
DeepSeek-V3.2-Exp:通过稀疏注意力机制提升长上下文效率
2025 年国庆前夕,DeepSeek 再次“无预警放大招”,发布了全新通用模型该版本基于持续训练而成,核心创新在于引入了,显著提升了模型在长上下文任务中的训练与推理效率。
《DeepSeek-V3.2-Exp:通过稀疏注意力机制提升长上下文效率》
2025 年国庆前夕,DeepSeek 再次“无预警放大招”,发布了全新通用模型 DeepSeek-V3.2-Exp(Experimental)。该版本基于 DeepSeek-V3.1-Terminus 持续训练而成,核心创新在于引入了 DeepSeek 稀疏注意力机制(DeepSeek Sparse Attention,简称 DSA),显著提升了模型在长上下文任务中的训练与推理效率。
一、架构:从 Terminus 到 DSA
与前一版本 DeepSeek-V3.1-Terminus 相比,DeepSeek-V3.2-Exp 在架构上的唯一改动是通过持续训练引入了 DSA 机制。
🧩 DSA 的核心原理
DSA 由两部分组成:
- 闪电索引器(Lightning Indexer):计算每个查询 token 与历史 token 的索引分数,用于确定应关注的上下文范围。
- 细粒度 Token 选择机制:在所有索引分数中筛选出前 k 个键值对,并在这些稀疏候选上执行标准注意力计算,从而显著减少计算量。
由于索引器采用较少的头部数(head)并以 FP8 实现,其计算效率极高。
⚙️ 基于 MLA 的 DSA 实例化
为了实现架构兼容,DSA 基于 MLA(Multi-Head Latent Attention)机制实例化。
在 MLA 的多查询注意力(MQA)模式下,每个键值对可被同一查询下的所有头共享,从而进一步提升效率。
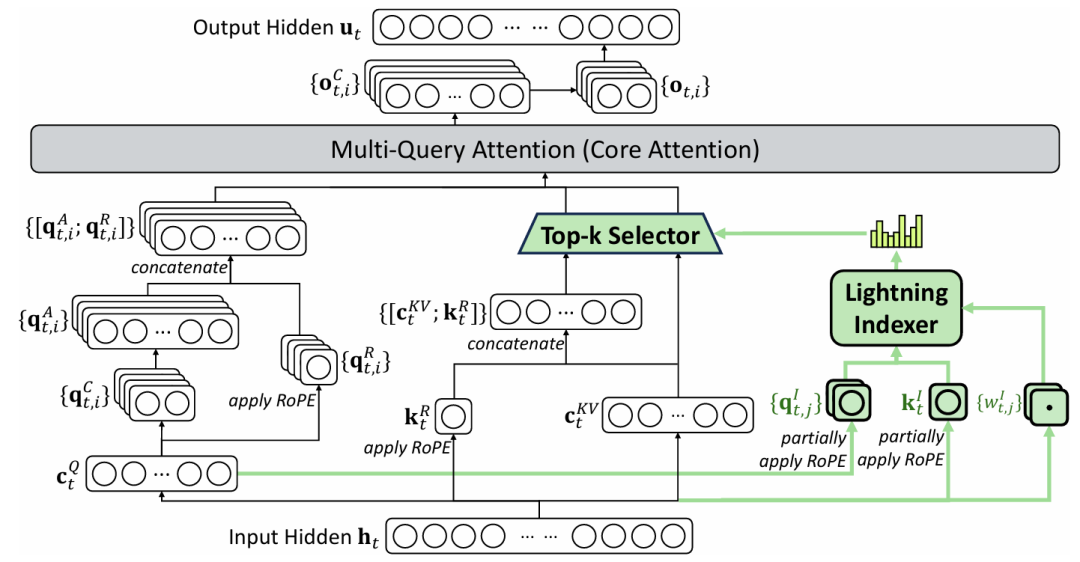
图1 | DeepSeek-V3.2-Exp 的注意力架构(绿色部分展示 DSA 选择 top-k 键值对的过程)
二、训练:从持续预训练到混合强化学习
DeepSeek-V3.2-Exp 从 V3.1-Terminus 的 128K 上下文基座出发,通过**持续预训练(Continued Pre-training)和后训练(Post-training)**两阶段构建完成。
1️⃣ 持续预训练
分为两个阶段:
(1)密集注意力预热阶段
- 初始化闪电索引器,冻结其他参数。
- 目标是让索引器输出分布与主注意力模块保持一致。
- 训练 1000 步,总计 2.1B token。
(2)稀疏训练阶段
- 引入稀疏选择机制,联合优化全部参数。
- 每个查询 token 选择 2K 个键值 token。
- 训练 15000 步,总量约 943.7B token。
2️⃣ 后训练
后训练阶段延续了 DeepSeek-V3.1 的全部流程与数据,以验证 DSA 的实际收益。
(1)专家蒸馏(Specialist Distillation)
针对五大领域(数学、编程、逻辑推理、智能体编程、智能体搜索)分别微调专家模型,并利用其生成高质量蒸馏数据。最终的通用模型在性能上与专家模型相近。
(2)混合强化学习训练(Mixed RL Training)
采用 组相对策略优化(GRPO) 算法,将推理、智能体与人类对齐训练整合于单阶段,避免灾难性遗忘。
奖励机制兼顾:
- 推理类任务:结果、长度、语言一致性奖励;
- 通用任务:基于生成式奖励模型的精细评估。
三、评估:性能与效率并进
🌟 模型能力
与 DeepSeek-V3.1-Terminus 对比(见表1),V3.2-Exp 在长上下文任务中显著提高计算效率,同时在短任务中保持性能稳定。性能差异主要源于推理 token 数量的不同。
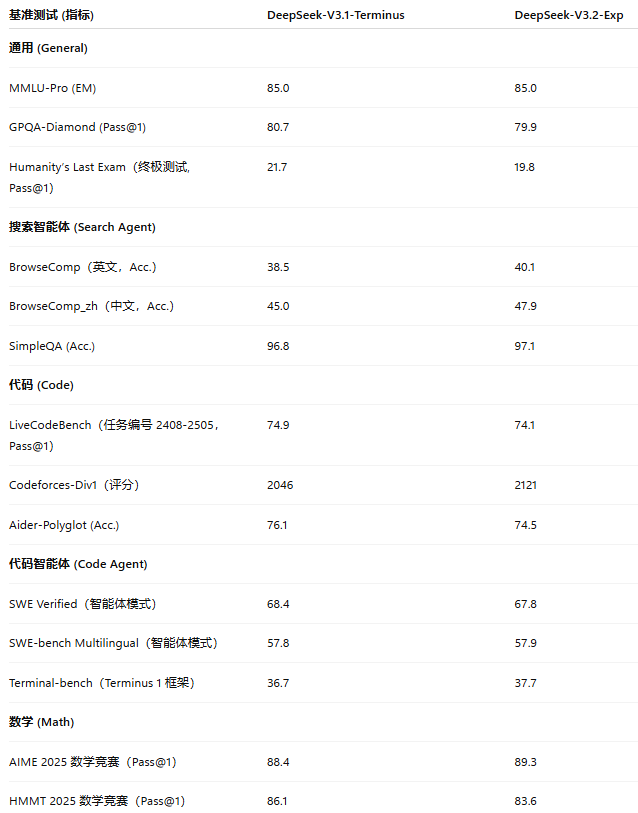
表1 | DeepSeek-V3.1-Terminus 与 V3.2-Exp 的评估结果
图2展示的 RL 训练曲线表明,两个模型在 BrowseComp 与 SWEVerified 任务上性能相近,验证了 DSA 的稳定性。
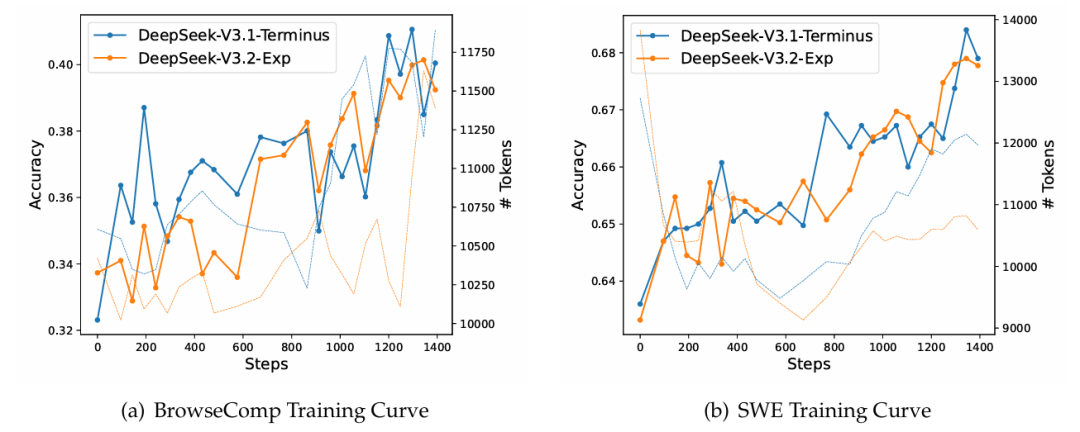
图2 | RL 训练曲线:准确率与生成 token 数量变化趋势
⚡ 推理成本
DSA 将注意力计算复杂度从 (O(n^2)) 降至 (O(nk)),其中 (k \ll n)。
虽然闪电索引器保持 (O(n^2)) 复杂度,但其计算量极小。综合优化后,在长上下文下实现端到端加速。
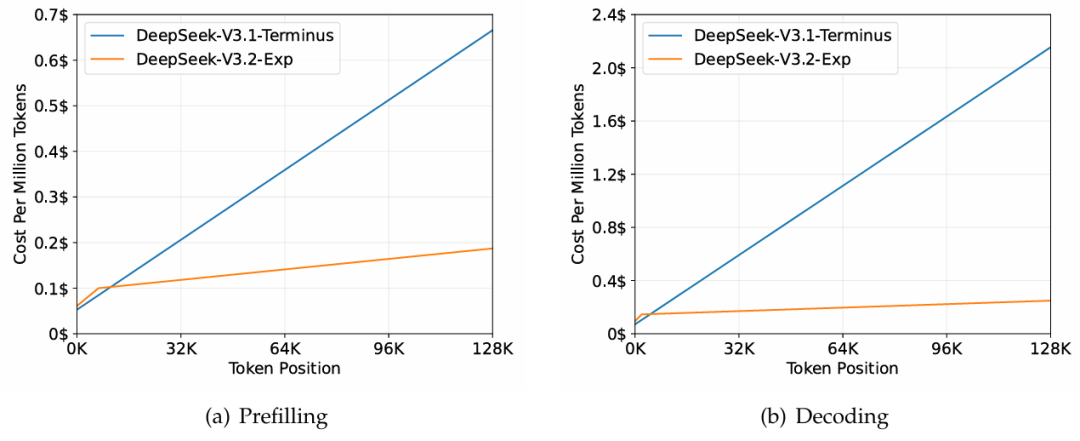
图3 | 在 H800 集群上的推理成本对比
此外,团队在短序列预填充(prefilling)场景中引入带掩码的 MHA 模式,进一步优化短上下文计算性能。
四、未来展望
团队将持续推动 DSA 架构在真实世界长文本推理与智能体任务中的应用测试,
以进一步揭示稀疏注意力在复杂语境下的潜在优势与边界。
附录A:MLA 的 MHA 与 MQA 模式
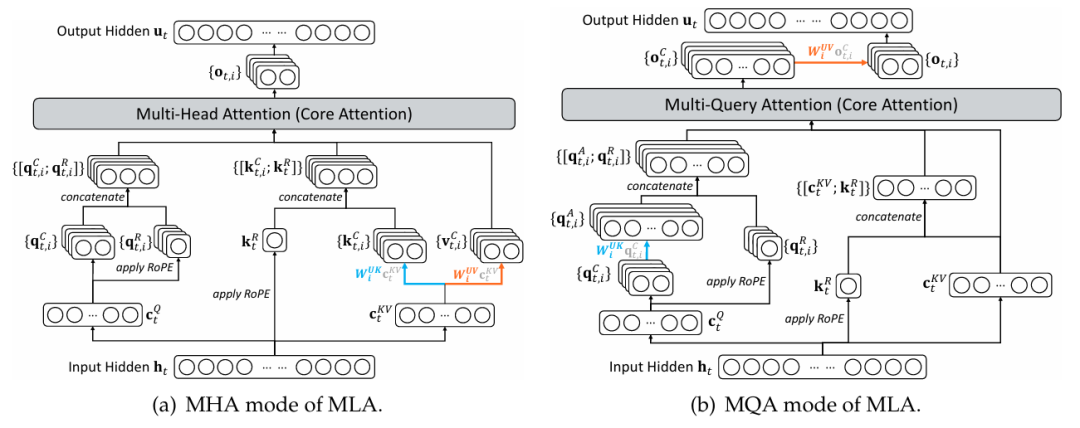
图4 | MLA 的 MHA 与 MQA 模式示意
在 DeepSeek-V3.1-Terminus 中,训练与预填充阶段使用 MHA 模式,而解码阶段切换为 MQA 模式。该图直观展示了两种模式的结构与转换关系。

欢迎加入北京社区
更多推荐



 10
10 0
0- 0



 已为社区贡献118条内容
已为社区贡献118条内容

所有评论(0)