FlexQuant: 大模型组合量化,助力推理SLO
本文基于不同量化算法在不同阶段、不同负载下的速度和精度表现,设计了一种组合量化机制FlexQuant,可以更全面、更轻松拿下精度、速度以及延迟和吞吐等SLO诉求,方案部署友好,直接有效,值得参考。
文章作者:李金金,赵守仁,蔡腾纬,赵军平。
介绍蚂蚁集团Asystem团队、在线推理团队针对大模型推理量化加速的探索实践,提出的FlexQuant方案通过组合业界多种量化方法,且在运行时动态协同、取长补短以满足业务对精度、延迟和吞吐等全方面诉求,效果反馈良好,且实测发现1+1>2意外之喜。此外,该方案可完美匹配PD分离场景。欢迎交流探讨。
一、背景
大模型推理面临计算压力、显存容量、访存带宽等综合挑战。量化是解决以上三方面挑战的重要手段之一。业界涌现了很多优秀的量化算法,例如AWQ,GPTQ,SmoothQuant,QServe等,然而典型硬件和负载下的实测表明,不同的量化算法对不同负载(batch)和阶段(prefill、decode等)所呈现的速度、精度表现存在较大波动和差异,即一种量化方法难以同时满足线上多方面的诉求:既要保证精度,又要首字延迟(TTFT),还要生成速度(TPOT)。
针对以上实际情况,分享团队在前段时间(2024年)的推理优化工作FlexQuant:一种高效的量化组合机制,它通过显存资源换来对SLO强要求、高标准满足,并减少复杂度和工程量。方案基于vLLM开发上线。核心要点包括:
-
确保精度和速度:逼近最好精度的同时,获得最快的速度(首字和生成)。
-
RT和吞吐的动态权衡:自动适应不同负载(batch),和PD不同阶段特点,例如Prefill采用量化A,decode采用量化B,(注:不涉及KV cache)。
-
统一的量化机制:一次量化过程可产出多个量化模型,方便部署使用。
注:
-
彼时(2024年)PD分离没火,以下主要基于非PD评测。但FlexQuant与PD分离八字极极极极其匹配。
-
基于本方案,与上海交大合作完成的同名论文已被AI顶会接收。arxiv链接:
FlexQuant: A Flexible and Efficient Dynamic Precision Switching Framework for LLM Quantization
https://arxiv.org/abs/2506.12024
二、分析调研
当前大模型量化以PTQ为主,典型有不同精度对称/非对称、per-channel/per-group等粒度、FP或INT。业界往往锚定一种量化方法,期待能包打所有不同场景。
-
W: 4~8bit
-
A: 4~16bit
-
KV: 2~8bit
然而不同场景、负载压力(batch)或序列长短下的实测表明,量化算法往往各有所长,一种方法难以在所有场合全面胜出,由此,我们希望动态组合多种方法,且让它们之间取长补短、动态切换,通过打组合拳的方式来满足业务场景的高要求。
1.硬件算力对比
不同精度在典型硬件上Tensor core算力对比如图1;低bit通常意味更快速度(但精度稍差)。
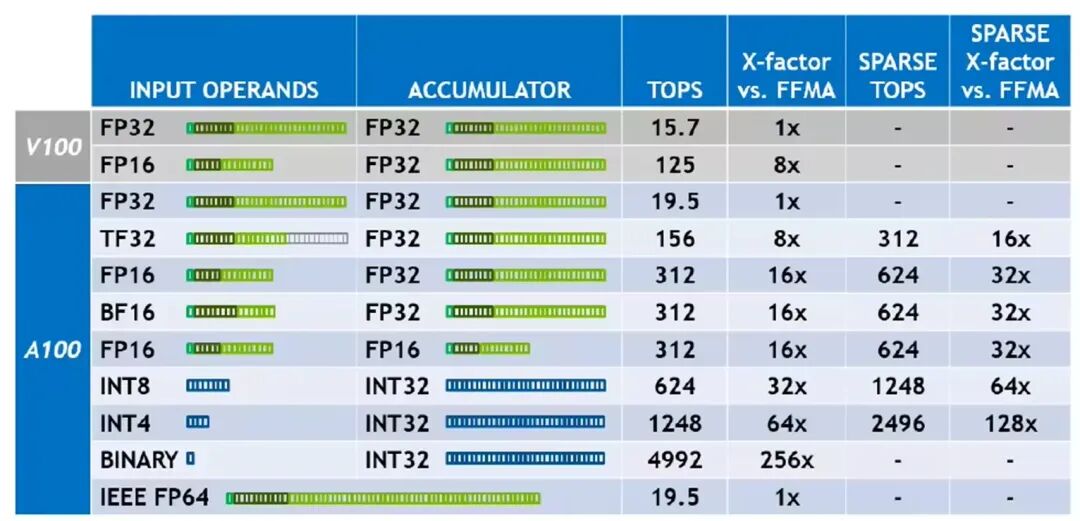
图1:不同bit的算力对比
2.不同量化方法的速度对比:PD阶段和batch
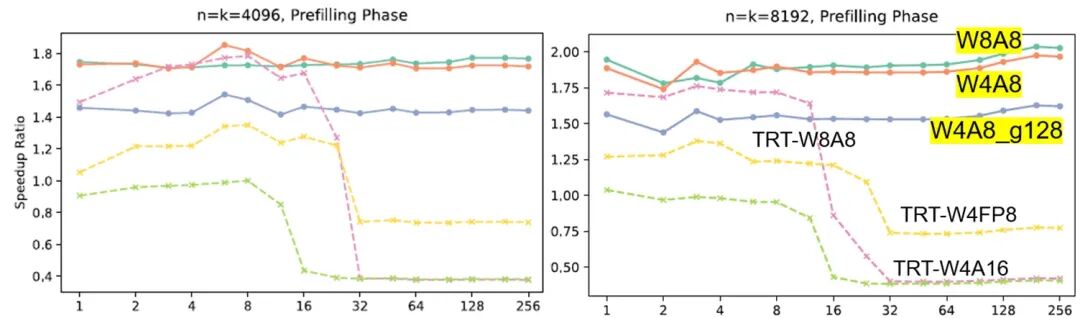
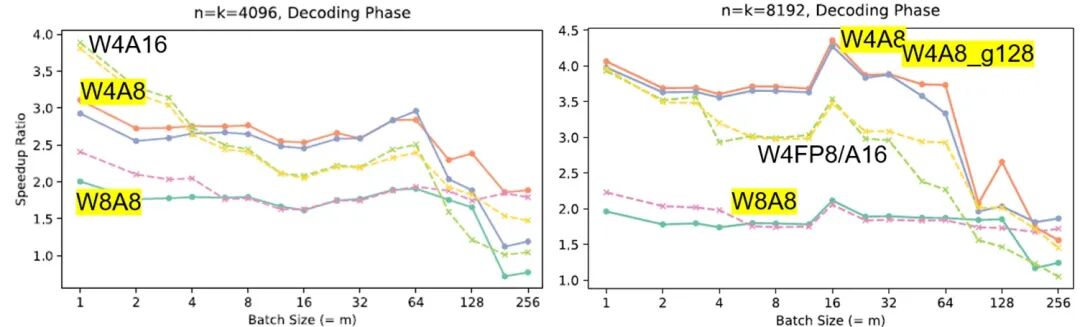
图2:不同量化算法的速度对比(注:2024年数据;最新数据可能有变化)
硬件: NVIDIA L40s 48GB
量化方法:
-
QServe:W4A8 per-channel、W4A8 per-group、W8A8
-
TRT-LLM:W4A16(AWQ)、W4AFP8(AWQ)、W8A8(SmoothQuant)
简要分析
1.prefill阶段
-
QServe的W8A8和W4A8明显最快(特别是中大batch),但二者速度差别不大(即如果为了保证精度,可以优先选择W8A8)。中小batch情况下,TRT-LLM的W8A8也与二者接近。
-
W4A16量化性能普遍差现。
-
支持更多的模型。
2.decode阶段
-
中小模型(或4~8卡拆分),batch=1~4时:W4A16的性能最好,QServe的W8A8最慢
-
大batch下、更大模型时:QServe的W4A8性能更好
典型例子:
-
QServe的W8A8:在prefill最快,decode时反而最慢;
-
TRT-W4A16:相反,prefill最慢,但decode在小batch情况下反而最快。
3.不同量化方法的精度对比
不同的量化方法精度往往不一样,通常(虽然不是所有场景)精度排序如下:
-
W8A8 >= W4A16 > W4A8 > W4A4
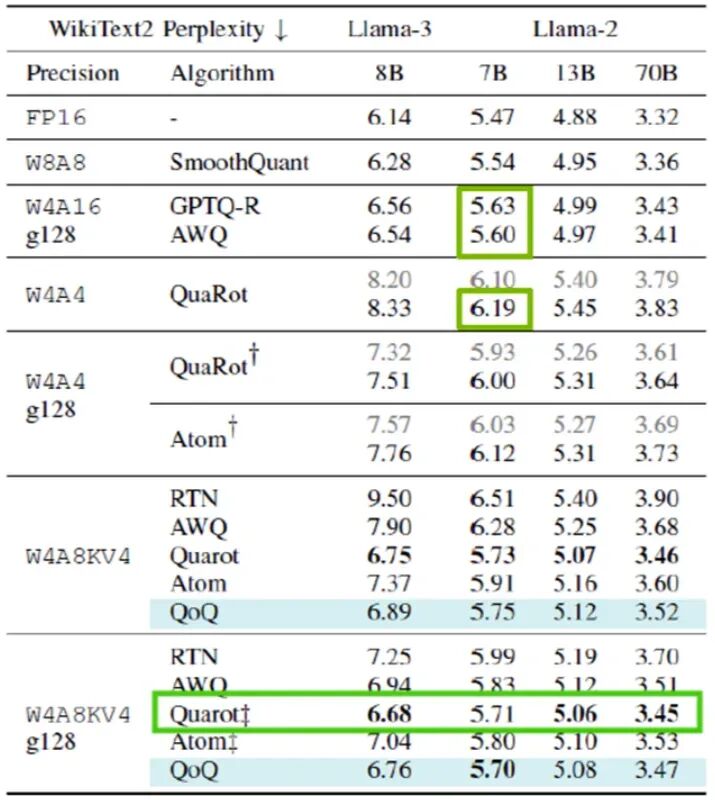
图3:精度对比(2024年数据,仅供参考)
三、FlexQuant方案
1.总体思路
组合思路:一次量化产出N个量化版模型(通常N=2);同时加载部署,在运行时根据负载、PD阶段和压力,以及精度/速度preference,由预定义策略触发自动切换。
-
典型场景如某时刻batch小,选择量化1;另时刻batch大,选择量化2。
动态组合策略:
-
PD-aware:prefill默认基于W8A8, decode组合W4A16和W8A8(见batch-aware)。
-
-
Prefill典型是计算密集,通常W8A8通过减少反量化开销速度优于W4A16;而decode通常是访存密集,中小batch负载下W4A16通常优于W8A8,而随batch增加 W8A8优势明显。
-
prefill对精度通常要求更高,选择高精度的W8A8;decode则动态切换。
-
-
Batch-aware:batch<=X时,decode用W4A16;大batch高吞吐需求下则切换到W4A8。
-
Layer-aware: 前N层使用较高bit量化,之后基于策略才激活更低bit量化等。此处详见论文。
2.总体架构
总体如图4所示。主要包含2个组件。方案彼时基于vLLM实现,也可以适配到其他框架如SGLang等。
-
QuantFactory: 产出不同版本的量化模型(16、8、4bit等)
-
QuantScheduler:动态调度不同的量化模型,P/D aware,Batch-aware、Layer-aware
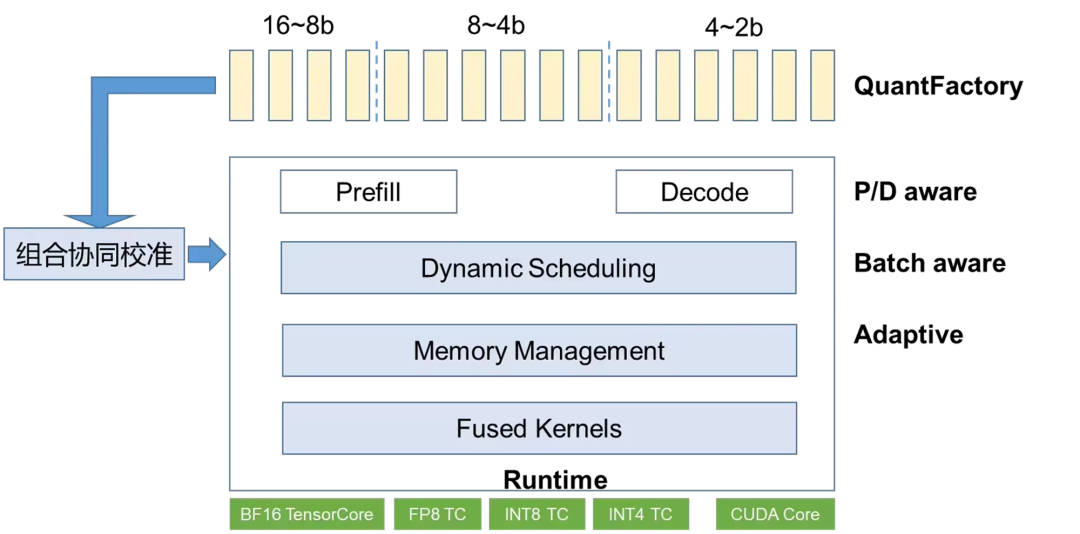
图4:FlexQuant总体架构
3.实现简介
我们基于llmcompressor量化+vLLM推理实现了FlexQuant,将多个量化模型合并成一个新模型,在模型内部动态调度多个量化模型。
-
量化过程只需要在vLLM里新增一种特殊的模型,比较方便支持不同模型、量化算法。
离线量化
基于llmcompressor
-
w4a16量化和w8a8量化的方法可以直接参考llmcompressor github
-
模型合并这部分主要有2点
-
-
合并weight:对权重的key加上不同的前缀防止互相覆盖
-
合并config.json:由于两份config.json之间必然有diff,因此需要新增字段,将量化相关的配置分别存放,推理的时候按约定读取和解析
-
tokenizer相关的配置所有量化模型均一致
-
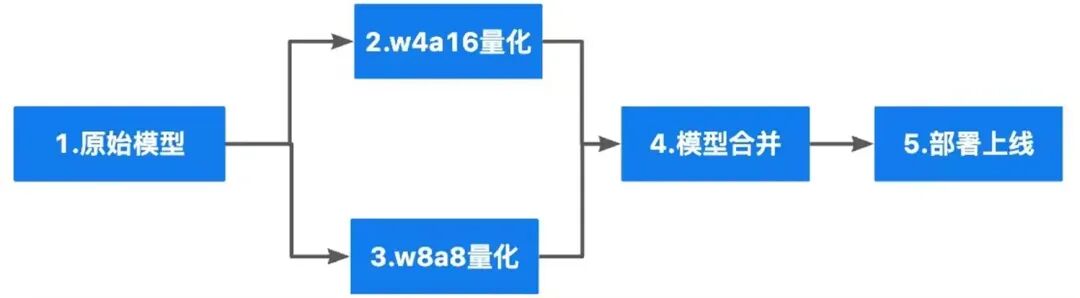
图5:FlexQuant离线量化过程
在线推理
-
在vLLM里增加一个新的模型类型,合并这2个量化模型。
-
在vLLM里用新增的这个模型,加载模型权重(2个量化模型分别load对应的weight)。
-
-
根据所处的阶段(prefill/decode)分别调用量化版本。
-
根据不同batch_size分别调用量化版本。
-
总体只要框架支持该量化算法,就可以方便的组合进来。
-
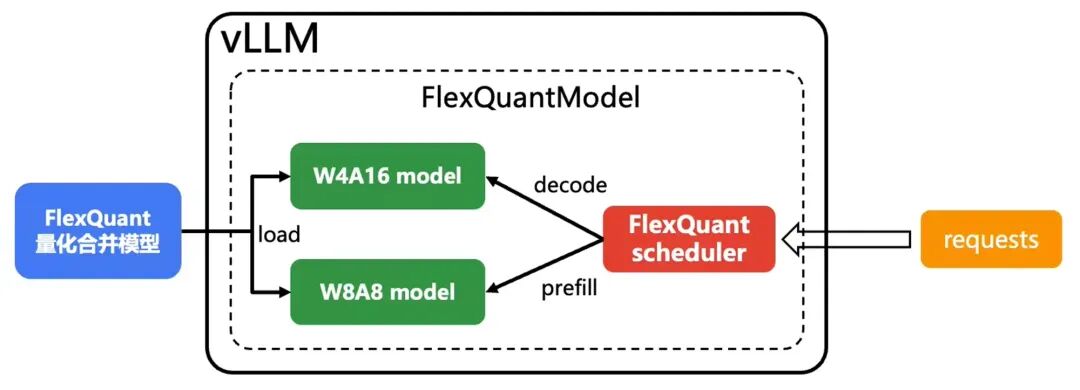
图6:FlexQuant在线推理与动态调用不同量化方法示意
补充说明
-
量化算法选择:目前主要验证支持的是W/A量化,即不同量化算法之间kv cache必须要可以共用。比如QServe这类量化过程中使用了rotate和smooth的算法,推理过程中的kv cache必然和GPTQ量化出来的模型不一样,无法组合使用。
-
显存开销:目前会加载2个模型(一份W8+一份W4),虽然相比W8和W4显存占用都有所增加,但相比W16仍减少了25%,且在小batch场景下性能上取得了W8A8和W4A16之间的最优解(参考4.2),适合SLO高要求或吞吐压力不太高场景。
-
-
注:取决于业务场景,很多在线部署为了优先满足首字指标,堆卡并行,卡略冗余而显存富裕。
-
四、FlexQuant评测
下面是精度和性能方面的评测结果。
1.精度评测
基于常见评测集(opencompass)的全方位对比评测,所有评测集相比BF16基线精度影响<1个点。
2.性能评测
-
引擎:vLLM(0.6.3 +FlexQuant)
-
硬件:L20*4
-
模型:80B模型,内部在线负载。
-
-
W8A8量化版
-
W4A16量化版(GPTQ)
-
FlexQuant组合量化版:组合以上2种。
-
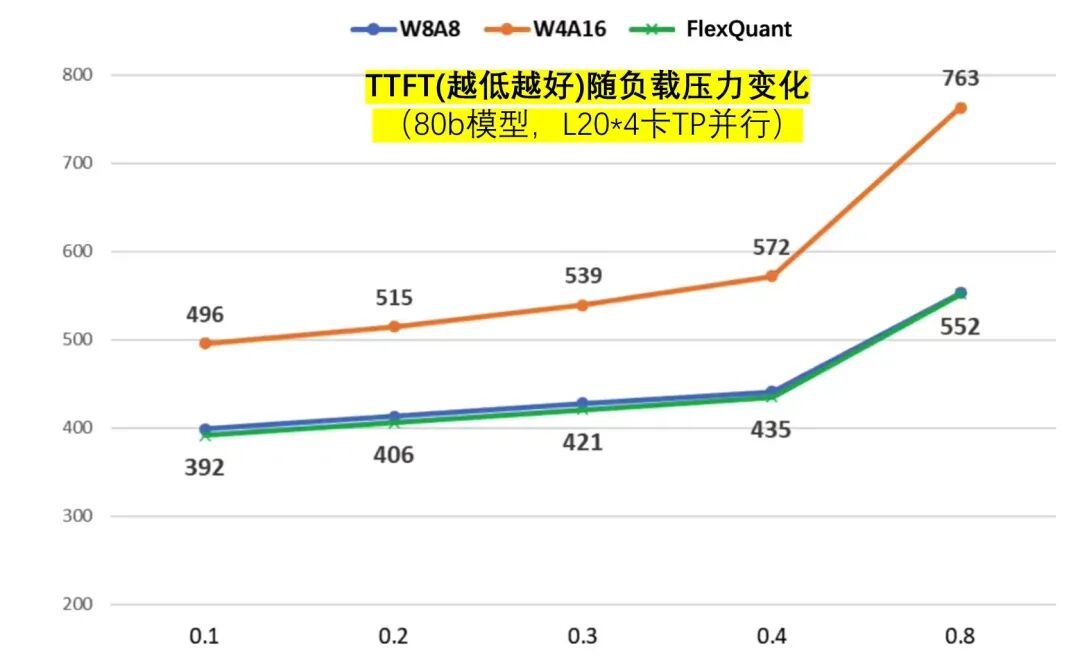
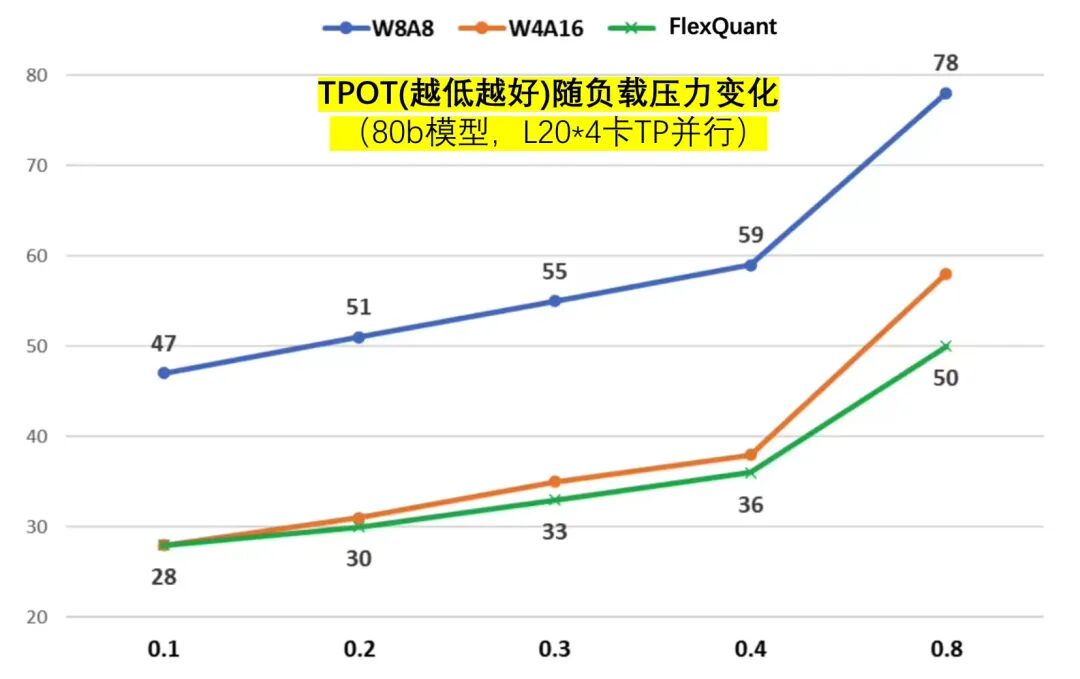
图7:FlexQuant的首字延迟、TPOT指标对比
结果分析:
-
首字与W8A8一致,比W4A16快最多28%;同时,生成速度比W8A8快36%~41%且优于W4A16。
-
-
有意思的是生成速度指标上,由于TTFT的约束,负载中等(此时运行时动态选择了W4A16),相比基线(PD都基于W4A16),FlexQuant组合方式下由于Prefill变得更高效,减少了对Decode的干扰,使得decode阶段的性能反超基线、更胜一筹,这就是1 + 1 > 2的意外之喜,妙手偶得。
-
-
由此FlexQuant达到了预设目标,它融合W4A16和W8A8各自优势,实现了既要又要且青胜于蓝。
五、小结
本文基于不同量化算法在不同阶段、不同负载下的速度和精度表现,设计了一种组合量化机制FlexQuant,可以更全面、更轻松拿下精度、速度以及延迟和吞吐等SLO诉求,方案部署友好,直接有效,值得参考。

惟楚有才,于斯为盛。欢迎来到长沙!!! 茶颜悦色、臭豆腐、CSDN和你一个都不能少~
更多推荐

 29
29 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)