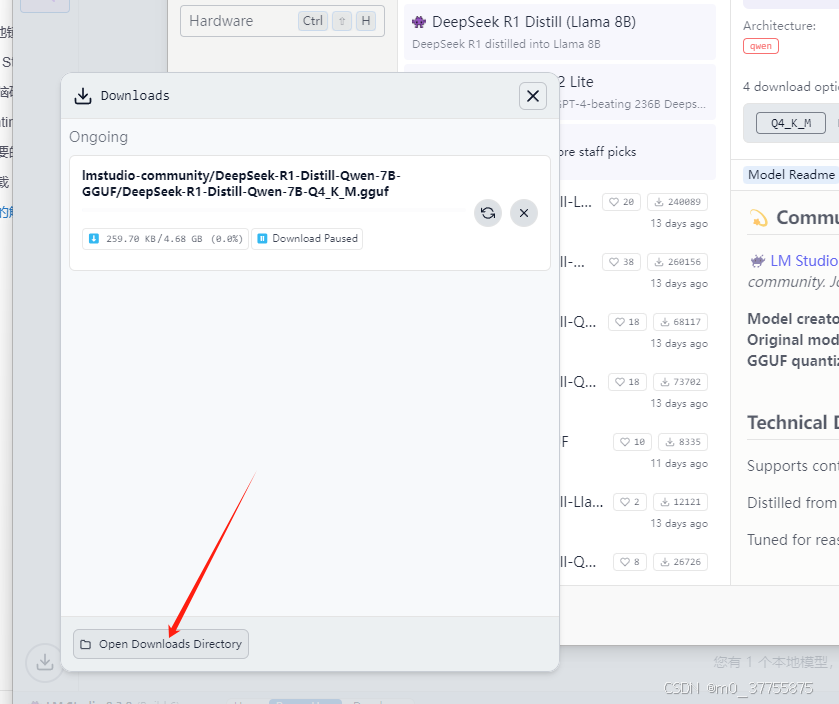
打开下载目录,进入到最内层目录
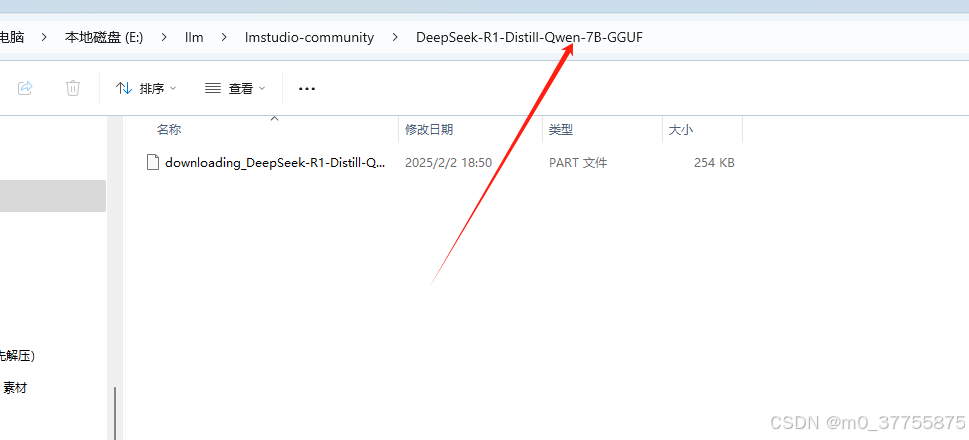
将下载模型粘贴进去
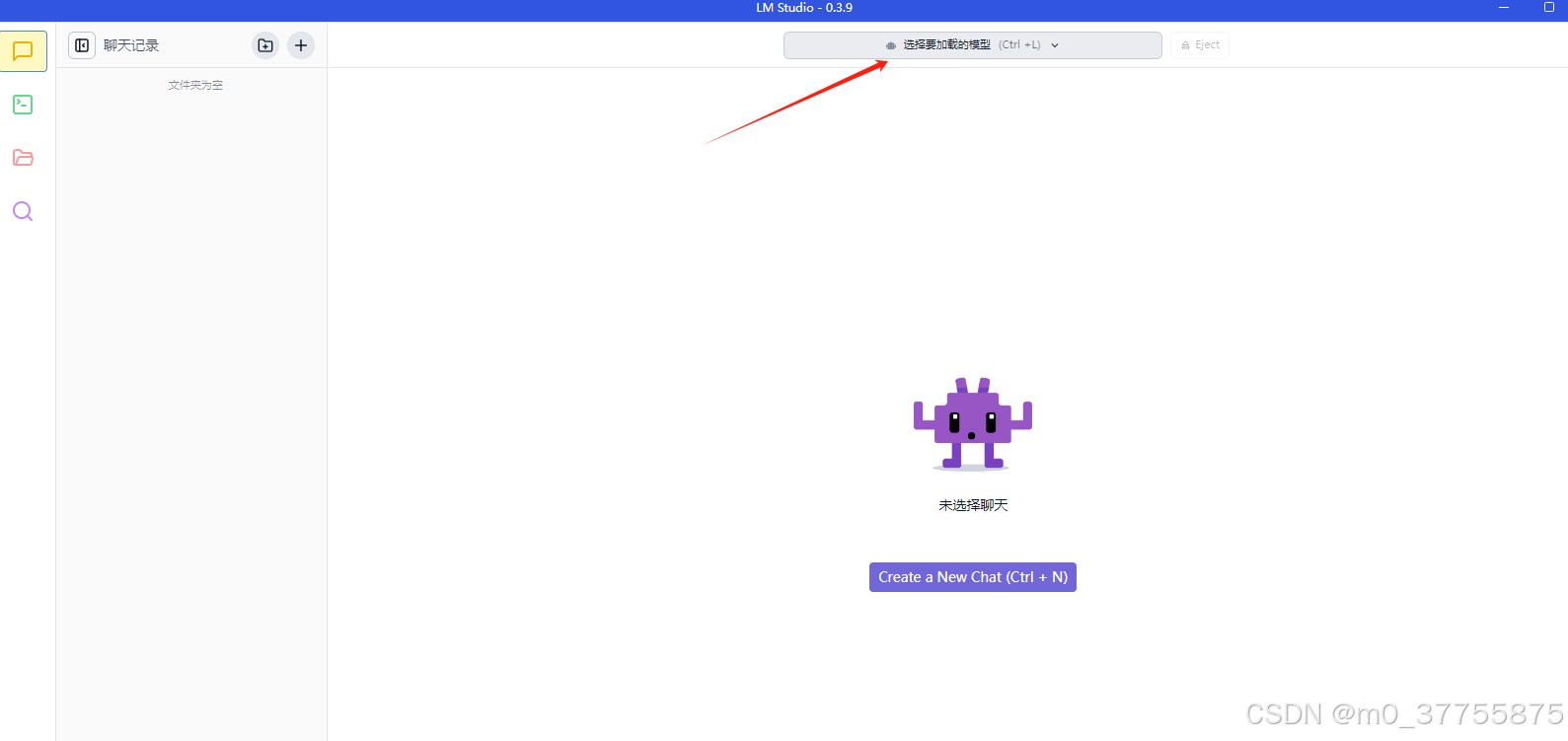
步骤3 载入模型
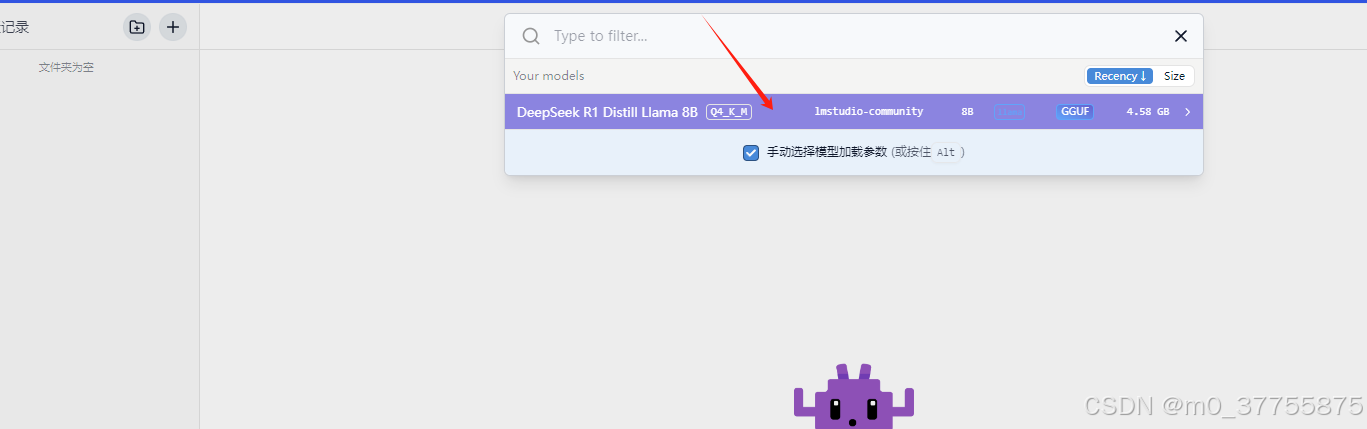
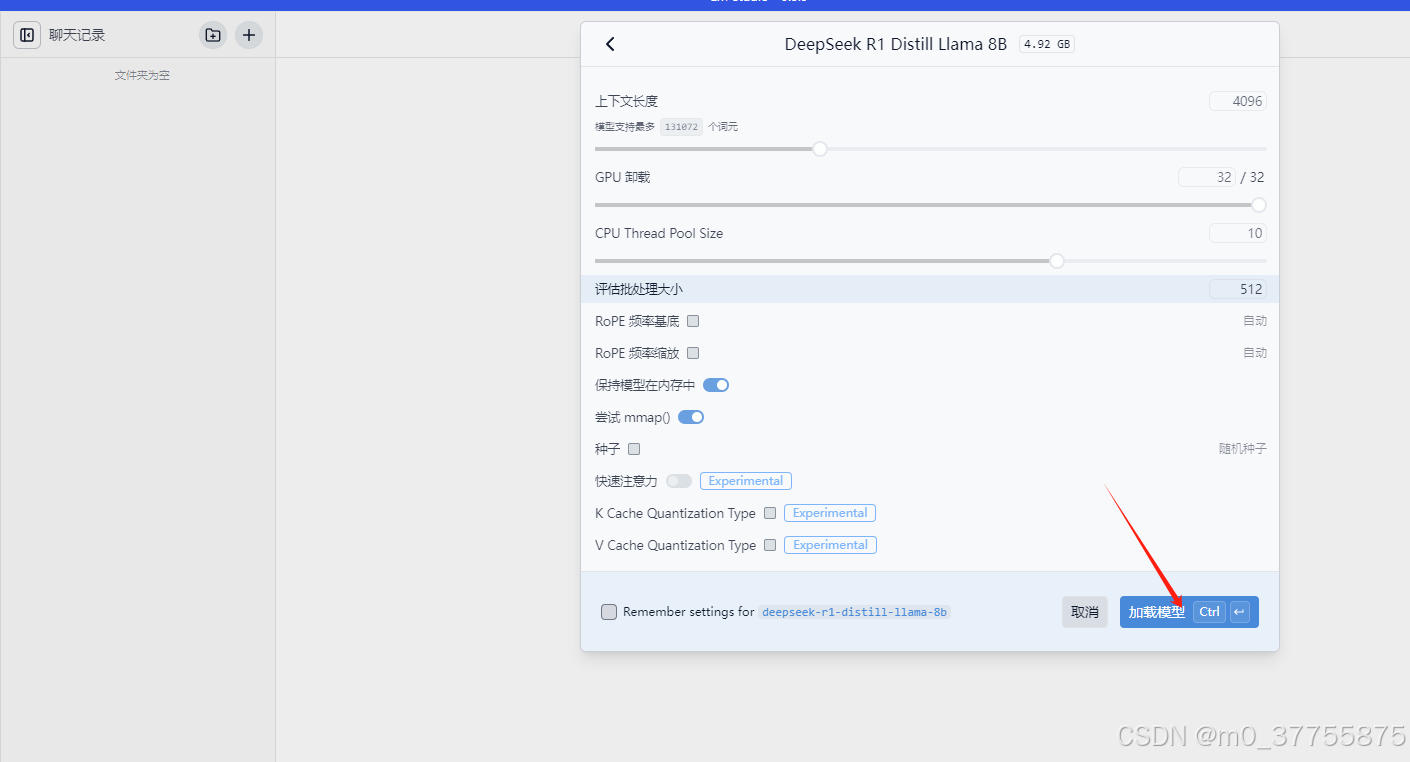
步骤4 开始聊天
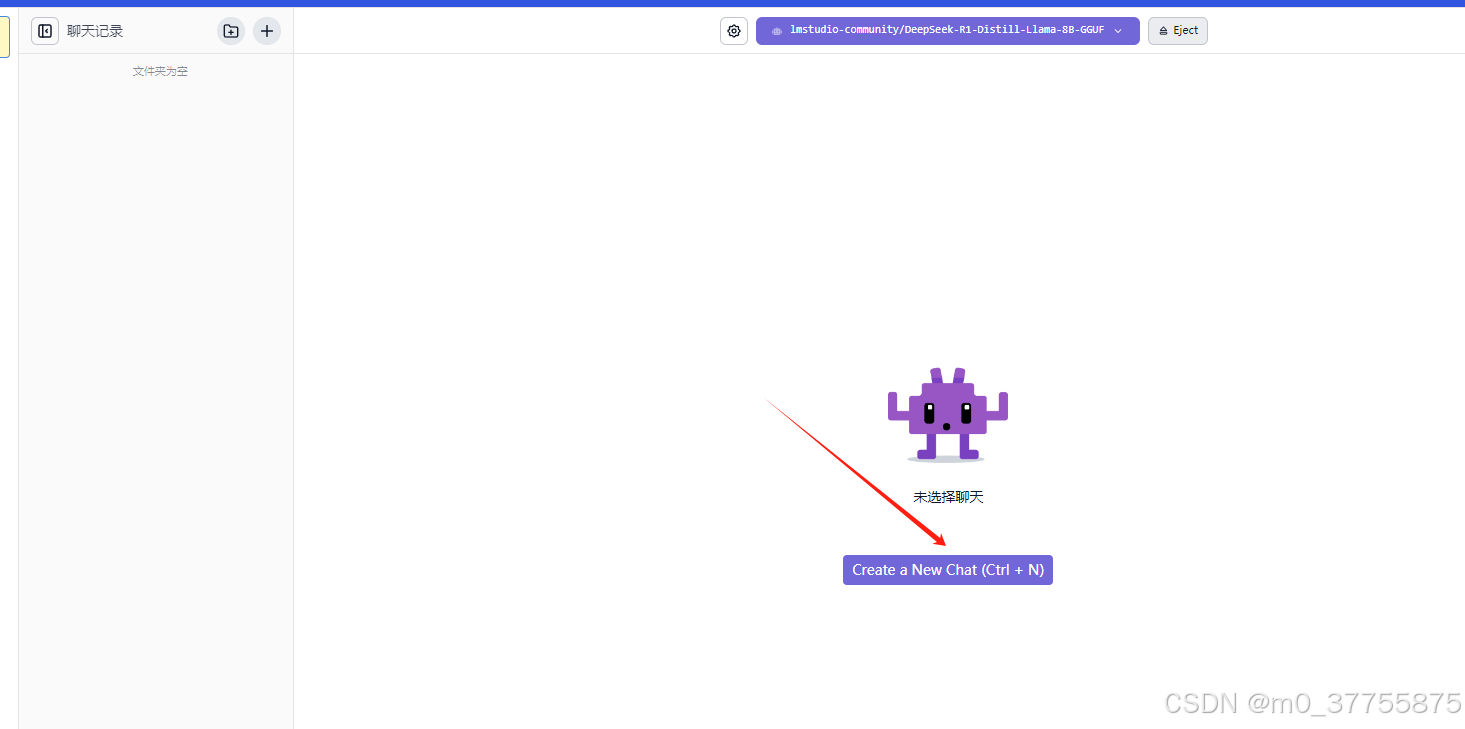
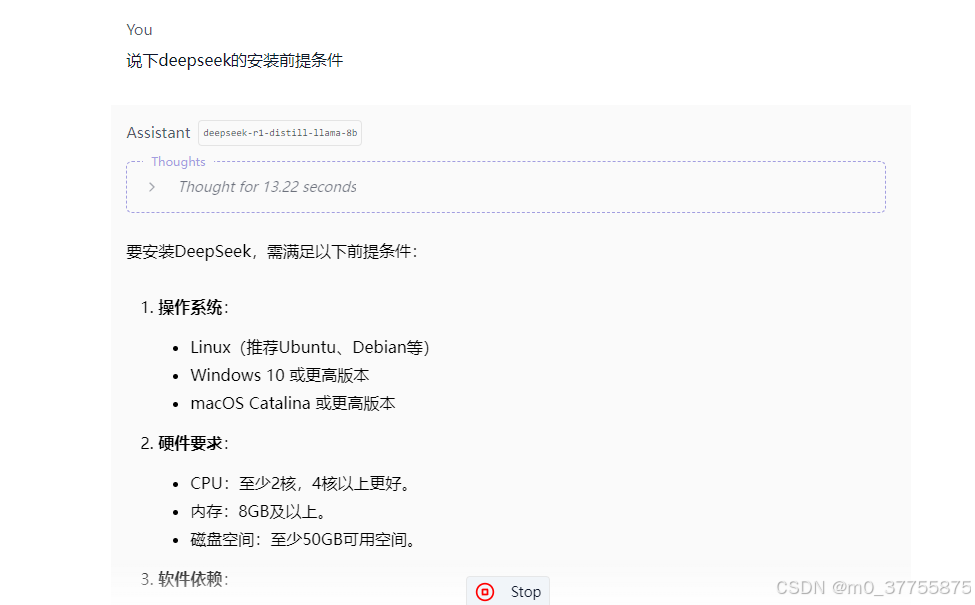
四、常见问题排查
| 问题现象 | 解决方案 |
|---|---|
| 下载速度慢 | 检查镜像替换是否完整→重新执行步骤1 |
| 模型加载失败 | 确认文件扩展名为.gguf→更新LM Studio至v0.2.9+ |
| GPU未调用 | 安装CUDA Toolkit→更新显卡驱动→重启客户端 |
| 回复速度慢 | 降低量化等级(如Q5→Q4)→关闭其他GPU应用 |
五、进阶技巧
-
多模型管理:创建
models文件夹分类存放不同用途模型 -
预设指令集:在
Chat Settings中保存常用提示词模板 -
API调用:通过
localhost:1234/v1接口对接第三方应用 -
性能监控:使用
nvitop工具实时查看显存占用
配套资源
-
国内网盘镜像(含DEEPSEEK R1各量化版本): 暂未上传

一起探索未来云端世界的核心,云原生技术专区带您领略创新、高效和可扩展的云计算解决方案,引领您在数字化时代的成功之路。
更多推荐



 24
24 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)