
Python图的存储与遍历全解:三种存储方式 +BFS/DFS
·
图是计算机中非常重要的非线性数据结构,由节点(顶点)和边组成,广泛应用于社交网络、路径规划、推荐系统等场景。在Python中实现图算法,第一步就是解决图的存储问题,第二步是掌握图的遍历核心算法。
本文结合实战代码,详细讲解图的三种主流存储方式(邻接矩阵、邻接表、边集数组),以及最常用的深度优先遍历(DFS)、广度优先遍历(BFS),新手也能轻松上手。
本文默认讲解无向带权图(边没有方向,边有权重),代码可无缝适配有向图/无权图。
一、前置知识
我们先统一符号定义,方便理解代码:
n:图的节点总数(节点编号默认从0开始)m:图的边总数u, v:边的两个端点w:边的权重(无权图可省略)inf:无穷大,代表两个节点不直接相连
二、Python 中图的三种存储方式
图的存储没有绝对最优解,根据图的稀疏程度选择存储方式是核心原则。
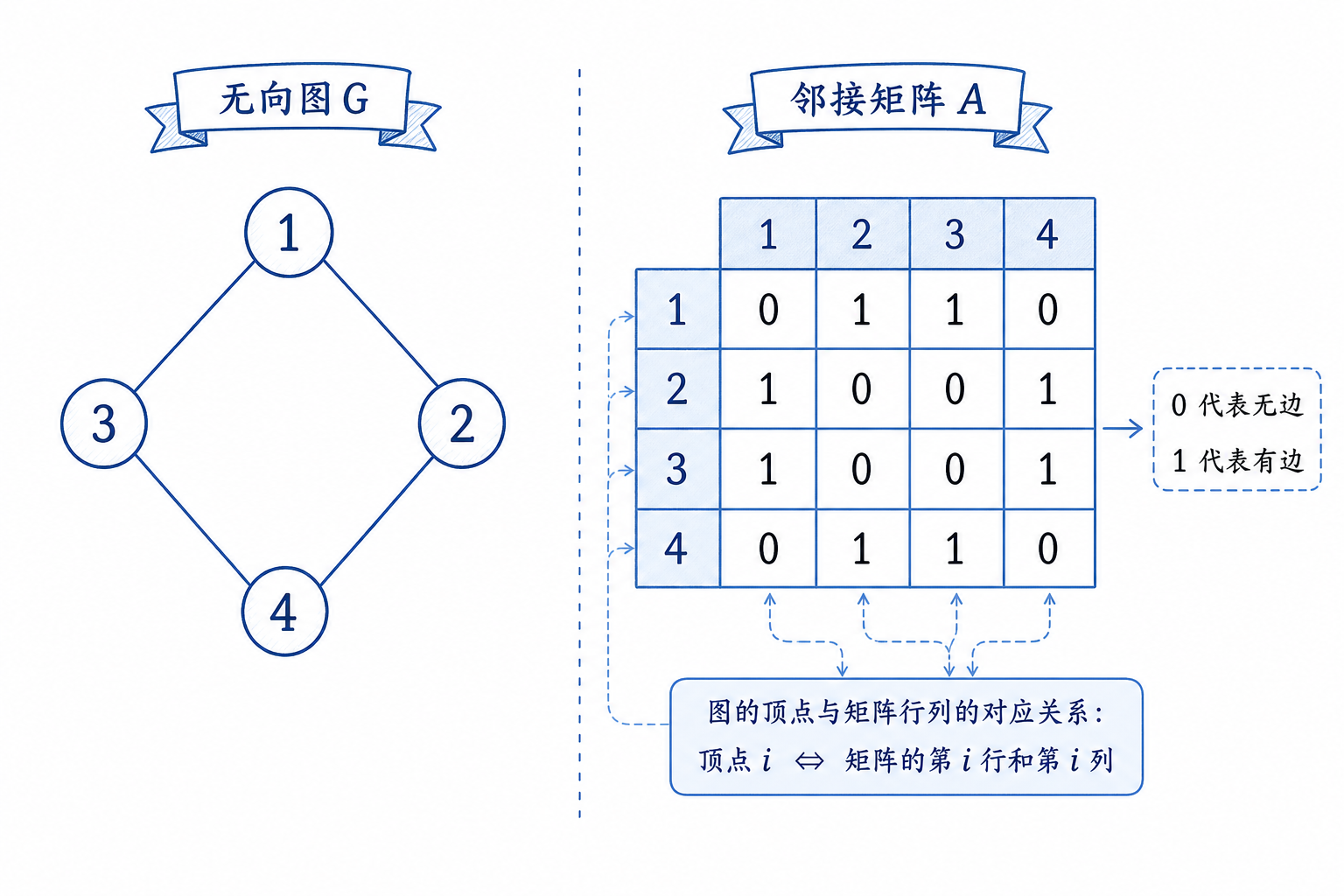
1. 邻接矩阵
邻接矩阵是最直观的存储方式,用二维列表表示图:
- 行和列对应图的节点
- 矩阵中
e[u][v]的值:表示节点u到v的边权重,无连接则为无穷大inf
代码实现
# 定义无穷大(必须提前定义!)
inf = float('inf')
# 输入:节点数n,边数m
n, m = map(int, input().split())
# 初始化n*n的邻接矩阵,默认值为inf(不连通)
e = [[inf] * n for _ in range(n)]
# 输入m条边,填充矩阵
for _ in range(m):
u, v, w = map(int, input().split())
e[u][v] = w # 有向图只写这一行
e[v][u] = w # 无向图:边双向连通
e[u][u] = 0 # 自己到自己的权重为0
e[v][v] = 0
# 测试:打印邻接矩阵
for row in e:
print(row)
优缺点
- ✅ 优点:查询两点是否连通O(1) 时间复杂度,简单直观
- ❌ 缺点:空间复杂度高(
O(n²)),稀疏图会造成大量空间浪费 - 🎯 适用场景:稠密图(边数接近
n²)
2. 邻接表
邻接表是工程中最常用的存储方式,用一维列表存储:
- 列表下标对应节点编号
- 每个下标存储一个子列表,存放相邻节点+边权重
python用list实现,与下图链表有点不一致,思想是一致的。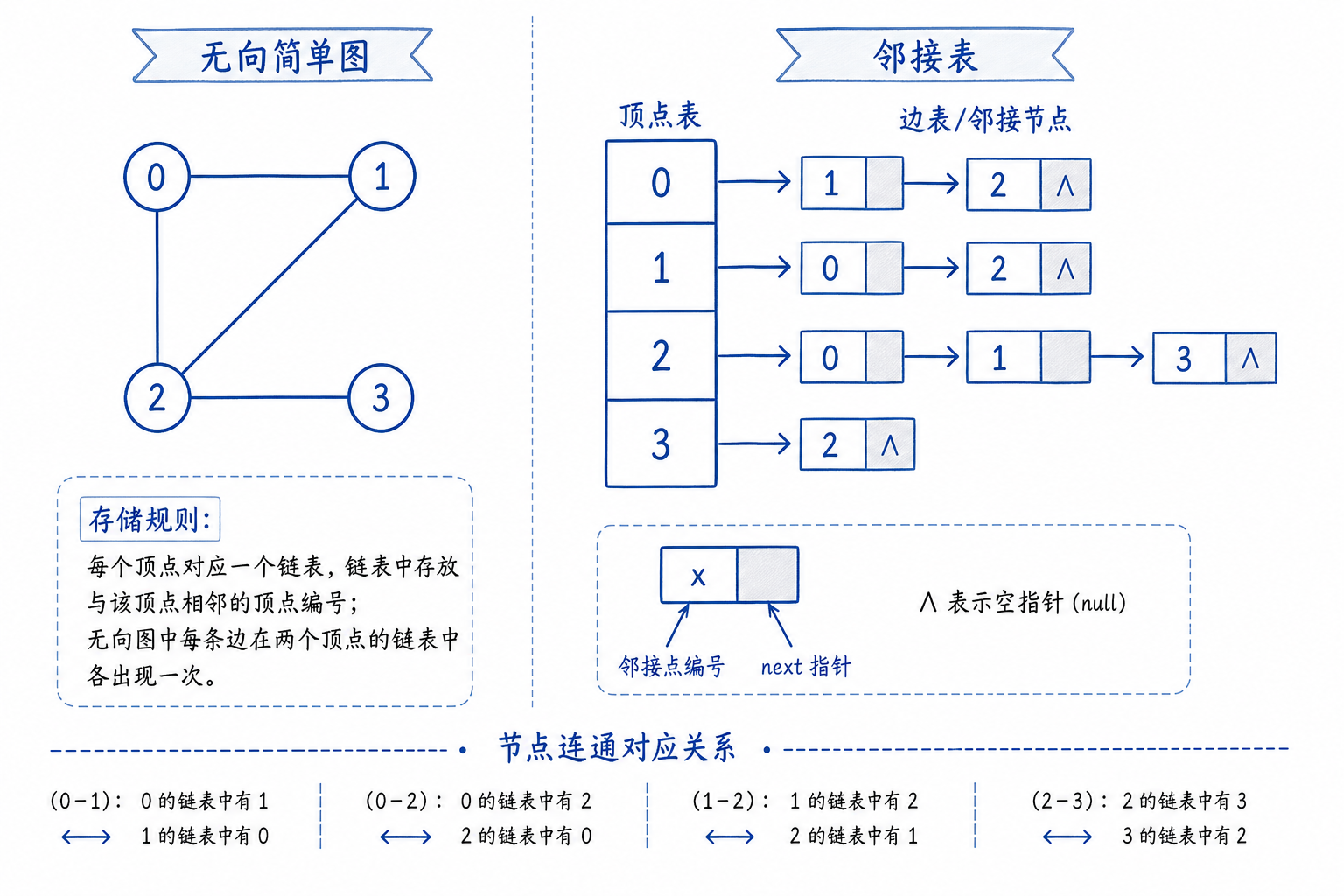
代码实现
# 输入:节点数n,边数m
n, m = map(int, input().split())
# 初始化n个空列表,对应n个节点的邻接表
e = [[] for _ in range(n)]
# 输入m条边,填充邻接表
for _ in range(m):
u, v, w = map(int, input().split())
e[u].append((v, w)) # 无向图:双向添加边
e[v].append((u, w))
# 测试:打印邻接表
for i in range(n):
print(f"节点{i}的邻接节点:{e[i]}")
优缺点
- ✅ 优点:空间利用率极高(
O(n+m)),适合绝大多数场景 - ❌ 缺点:查询两点是否连通需要遍历节点的邻接边
- 🎯 适用场景:稀疏图(日常开发90%的场景)
- 🌟 关键:本文的遍历算法基于邻接表实现
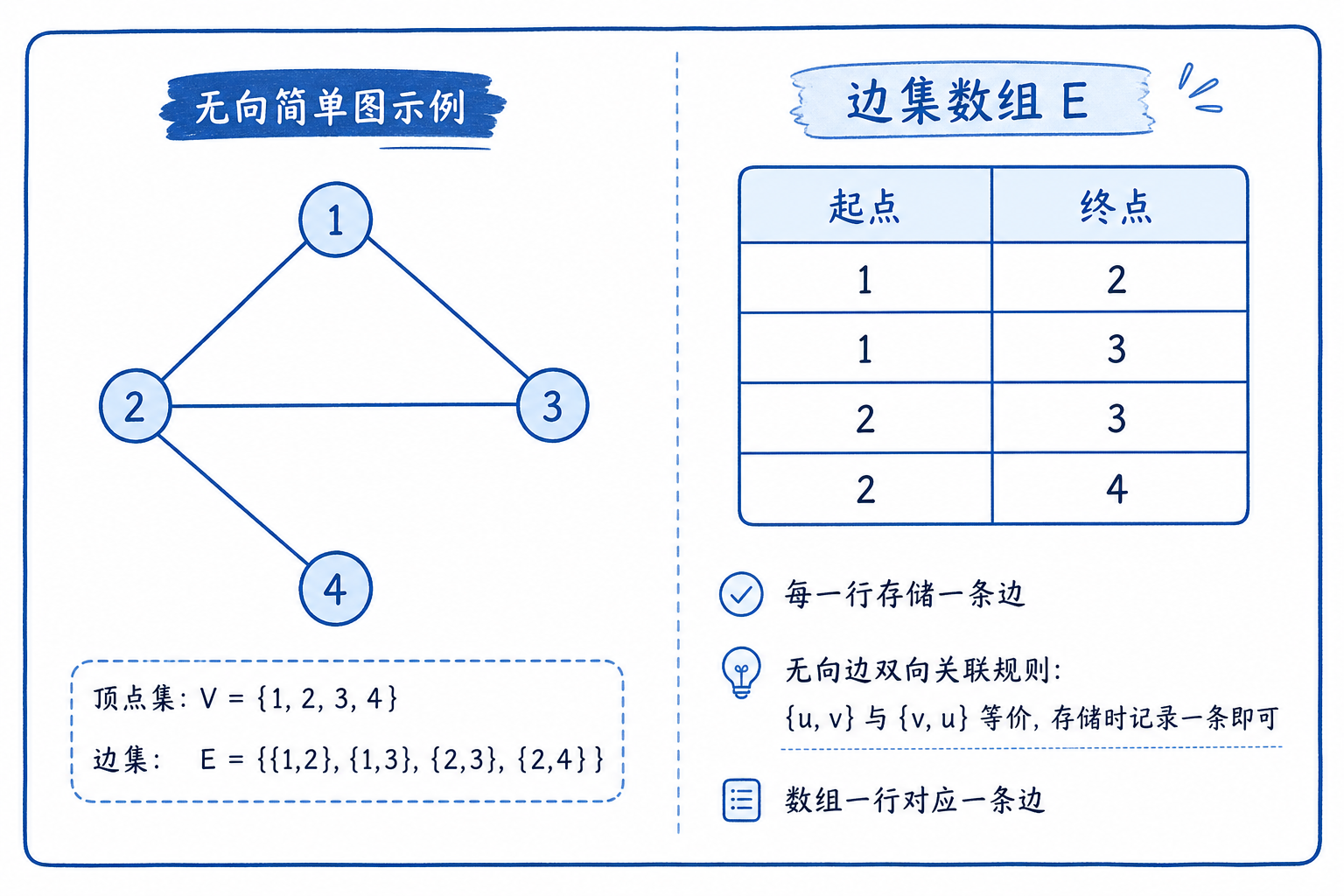
3. 边集数组
边集数组是最简单的存储方式,直接用一维列表存储所有边的信息,不关心节点关系。
代码实现
# 输入:节点数n,边数m
n, m = map(int, input().split())
# 初始化空列表,存储所有边
e = []
# 输入m条边,直接追加到列表
for _ in range(m):
u, v, w = map(int, input().split())
e.append((u, v, w))
# 直接输出所有边
print("边集数组:", e)
优缺点
- ✅ 优点:代码极简,适合存储所有边
- ❌ 缺点:查询两点连通性效率极低(
O(m)) - 🎯 适用场景:仅用于需要遍历所有边的算法(如最小生成树)
- ❌ 不适合:图的遍历
三、深度优先搜索(DFS)
图的遍历是指依次访问图中所有节点,且每个节点仅访问一次。
深度优先搜索(DFS)是最经典的遍历方式,核心思想:一路走到底,走不通再回溯。
代码解析(基于邻接表)
你提供的DFS代码是递归实现,简洁易懂:
# 定义集合:记录已访问的节点(避免重复访问)
s = set()
def dfs(u):
"""
DFS遍历函数
:param u: 当前遍历的起始节点
"""
# 1. 访问当前节点:打印输出
print(u, end=' ')
# 2. 标记当前节点为已访问
s.add(u)
# 3. 遍历当前节点的所有邻接节点
for v, _ in e[u]:
# 4. 如果邻接节点未被访问,递归遍历
if v not in s:
dfs(v)
完整可运行代码
整合邻接表+DFS,直接复制运行:
# 完整示例:邻接表存储 + DFS遍历
n, m = map(int, input().split())
e = [[] for _ in range(n)]
for _ in range(m):
u, v, w = map(int, input().split())
e[u].append((v, w))
e[v].append((u, w))
# DFS遍历
s = set()
def dfs(u):
print(u, end=' ')
s.add(u)
for v, _ in e[u]:
if v not in s:
dfs(v)
# 从节点0开始遍历
dfs(0)
测试用例
输入:
5 5
0 1 1
0 2 1
1 3 1
1 4 1
2 4 1
输出:
0 1 3 4 2
四、广度优先搜索(BFS)
除了DFS,**广度优先搜索(BFS)**也是常用遍历方式,核心思想:一层一层遍历(类似树的层序遍历),用队列实现:
from collections import deque
def bfs(start):
q = deque()
q.append(start)
s.add(start)
while q:
u = q.popleft()
print(u, end=' ')
for v, _ in e[u]:
if v not in s:
s.add(v)
q.append(v)
# 调用
s = set()
bfs(0)
五、总结
- 存储方式选择
- 稠密图 → 邻接矩阵
- 稀疏图/日常开发 → 邻接表(首选)
- 仅需存储边 → 边集数组
- 遍历算法
- DFS:递归实现,适合深度探索、路径查找
- BFS:队列实现,适合最短路径、层序遍历
掌握这三种存储方式和两种遍历算法,你就可以轻松入门图的所有基础算法(最短路径、最小生成树等)啦!
更多推荐

 17
17 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)