arXiv 2025 | 轻量级分组注意力模块,即插即用,涨点起飞!
本文提出了一种轻量级群组注意力骨干网络LWGANet,用于遥感视觉任务。该网络的核心创新是轻量级群组注意力(LWGA)模块,通过特征分组并行处理,高效提取并融合从局部到全局的多尺度空间信息,解决遥感图像中目标尺度差异大的问题。LWGA模块集成了四种针对不同尺度的注意力子模块,协同工作以捕捉不同尺寸目标特征。实验表明,LWGANet在12个遥感数据集上的场景分类、目标检测、语义分割和变化检测任务中,
1. 基本信息

-
标题: LWGANet: A Lightweight Group Attention Backbone for Remote Sensing Visual Tasks
-
论文来源: https://arxiv.org/abs/2404.14920v1
-
作者与单位: Wei Lu, Si-Bao Chen, Jin Tang, Bin Luo (安徽大学); Chris H. Q. Ding (香港中文大学(深圳))
2. 核心创新点
-
提出轻量级群组注意力 (LWGA) 模块:在轻量化前提下,通过特征分组并行处理,高效提取并融合从局部到全局的多尺度空间信息,专门解决遥感图像中目标尺度差异巨大的挑战。
-
设计专为遥感任务优化的骨干网络 (LWGANet):基于LWGA模块构建了一个全新的轻量级骨干网络,在参数量和计算量(FLOPs)上具有显著优势,同时在多个遥感任务中表现出色。
-
开创性的多注意力机制融合:LWGA模块内部创新性地集成了四种针对不同尺度设计的注意力子模块(GPA, RLA, SMA, SGA),协同工作以精细化捕捉微小目标、局部细节、中等尺寸不规则目标和全局上下文。
-
广泛的有效性和通用性验证:在涵盖场景分类、旋转目标检测、语义分割和变化检测四大遥感视觉任务的12个公开数据集上进行了全面实验,证明了LWGANet在保持低复杂度的同时,实现了SOTA性能。
3. 方法详解
整体结构概述: LWGANet采用分层架构,共包含四个阶段,每个阶段的特征图分辨率依次降低为输入的1/4, 1/8, 1/16和1/32。网络以一个步长为4的卷积层(Stem)开始,随后是多个LWGA Block堆叠。每个阶段之间通过一个DRFD下采样模块连接,以保留精细特征。LWGA Block是网络的核心,由一个LWGA模块和一个CMLP模块(通道多层感知机)通过残差连接构成。
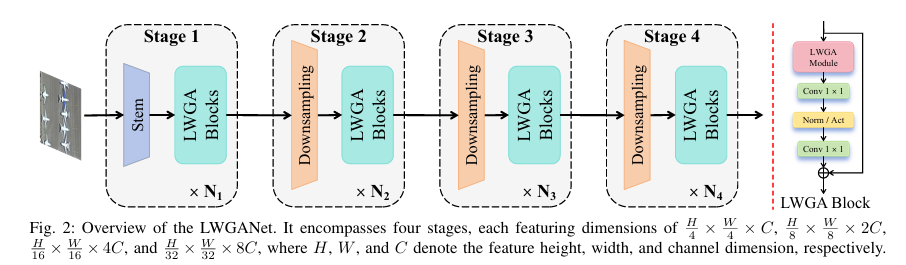
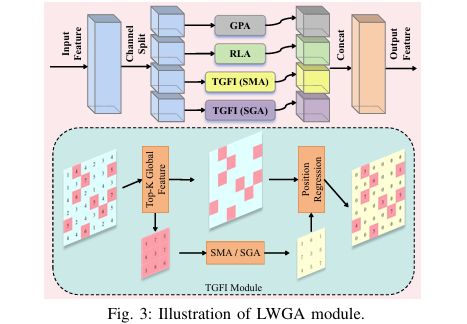
步骤分解: LWGA模块是LWGANet的特征提取核心,其工作流程如下:
-
特征分组:输入特征图 在通道维度上被平均分割成四个部分 ,每部分通道数为 。
-
门控点注意力 (GPA) 模块:处理 ,通过通道扩张与收缩,并利用Sigmoid函数生成注意力图,强化对微小目标的特征响应。
-
常规局部注意力 (RLA) 模块:处理 ,本质是一个标准的3x3卷积,专注于高效提取局部纹理和边缘等细节特征。
-
稀疏中程注意力 (SMA) 模块:处理 ,首先通过TGFI模块稀疏化采样特征,然后在采样点上执行中程注意力计算,以捕获中等尺寸和不规则对象的上下文信息。其核心计算公式如下:
-
稀疏全局注意力 (SGA) 模块:处理 ,采用分阶段策略。在浅层网络(Stage 1/2),使用大核空洞卷积模拟全局注意力以降低计算量;在深层网络(Stage 3/4),则使用标准的视觉注意力机制来建立长距离依赖关系。
-
特征融合:将四个分支处理后的特征 沿通道维度拼接(Concatenate),形成最终的输出特征 。
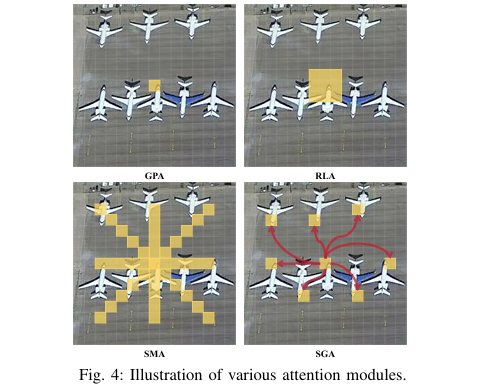
4. 即插即用模块作用
LWGA模块是一个可即插即用的核心组件
适用场景
该技术可作为骨干网络的核心模块,广泛应用于多种遥感视觉任务:
-
场景分类 (如 UCM, AID, NWPU 数据集)
-
旋转目标检测 (如 DOTA, DIOR-R 数据集)
-
语义分割 (如 UAVid, LoveDA 数据集)
-
变化检测 (如 LEVIR-CD, WHU-CD 数据集)
主要作用
它能为下游任务模型带来以下核心收益:
-
模拟多尺度特征提取能力:通过并行处理点、局部、中程和全局信息,有效替代复杂的多分支或特征金字塔结构。
-
大幅降低计算复杂度:在不增加空间维度和额外参数的情况下,有效扩展感受野,为轻量化模型提供强大的多尺度表征能力。
-
增强模型性能与泛化性:帮助模型更好地处理遥感图像中尺度变化剧烈的物体(如港口中的大小船只),提升检测和分割的准确率。
-
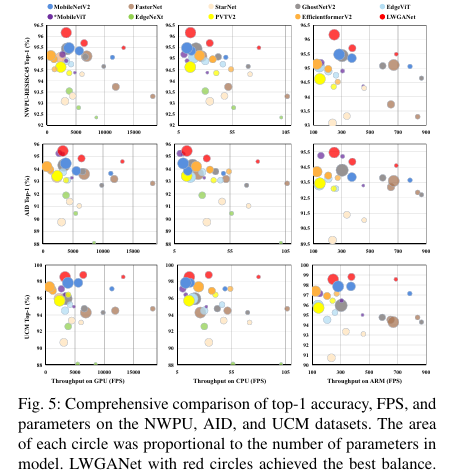
增强模型的可部署性:在资源受限的设备(如无人机、移动端)上,实现高性能与低延迟的平衡,论文在GPU、CPU和ARM平台上验证了其高效性。
总结
LWGA是一个即插即用的轻量级注意力模块,通过并行的“分而治之”策略,以极低的计算成本高效捕获并融合遥感图像中的多尺度特征。
5. 即插即用模块
以下代码片段根据论文中对 LWGA 模块 的描述,展示了其核心的“特征分组-并行处理-融合”思想的实现逻辑。这体现了其模块化和即插即用的价值。 ➔➔➔➔点击查看原文,获取本文及其他精选即插即用模块集合
import torch
import torch.nn as nn
from timm.models.layers import DropPath, trunc_normal_
from typing import List
from torch import Tensor
import antialiased_cnns
import torch.nn.functional as F
class PA(nn.Module):
def __init__(self, dim, norm_layer, act_layer):
super().__init__()
self.p_conv = nn.Sequential(
nn.Conv2d(dim, dim*4, 1, bias=False),
norm_layer(dim*4),
act_layer(),
nn.Conv2d(dim*4, dim, 1, bias=False)
)
self.gate_fn = nn.Sigmoid()
def forward(self, x):
att = self.p_conv(x)
x = x * self.gate_fn(att)
return x
class LA(nn.Module):
def __init__(self, dim, norm_layer, act_layer):
super().__init__()
self.conv = nn.Sequential(
nn.Conv2d(dim, dim, 3, 1, 1, bias=False),
norm_layer(dim),
act_layer()
)
def forward(self, x):
x = self.conv(x)
return x
class MRA(nn.Module):
def __init__(self, channel, att_kernel, norm_layer):
super().__init__()
att_padding = att_kernel // 2
self.gate_fn = nn.Sigmoid()
self.channel = channel
self.max_m1 = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)
self.max_m2 = antialiased_cnns.BlurPool(channel, stride=3)
self.H_att1 = nn.Conv2d(channel, channel, (att_kernel, 3), 1, (att_padding, 1), groups=channel, bias=False)
self.V_att1 = nn.Conv2d(channel, channel, (3, att_kernel), 1, (1, att_padding), groups=channel, bias=False)
self.H_att2 = nn.Conv2d(channel, channel, (att_kernel, 3), 1, (att_padding, 1), groups=channel, bias=False)
self.V_att2 = nn.Conv2d(channel, channel, (3, att_kernel), 1, (1, att_padding), groups=channel, bias=False)
self.norm = norm_layer(channel)
def forward(self, x):
x_tem = self.max_m1(x)
x_tem = self.max_m2(x_tem)
x_h1 = self.H_att1(x_tem)
x_w1 = self.V_att1(x_tem)
x_h2 = self.inv_h_transform(self.H_att2(self.h_transform(x_tem)))
x_w2 = self.inv_v_transform(self.V_att2(self.v_transform(x_tem)))
att = self.norm(x_h1 + x_w1 + x_h2 + x_w2)
out = x[:, :self.channel, :, :] * F.interpolate(self.gate_fn(att),
size=(x.shape[-2], x.shape[-1]),
mode='nearest')
return out
def h_transform(self, x):
shape = x.size()
x = torch.nn.functional.pad(x, (0, shape[-1]))
x = x.reshape(shape[0], shape[1], -1)[..., :-shape[-1]]
x = x.reshape(shape[0], shape[1], shape[2], 2*shape[3]-1)
return x
def inv_h_transform(self, x):
shape = x.size()
x = x.reshape(shape[0], shape[1], -1).contiguous()
x = torch.nn.functional.pad(x, (0, shape[-2]))
x = x.reshape(shape[0], shape[1], shape[-2], 2*shape[-2])
x = x[..., 0: shape[-2]]
return x
def v_transform(self, x):
x = x.permute(0, 1, 3, 2)
shape = x.size()
x = torch.nn.functional.pad(x, (0, shape[-1]))
x = x.reshape(shape[0], shape[1], -1)[..., :-shape[-1]]
x = x.reshape(shape[0], shape[1], shape[2], 2*shape[3]-1)
return x.permute(0, 1, 3, 2)
def inv_v_transform(self, x):
x = x.permute(0, 1, 3, 2)
shape = x.size()
x = x.reshape(shape[0], shape[1], -1)
x = torch.nn.functional.pad(x, (0, shape[-2]))
x = x.reshape(shape[0], shape[1], shape[-2], 2*shape[-2])
x = x[..., 0: shape[-2]]
return x.permute(0, 1, 3, 2)
class GA12(nn.Module):
def __init__(self, dim, act_layer):
super().__init__()
self.downpool = nn.MaxPool2d(kernel_size=2, stride=2, return_indices=True)
self.uppool = nn.MaxUnpool2d((2, 2), 2, padding=0)
self.proj_1 = nn.Conv2d(dim, dim, 1)
self.activation = act_layer()
self.conv0 = nn.Conv2d(dim, dim, 5, padding=2, groups=dim)
self.conv_spatial = nn.Conv2d(dim, dim, 7, stride=1, padding=9, groups=dim, dilation=3)
self.conv1 = nn.Conv2d(dim, dim // 2, 1)
self.conv2 = nn.Conv2d(dim, dim // 2, 1)
self.conv_squeeze = nn.Conv2d(2, 2, 7, padding=3)
self.conv = nn.Conv2d(dim // 2, dim, 1)
self.proj_2 = nn.Conv2d(dim, dim, 1)
def forward(self, x):
x_, idx = self.downpool(x)
x_ = self.proj_1(x_)
x_ = self.activation(x_)
attn1 = self.conv0(x_)
attn2 = self.conv_spatial(attn1)
attn1 = self.conv1(attn1)
attn2 = self.conv2(attn2)
attn = torch.cat([attn1, attn2], dim=1)
avg_attn = torch.mean(attn, dim=1, keepdim=True)
max_attn, _ = torch.max(attn, dim=1, keepdim=True)
agg = torch.cat([avg_attn, max_attn], dim=1)
sig = self.conv_squeeze(agg).sigmoid()
attn = attn1 * sig[:, 0, :, :].unsqueeze(1) + attn2 * sig[:, 1, :, :].unsqueeze(1)
attn = self.conv(attn)
x_ = x_ * attn
x_ = self.proj_2(x_)
x = self.uppool(x_, indices=idx)
return x
class D_GA(nn.Module):
def __init__(self, dim, norm_layer):
super().__init__()
self.norm = norm_layer(dim)
self.attn = GA(dim)
self.downpool = nn.MaxPool2d(kernel_size=2, stride=2, return_indices=True)
self.uppool = nn.MaxUnpool2d((2, 2), 2, padding=0)
def forward(self, x):
x_, idx = self.downpool(x)
x = self.norm(self.attn(x_))
x = self.uppool(x, indices=idx)
return x
class GA(nn.Module):
def __init__(self, dim, head_dim=4, num_heads=None, qkv_bias=False,
attn_drop=0., proj_drop=0., proj_bias=False, **kwargs):
super().__init__()
self.head_dim = head_dim
self.scale = head_dim ** -0.5
self.num_heads = num_heads if num_heads else dim // head_dim
if self.num_heads == 0:
self.num_heads = 1
self.attention_dim = self.num_heads * self.head_dim
self.qkv = nn.Linear(dim, self.attention_dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(self.attention_dim, dim, bias=proj_bias)
self.proj_drop = nn.Dropout(proj_drop)
def forward(self, x):
B, C, H, W = x.shape
x = x.permute(0, 2, 3, 1)
N = H * W
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, self.head_dim).permute(2, 0, 3, 1, 4)
q, k, v = qkv.unbind(0) # make torchscript happy (cannot use tensor as tuple)
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, H, W, self.attention_dim)
x = self.proj(x)
x = self.proj_drop(x)
x = x.permute(0, 3, 1, 2)
return x
class LWGA_Block(nn.Module):
def __init__(self,
dim,
stage,
att_kernel,
mlp_ratio,
drop_path,
act_layer,
norm_layer
):
super().__init__()
self.stage = stage
self.dim_split = dim // 4
self.drop_path = DropPath(drop_path) if drop_path > 0.else nn.Identity()
mlp_hidden_dim = int(dim * mlp_ratio)
mlp_layer: List[nn.Module] = [
nn.Conv2d(dim, mlp_hidden_dim, 1, bias=False),
norm_layer(mlp_hidden_dim),
act_layer(),
nn.Conv2d(mlp_hidden_dim, dim, 1, bias=False)
]
self.mlp = nn.Sequential(*mlp_layer)
self.PA = PA(self.dim_split, norm_layer, act_layer) # PA is point attention
self.LA = LA(self.dim_split, norm_layer, act_layer) # LA is local attention
self.MRA = MRA(self.dim_split, att_kernel, norm_layer) # MRA is medium-range attention
if stage == 2:
self.GA3 = D_GA(self.dim_split, norm_layer) # GA3 is global attention (stage of 3)
elif stage == 3:
self.GA4 = GA(self.dim_split) # GA4 is global attention (stage of 4)
self.norm = norm_layer(self.dim_split)
else:
self.GA12 = GA12(self.dim_split, act_layer) # GA12 is global attention (stages of 1 and 2)
self.norm = norm_layer(self.dim_split)
self.norm1 = norm_layer(dim)
self.drop_path = DropPath(drop_path)
def forward(self, x: Tensor) -> Tensor:
# for training/inference
shortcut = x.clone()
x1, x2, x3, x4 = torch.split(x, [self.dim_split, self.dim_split, self.dim_split, self.dim_split], dim=1)
x1 = x1 + self.PA(x1)
x2 = self.LA(x2)
x3 = self.MRA(x3)
if self.stage == 2:
x4 = x4 + self.GA3(x4)
elif self.stage == 3:
x4 = self.norm(x4 + self.GA4(x4))
else:
x4 = self.norm(x4 + self.GA12(x4))
x_att = torch.cat((x1, x2, x3, x4), 1)
x = shortcut + self.norm1(self.drop_path(self.mlp(x_att)))
return x
if __name__ == "__main__":
batch_size = 1
dim = 32
height, width = 256, 256
input_tensor = torch.randn(batch_size, dim, height, width).cuda()
# 初始化 LWGA_Block
model = LWGA_Block(
dim=dim,
stage=2,
att_kernel=3,
mlp_ratio=4.0,
drop_path=0.1,
act_layer=nn.GELU,
norm_layer=nn.BatchNorm2d
).cuda()
print(model) # 前向传播
output = model(input_tensor)
# 打印输入输出形状
print(f"Input shape: {input_tensor.shape}")
print(f"Output shape: {output.shape}")

惟楚有才,于斯为盛。欢迎来到长沙!!! 茶颜悦色、臭豆腐、CSDN和你一个都不能少~
更多推荐

 19
19 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)