

循环神经网络(RNN):给AI装上记忆芯片
RNN的核⼼思想是利⽤“循环”的机制,将⽹络的输出反馈到输⼊,这使得它能够,从⽽捕获序列中的⻓距离依赖关系,在处理序列数据,如⽂本、语⾳和时间序列时具有明显的优势。在每一次的输入处理中都会把之前已经提问过的问题通过与权重相乘到新的节点。结合前⼀时间步的隐藏层状态ht−1,计算当前时间步的隐藏层状态ht(即上图中的h这通常通过⼀个激活函数(如tanh函数)实现。计算公式如下(其中,Whh是隐藏
循环神经网络:给AI装上"记忆芯片"
RNN的核⼼思想是利⽤“循环”的机制,将⽹络的输出反馈到输⼊,这使得它能够在处理数据时保留前⾯的信息,从⽽捕获序列中的⻓距离依赖关系,在处理序列数据,如⽂本、语⾳和时间序列时具有明显的优势。
在每一次的输入处理中都会把之前已经提问过的问题通过与权重相乘到新的节点。
结合前⼀时间步的隐藏层状态
h
(
t
−
1
)
h_{(t-1)}
h(t−1),计算当前时间步的隐藏层状态
h
t
h_t
ht(即上图中的h)。这通常通过⼀个激活函数(如tanh函数)实现。计算公式如下(其中,
W
h
h
W_{hh}
Whh是隐藏层90到隐藏层的权重矩阵,
W
x
h
W_{xh}
Wxh是输⼊到隐藏层的权重矩阵)
h
t
=
t
a
n
h
(
W
h
h
∗
h
(
t
−
1
)
+
W
x
h
∗
x
t
+
b
h
)
h_t = tanh(W_{hh} * h_{(t-1)} + W_{xh} * x_t + b_h)
ht=tanh(Whh∗h(t−1)+Wxh∗xt+bh)
(3)基于当前时间步的隐藏层状态
h
t
h_t
ht,计算输出层
y
t
y_t
yt(RNN在时间步t的输出)。通常通过⼀个线性变换和激活函数实现。计算公式如下:
y
t
=
s
o
f
t
m
a
x
(
W
h
y
∗
h
t
+
b
y
)
y_t = softmax(W_{hy} * h_t + b_y)
yt=softmax(Why∗ht+by)
RNN采⽤BPTT算法进⾏训练。
与普通反向传播不同,BPTT算法需要在时间维度上展开RNN,以便在处理时序依赖性时计算损失梯度。
因此,BPTT算法可以看作⼀种针对具有时间结构的数据的反向传播算法。在BPTT算法中,我们⾸先⽤损失函数计算模型的损失(如交叉熵损失),然后使⽤梯度下降法(或其他优化算法)来更新模型参数。
BPTT算法的关键在于,我们需要将梯度沿着时间步(对于⾃然语⾔处理问题来说,时间步就是⽂本序列的token)反向传播,从输出层⼀直传播到输⼊层。具体步骤如下。
(1)根据模型的输出和实际标签计算损失。对每个时间步,都可以计算⼀个损失值,然后对所有时间步的损失值求和,得到总损失。
(2)计算损失函数关于模型参数(权重矩阵和偏置)的梯度。这需要应⽤链式求导法则,分别计算损失函数关于输出层、隐藏层和输⼊层的梯度。然后将这些梯度沿着时间步传播回去。
(3)使⽤优化算法(如梯度下降法、Adam等)来更新模型参数。这包括更新权重矩阵( W h h W_{hh} Whh, W x h W_{xh} Wxh和 W h y W_{hy} Why)和偏置( b h b_h bh和 b y b_y by)。
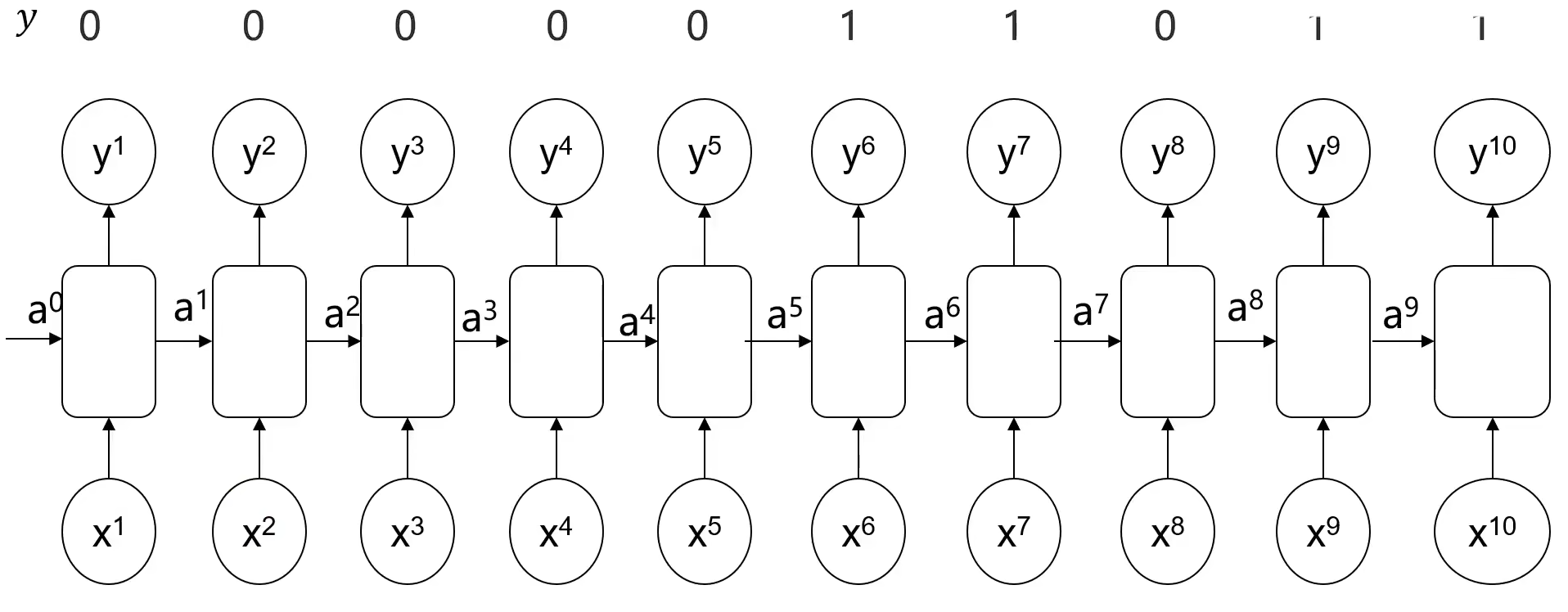
如下图此类多输入多输出的情况可以有特定信息识别的功能:
再如下图:
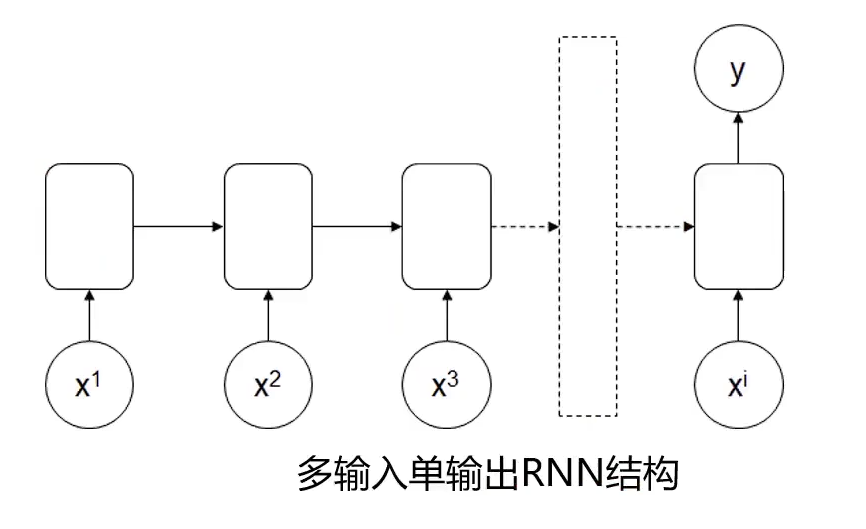
应用于情感识别
eg:l feel happy watching the movie
判断:可通过happy判断为正向情感
又如下图:
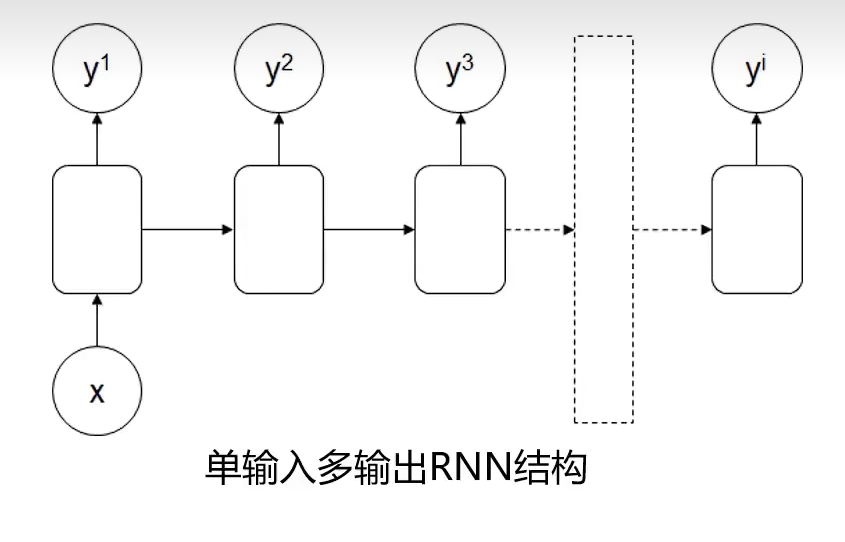
可做序列生成器
例如文章生成或者音乐生成
再如下图
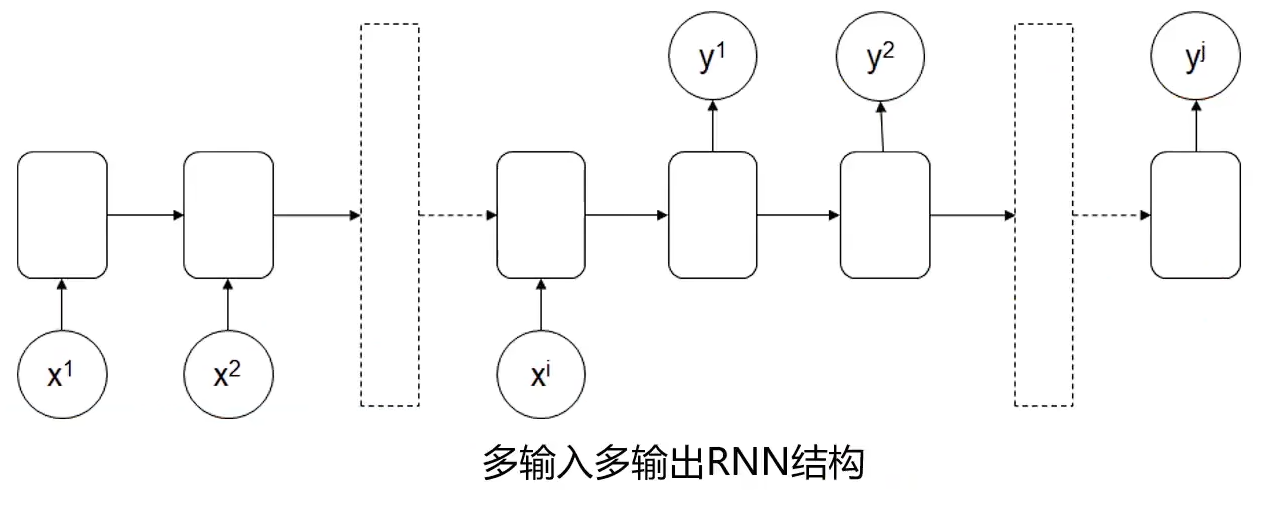
可做语言翻译
1.RNN实现流程
import torch.nn as nn # 导⼊神经⽹络模块
# 定义神经概率语⾔模型(NPLM)
class NPLM(nn.Module):
def __init__(self):
super(NPLM, self).__init__() # 调⽤⽗类的构造函数
self.C = nn.Embedding(voc_size, embedding_size) # 定义⼀个词嵌⼊层
# ⽤LSTM层替代第⼀个线性层,其输⼊⼤⼩为embedding_size,隐藏层⼤⼩为n_hidden
self.lstm = nn.LSTM(embedding_size, n_hidden, batch_first=True)
# 第⼆个线性层,其输⼊⼤⼩为n_hidden,输出⼤⼩为voc_size,即词汇表⼤⼩
self.linear = nn.Linear(n_hidden, voc_size)
def forward(self, X): # 定义前向传播过程
# 输⼊数据X张量的形状为[batch_size, n_step]
X = self.C(X) # 将X通过词嵌⼊层,形状变为[batch_size, n_step, embedding_size]
# 通过LSTM层
lstm_out, _ = self.lstm(X) # lstm_out形状变为[batch_size, n_step, n_hidden]
# 只选择最后⼀个时间步的输出作为全连接层的输⼊,通过第⼆个线性层得到输出
output = self.linear(lstm_out[:, -1, :]) # output的形状为[batch_size, voc_size]
return output # 返回输出结果
RNN模型结构:RNNLM(
(embedding): Embedding(7, 2)
(lstm): LSTM(2, 2, batch_first=True)
(linear): Linear(in_features=2, out_features=7, bias=True))
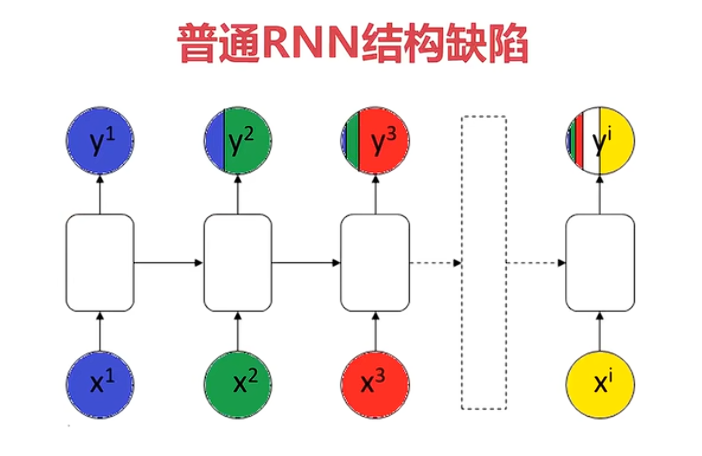
前部序列信息在传递到后部的同时,信息权重下降,导致重要信息丢失
求解过程中梯度消失
2. LSTM:记忆宫殿的建造师
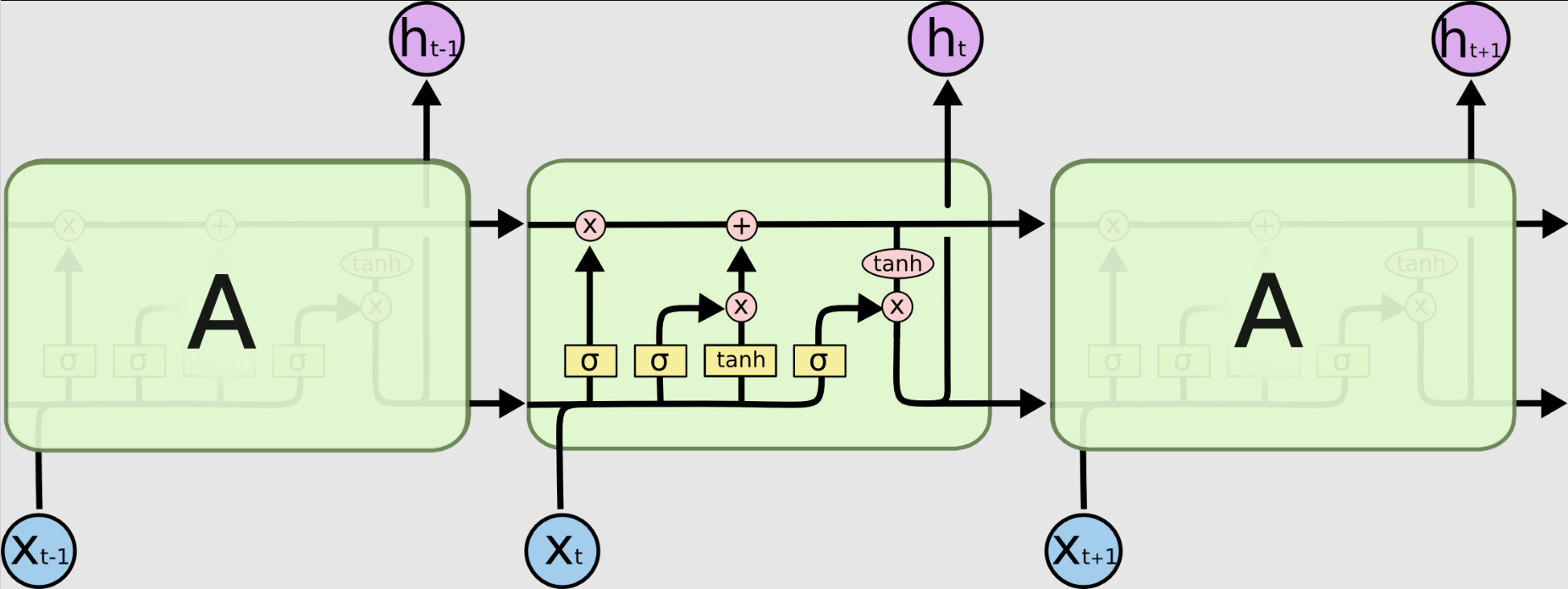
LSTM会计算输⼊⻔、遗忘⻔和输出⻔的激活值。这些⻔控机制使得LSTM能够有选择地
保留或遗忘之前的信息,从⽽更好地捕捉⻓距离依赖关系。这些⻔的计算公式如下。
- 输⼊⻔:i_t = sigmoid(W_ii * x_t + b_ii + W_hi * h_(t-1) + b_hi)
- 遗忘⻔:f_t = sigmoid(W_if * x_t + b_if + W_hf * h_(t-1) + b_hf)
- 输出⻔:o_t = sigmoid(W_io * x_t + b_io + W_ho * h_(t-1) + b_ho)
LSTM更新细胞状态c_t。这是通过结合输⼊⻔、遗忘⻔和当前输⼊的信息来实现的。计算公式如下:
- 细胞候选状态:g_t = tanh(W_ig * x_t + b_ig + W_hg * h_(t-1) + b_hg)
- 细胞状态更新:c_t = f_t * c_(t-1) + i_t * g_t
最后,LSTM会计算当前时间步的隐藏状态h_t,这通常作为输出。计算公式如下:
- 隐藏状态:h_t = o_t * tanh(c_t)
代码实现:
class LSTM(nn.Module):
def __init__(self, input_size, hidden_size):
super().__init__()
self.input_size = input_size
self.hidden_size = hidden_size
# 定义各类门结构参数
self.W_xi = nn.Parameter(torch.Tensor(input_size, hidden_size))
self.W_hi = nn.Parameter(torch.Tensor(hidden_size, hidden_size))
# ...其他参数初始化...
def forward(self, x, init_states=None):
# 实现门控逻辑
i_t = torch.sigmoid(x @ self.W_xi + h_prev @ self.W_hi)
# ...其他门计算...
return output, (h_t, c_t)
3.从AI到AGI:记忆与推理的终极进化
前沿突破:
- Neural Turing Machine:给RNN配备可微分内存
- Differentiable Neural Computer:实现类比推理
- Liquid Neural Network:模拟生物神经网络特性
未来展望:
- 实时翻译:具备上下文记忆的同声传译
- 文学创作:续写《红楼梦》后四十回
- 科研突破:预测蛋白质折叠轨迹

一起探索未来云端世界的核心,云原生技术专区带您领略创新、高效和可扩展的云计算解决方案,引领您在数字化时代的成功之路。
更多推荐



 22
22 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

















































 Go语言基础
Go语言基础

所有评论(0)