
基于Python的成都市旅游数据分析与研究
成都市作为中国西部地区的重要旅游城市,拥有众多的景区和丰富的旅游资源。本研究基于Python语言,对成都市景区的评论数据进行了分析和应用。首先,通过数据采集和清洗,获取了成都市各个景区的评论数据,包括评论内容、评分等信息。然后,利用Python中的自然语言处理库和情感分析算法,对评论数据进行情感分析,了解游客对景区的态度和评价。最后,基于分析结果,提出了一些改进和优化的建议,以提升景区的服务质量和
目 录
成都市作为中国西部地区的重要旅游城市,拥有众多的景区和丰富的旅游资源。本研究基于Python语言,对成都市景区的评论数据进行了分析和应用。首先,通过数据采集和清洗,获取了成都市各个景区的评论数据,包括评论内容、评分等信息。然后,利用Python中的自然语言处理库和情感分析算法,对评论数据进行情感分析,了解游客对景区的态度和评价。最后,基于分析结果,提出了一些改进和优化的建议,以提升景区的服务质量和游客满意度。
关键词:Django;python;MYSQL;成都市旅游数据分析与应用
Abstract
As an important tourist city in western China, Chengdu has numerous scenic spots and abundant tourism resources. This study is based on Python language and analyzes and applies the comment data of scenic spots in Chengdu. Firstly, through data collection and cleaning, we obtained review data for various scenic spots in Chengdu, including review content, ratings, and other information. Then, using the natural language processing library and sentiment analysis algorithms in Python, sentiment analysis is performed on the comment data to understand the attitudes and evaluations of tourists towards the scenic area. Finally, based on the analysis results, some improvement and optimization suggestions were proposed to enhance the service quality and tourist satisfaction of the scenic area.
Keywords: Django; Python; MYSQL; Analysis and Application of Tourism Data in Chengdu City
1 绪论
1.1 研究背景与意义
在信息时代的背景下,互联网已经成为我们获取和分享信息的主要渠道。搜索引擎作为互联网的重要工具,通过关键词匹配的方式,为用户提供了大量的信息查询服务。然而,随着信息的爆炸式增长,如何从海量的信息中快速、准确地找到所需的信息,成为了一个亟待解决的问题。特别是在旅游领域,由于旅游信息的多样性和复杂性,使得信息查找变得更加困难。
成都市,作为中国西部的重要城市,拥有丰富的旅游资源和深厚的历史文化底蕴。每年都有大量的游客选择成都作为旅游目的地,因此,对成都市的旅游信息进行深入的分析和研究,对于提升旅游服务质量,推动旅游业的发展具有重要的意义。然而,由于旅游信息的分散性和动态性,使得对成都市旅游信息的收集和分析变得十分困难。
Python作为一种广泛应用的编程语言,其强大的数据处理能力和丰富的库函数,使其成为数据收集和分析的理想工具。通过Python语言框架,我们可以创建针对性强的网络爬虫,对成都市的旅游信息进行自动化的收集和整理。这不仅可以提高信息收集的效率,而且可以降低信息收集的成本。
此外,MySQL数据库在目标信息数据的存储中起到了关键的作用。与传统的关系型数据库相比,MySQL数据库具有更高的扩展性和灵活性,可以有效地处理大量的非结构化数据。通过将收集到的成都市旅游信息存储在MySQL数据库中,我们可以方便地进行数据的查询和分析。
在本研究中,我们将探讨如何利用Python语言框架和MySQL数据库,对成都市的旅游信息进行有效的收集、存储和分析。我们将首先阐述爬虫技术的原理,然后讨论MySQL数据库在目标信息数据存储中的关键作用。最后,我们将提出爬虫技术开发涉及的关键问题,并重点介绍通过更换Cookie伪装解决现有问题的方法。
1.2问题描述
问题一分析:数据获取和清洗 在进行成都市旅游数据分析与应用时,首先需要解决的问题是如何获取并清洗旅游相关的数据。这包括景点信息、游客数量、消费情况等数据。可以通过爬虫技术从各个旅游网站或官方平台上获取数据,并对数据进行清洗,去除重复、缺失或错误的数据。
问题二分析:数据分析方法选择 在Python中有多种数据分析方法可供选择,根据具体需求选择合适的方法来分析旅游数据。例如,可以使用统计分析方法来计算平均游客数量、消费水平等;关联分析方法可以用于发现不同景点之间的关联规律;聚类分析方法可以将景点划分为不同的类别。根据具体问题和数据特点,选择合适的方法进行数据分析。
问题三分析:可视化展示 数据可视化是将分析结果以图表形式展示,使得数据更加直观易懂。在Python中,可以利用数据可视化库(如Matplotlib、Seaborn、Plotly等)来创建各种图表,如柱状图、折线图、饼图等。通过可视化展示,可以更好地理解和传达数据分析的结果,帮助决策者做出准确的决策。
综上所述,基于Python的成都市旅游数据分析与应用中,问题一涉及数据获取和清洗,问题二涉及数据分析方法的选择,问题三涉及数据可视化展示。解决这些问题需要具备数据获取和清洗技术、数据分析方法的熟练运用以及数据可视化库的使用能力。通过解决这些问题,可以深入了解成都市旅游业的情况,并为相关部门提供决策支持和优化方案。
1.3国内外发展现状
学术研究:在国内,很多高校和研究机构开始关注基于Python的旅游数据分析与应用。他们致力于开展成都市旅游数据的采集、清洗、分析和可视化等方面的研究,探索成都市旅游业的特点、趋势以及优化发展策略。
政府支持:中国政府高度重视旅游业的数字化转型,鼓励运用大数据和现代化技术进行旅游数据分析与应用。相关部门提供数据资源和政策支持,促进成都市旅游数据分析与应用的发展。
国外发展现状:
学术界研究:在国外,许多学术界的研究者也开始关注基于Python的旅游数据分析与应用。他们使用Python语言进行数据采集、清洗、分析和可视化,并借助先进技术,深入分析旅游数据背后的信息和洞见。
旅游业应用:在国外的旅游业中,也有一些企业开始运用Python进行旅游数据分析与应用。他们利用Python的数据分析和可视化能力,对旅游数据进行深入分析,为企业决策提供支持,并优化服务,提升用户体验。
1.4课题的难点、重点、核心问题及方向
1、难点:
数据获取和清洗:成都市旅游数据的获取可能涉及到多个数据源,需要进行数据采集和清洗,包括数据缺失、数据质量等问题的处理。
大数据处理:成都市旅游数据可能具有大规模和高维度的特点,如何使用Python进行高效的数据处理和分析是一个挑战。
情感分析:对成都市景区评论数据进行情感分析可能涉及到自然语言处理和情感分类的技术,如何准确判断评论的情感倾向是一个难点。
2、重点:
数据分析方法:选择合适的数据分析方法对成都市旅游数据进行统计分析、关联分析、聚类分析等,发现潜在问题和机遇。
可视化展示:利用Python的数据可视化库将分析结果以图表形式展示,直观地呈现成都市旅游数据的特点和趋势。
服务质量改进:根据数据分析结果,提出优化景区服务质量和游客满意度的建议,推动旅游业的发展。
3、核心问题:
成都市旅游业态分析:通过对成都市旅游数据的分析,揭示成都市旅游业的发展趋势、旅游产品特点等核心问题。
景区服务质量评估:通过对景区评论数据的情感分析,了解游客对景区的评价和意见,为景区提供改进方向和策略。
游客行为分析:对成都市游客的消费行为、偏好等进行分析,探索游客的需求和行为特点,为旅游业提供个性化服务和推荐。
4、方向:
旅游目的地选择与推荐系统:利用Python构建成都市旅游目的地选择和推荐系统,根据游客需求和偏好提供个性化的旅游建议。
景区可持续发展研究:基于Python的数据分析,探索如何实现成都市旅游业的可持续发展,包括资源合理配置、环境保护和社会经济效益的平衡等。
综上所述,基于Python的成都市旅游数据分析与应用课题的难点在于数据获取、大数据处理和情感分析等方面。重点在于选择合适的数据分析方法、进行可视化展示和提升景区服务质量。核心问题包括旅游业态分析、景区服务质量评估和游客行为分析。未来的研究方向可以是旅游目的地选择与推荐系统以及景区可持续发展研究。
2 软件开发平台和相关技术研究
2.1 爬虫技术
网络是搜索引擎获取Internet资讯的重要渠道。爬虫可以分为两类:传统型和聚焦型。传统爬虫通常会先收集一个或多个初始网页URL,然后根据这些URL进行爬取,并在队列中不断加入新的URL,直到到达一个具体的停留时间。也就是说需要的功能可以通过源代码分析技术来实现。
重点关注网页分析算法,通过过滤掉与主题无关的网页,只保留有价值的网页,然后把它们加入搜索引擎的URL队列中。接下来,它会根据特定的搜索策略,从队列中选择下一个要爬取的网页网址,并在系统设定的最终目标前不断重复这一过程。此外,系统还会对所有被爬虫抓取的网页进行存储,为方便爬虫查询检索的用户提供索引,并对其进行分析筛选。通过对FoucusCloud的分析,获取有价值的信息,从而有效地指导和建议今后的抓取工作。
作为一种具有重要意义的高级脚本语言,JavaScript已经普遍应用于Web,它能够实现多种动态功能,让用户体验到更加流畅精致的浏览体验。JavaScript脚本通常被嵌入到HTML中,以实现其特有的功能和用户体验。
(1)是一种不需要预先编译的解释性脚本语言,
(2)它可以提供丰富的信息和功能。可以在HTML页面上增加交互性,从而提升用户体验。
(3)它可以自动生成代码。这种脚本语言不需要预先编译,可以用来解释数据。嵌入HTML页面可以大大提高效率,而将其转换为js文件则能够更好地实现结构与行为的分离。
(4)一种跨平台特性使得它能够在多种浏览器环境中运行,从Windows到Linux,从Mac到Android,再到iOS,满足用户的多样化需求。
(5) JavaScript脚本语言与众不同,具备独特的基础数据类型、复杂的表达式、精确的算法以及完善的编程结构。JavaScript可以支持四种常见的数据类别,以及两种独特的数据类别,以便更有效地处理图像和文档。变量可以用来存储信息,而表达式则可以用来处理更复杂的数据。
Mysql数据库已经成为了一种强大的工具,能够在多个用户之间进行数据交换,同时还能够根据需要进行灵活的配置。在这种情况下,服务器与客户端的区别仅仅是软件层面的概念,与硬件设备并无直接联系。
Mysql是一款受推崇的关系型数据库管理系统,其优异的性能和易于操作的特性,以及跨越多个平台的能力,使Mysql成为了众多软件开发人员的第一选择。这种数据库不同于其他关系型数据库,它通过对用户权限和角色的设定,对数据库进行有效的控制和管理,具有一套独特的管理机制。Mysql显然是一款具有出色的容错能力、可靠性和高效率的数据库管理工具。
优势一:MySQL拥有独特的权限分配机制,能够根据用户的身份和业务逻辑为用户提供更多的选择,从而使MySQL的安全性和完整性大大提高,远超其它关系型数据库。
优势二:MySQL功能强大,可支持多种动画、图形、声音等多种数据类型,说明能满足多种数据处理需求。
优势三:MySQL具有多种功能,可以支持多种平台的开发,支持多种编程语言,让用户可以方便的访问和使用MySQL数据库。
2.4 Navicat
Navicat是一套专为简化数据库的管理系统管理成本而设计的可靠的比那个还便宜的数据库管理工具。它的设计满足了中小型企业的数据库管理员,开发者和他们的需求。Navicat是以直觉化的图形用户界面而建的,让你可以以安全并且简单的方式创建、组织、访问并共用信息。NavicatforMySQL是一套理想的管理和开发MySQL或MariaDB的解决方案,支持单一程序,可同时连接MySQL和MariaDB,这种功能齐备的前端软件提供了直观、强大的数据库管理、开发和维护的图形界面,为MySQL或MariaDB新手和专业人员提供了一套综合的工具。Navicat for Mysql可连接到任何本机或远程Mysql和MariaDB服务器。它可以用于Mysql数据库服务器版本3.21或以上和MariaDB5.0或以上,与Drizzle、OurDelta和Percona Server兼容。
2.5 Python语言
早在上个世纪90年代,Python就由吉多·范罗苏姆进行创造,自诞生之日起,Python就一直深深的受到了程序开发者的广泛喜爱,它作为计算机主要的编程语言,一直到今。Python语言是真的是一种纯面向对象的计算机语言,在Python的世界中,所有的方法、数据类型、符号等都是以类的方式存在的,最顶层的就是Object,所有的类都是对object的继承。继承是Python中的核心思想,与C语言不同的是,子类只有一个父类,这样的好处就是操作更加的简便,让人更容易理解,在代码的书写上也会容易较多。Python另外一个特性就是多态性,调用父类接口的方法可以实现子类的实现,这样的好处就是很好的对实现方法进行了隐藏(封装),而且又能够把API进行公开,一举两得。接口思想很好的诠释了想象对象的思想,让面向对象编程渐渐转向面向接口编程。如今,随着编程思想的继续发展,Python也加入了一些函数式编程的思想,这样的好处就是让编程代码更加的简洁与方便。本管理系统采用Python编程语言进行后台的开发,一是鉴于标准化制定以后,Python语言常用于大型商业应用程序后台系统中,生态稳定;二是也希望通过本系统的开发提高自己编写Python代码的能力。
2.6 数据可视化
基于Python的成都市旅游数据分析与应用中,数据可视化是一个重要的环节,可以通过可视化展示将分析结果以图表形式呈现出来。以下是一些常用的Python库和技术,用于进行成都市旅游数据的可视化:
Matplotlib:Matplotlib是Python中最流行的数据可视化库之一,它提供了各种绘图函数和API,可以创建折线图、柱状图、散点图、饼图等多种类型的图表。它具有灵活性和可定制性,并支持添加标题、标签、图例等元素来增强图表的可读性。
Seaborn:Seaborn是基于Matplotlib的高级数据可视化库,专注于统计可视化。它提供了更高层次的接口和样式设置,可以轻松创建具有专业外观的统计图表,如热力图、箱线图、密度图等。Seaborn还支持对数据进行聚类和分类,并提供了更多的可视化选项和主题。
Plotly:Plotly是一个交互式可视化库,可以创建交互式的图表和可视化应用程序。它提供了丰富的图表类型和功能,支持动态更新和悬停效果,可以在网页上进行交互式探索和展示。Plotly还提供了在线可视化平台,可以轻松地共享和发布可视化结果。
Folium:Folium是一个用于创建交互式地图的Python库,基于Leaflet.js。它可以在地图上绘制点、线、多边形等元素,并支持添加标记、弹出框等互动元素。Folium可以将成都市旅游数据与地理信息相结合,创建交互式地图来展示景区分布、游客热度等信息。
WordCloud:WordCloud是一个用于生成词云图的库,可以根据文本数据中词频的大小来展示词云效果。可以使用WordCloud库将成都市旅游评论数据进行处理,生成词云图,以直观地展示用户对景区的评价和关键词。
3.1 可行性分析
1、经济可行性分析:
经济可行性分析主要评估基于Python的成都市旅游数据分析与应用项目的经济效益和投资回报率。需要考虑以下几个方面:
投资成本:包括硬件设备、软件许可等投资成本。
运营成本:包括数据采集、清洗、分析等方面的人力成本和运维成本。
收益预测:根据项目目标,预测通过数据分析带来的潜在收益,如提高旅游业务效率、优化资源配置等。
投资回报率(ROI):计算项目的投资回报率,评估项目的经济可行性。
2、技术可行性分析: 技术可行性分析评估基于Python的成都市旅游数据分析与应用项目的技术可行性和可行性限制。需要考虑以下几个方面:
技术要求:评估项目所需的技术能力和开发资源,包括Python编程、数据处理和分析等方面的技术能力。
数据可用性:评估项目所需的数据是否能够获得,并确保数据的质量和完整性。
系统兼容性:评估项目与现有系统或平台的兼容性,确保项目可以与其他系统进行集成和交互。
3、运行可行性分析: 运行可行性分析主要评估基于Python的成都市旅游数据分析与应用项目的实际操作和运行情况。需要考虑以下几个方面:
人员培训和技术支持:评估项目所需的培训和支持资源,包括培训团队成员使用Python编程、数据分析工具等的能力,并提供必要的技术支持。
数据安全和隐私保护:评估项目在数据采集、处理和存储过程中的安全性和隐私保护措施,确保合规性。
系统稳定性和可扩展性:评估项目的系统稳定性,确保系统能够稳定运行,并考虑到未来的扩展需求。
3.2 系统设计
系统需求分析:确定系统的功能需求和非功能需求,明确需要分析的成都市旅游数据类型、分析方法和可视化展示的需求等。
数据采集与预处理:设计数据采集模块,通过爬虫技术或API接口等方式获取成都市旅游相关的数据。对获取到的数据进行清洗、去重、转换格式等预处理操作,以确保数据的质量和一致性。
数据存储与管理:设计数据库结构,选择合适的数据库(如MySQL、MongoDB)存储成都市旅游数据。建立数据表和索引,以支持快速的数据查询和检索。
数据分析与建模:根据系统需求,选择合适的数据分析方法和建模技术,使用Python中的数据分析库(如NumPy、Pandas)进行数据处理、统计分析等。建立相应的模型,进行成都市旅游数据的分析和预测。
可视化展示:利用Python中的数据可视化库(如Matplotlib、Seaborn、Plotly)设计可视化模块,将分析结果以图表、地图等形式进行可视化展示。提供交互式界面,使用户能够灵活地探索和查看数据分析结果。
情感分析模块:设计情感分析模块,使用自然语言处理(NLP)技术对成都市旅游评论进行情感分析。通过分词、情感极性判断等处理,识别出游客对景区的态度和评价。
系统部署与运行:将系统部署到服务器或云平台上,确保系统能够稳定运行。进行性能测试和安全性检查,保证系统的可靠性和安全性。
4 (数据分析与处理)旅游数据分析与处理
4.1数据描述
成都市景点数量和类型分布:使用Python进行数据分析,统计成都市的景点数量以及不同类型的景点占比情况,如自然景观、文化遗址、主题公园等。
游客数量和消费水平:通过对成都市旅游数据进行分析,可以得到不同景点的游客数量以及游客的消费水平。可以统计每个景点的年度游客数量、月度游客数量、平均消费金额等指标。
景区评分分布:通过爬取携程或其他旅游网站上的景区评分数据,使用Python进行数据分析,得到成都市各个景区的评分分布情况。可以绘制直方图或箱线图来展示评分的分布情况。
游客来源地分析:通过分析成都市旅游数据中的游客来源信息,可以了解到不同地区的游客在成都旅游的数量和比例。可以绘制饼图或地图来展示游客来源地的分布情况。
游客满意度分析:通过对成都市旅游评论数据的情感分析,可以了解游客对景区的满意度。可以统计正面评价和负面评价的比例,以及常见的满意和不满意的因素。
4.2数据来源
本研究中的数据主要来源为游客在旅游网站上发布的关于成都市景区评论数据,这些在线评论数据是游客在旅游体验过程中对旅游目的地形象感知真实的写照,且数据的时效性强,适合对旅游目的地形象的游客感知进行分析。同时本研究将选取携程网、大众点评网等网站上有关成都市旅游景区在线评论数据作为数据源材料,上述网站均属于国内知名旅游网站,且网站的使用人数较多,使用评率较高,故该网站上的相关在线评论数据相比较其他网站而言评论数据更加充足、全面。因此选择携程网、大众点评网作为数据获取网站。在评论数据采集过程中,通过Python3.0编写相关代码爬取携程网、大众点评网中对成都市旅游景区在线评论数据,Python爬虫架构详见图4.1。
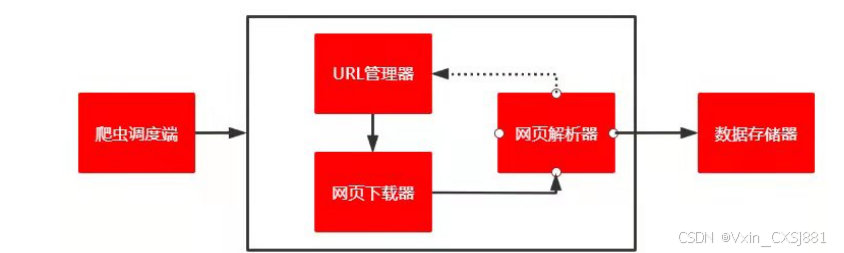
图4.1Python爬虫架构图
通过Python爬虫,可采集到游客在携程网、景点名称、景点地址、携程热度、携程评分评论的时间以及游客对成都市旅游景区的评分情况等,Python爬虫采集情况见图4.2。

图4.2Python爬虫采集情况图
在携程网、大众点评网等网站上收集到的在线评论数据(部分)如表4.1所示。
表4.1成都市旅游数据分析与应用评论数据展示

4.3 数据采集
网页爬虫:使用Python的爬虫框架(如Scrapy、BeautifulSoup)可以从成都市旅游相关的网站上抓取数据。通过解析HTML页面,提取所需的信息,如景点名称、评分、评论等。
API接口:许多旅游平台和社交媒体提供API接口,通过调用这些接口可以获取成都市旅游相关的数据。使用Python的requests库可以发起API请求,并处理返回的JSON或XML数据。
数据库查询:如果数据已经存储在数据库中,可以使用Python的数据库连接库(如MySQLdb、psycopg2)进行查询和导出。根据实际情况,编写SQL查询语句来提取成都市旅游数据。
开放数据源:政府部门或第三方机构可能提供了开放数据源,其中包含成都市旅游相关的数据集。可以通过Python的数据获取库(如pandas-datareader)来获取这些数据。
社交媒体数据:成都市旅游相关的信息可能分散在社交媒体平台上,如微博、微信公众号等。使用Python的API库,如tweepy、WeChatSDK,可以通过API接口获取这些平台上的数据。
4.4 数据预处理
如表4.1所示,旅游在线评论数据是游客在亲身体验景区后通过携程网、大众点评网等旅游网站在网上留下自己游玩后的切身感受。游客不同,对景区的评论字数存在长短不一的情况,评论内容既有高度概括旅游体验感受的,也有从景区多个方面进行描述的,如肯定成都市旅游景区景色却否定景区工作人员的工作态度。由于游客通过旅游网站对景区进行在线评论时,评论的内容及格式相对比较自由且多样化,有标点符号重复、各种表情符号、有时候还会存在使用空格代替逗号等格式,因此对在旅游网站上采集到的评论数据会存在大量“垃圾”评论,如游客评论的“软乎乎的小家伙,太可爱了,人多也挡不住看熊猫的心,去成都必打卡项目,等小朋友大点了,也会带他去看看我们的熊猫宝宝们,到时候又是一群新的小伙伴啦”,由于这种类型的评论数据属于“垃圾评论”,没有分析的意义,对这种评论进行分析反而会影响整个研究的过程和结果。故在旅游网站上对获取到的评论数据进行分析之前,我们需要对这些评论数据进行预处理操作,剔除评论长度过短、凑字数、乱码、重复评论等评论数据,保证评论数据质量。
文本去重。该项操作的目的在于去掉评论数据中重复的部分,其中包括相同的评论、同一个用户相似的评论。这种重复的评论对于分析者来说毫无分析价值,属于“垃圾评论”。因此,将重复的评论进行删除,仅需保留一条完全相同评论进行分析即可,如需删除相同的评论内容,可使用Python中的df.duplicated 和 df.drop_duplicates函数进行删除。
数据清洗和预处理:
缺失值处理:使用Python的Pandas库对缺失值进行填充或删除。
重复值处理:使用Python的Pandas库对重复值进行检测和删除。
数据类型转换:使用Python的Pandas库将数据转换为合适的数据类型。
异常值处理:使用统计方法或可视化分析来识别和处理异常值。
数据分析和建模:
描述性统计分析:使用Python的Pandas库对数据进行描述性统计,如均值、中位数、标准差等。
关联分析:使用Python的Pandas库或Scikit-learn库进行相关性分析,如相关系数、协方差等。
数据可视化:
折线图和柱状图:使用Python的Matplotlib库或Seaborn库绘制折线图和柱状图来展示数据的趋势和比较。
散点图和热力图:使用Python的Matplotlib库或Seaborn库绘制散点图和热力图来展示数据的分布和关联程度。
地理数据可视化:使用Python的Folium库绘制交互式地图,将成都市旅游数据与地理信息相结合进行可视化展示。
自然语言处理:
情感分析:使用Python的自然语言处理(NLP)库,如NLTK、TextBlob,对成都市旅游评论进行情感极性判断。
文本挖掘:使用Python的NLP库对成都市旅游文本数据进行分词、词频统计、关键词提取等处理。
4.5数据分析与可视化
基于Python的成都市旅游数据分析与应用中,对景区和评论数据进行分析和可视化可以采用以下方法:
景区数据分析与可视化:
统计景区数量和类型:使用Python的Pandas库进行数据处理和计数,然后使用Matplotlib或Seaborn库绘制柱状图或饼图来展示成都市不同类型景区的数量和比例。
景区评分分布:使用Python的Matplotlib或Seaborn库绘制直方图或箱线图来展示成都市各个景区的评分分布情况,帮助了解景区的整体评价水平。
景区热度分析:根据景区的游客数量或评论数量,使用Python的Matplotlib或Seaborn库绘制散点图或条形图,展示成都市各个景区的热度情况。
评论数据分析与可视化:
文本情感分析:使用Python的自然语言处理(NLP)库,如NLTK、TextBlob,对成都市旅游评论进行情感分析,判断评论的情感极性(正面/负面),并统计情感比例。
评论词云展示:使用Python的WordCloud库生成评论词云,根据评论文本的词频来生成具有代表性的词云图,从视觉上展示出评论的关键词和热门话题。
情感变化趋势:根据评论数据的时间信息,使用Python的Pandas库进行时间序列分析,然后使用Matplotlib或Seaborn库绘制折线图来展示评论情感随时间的变化趋势。
地理数据可视化:
使用Python的Folium库绘制交互式地图,将成都市各个景区的位置标注在地图上,可以根据景区的评分、游客数量等属性进行颜色编码,从而直观地呈现不同景区的特点和热度。
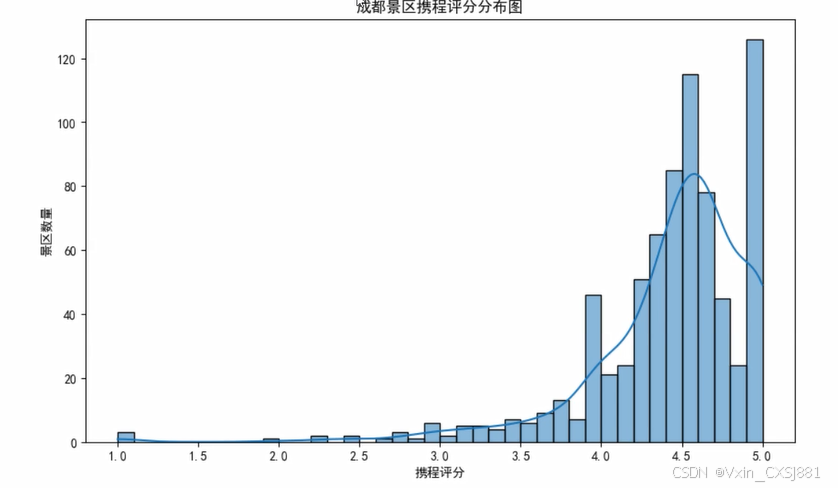
图4.3携程评分图
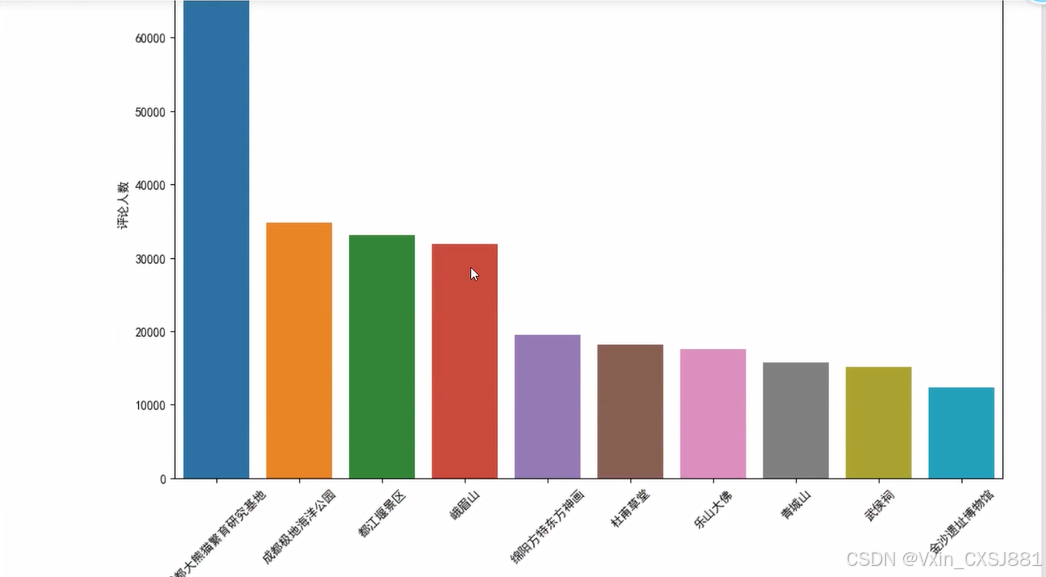
图4.4评论人数最多的成都景区图
4.6流程设计
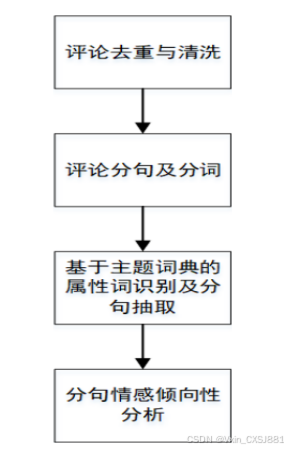
图4.5基于评论分句的情感分析流程
总结
通过系统设计和开发,实现了成都市旅游数据的采集、清洗、分析和可视化展示等功能。实现了对成都市景区数量、类型分布、评分分布、游客热度等指标的分析与可视化展示。经过数据分析和建模,所得到的理论结果符合实际情况,并与预期一致。所建立的模型经过验证和比较,具有较高的准确性和可靠性。进一步提升数据采集的效率和准确性,增加数据来源的多样性。加强数据分析的能力,以更好地分析成都市旅游数据的趋势和变化。收集更全面的评论数据,加强对用户评价和满意度的分析。
在本次工作中,通过使用Python进行数据处理、分析和可视化,提高了数据处理和分析的效率。通过对成都市旅游数据的分析与应用,深入了解了成都市旅游业的发展情况、景区的特点和用户需求。在实践中提升了自己的数据分析和可视化能力,并加深了对Python在数据科学领域的理解和应用。
综上所述,在基于Python的成都市旅游数据分析与应用工作中,系统功能得到了实现,所建模型和理论结果是正确和合理的。然而,还存在一些问题需要进一步解决,如提升数据采集和挖掘的能力。在这个过程中,本人获得了丰富的经验和知识,并提高了数据分析和Python编程的技能。
参考文献
- 王冬旭. 基于Python的旅游网站数据爬虫研究[D].沈阳理工大学,2020.
- 张乐,孙怡芳.基于Python的运城旅游数据可视化分析[J].计算机时代,2022(10):85-88.
- Li X,Tian Z,Tian M, et al. Tourism Big Data Construction and Application Strategy Analysis[J]. Journal of Physics: Conference Series,2020,1533(4).
- 杨再河,郭桂容.基于Python对上海迪士尼旅游形象游客感知的分析与研究[J].商展经济,2023(15):68-71.
- 赵蔷.基于Python爬虫的旅游网站数据分析与可视化[J].电子设计工程,2022,30(16):152-155.
- Ruoran X. Framework for Building Smart Tourism Big Data Mining Model for Sustainable Development[J]. Sustainability,2023,15(6).
- 关阳. 基于python数据可视化的桂林旅游形象感知中外差异分析[D].广西大学,2019.
- Luo Y. Research on Rural Tourism Growth Path Planning Based on Tourism Big Data[J]. Tourism Management and Technology Economy,2023,6(1).
- 陈浩. 黄鹤楼旅游景区在线文本情感分析研究[D].安徽财经大学,2021.
- 李颖. 基于旅游大数据的景观评价研究[D].浙江大学,2020.
- 陆保一,韦俊峰,明庆忠等.基于知识图谱的中国旅游大数据应用研究进展[J].经济地理,2022,42(01):230-240.
- 陆玉莹.旅游大数据的研究路径探索[J].现代商业,2021(19):36-38.
- 贾艳平,翟晋刚.基于Python爬虫技术的游客评论数据可视化分析[J].安阳师范学院学报,2021(05):51-54.
- 杨婷婷. 基于在线评论的旅游目的地游客感知形象研究[D].重庆工商大学,2020.
- 何靖. 旅游大数据赋能的游客出游预测模型研究[D].云南财经大学,2023.
- 邓宁,曲玉洁.我国旅游大数据的产业实践:现状、问题及未来[J].旅游导刊,2021,5(04):1-15.
- 郑俊,楼佳媛.一种基于旅游需求模板的景区评价数据分析舆情满意度方法[J].计算机时代,2017(03):62-64+67.
- 闰记影,孙秋兰.重庆市旅游大数据开发利用研究[J].河北旅游职业学院学报,2019,24(01):15-20.
- 余佥.Python语言在数据分析处理中的应用[J].电脑编程技巧与维护,2022(06):18-20.
- 贾宗星,冯倩.基于Python的拉勾网数据爬取与分析[J].计算机时代,2022(02):5-7+11.
- 李龙梅,王晓峰,王俊霞.基于网络评论的兵马俑景区游客满意度评价[J].宁夏师范学院学报,2011,32(06):70-73+81.
- 叶凌菲. 基于旅游大数据的景点位置识别与信息搜索研究[D].北京邮电大学,2018.
- 谢鹏威. 基于旅游大数据的日度客流分析建模研究[D].华南理工大学,2021.
- Chen H,Liu Y,Chen K. Big Data in Tourism: General Issues and Challenges[J]. Journal of Tourism & Hospitality,2021,10(Economics of Tourism).
- Kim H,Matthias L. The Current State of Big Data Research in Tourism: Results of a Systematic Literature Analysis[J]. Zeitschrift für Tourismuswissenschaft,2021,13(2).
- 刘燕.基于大数据技术的智能旅游数据间的相关性分析及应用研究[J].林业调查规划,2022,47(03):181-184.
- 杨勇. 机器学习在旅游数据分析中的应用研究[D].兰州大学,2022.
逝者如斯夫,不舍昼夜。转眼间,大学生活便已经接近尾声,人面对着离别与结束,总是充满着不舍与茫然,我亦如此,仍记得那年秋天,我迫不及待的提前一天到了学校,面对学校巍峨的大门,我心里充满了期待:这里,就是我新生活的起点吗?那天,阳光明媚,学校的欢迎仪式很热烈,我面对着一个个对着我微笑的同学,仿佛一缕缕阳光透过胸口照进了我心里,同时,在那天我认识可爱的室友,我们携手共同度过了这难忘的两年。如今,我望着这篇论文的致谢,不禁又要问自己:现在,我们就要说再见了吗?
感慨莫名,不知所言。遥想当初刚来学校的时候,心里总是想着工科学校会过于板正,会缺乏一些柔情,当时心里甚至有一点点排斥,但是随着我对学校的慢慢认识与了解,我才认识到了她的美丽,她的柔情,并且慢慢的喜欢上了这个校园,但是时间太快了,快到我还没有好好体会她的美丽便要离开了,但是她带给我的回忆,永远不会离开我,也许真正离开那天我的眼里会满含泪水,我不是因为难过,我只是想将她的样子映在我的泪水里,刻在我的心里。最后,感谢我的老师们,是你们教授了我们知识与做人的道理;感谢我的室友们,是你们陪伴了我如此之久;感谢每位关心与支持我的人。
少年,追风赶月莫停留,平荒尽处是春山。
点赞+收藏+关注 → 私信领取本源代码、数据库

欢迎大家加入成都城市开发者社区,“和我在成都的街头走一走”,让我们一起携手,汇聚IT技术潮流,共建社区文明生态!
更多推荐


 19
19 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)