【深度好文】MoE技术详解:大模型架构的革命性突破(小白也能懂)
【深度好文】MoE技术详解:大模型架构的革命性突破(小白也能懂)
Mixture of Experts(简称MoE,混合专家模型)是一种颠覆传统神经网络设计思路的架构范式,其核心逻辑是“分而治之”——将复杂任务拆解为多个细分场景,为每个场景匹配一个专门的专家网络,再通过“调度中心”(门控网络)协调专家分工。这种架构在大模型领域的应用,彻底打破了“模型性能提升必须依赖全参数计算”的瓶颈,让大规模模型的高效训练与推理成为可能。
近年来,随着大语言模型(LLMs)对参数规模和计算效率的需求激增,MoE技术从理论走向实用,成为GPT-4、Mixtral等顶尖大模型的核心架构支撑。本文将从MoE的起源讲起,拆解其在大模型中的落地逻辑,结合实际案例帮你搞懂这项关键技术。若需更系统的理论参考,可阅读权威综述:

一、MoE的“前世”:从理论构想走向技术突破
MoE并非新鲜概念,其雏形早在1991年就由机器学习领域权威学者Michael I. Jordan和Robert A. Jacobs在论文《Adaptive mixtures of local experts》中提出。当时他们构想的MoE架构包含两大核心组件:
- 专家网络(Expert Network):多个并行的“专业模块”,每个模块专注处理一类输入模式(比如图像中的“边缘检测”“纹理识别”);
- 门控网络(Gating Network):相当于“任务调度员”,根据输入数据的特征,判断哪些专家网络适合处理当前任务,并对专家的输出结果进行加权融合。
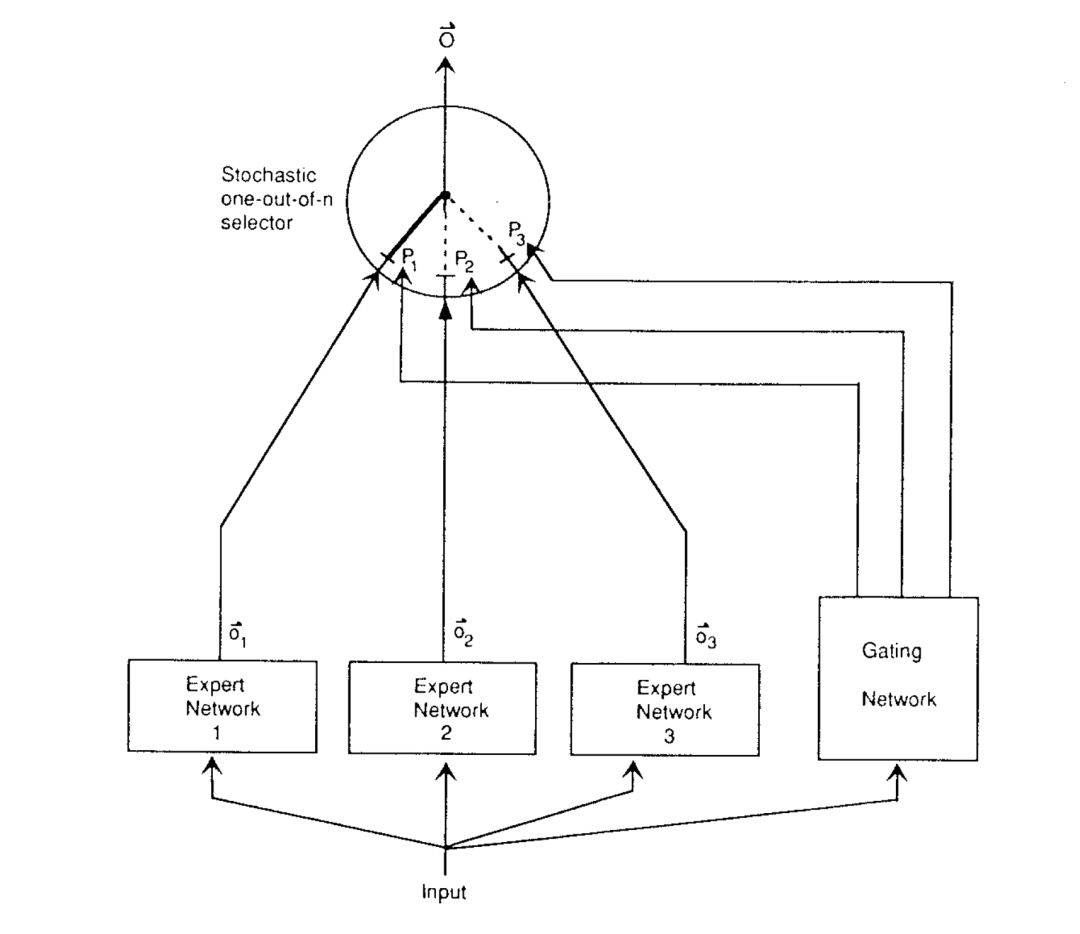
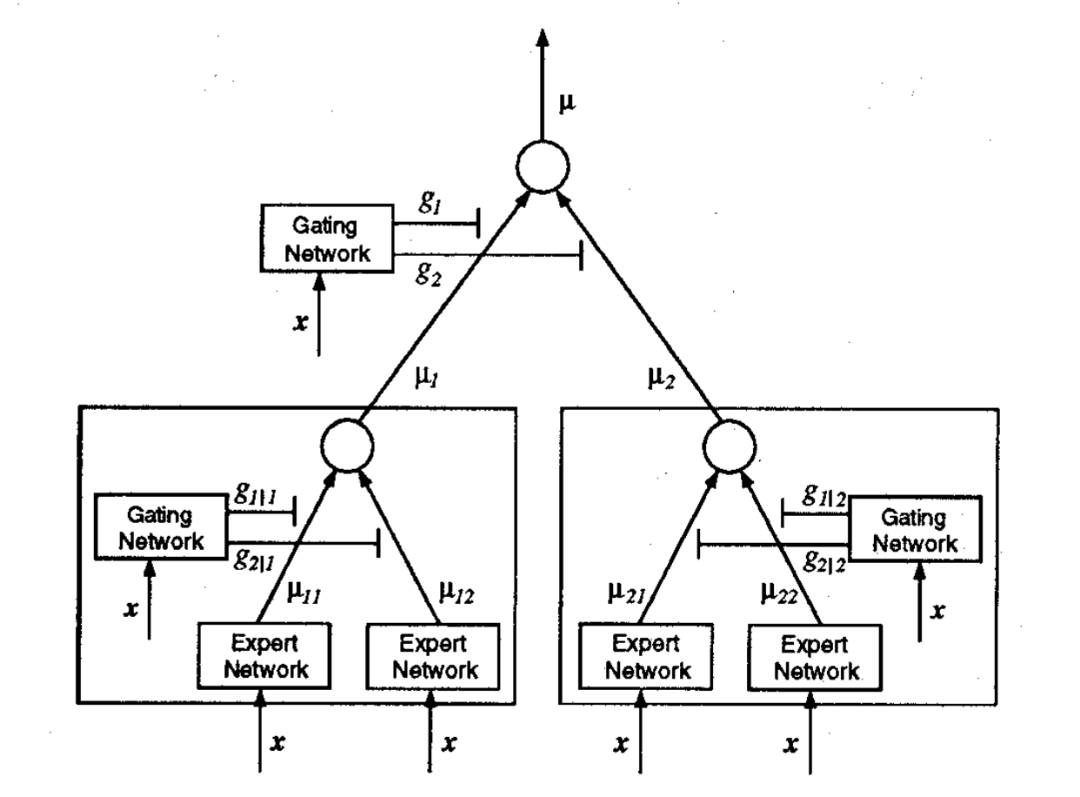
1993年,Jordan在后续论文《Hierarchical mixtures of experts and the EM algorithm》中进一步完善了MoE理论:提出“分层混合专家”(Hierarchical MoE)结构,将多个基础MoE模块再分层级,适配更复杂的任务;同时引入EM算法(期望最大化算法)解决MoE的训练收敛问题,为后续技术发展打下了理论基础。
然而,在提出后的近30年里,MoE始终未能广泛应用,核心瓶颈集中在三点:
- 算力制约:早期硬件算力有限,而MoE需要同时维护多个专家网络,训练和推理成本远超传统模型;
- 训练难题:门控网络的决策逻辑难以优化——要么出现“梯度消失”(门控对专家的选择信号无法传递到模型底层),要么出现“专家偏科”(少数专家被频繁调用,多数专家闲置);
- 无真正稀疏性:早期门控网络采用Softmax激活函数,会让所有专家网络同时参与计算(只是权重不同),无法实现“按需激活”,计算效率并未实质性提升。
直到2017年后,三项关键技术突破让MoE“重获新生”,并快速适配大模型需求:
- 稀疏门控技术:Google Brain团队在论文《Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer》中提出“稀疏门控”(Sparsely-Gated)——门控网络仅激活Top-k个(通常k=1或2)最匹配当前任务的专家,其他专家完全不参与计算,直接将计算效率提升一个量级;
- 大模型验证:Google在2021年推出的GLaM模型中首次规模化应用MoE,用1.2万亿总参数(实际活跃参数仅1370亿)实现了超越GPT-3的性能,且训练成本降低1/3,证明了MoE在“大参数+高效率”上的优势;
- Transformer适配:随着Transformer架构成为大模型主流,研究人员发现MoE可直接替换Transformer中的FFN(前馈网络)层,无需重构整体框架,这一改动让PaLM、Switch Transformers、Mixtral等模型快速接入MoE,推动其成为大模型标配技术。
二、MoE的“今生”:大模型中的落地逻辑与关键设计
GPT-4刚发布时,行业曾有一个广为流传的猜测:“GPT-4是由16个专家网络组成的MoE模型,每个专家含1110亿参数,总参数达1.77万亿”。当时不少人据此绘制了简单的“专家并行”架构图:
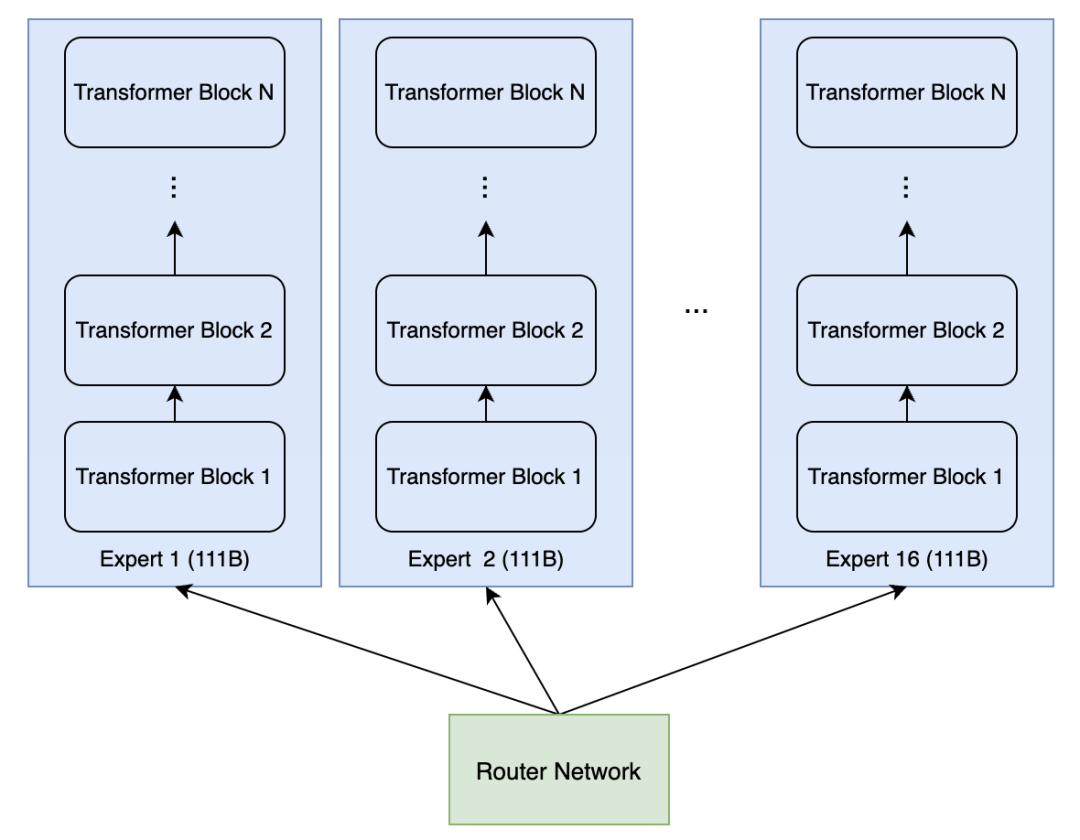
但实际大模型中的MoE设计远比这更精细——它并非将整个模型拆分为多个专家,而是仅替换Transformer中的FFN层为MoE层。这种“局部替换”的思路,既保留了Transformer的特征提取能力,又通过MoE实现了“参数扩容不增算力”的目标,成为当前大模型的主流方案。
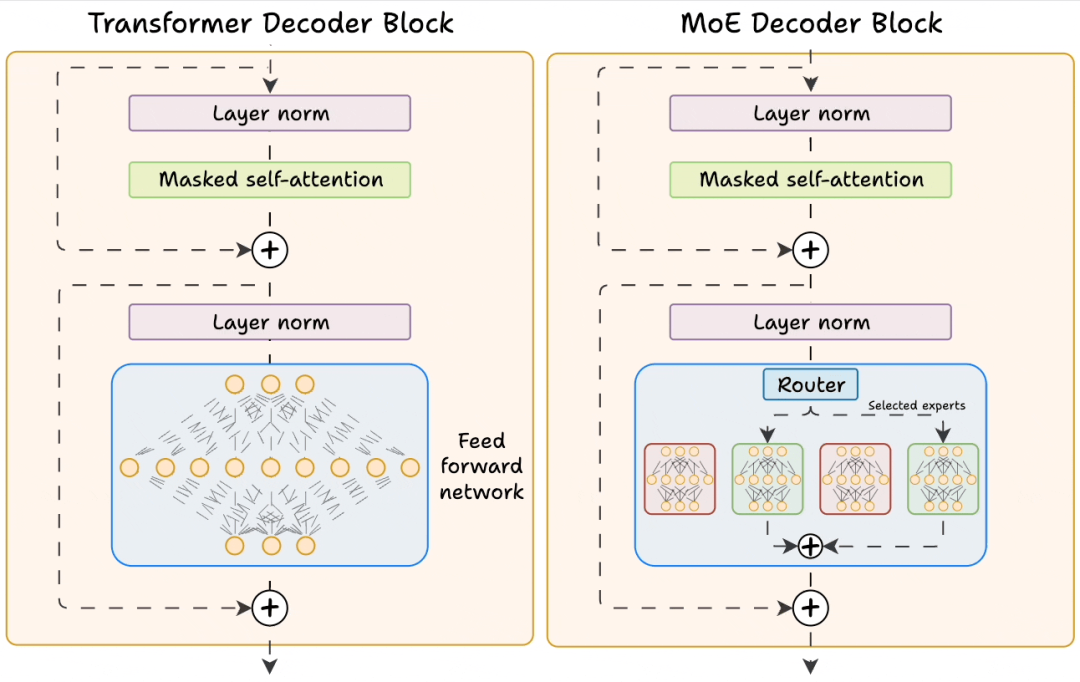
从架构图可见,大模型中的MoE层依然由“专家网络”和“门控网络”组成,但功能和设计更贴合语言任务需求:
- 专家网络:不再是独立的完整模型,而是一组并行的FFN子网络(数量从8个到上百个不等,如Mixtral 8x7B含8个专家)。每个专家网络有独立的权重,会针对性学习语言的某类模式(比如有的擅长处理逻辑推理,有的擅长生成诗歌,有的专注于代码语法);
- 门控网络(也称路由网络Router):是一个轻量级线性网络,输入为Transformer前一层的特征向量,输出为每个专家的“匹配分数”,最终根据分数选择Top-k个专家参与计算。
2.1 核心机制1:稀疏激活(Sparse Activation)——让计算“按需分配”
传统Transformer的FFN层是“密集计算”:无论输入是什么,都要激活FFN的所有参数,计算成本固定。而MoE层的核心优势是“稀疏激活”——仅让Top-k个专家参与计算,其他专家的参数完全不加载、不运算,直接降低计算量。
举个例子:Mixtral 8x7B的总参数约560亿(8个70亿参数专家),但每次推理时仅激活2个专家,实际参与计算的参数仅140亿,相当于用“小模型的算力”实现了“大模型的容量”。
稀疏激活的实现依赖门控网络的“Top-k选择”,目前最常用的是Google提出的“Noisy Top-K Gating”策略,通过引入噪声避免门控“固化选择”,具体步骤如下:
- 计算基础分数:门控网络对输入特征向量做线性变换,得到每个专家的初始匹配分数;
- 添加可调噪声:引入一个可学习的噪声矩阵,为初始分数添加随机扰动(避免门控总是选择同一批专家);
- 筛选Top-k专家:对加噪后的分数排序,只保留前k个分数最高的专家,其余专家的分数设为极小值(-1e9);
- 计算激活权重:对Top-k专家的分数做Softmax,得到每个专家的激活权重,用于后续输出融合。
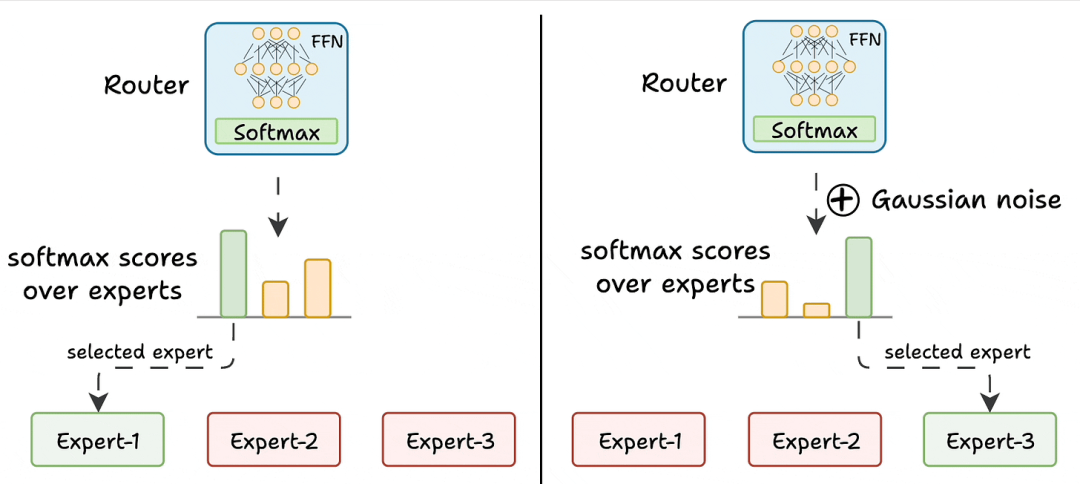
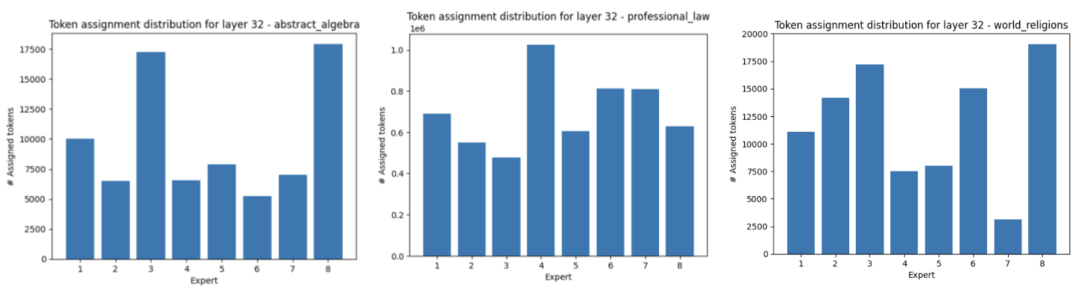
这种机制让不同输入能精准匹配擅长的专家:比如输入“写一段Python代码”时,门控会优先激活“代码处理专家”;输入“解释相对论”时,则会激活“科学知识专家”。下图展示了Mixtral 8x7B第32层中,不同领域输入对应的专家Token分配情况,可见专家的“分工明确”:
而词云图进一步直观呈现了每个专家最常处理的Token,比如有的专家高频处理“if、for、def”等代码关键词,有的则高频处理“因为、所以、结论”等逻辑推理词汇:

2.2 核心机制2:负载均衡损失(Load Balancing Loss, LBL)——避免专家“忙闲不均”
如果仅用Top-k选择,会出现一个严重问题:负载不均衡。比如某个专家特别擅长处理“日常对话”类输入,而这类输入在训练数据中占比极高,导致该专家被频繁调用,其他专家长期闲置——不仅浪费模型容量,还会让闲置专家的参数无法有效更新,影响模型整体性能。
为解决这一问题,研究人员在训练过程中引入了“负载均衡辅助损失”(LBL),其核心目标是“强迫门控网络均匀调用所有专家”。LBL的计算逻辑围绕两个指标:
- 专家选择频率:每个专家在一个训练批次(Batch)中被选中的次数;
- 专家平均分数:每个专家被选中时的匹配分数均值。
经典的LBL公式设计为:让所有专家的“选择频率×平均分数”尽可能接近,当所有专家的这一乘积相等时,LBL达到最小值,此时负载完全均衡。
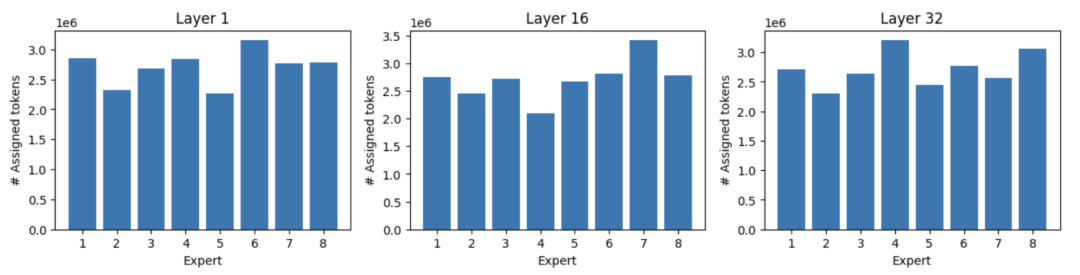
引入LBL后,模型会在“精准匹配任务”和“均匀调用专家”之间找到平衡。下图展示了Mixtral 8x7B经过LBL优化后,不同层中每个专家的Token分配情况——可见各专家的负载差异明显缩小,资源利用率大幅提升:
2.3 代码示例:基于PyTorch实现Noisy Top-k Gating
以下是简化版的Noisy Top-k门控网络实现代码,基于PyTorch框架,可直观理解稀疏激活的逻辑:
import torch
import torch.nn as nn
import torch.nn.functional as F
class NoisyTopkRouter(nn.Module):
def __init__(self, d_model, num_experts, top_k=2):
super(NoisyTopkRouter, self).__init__()
self.top_k = top_k # 每次激活的专家数量,默认2
self.gate_linear = nn.Linear(d_model, num_experts) # 计算专家基础分数
self.noise_linear = nn.Linear(d_model, num_experts) # 计算噪声幅度(可学习)
def forward(self, x):
# x: 输入特征,形状为[batch_size, seq_len, d_model]
batch_size, seq_len, d_model = x.shape
# 1. 计算基础分数和噪声
base_logits = self.gate_linear(x) # [batch_size, seq_len, num_experts]
noise_scale = F.softplus(self.noise_linear(x)) # 噪声幅度(确保非负)
noise = torch.randn_like(base_logits) * noise_scale # 生成可调噪声
# 2. 加噪后筛选Top-k专家
noisy_logits = base_logits + noise
top_k_logits, top_k_indices = noisy_logits.topk(self.top_k, dim=-1) # 选前k个专家
# 3. 构建稀疏分数矩阵(非Top-k专家分数设为-1e9,Softmax后接近0)
sparse_logits = torch.full_like(noisy_logits, fill_value=-1e9)
sparse_logits = sparse_logits.scatter(dim=-1, index=top_k_indices, src=top_k_logits)
# 4. 计算专家激活权重
gating_weights = F.softmax(sparse_logits, dim=-1) # [batch_size, seq_len, num_experts]
return gating_weights, top_k_indices # 返回权重和选中的专家索引
三、总结:MoE为何是大模型的“未来方向”
如今,MoE技术已在GPT-4、Mixtral、PaLM 2等顶级大模型中验证了其价值——它解决了大模型发展的核心矛盾:如何在控制计算成本的前提下,持续提升模型容量和性能。
传统大模型是“密集架构”:参数规模翻倍,计算成本也近乎翻倍;而MoE是“稀疏架构”:总参数规模可通过增加专家数量轻松扩展,但计算成本仅取决于“激活专家的数量”,实现了“容量与算力的解耦”。这种特性让大模型能够以更低的成本探索“万亿参数”甚至更大规模的可能性。
从行业趋势看,随着大模型在复杂任务(如多模态、科学计算、通用智能)上的需求提升,MoE的优势会进一步凸显——未来的大模型可能不再是“单一巨无霸”,而是由无数个“专精专家”组成的“协作网络”,而MoE正是构建这种网络的核心技术基石。

那么,如何系统的去学习大模型LLM?
作为一名从业五年的资深大模型算法工程师,我经常会收到一些评论和私信,我是小白,学习大模型该从哪里入手呢?我自学没有方向怎么办?这个地方我不会啊。如果你也有类似的经历,一定要继续看下去!这些问题啊,也不是三言两语啊就能讲明白的。
所以我综合了大模型的所有知识点,给大家带来一套全网最全最细的大模型零基础教程。在做这套教程之前呢,我就曾放空大脑,以一个大模型小白的角度去重新解析它,采用基础知识和实战项目相结合的教学方式,历时3个月,终于完成了这样的课程,让你真正体会到什么是每一秒都在疯狂输出知识点。
由于篇幅有限,⚡️ 朋友们如果有需要全套 《2025全新制作的大模型全套资料》,扫码获取~
为什么要学习大模型?
我国在A大模型领域面临人才短缺,数量与质量均落后于发达国家。2023年,人才缺口已超百万,凸显培养不足。随着AI技术飞速发展,预计到2025年,这一缺口将急剧扩大至400万,严重制约我国AI产业的创新步伐。加强人才培养,优化教育体系,国际合作并进是破解困局、推动AI发展的关键。


👉大模型学习指南+路线汇总👈
我们这套大模型资料呢,会从基础篇、进阶篇和项目实战篇等三大方面来讲解。

👉①.基础篇👈
基础篇里面包括了Python快速入门、AI开发环境搭建及提示词工程,带你学习大模型核心原理、prompt使用技巧、Transformer架构和预训练、SFT、RLHF等一些基础概念,用最易懂的方式带你入门大模型。
👉②.进阶篇👈
接下来是进阶篇,你将掌握RAG、Agent、Langchain、大模型微调和私有化部署,学习如何构建外挂知识库并和自己的企业相结合,学习如何使用langchain框架提高开发效率和代码质量、学习如何选择合适的基座模型并进行数据集的收集预处理以及具体的模型微调等等。
👉③.实战篇👈
实战篇会手把手带着大家练习企业级的落地项目(已脱敏),比如RAG医疗问答系统、Agent智能电商客服系统、数字人项目实战、教育行业智能助教等等,从而帮助大家更好的应对大模型时代的挑战。
👉④.福利篇👈
最后呢,会给大家一个小福利,课程视频中的所有素材,有搭建AI开发环境资料包,还有学习计划表,几十上百G素材、电子书和课件等等,只要你能想到的素材,我这里几乎都有。我已经全部上传到CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
相信我,这套大模型系统教程将会是全网最齐全 最易懂的小白专用课!!

惟楚有才,于斯为盛。欢迎来到长沙!!! 茶颜悦色、臭豆腐、CSDN和你一个都不能少~
更多推荐
 12
12 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)