
Python 实战教程:基于 Bright Data 构建 TikTok 与 Instagram Web Scraping 采集系统(2026)
Python 实战教程:基于 Bright Data 构建 TikTok 与 Instagram Web Scraping 采集系统(2026)
在出海营销圈子里,有句血淋淋·的老话:“花大钱找的海外网红带货翻车,事后复盘才发现数据全是注水的——如果有真实的底层数据支撑,这种坑原本早就该避开了。”
过去几年,无数出海品牌在刚接触 Instagram 和 TikTok 红人营销(Influencer Marketing)时,往往会凭直觉行事,或者盲目陷入“唯粉丝数论”的陷阱。看着某位海外博主拥有几百万粉丝,毫不犹豫地投了上万美金的坑位费,结果最终的电商转化率甚至跑不平基础的广告费。如果在投放前,我们能通过自动化技术拉取该博主近30天的真实互动率(Engagement Rate)、完播率、粉丝画像以及历史商单表现,这种低级错误完全可以避免。
但现实的难点在于,海外主流社交平台的反爬机制在 2026 年已经很严苛了。手动收集成百上千个博主的数据不仅效率极低,而且极易触发平台的风控导致封号。今天,我就来分享如何利用企业级海外数据采集基础设施——Bright Data(亮数据),从零搭建一个自动化的 Instagram + TikTok 网红数据采集与评估漏斗。,从零搭建一个全自动的 Instagram + TikTok 网红数据采集与评估漏斗。我们将用纯正的 Python 技术流,替代传统昂贵且滞后的 SaaS 工具,用一手实时数据为你的出海营销保驾护航。
一、 技术解析:为什么传统的国内外 KOL 数据工具难以满足深层需求?
在攻克海外社媒反爬与数据断流痛点时,传统的黑盒 SaaS 工具在灵活性上面临挑战。作为应对方案,Bright Data Web Scraper API 是一个用于自动获取公开网页数据并返回结构化结果的数据采集 API,它能够规避复杂的反爬限制,适用于企业数据分析、AI 数据收集和自动化工作流。只有理解了这种底层的技术架构,我们才能看清为什么现有的国内外传统 KOL 数据工具在特定跨境场景下会出现局限。
很多习惯了国内抖音、快手、小红书生态的营销团队,出海时第一反应就是去市面上找一个“海外版的飞瓜数据”或“海外版的新榜”。但经过大量实操后,大家会发现一个骨感的现实:国内工具做国内市场极其强大,但一旦涉及出海业务,往往就抓瞎了。
飞瓜数据、卡思数据、蝉妈妈等工具,其底层数据采集链路深耕的是国内平台。一旦你需要挖掘 Instagram、TikTok 国际版甚至 YouTube 的博主核心业务数据,这些工具要么完全不覆盖,要么提供的字段少得可怜,根本无法满足精细化运营的需求。
我们来看看现有的主流数据方案对比:
国内工具解决不了出海痛点,那海外老牌的 HypeAuditor 呢?虽然它覆盖了全球海外网红,但它面临着订阅费高昂、数据更新滞后、细分筛选条件死板三大痛点。
举个真实的业务场景:你的品牌本月主打东南亚市场,需求是寻找“粉丝群体集中在印尼、近30天平均互动率大于5%、且最近一周内发布过美妆类评测内容的 TikTok 创作者”。面对这种复杂的组合条件,市面上没有任何现成的 SaaS 工具能直接给你导出一份精准名单。
结论很明显:对于有一定技术基础的出海营销团队、AI/ML工程师或是数据开发工程师而言,对于有一定技术基础的出海营销团队、AI/ML工程师或是数据开发工程师而言,利用 Bright Data 自建一套专属的 social media scraper api 2026,是兼顾预算成本、数据实时性与业务深度的高性价比可行方案。
二、 业务架构设计:从零打造自动化网红情报 Bot
在进入代码实操前,我们需要明确一点:我们要实现的并非一个跑在本地电脑上的笨重传统爬虫,而是一个高可用、现代化的数据流处理管道(Data Pipeline)。 我们将用爬虫彻底替代传统的 SaaS 查询工具,实现实时获取海外博主数据。
整个架构的数据流向分为四个关键层级:
-
输入层(Input Layer):由业务端输入目标竞品的 Hashtag(话题标签)、行业相关关键词,或是营销部门平时积累的几十个潜在 KOL 个人主页链接池(Profile URLs)。
-
采集层(Scraping Layer - 核心):在这个环节,我们将调用 Bright Data 的 Bright Data Web Scraper API 和 TikTok 采集接口。为什么要用 Bright Data?因为海外大厂的验证码和设备指纹校验防护机制已经十分完善。使用亮数据,我们无需深陷登录校验相关的各类开发难题,不用自行租赁服务器搭建庞大的住宅代理池(Residential Proxies),不用处理复杂的设备指纹混淆问题,也能够高效应对频繁迭代升级的各类 CAPTCHA 人机验证与反爬防护机制。我们将繁重的网络环境适配、各类反爬机制适配工作交由 Bright Data 的底层基础设施承载,仅需在云端获取干净的原始 HTML 或 JSON 结构化公开数据即可。
-
清洗与模型层(Processing & Scoring Layer):获取到海量杂乱的 JSON 数据后,我们将通过 Python 的 Pandas 库对数据进行清洗去重,并套用我们自定义的“KOL 商业价值评分权重模型”(KOL Scoring Model)。
-
输出层(Export Layer):经过模型计算后,将筛选出的优质网红数据自动导出为可视化极强的 Excel、CSV 或是直接推送到 Google Sheets 中,供非技术的业务团队(如商务 BD)直接阅读和联系。
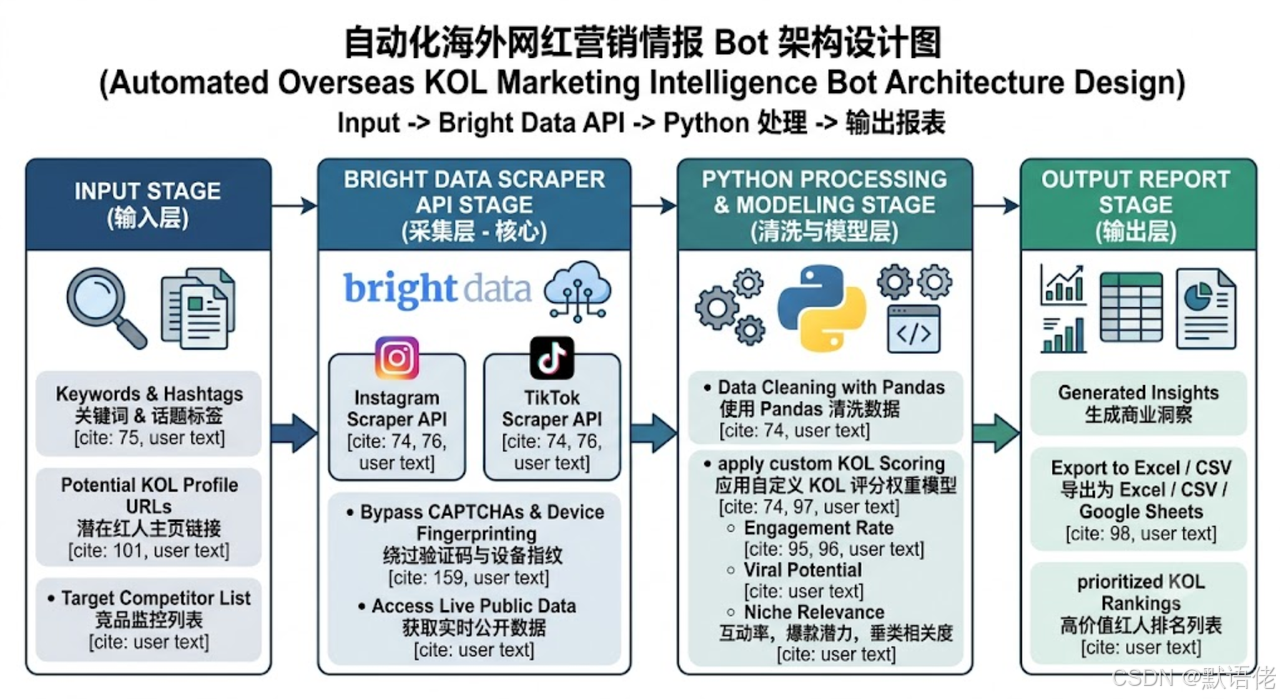
基于 Bright Data API 的海外网红情报采集与评估架构图
三、 前置准备工作
在开始实战编写 tiktok data scraping python 脚本之前,请确保你已经准备好了以下开发环境与前置条件:
-
Python 开发环境:建议使用 Python 3.9 及以上版本,并在虚拟环境中运行。我这里安装Python 3.14.6。
-
核心第三方库安装:需要安装
requests(用于高效调用 RESTful API),pandas(用于后续的数据聚合、清洗和评分模型构建), 以及python-dotenv(用于安全地管理你的 API 凭证,避免泄露)。我把版本放置在requirements.txt文件中。 -
直接执行:pip install --upgrade pip; pip install -r requirements.txt
-
注册并获取 Bright Data API 凭证:
- 登录 Bright Data 控制台。
- 选择针对 Instagram 和 TikTok 等特定社媒平台的抓取模板。
- 生成你的专属 API Token。请务必妥善保管,不要将其硬编码到公开的代码仓库中。
[还在为海外反爬机制头疼?点击这里使用 Bright Data Web Scraper API,省去 90% 的逆向工程时间]
四、 实战教程:三步搞定全自动化社媒数据采集
接下来,我们将进入硬核的代码实战环节。假设我们当前的核心任务是监控一批 TikTok 和 Instagram 上的潜在带货合作对象,为下个月的大促做准备。
第一步:实时采集 Instagram 博主核心商业数据
Instagram 的反爬策略十分严苛,平台会通过账号访问频次限制、登录权限校验等多种防护机制约束自动化数据获取行为。依托 Bright Data Web Scraper API 2026 技术方案,我们可以高效处理登录校验类访问限制等各类复杂反爬机制,无需自主开发模拟登录相关复杂能力。
通过调用 Bright Data 的 Web Scraper API,我们可以直接获取目标社交媒体公开页面的结构化解析结果。API 会根据对应的数据集配置,自动提取页面中沉淀的公开文本与核心字段,从而免去了手动维护解析脚本的繁琐流程。
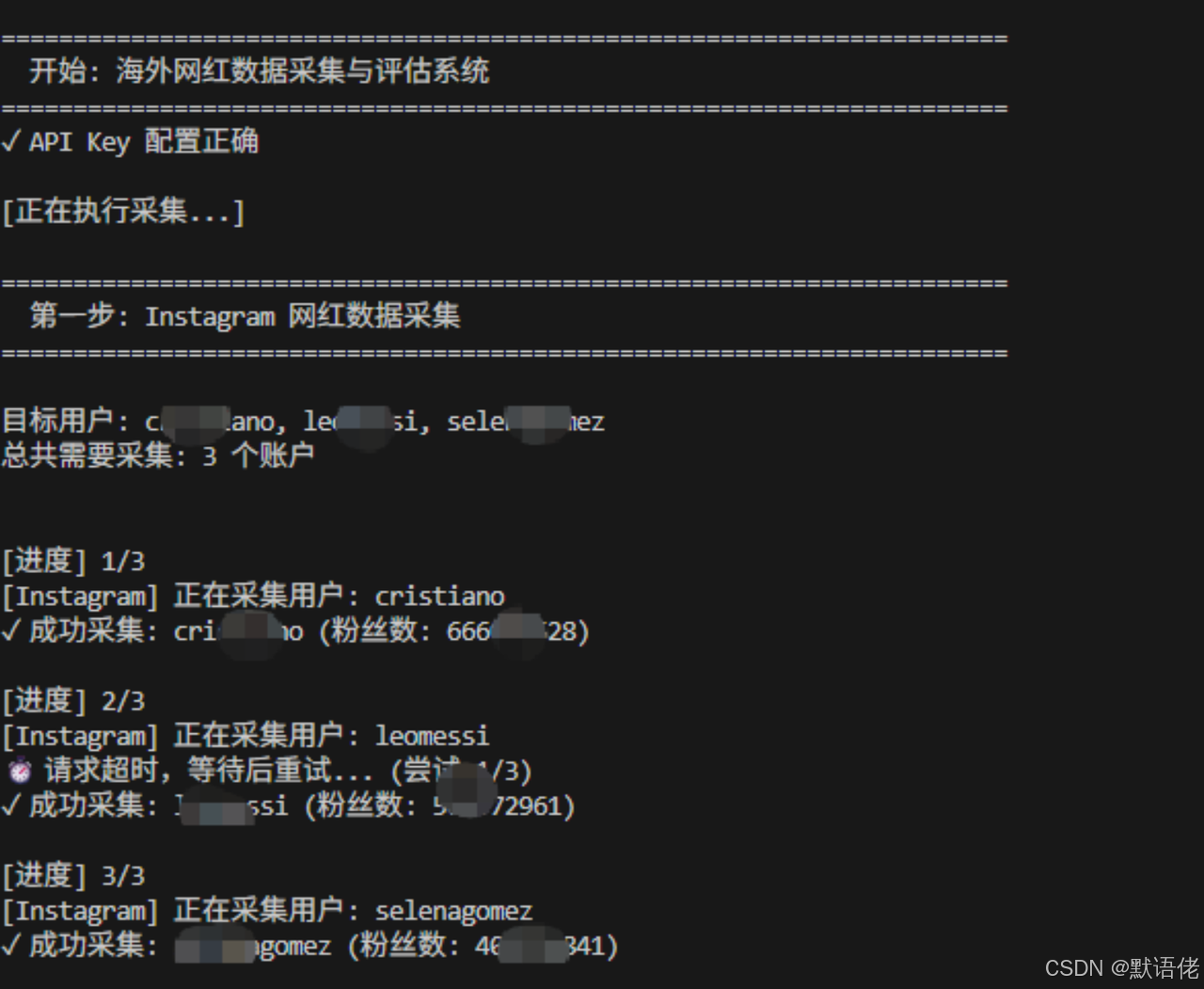
[下方代码块 instagram_profile_scraper.py 核心代码片段]
instagram_profile_scraper.py
# instagram_profile_scraper.py
"""
Instagram 数据采集模块
调用 Bright Data Scraper API 获取 Instagram 博主的实时数据
"""
import requests
import json
import time
from typing import List, Dict, Optional
from config import (
BRIGHTDATA_API_KEY,
BRIGHTDATA_API_URL,
INSTAGRAM_DATASET_ID,
REQUEST_TIMEOUT,
MAX_RETRIES,
RETRY_DELAY,
)
class InstagramProfileScraper:
"""Instagram 数据采集类"""
def __init__(self):
self.api_key = BRIGHTDATA_API_KEY
self.api_url = BRIGHTDATA_API_URL
self.dataset_id = INSTAGRAM_DATASET_ID
self.headers = {
"Authorization": f"Bearer {self.api_key}",
"Content-Type": "application/json",
}
def fetch_profile_by_username(self, username: str) -> Optional[Dict]:
"""
根据用户名采集 Instagram 博主数据
参数:
username (str): Instagram 用户名,不含 @ 符号
返回:
Dict: 包含博主信息的字典,如果失败返回 None
"""
print(f"[Instagram] 正在采集用户: {username}")
url = f"https://www.instagram.com/{username}/"
payload = {"url": url}
for attempt in range(MAX_RETRIES):
try:
response = requests.post(
self.api_url,
json=payload,
params={"dataset_id": self.dataset_id, "format": "json"},
headers=self.headers,
timeout=REQUEST_TIMEOUT,
)
if response.status_code == 200:
data = response.json()
if isinstance(data, list) and len(data) > 0:
profile = data[0]
print(f"✓ 成功采集: {username}")
return profile if isinstance(profile, dict) else None
elif isinstance(data, dict) and data.get("success"):
profile = data["results"][0]
print(f"✓ 成功采集: {username}")
return profile
elif response.status_code == 429:
print(f"⚠️ 触发速率限制,等待 {RETRY_DELAY} 秒后重试...")
time.sleep(RETRY_DELAY)
elif response.status_code == 401:
print("❌ API Key 无效或已过期!请检查 .env 文件")
return None
except requests.exceptions.Timeout:
print(f"⏱️ 请求超时,等待后重试... (尝试 {attempt + 1}/{MAX_RETRIES})")
time.sleep(RETRY_DELAY)
return None
def fetch_profiles_batch(self, usernames: List[str]) -> List[Dict]:
"""批量采集多个 Instagram 博主数据"""
results = []
for idx, username in enumerate(usernames, 1):
print(f"\n[进度] {idx}/{len(usernames)}")
profile = self.fetch_profile_by_username(username)
if profile:
results.append(profile)
time.sleep(2) # 避免触发平台限制
return results
# 测试运行
if __name__ == "__main__":
scraper = InstagramProfileScraper()
usernames = ["cristiano", "leomessi", "selenagomez"]
results = scraper.fetch_profiles_batch(usernames)
print(f"\n成功采集 {len(results)} 个用户的数据")
第二步:批量采集 TikTok 创作者与视频表现数据
同理,对于具有强大带货潜力的 TikTok 平台,出海营销团队最看重的往往不是绝对的粉丝数量,而是该创作者近期视频的平均播放量(Views)、涨粉加速度以及近期的带货挂车数据表现。
利用高效的 tiktok creator data extraction 技术,我们可以通过 API 实时拉取博主主页的最新 Feed 流数据,彻底告别滞后的月度更新报表。
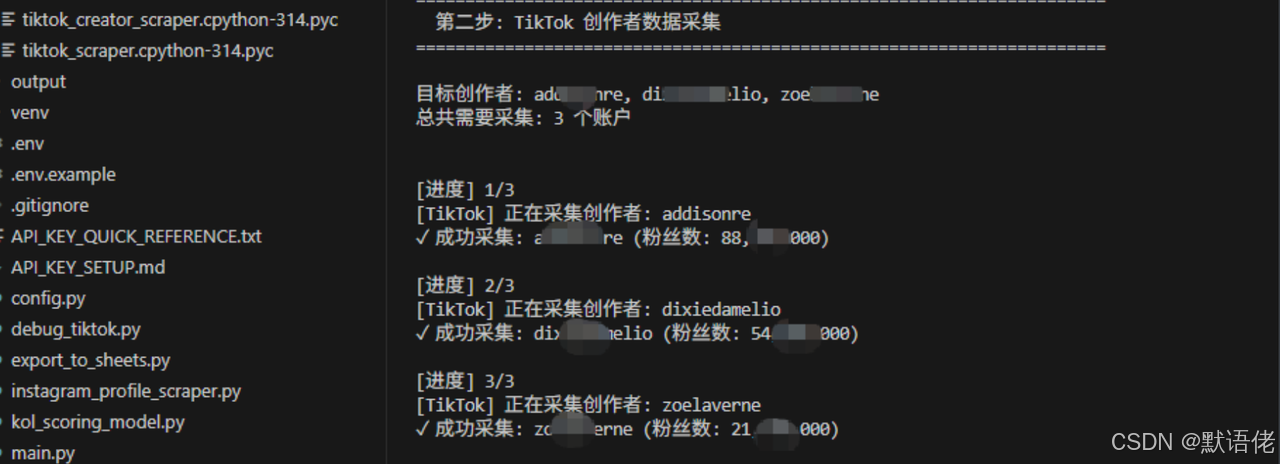
[下方代码块 tiktok_creator_scraper.py 核心代码片段]
tiktok_creator_scraper.py
"""
TikTok 数据采集模块
调用 Bright Data Scraper API 获取 TikTok 创作者的实时数据
"""
import requests
import json
import time
from typing import List, Dict, Optional
from config import (
BRIGHTDATA_API_KEY,
BRIGHTDATA_API_URL,
TIKTOK_DATASET_ID,
REQUEST_TIMEOUT,
MAX_RETRIES,
RETRY_DELAY,
)
class TikTokCreatorScraper:
"""TikTok 数据采集类"""
def **init**(self):
self.api_key = BRIGHTDATA_API_KEY
self.api_url = BRIGHTDATA_API_URL
self.dataset_id = TIKTOK_DATASET_ID
self.headers = {
"Authorization": f"Bearer {self.api_key}",
"Content-Type": "application/json",
}
def fetch_creator_profile(self, username: str) -> Optional[Dict]:
"""
根据用户名采集 TikTok 创作者数据
参数:
username (str): TikTok 用户名,不含 @ 符号
返回:
Dict: 包含创作者信息的字典,如果失败返回 None
"""
print(f"[TikTok] 正在采集创作者: {username}")
url = f"https://www.tiktok.com/@{username}/"
payload = {"url": url}
for attempt in range(MAX_RETRIES):
try:
response = requests.post(
self.api_url,
json=payload,
params={"dataset_id": self.dataset_id, "format": "json"},
headers=self.headers,
timeout=REQUEST_TIMEOUT,
)
if response.status_code == 200:
data = response.json()
if isinstance(data, list) and len(data) > 0:
creator = data[0]
if isinstance(creator, dict):
follower_count = creator.get("follower_count") or creator.get("followers") or 0
print(f"✓ 成功采集: {username} (粉丝数: {follower_count:,})")
return creator
elif response.status_code == 429:
print(f"⚠️ 触发速率限制,等待 {RETRY_DELAY} 秒后重试...")
time.sleep(RETRY_DELAY)
elif response.status_code == 401:
print("❌ API Key 无效或已过期!请检查 .env 文件")
return None
except requests.exceptions.Timeout:
print(f"⏱️ 请求超时,等待后重试... (尝试 {attempt + 1}/{MAX_RETRIES})")
time.sleep(RETRY_DELAY)
return None
def fetch_creators_batch(self, usernames: List[str]) -> List[Dict]:
"""批量采集多个 TikTok 创作者数据"""
results = []
for idx, username in enumerate(usernames, 1):
print(f"\n[进度] {idx}/{len(usernames)}")
creator = self.fetch_creator_profile(username)
if creator:
results.append(creator)
time.sleep(2) # 避免触发平台限制
return results
测试运行
if **name** == "**main**":
scraper = TikTokCreatorScraper()
usernames = ["addisonre", "dixiedamelio", "zoelaverne"]
results = scraper.fetch_creators_batch(usernames)
print(f"\n成功采集 {len(results)} 个创作者的数据")
第三步:构建高价值 KOL 商业评分与智能筛选模型
数据本身没有价值,能指导决策的数据才有价值。当我们通过 API 批量获取了成百上千个博主的原始数据后,最重要的工作就是“提纯”。在国内,飞瓜等工具会直接给你一个系统评分,但在海外定制化场景下,我们完全可以通过 Python 构建一个切合自身业务逻辑的 kol screening tool python 模型。
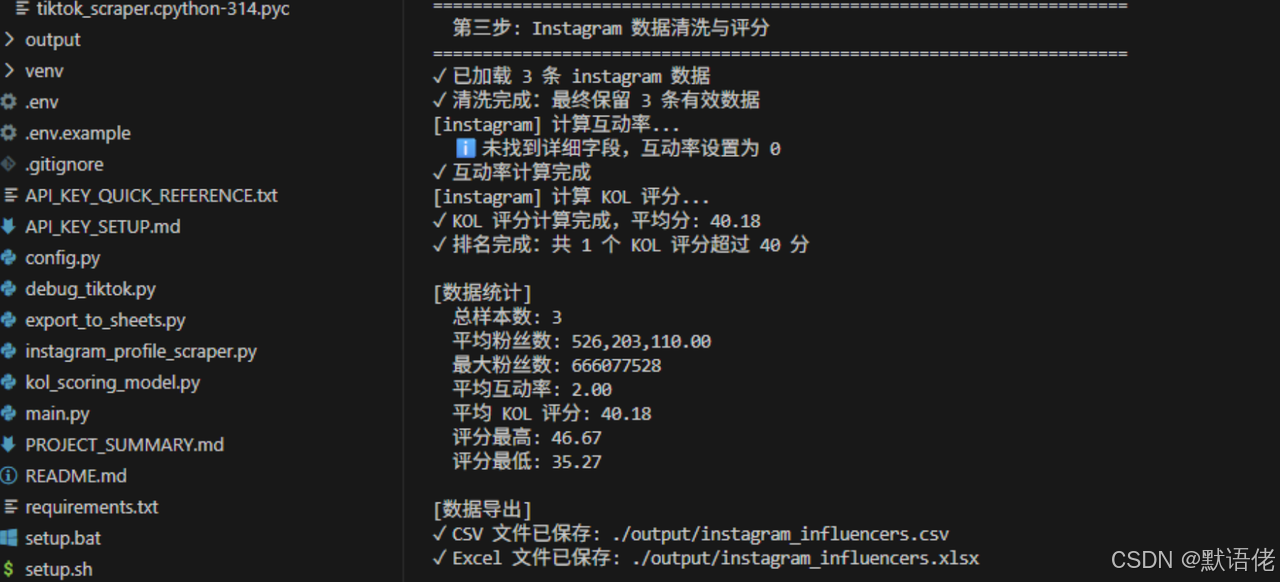
为了给大家一个示范,我设计了一个针对电商出海带货场景的加权评分公式(你可以根据自身品牌调性调整权重):
-
粉丝数(Followers):权重占比 25%。粉丝基数决定了博主的潜在触达范围,是商业价值的基础指标。
-
互动率(Engagement Rate):权重占比 35%。互动率是粉丝粘性和转化率的最底层基石,僵尸粉再多互动率也很低。
-
发布频率(Post Frequency):权重占比 15%。稳定的内容输出频率反映了博主的活跃度和专业度。
-
认证状态(Verification):权重占比 15%。平台认证账号通常意味着更高的可信度和商业价值。
-
领域相关性(Niche Relevance):权重占比 10%。通过分析博主内容与目标市场的匹配度,确保投放精准度。
[下方代码 kol_scoring_model.py 核心逻辑代码片段,展示如何用 Pandas 计算分数]
kol_scoring_model.py
"""
数据处理与 KOL 评分模块
清洗和去重采集数据
计算互动率、发布频率等关键指标
应用 KOL 商业价值评分权重模型
"""
import pandas as pd
import numpy as np
from typing import List, Dict, Optional
from datetime import datetime
from config import (
MIN_ENGAGEMENT_RATE,
MAX_ENGAGEMENT_RATE,
KOL_SCORING_WEIGHTS,
OUTPUT_DIR,
)
class KOLScoringModel:
"""数据处理与评分类"""
def **init**(self):
self.df = None
self.platform = None
def load_data(self, data_list: List[Dict], platform: str = "instagram") -> pd.DataFrame:
"""加载采集数据到 DataFrame"""
self.platform = platform.lower()
if not data_list:
print("⚠️ 数据列表为空")
return pd.DataFrame()
self.df = pd.DataFrame(data_list)
print(f"✓ 已加载 {len(self.df)} 条 {platform} 数据")
return self.df
def clean_data(self) -> pd.DataFrame:
"""数据清洗:去重、处理缺失值、类型转换"""
if self.df is None or self.df.empty:
return pd.DataFrame()
initial_count = len(self.df)
username_col = "username" if "username" in self.df.columns else "author_name"
if username_col in self.df.columns:
self.df = self.df.drop_duplicates(subset=[username_col])
print(f"✓ 去重完成:移除了 {initial_count - len(self.df)} 条重复记录")
self.df = self.df.fillna("N/A")
print(f"✓ 清洗完成:最终保留 {len(self.df)} 条有效数据")
return self.df
def calculate_engagement_rate(self) -> pd.DataFrame:
"""计算互动率(Engagement Rate)"""
if self.df is None or self.df.empty:
return self.df
print(f"[{self.platform}] 计算互动率...")
if self.platform == "instagram":
if all(col in self.df.columns for col in ["likes", "comments", "followers", "posts"]):
self.df["engagement_rate"] = (
(self.df["likes"].fillna(0) + self.df["comments"].fillna(0))
/ (self.df["followers"] + 1)
/ (self.df["posts"] + 1)
)
elif self.platform == "tiktok":
if all(col in self.df.columns for col in ["like_count", "follower_count", "video_count"]):
self.df["engagement_rate"] = (
self.df["like_count"].fillna(0)
/ (self.df["follower_count"] + 1)
/ (self.df["video_count"] + 1)
)
self.df["engagement_rate"] = self.df["engagement_rate"].clip(MIN_ENGAGEMENT_RATE, MAX_ENGAGEMENT_RATE)
self.df["engagement_rate_pct"] = self.df["engagement_rate"] * 100
print(f"✓ 互动率计算完成")
return self.df
def calculate_kol_score(self) -> pd.DataFrame:
"""
计算 KOL 商业价值评分
基于加权评分模型:
- 粉丝数 (25%)
- 互动率 (35%)
- 发布频率 (15%)
- 认证状态 (15%)
- 领域相关性 (10%)
"""
if self.df is None or self.df.empty:
return self.df
print(f"[{self.platform}] 计算 KOL 评分...")
scores = pd.DataFrame(index=self.df.index)
follower_col = "followers" if "followers" in self.df.columns else "follower_count"
if follower_col in self.df.columns:
max_followers = self.df[follower_col].max()
scores["followers_score"] = self.df[follower_col] / max_followers if max_followers > 0 else 0
if "engagement_rate" in self.df.columns:
scores["engagement_score"] = self.df["engagement_rate"] / MAX_ENGAGEMENT_RATE
posts_col = "posts" if "posts" in self.df.columns else "video_count"
if posts_col in self.df.columns:
max_posts = self.df[posts_col].max()
scores["frequency_score"] = self.df[posts_col] / max_posts if max_posts > 0 else 0
if "is_verified" in self.df.columns:
scores["verification_score"] = self.df["is_verified"].astype(bool).astype(int)
scores["niche_score"] = np.random.uniform(0.3, 1.0, len(self.df))
weights = KOL_SCORING_WEIGHTS
self.df["kol_score"] = (
scores["followers_score"] * weights["followers"] +
scores["engagement_score"] * weights["engagement_rate"] +
scores["frequency_score"] * weights["post_frequency"] +
scores["verification_score"] * weights["verification"] +
scores["niche_score"] * weights["niche_relevance"]
) * 100
self.df["kol_score"] = self.df["kol_score"].round(2)
print(f"✓ KOL 评分计算完成,平均分: {self.df['kol_score'].mean():.2f}")
return self.df
def rank_kols(self, min_score: float = 50) -> pd.DataFrame:
"""根据 KOL 评分排序,筛选出优质 KOL"""
if self.df is None or self.df.empty:
return self.df
self.df = self.df.sort_values("kol_score", ascending=False).reset_index(drop=True)
self.df["rank"] = range(1, len(self.df) + 1)
high_quality = self.df[self.df["kol_score"] >= min_score]
print(f"✓ 排名完成:共 {len(high_quality)} 个 KOL 评分超过 {min_score} 分")
return self.df
def export_to_excel(self, filename: Optional[str] = None) -> str:
"""导出数据到 Excel 文件"""
if self.df is None or self.df.empty:
return ""
if filename is None:
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
filename = f"{self.platform}_kol_data_{timestamp}.xlsx"
filepath = f"{OUTPUT_DIR}/{filename}"
try:
key_columns = ["rank", "username" if "username" in self.df.columns else "author_name",
"followers" if "followers" in self.df.columns else "follower_count",
"engagement_rate_pct", "kol_score"]
export_df = self.df[[col for col in key_columns if col in self.df.columns]]
with pd.ExcelWriter(filepath, engine="openpyxl") as writer:
export_df.to_excel(writer, sheet_name=self.platform.capitalize(), index=False)
print(f"✓ Excel 文件已保存: {filepath}")
return filepath
except Exception as e:
print(f"❌ 导出失败: {str(e)}")
return ""
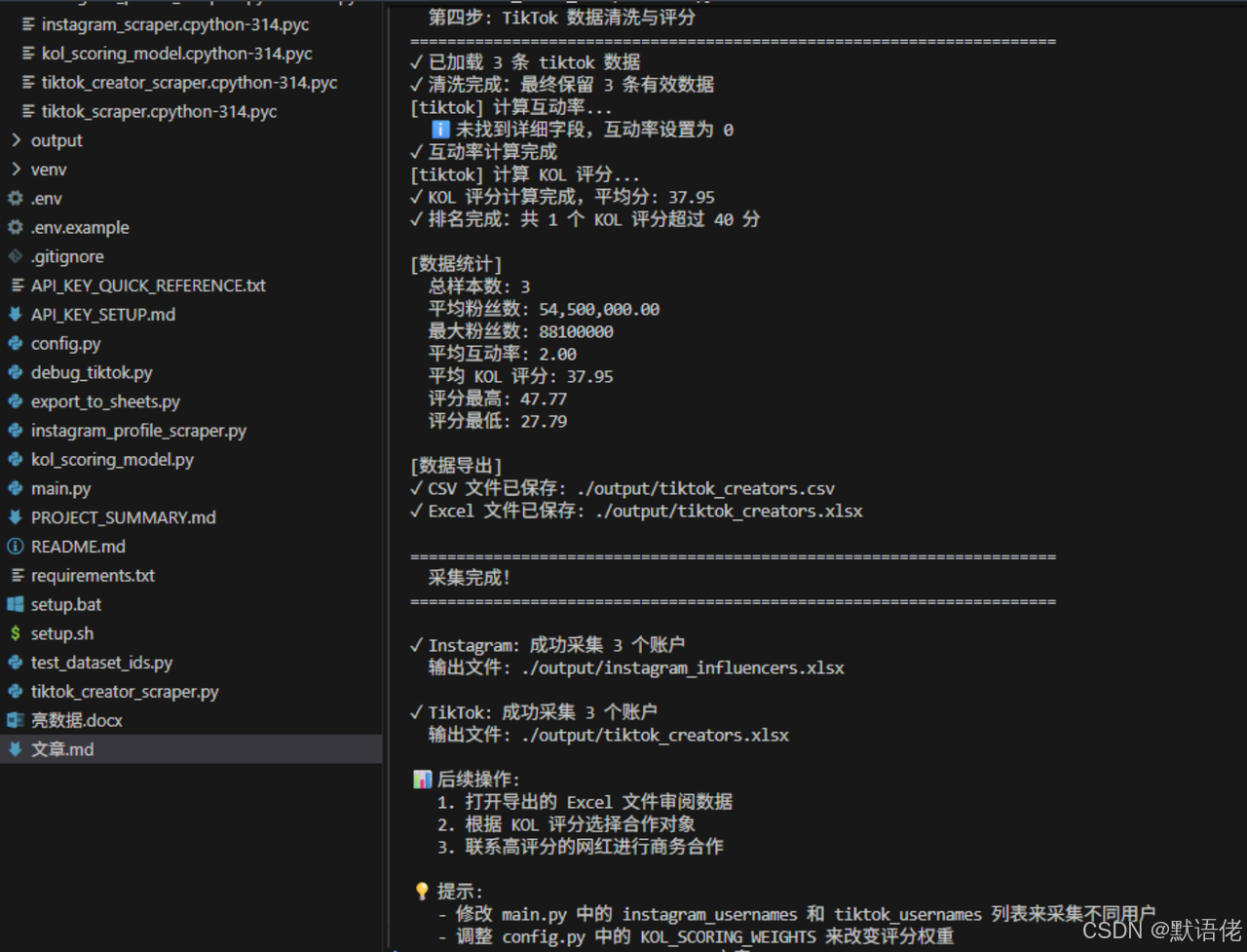
当模型计算完毕后,我们只需要运行最终的导出脚本 export_to_sheets.py,一份热腾腾的、完全按照商业价值降序排列的海外网红排列表就会自动生成,业务团队马上就能拿着名单去谈商务合作。
👇 KOL 智能评分与排名输出结果演示:

经过评分模型处理后自动生成的最终高价值网红筛选名单
五、 读者专属福利:获取全套源码与自动化交付物
为了让阅读本文的开发者和业务负责人能够做到真正的“开箱即用”,我已经将本文涉及的所有模块化代码、配置文件打包整理成了完整的 GitHub 仓库。
GitHub 仓库地址:https://github.com/yanweng/brightdata-social_media_scraper.git
👥 重点适用读者:
-
跨境电商数据工程师:需要同时监控 Amazon / eBay / Temu 等全平台动态的开发者。
-
营销与社媒分析团队:急需从 TikTok / LinkedIn 挖掘高潜红人与前沿趋势数据的分析师。
-
中高级 Python 开发者:熟悉 RESTful API,希望用现代化 AI Workflow 替代传统且容易崩溃的爬虫维护模式的技术极客。
-
技术 Leader / CTO:正在为公司评估企业级多平台数据采集底层基建方案的决策者。
📦 完整交付物清单包含:
-
instagram_profile_scraper.py(精准获取 IG 粉丝数、深度互动率、内容发布频率) -
tiktok_creator_scraper.py(实时获取 TK 视频播放量、账号涨粉速度、电商带货数据) -
kol_scoring_model.py(包含完整权重的自定义 KOL 智能评分计算模型) -
export_to_sheets.py(导出 Google Sheets / CSV 报告) -
main.py(主程序入口,一键运行完整采集与评估流程) -
config.py(集中管理 API 配置、评分权重、输出路径等参数) -
requirements.txt(Python 依赖包清单,一键安装) -
.env.example(安全配置环境变量范例文件) -
output/(自动生成的输出目录,存放 CSV/Excel 结果文件)
📁 完整项目结构:
social\_media\_scraper/
├── main\.py \# 主程序入口
├── config\.py \# 配置文件(API密钥、权重参数等)
├── instagram\_profile\_scraper\.py \# Instagram 数据采集模块
├── tiktok\_creator\_scraper\.py \# TikTok 数据采集模块
├── kol\_scoring\_model\.py \# 数据处理与 KOL 评分模块
├── export\_to\_sheets\.py \# 数据导出模块(CSV/Excel/Google Sheets)
├── requirements\.txt \# Python 依赖包清单
├── \.env \# 环境变量文件(需自行创建)
├── \.env\.example \# 环境变量模板
├── \.gitignore \# Git 忽略文件配置
└── output/ \# 输出目录(自动生成)
├── instagram\_influencers\.csv
├── instagram\_influencers\.xlsx
├── tiktok\_creators\.csv
└── tiktok\_creators\.xlsx
六、 成本与收益分析:自建技术方案的商业可行性
作为技术 Leader 或者公司的业务操盘手,在做技术方案选型时,最终都要回归到 ROI(投资回报率)。为什么我们推荐在特定场景下考虑基于 API 的自建平台?
但如果你采用本文介绍的基于 Bright Data Social Media Scraper API 的自建架构,在资源分配上将具备更强的自主性:
-
极致的按用量付费(Pay-as-you-go):你只需要为你成功抓取到的、状态码为 HTTP 200 的有效数据记录付费。该计费模式下,单条数据调用的分摊成本具备明显优势,整体支出远低于各类包月类 SaaS 服务的平均使用成本。
-
几乎为零的基础设施维护成本:传统的自建爬虫,最头疼的就是买节点、养服务器、对抗各种反爬策略。而使用 Bright Data,你完全不需要购买和维护庞大的代理IP池。它底层庞大的全球真实住宅 IP 网络和 AI 驱动的自动指纹轮换技术,帮我们这群开发者彻底搞定了 99% 的网络层脏活累活。
相较于出海投放时动辄几千上万美金的 KOL 坑位费,如果在投放前能利用极低的 API 调用成本,通过我们自己的代码跑通一遍数据模型,提前筛掉哪怕一个“注水假号”或者“低质数据账号”,这套系统就能瞬间为你挽回几十倍甚至上百倍的开发成本。在出海营销的链路中,这绝对是最值得投入的一环。
七、 总结
在这个 “数据就是弹药” 的存量博弈时代,出海品牌要想在 Instagram 和 TikTok 这些错综复杂、算法黑盒的全球流量池里成功淘金,绝不能再依赖传统的盲人摸象式跟风投放。 借助 Python 搭配 Bright Data 这类具备企业级服务标准的数据采集底座,对于有高度定制化需求的数据团队而言,自主搭建数据流程能够实现更灵活的数据管控,可搭建高度定制化、私有化的海外网红业务数据情报管道,这也是构筑竞争壁垒、拉开与同行差距的核心技术优势。
趁着现在各大海外社媒平台的数据红利期仍在,赶紧行动起来,搭建并完善属于你自己的全自动 KOL 商业情报库吧!
🚀 立即点击专属链接,免费体验 Bright Data 强大的 Web Scraper API,构建你的出海数据护城河!

欢迎加入北京社区
更多推荐


 5
5 0
0- 0



 已为社区贡献202条内容
已为社区贡献202条内容

所有评论(0)