
工业 IoT 时序数据治理:DolphinDB 高频写入、降采样与查询优化的工程实践
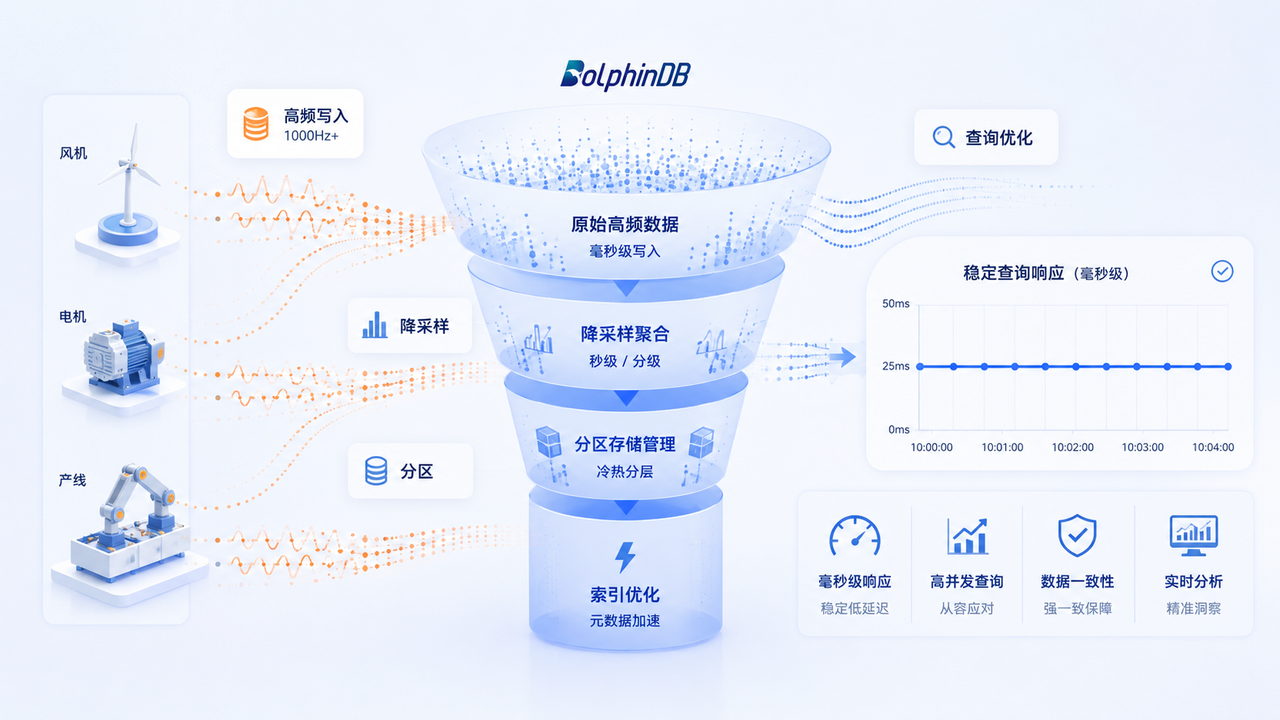
摘要
工业物联网开发久了,会发现一个反直觉的现象: 传感器越装越多、采集频率越提越高,但数据真正能用起来的比例反而越来越低。原始数据堆成山,查询越来越慢,磁盘越扩越大,可业务侧要一个"昨天某台设备每分钟的振动趋势",还是要等上十几秒甚至超时。
这背后不是数据库选得不够"先进",而是 数据治理 没跟上——分区怎么切、高频数据怎么降采样、过期数据怎么清、查询怎么不退化,这些"脏活累活"才是决定一个 IoT 数据平台能不能长期跑下去的关键。
这篇就围绕 DolphinDB,把这些容易被忽略的工程细节摊开聊一聊:从高频写入落盘、复合分区设计、多层级降采样,到 TTL 与查询优化。代码为主,少谈概念。
一、问题背景:数据"采得起",却"治不动"
先说清楚为什么要专门谈"治理"。
一个典型的工业 IoT 场景:一条产线上几百台设备,每台挂几十个测点(振动、温度、电流、转速),高频测点按 10kHz 采样,低频测点按 1Hz 采样。粗算下来,单条产线一天就能产生几亿到几十亿行数据。
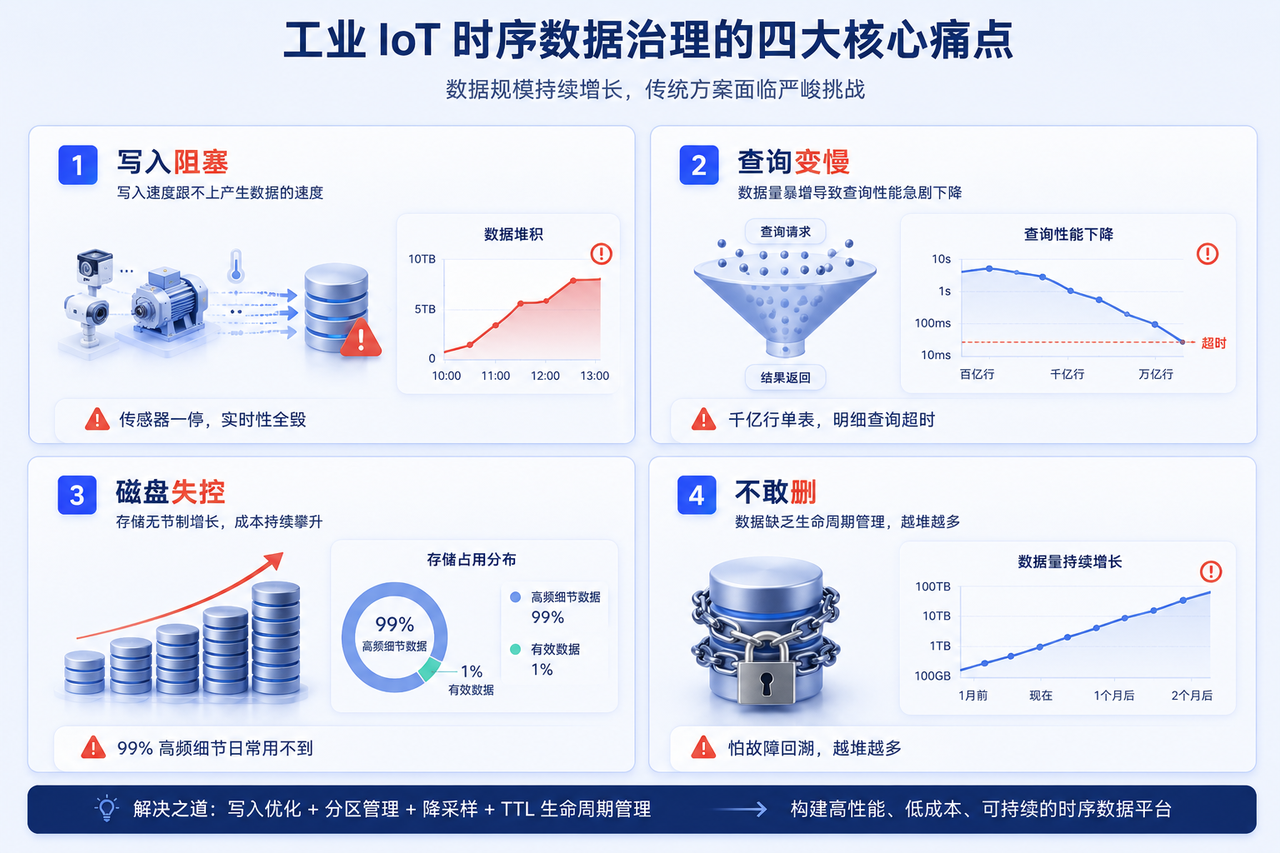
这种规模下,几个工程问题会陆续冒出来:
-
写入不能阻塞:传感器数据是持续涌进来的,落盘慢一拍,缓冲队列就堆积,实时性全毁。
-
原始数据查询越来越慢:一年下来单表上千亿行,哪怕只查一台设备一天的明细,也可能扫出一堆无关分区。
-
磁盘成本失控:高频原始数据 99% 的细节在日常监控里根本用不到,但它们占了绝大部分存储。
-
历史数据不敢删:又怕哪天要做故障回溯,结果就是越堆越多。
下面这几节,就是针对这四个问题的工程化解法。它们之间是有关联的:写入设计决定分区,分区决定查询性能,降采样决定存储成本,TTL 决定生命周期。
二、写入侧:让高频数据稳定落盘
2.1 流表订阅:传感器数据的实时入口
工业现场的传感器数据通常先经过 MQTT/OPC UA 网关,再推到数据库。DolphinDB 的做法是用流数据表(streamTable)做实时入口,再通过订阅把数据落到分布式表里:
// 1. 建分布式表(分区设计见下一节)
db1 = database("", VALUE, 2024.01.01..2025.12.31)
db2 = database("", HASH, [SYMBOL, 20])
db = database("dfs://iot", COMPO, [db1, db2])
schema = table(1:0, `ts`deviceId`vibration`temperature`current`rpm,
[TIMESTAMP, SYMBOL, DOUBLE, DOUBLE, DOUBLE, DOUBLE])
db.createPartitionedTable(schema, "sensor", `ts`deviceId)
// 2. 建流表作为实时入口
share streamTable(1:0, `ts`deviceId`vibration`temperature`current`rpm,
[TIMESTAMP, SYMBOL, DOUBLE, DOUBLE, DOUBLE, DOUBLE]) as sensorStream
// 3. 订阅流表,实时写入分布式表
subscribeTable(
tableName="sensorStream",
actionName="persist",
handler=tableInsert{loadTable("dfs://iot", "sensor")},
msgAsTable=true,
offset=0,
reconnect=true
)这里有几个工程上值得注意的点:
-
msgAsTable=true让订阅按批次(以表为单位)写入,而不是逐条写入。批量写入对 LSM-Tree 类存储引擎的吞吐至关重要,逐条写会让写放大和 Compaction 压力剧增。 -
reconnect=true在订阅端异常断开时自动重连。工业现场网络抖动是常态,这个参数能避免数据缺口。 -
流表本身是无持久化的内存表(除非配置
enableTableShareAndPersistence),它的职责是"接得住高频涌入",真正的持久化交给下游订阅。
实测中,单节点承载每秒数十万到上百万点的写入是没问题的,关键是别让写入和查询互相拖累——这正是下一节分区设计要解决的。
2.2 列存与压缩:用更少的磁盘装更多数据
DolphinDB 的 TSDB 引擎是行列混存(PAX)+ 列式压缩。工业时序数据有个特点:时间连续、数值渐变。比如温度传感器一秒前的值和现在的值通常只差零点几度。针对这种特征,DolphinDB 会自动选择 Delta-of-Delta、CHIMP、ZSTD 等压缩算法,实测压缩比能到 10:1 ~ 20:1。
这意味着什么?100GB 的原始数据,落到磁盘可能只有 5~10GB。对一个要长期累积海量历史数据的 IoT 平台来说,这个压缩比直接决定了你的存储成本是"能接受"还是"吓人"。
工程上的一个建议:尽量让相同设备、相同测点的数据在物理上连续存放(这也是为什么下面要用设备 HASH 分区 + 排序),这样列式压缩的命中率最高。如果数据是乱序混在一起的,压缩比会明显下降。
三、分区设计:决定查询性能的"地基"
这一节是全文最关键的部分。DolphinDB 的查询性能,七成取决于分区设计得对不对。
3.1 复合分区:日期 VALUE + 设备 HASH
工业 IoT 数据最常用的分区方案是两级复合分区(COMPO):
db1 = database("", VALUE, 2024.01.01..2025.12.31) // 一级:按日期 VALUE
db2 = database("", HASH, [SYMBOL, 20]) // 二级:按设备ID HASH
db = database("dfs://iot", COMPO, [db1, db2])为什么这么设计:
-
日期用 VALUE 分区:一天一个分区。绝大多数工业查询都带时间范围("昨天""上周""最近一小时"),VALUE 分区能让查询引擎精确裁剪到目标日期分区,不碰其他天的数据。同时,按天分区也让 TTL(过期清理)变得简单——直接删分区就行,见第四节。
-
设备用 HASH 分区:把设备 ID 均匀打散到 20 个子分区。这一层的价值是并行——当你按
deviceId查询或做group by deviceId时,不同设备的数据分布在不同的节点/分片上,可以并行计算。
如果只用日期分区、不做设备维度分区,会出现什么问题?我对比测过:同样 3000 万条数据、按 group by deviceId 提取特征,单维度日期分区耗时约 2.3 秒,加上设备 HASH 分区后降到 1.5 秒左右。差距会随数据量增长进一步拉大。
3.2 分区裁剪:带上时间条件才不白扫
分区建好了,不代表查询就一定快。触发分区裁剪的前提是查询条件能命中分区键。这是个特别容易踩的坑:
-- ✅ 好:条件直接落在日期分区键上,只扫描 6/1~6/7 七个分区
select avg(vibration) from loadTable("dfs://iot","sensor")
where date(ts) between 2024.06.01 and 2024.06.07
group by deviceId
-- ❌ 差:不带时间条件,全表扫描所有日期分区
select avg(vibration) from loadTable("dfs://iot","sensor")
group by deviceId同样,如果带了 deviceId = "DEV_003" 的条件,也能在 HASH 分区上做裁剪,只扫该设备所在的那一个子分区。
工程实践上,业务侧的所有查询都强制带时间范围,这应该作为一个开发规约定下来。否则再好的分区设计也救不了全表扫描。
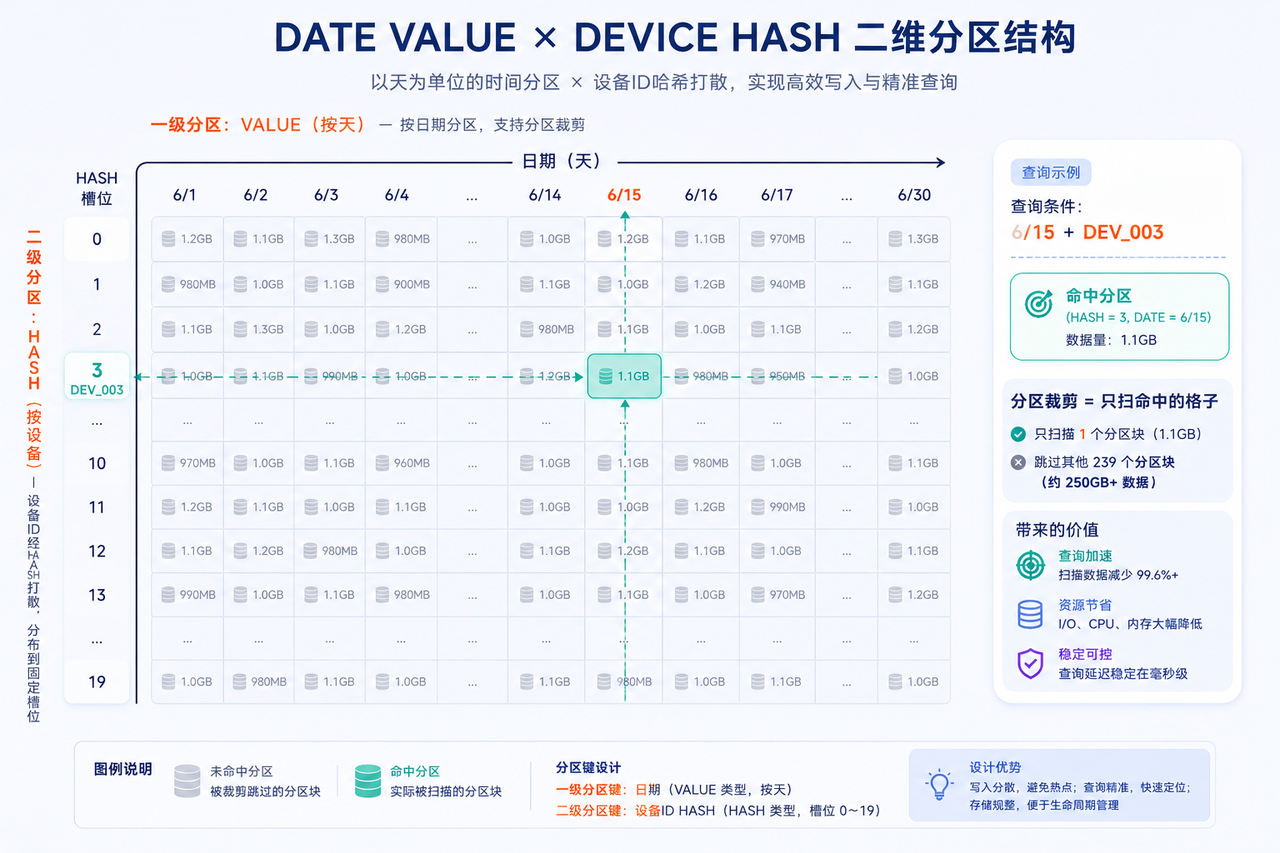
3.3 分区粒度的权衡
分区不是越细越好,也不是越粗越好:
-
太细(比如按小时分区):分区数量爆炸,元数据膨胀,小查询反而因为调度开销变慢。
-
太粗(比如按月分区):单分区数据量过大,查询时即使裁剪到一个分区,也要扫太多数据。
工业 IoT 场景的经验值是按天分区比较稳妥。如果数据量特别大(单日几十亿行),可以考虑按天 + 设备 HASH 的二级分区把单分区数据量压下来。一个可参考的目标是:单分区数据量控制在 1~10GB 之间,这个区间内查询和写入都比较舒服。
四、降采样:高频原始数据的"瘦身"
这是工业 IoT 数据治理里价值最高、却最容易被忽视的一环。
4.1 为什么需要降采样
10kHz 的振动原始数据,对实时故障预警和频谱分析是必要的,但对"看趋势""做日报""算健康分"这类需求来说,秒级甚至分钟级的聚合值就完全够用了。
如果把所有分析都跑在原始高频数据上,会有两个后果:一是查询慢,二是存储成本被高频数据吃掉绝大部分。合理的做法是分层存储:
|
层级 |
粒度 |
保留时长 |
用途 |
|
原始层 |
10kHz / 1Hz |
7~30 天 |
故障回溯、频谱分析 |
|
分钟层 |
1 分钟聚合 |
1~3 个月 |
趋势监控、日报 |
|
小时层 |
1 小时聚合 |
1~2 年 |
长期统计、对比分析 |
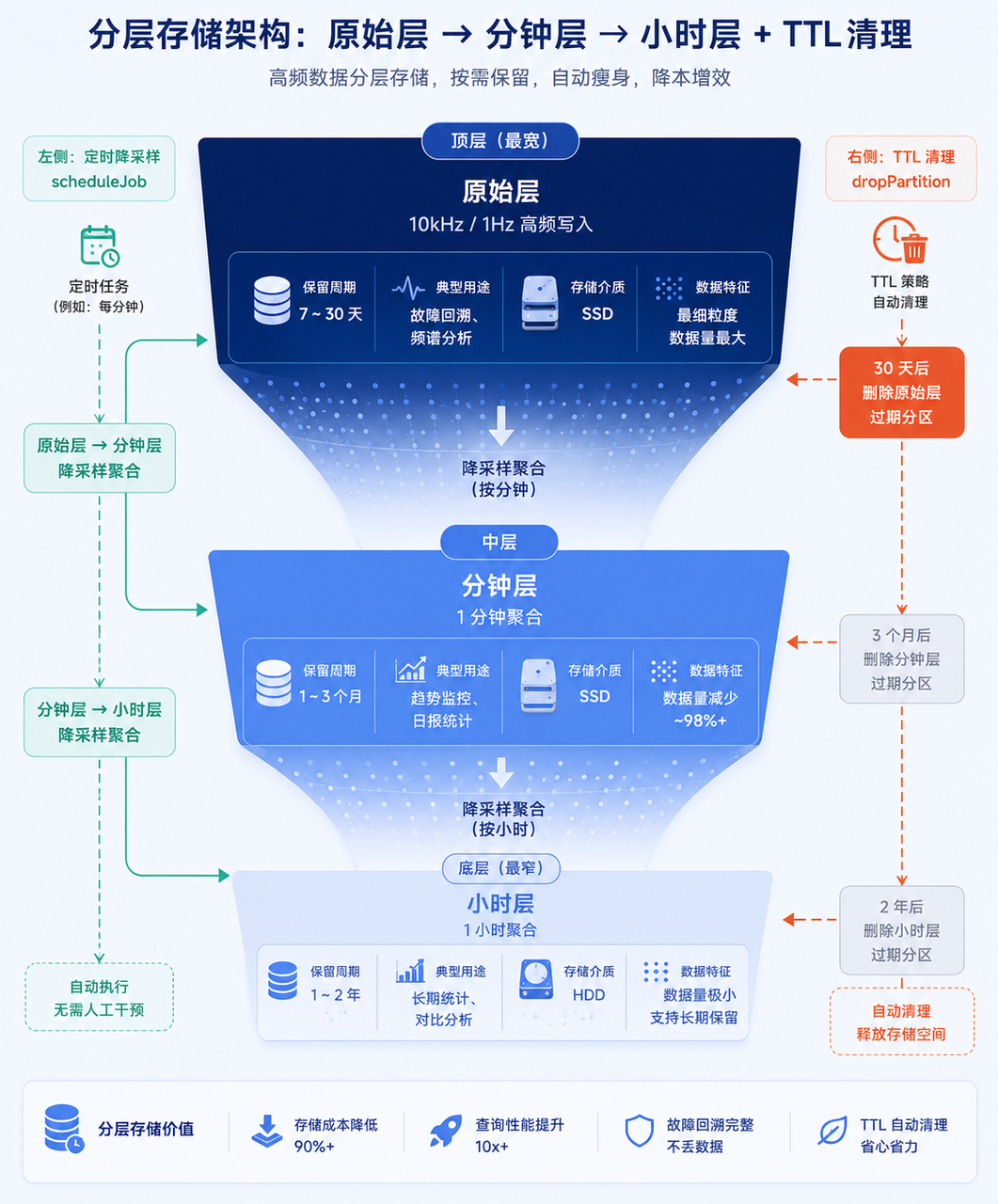
原始层只留近期数据,历史分析都跑在降采样层上。这样既保住了近期故障回溯的能力,又把长期存储成本压下来一个数量级。
4.2 用 scheduleJob 构建降采样管道
降采样的实现思路很直接:定时跑一个聚合 SQL,把结果写入降采样表。DolphinDB 的 scheduleJob 正好干这个:
// 1. 建分钟级降采样结果表
db_min = database("dfs://iot_min", VALUE, 2024.01.01..2025.12.31)
minSchema = table(1:0, `ts`deviceId`vibMean`vibMax`vibP95`tempMean`currentMean,
[TIMESTAMP, SYMBOL, DOUBLE, DOUBLE, DOUBLE, DOUBLE, DOUBLE])
db_min.createPartitionedTable(minSchema, "sensor_min", `ts)
// 2. 定义降采样函数:把昨天的原始数据聚合成分钟级
def downsampleToMinute() {
yesterday = date(now()) - 1
result = select
minute(ts) as ts,
deviceId,
avg(vibration) as vibMean,
max(vibration) as vibMax,
percentile(vibration, 95) as vibP95,
avg(temperature) as tempMean,
avg(current) as currentMean
from loadTable("dfs://iot", "sensor")
where date(ts) = yesterday
group by minute(ts), deviceId
loadTable("dfs://iot_min", "sensor_min").append!(result)
}
// 3. 注册定时任务:每天凌晨 1 点跑
scheduleJob("downsampleMin", "downsample raw to minute",
downsampleToMinute, 0 1 * * *)几个工程细节:
-
降采样表也按日期分区,和原始表保持一致的分区策略,方便关联查询。
-
用
minute(ts)这种时间桶函数聚合,比手动floor干净。 -
percentile(vibration, 95)这种分位数计算,在原始高频数据上算很慢,但降采样时算一次、存下来,后续分析直接用,这是降采样最大的价值之一。
4.3 查询时按需选层
降采样做好之后,业务查询就按时间范围选层:
-- 最近 1 小时的实时监控:查原始层(数据量小,快)
select avg(vibration) from loadTable("dfs://iot","sensor")
where ts > now() - 1H group by deviceId, bar(ts, 1m)
-- 最近 1 个月的趋势:查分钟层
select vibMean from loadTable("dfs://iot_min","sensor_min")
where date(ts) between 2024.06.01 and 2024.06.30
-- 最近 1 年的对比:查小时层
select vibMean from loadTable("dfs://iot_hour","sensor_hour")
where date(ts) between 2023.07.01 and 2024.06.30这种"按需选层"的策略,能让年级别的查询也停在毫秒到秒级,而不是去硬扫原始数据。
五、数据生命周期:TTL 与冷热分层
5.1 按分区清理过期数据
工业数据不能无限期保留原始数据。按天 VALUE 分区的一个直接好处是:TTL 实现起来特别简单——删分区就行。
// 删除 30 天前的原始数据分区
dropPartition(database("dfs://iot"),
[temporalSet(2024.05.01, 2024.05.31)], // 要删除的日期范围
sensor)
// 封装成定时任务,每天清理一次
def cleanExpiredRaw() {
cutoff = date(now()) - 30
dropPartition(database("dfs://iot"),
select * from temporalSet(date(now())-40, cutoff), true)
}
scheduleJob("cleanRaw", "clean raw data older than 30d",
cleanExpiredRaw, 0 3 * * *)dropPartition 删的是整个分区文件,不走逐行删除,所以即便数据量巨大,清理也是秒级完成,不会产生大量删除日志拖慢系统。这比在传统数据库里 delete from ... where ts < ... 要轻量得多。
策略上,建议原始层只留近期(7~30 天),降采样层留中长期,小时层留长期。配合上一节的降采样管道,就能在"不丢关键信息"和"控制存储成本"之间找到平衡。
5.2 冷热数据分级存储
如果连降采样后的数据都不想删,还可以做冷热分层。DolphinDB 支持给不同分区配置不同的存储介质(volume),把热数据放 SSD、冷数据挪到 HDD 或对象存储。
一个比较务实的分层:
-
近 1~3 个月的降采样数据:放 SSD,查询频繁,要求快。
-
3 个月以上的降采样数据:挪到 HDD,查询偶尔,慢一点能接受。
-
原始层:本身就只留短期,放 SSD 保证写入和近期回溯速度。
冷热分层的好处是用更低的成本保留更长的历史。实际操作中,这种分层往往是和降采样配合用的:原始层短期 + 热SSD,降采样层长期 + 冷HDD,成本和性能都能兼顾。
六、查询优化:让亿级数据查询停在毫秒级
前面几节把存储和治理讲完了,最后说说查询侧的优化。这部分很多是细节,但细节堆起来就是数量级的差距。
6.1 分区裁剪 + 列裁剪
除了前面说的"查询必须带时间条件触发分区裁剪",还有列裁剪。DolphinDB 是列式存储,查一列只读一列的文件:
-- ✅ 好:只取需要的列
select deviceId, avg(vibration) from sensor
where date(ts) = 2024.06.15 group by deviceId
-- ❌ 差:select * 把所有列都读出来,I/O 翻几倍
select * from sensor where date(ts) = 2024.06.15工业表动辄几十列测点,select * 的代价在列存下会被放大。养成"只取需要的列"的习惯,收益立竿见影。
6.2 context by + csort 的顺序陷阱
做移动窗口、累计计算这类时序分析时,context by(按组处理)几乎是必用的。但有个特别隐蔽的坑:context by 不保证组内的时间顺序。
-- ✅ 正确:csort 保证组内按时间排序,mavg 结果可靠
select deviceId, ts, mavg(vibration, 60) as vib_ma60
from sensor
where date(ts) = 2024.06.15
context by deviceId csort ts
-- ❌ 错误:缺 csort,mavg 的窗口可能跨越乱序数据,结果不可靠
select deviceId, ts, mavg(vibration, 60) as vib_ma60
from sensor
where date(ts) = 2024.06.15
context by deviceId这个坑踩过一次就忘不了——查询不报错,结果也"看起来正常",但移动平均值是错的,用在告警逻辑里会出大事。记住一个规矩:用 context by 配合任何移动窗口函数(mavg/msum/mstd/move/deltas)时,必须带 csort。
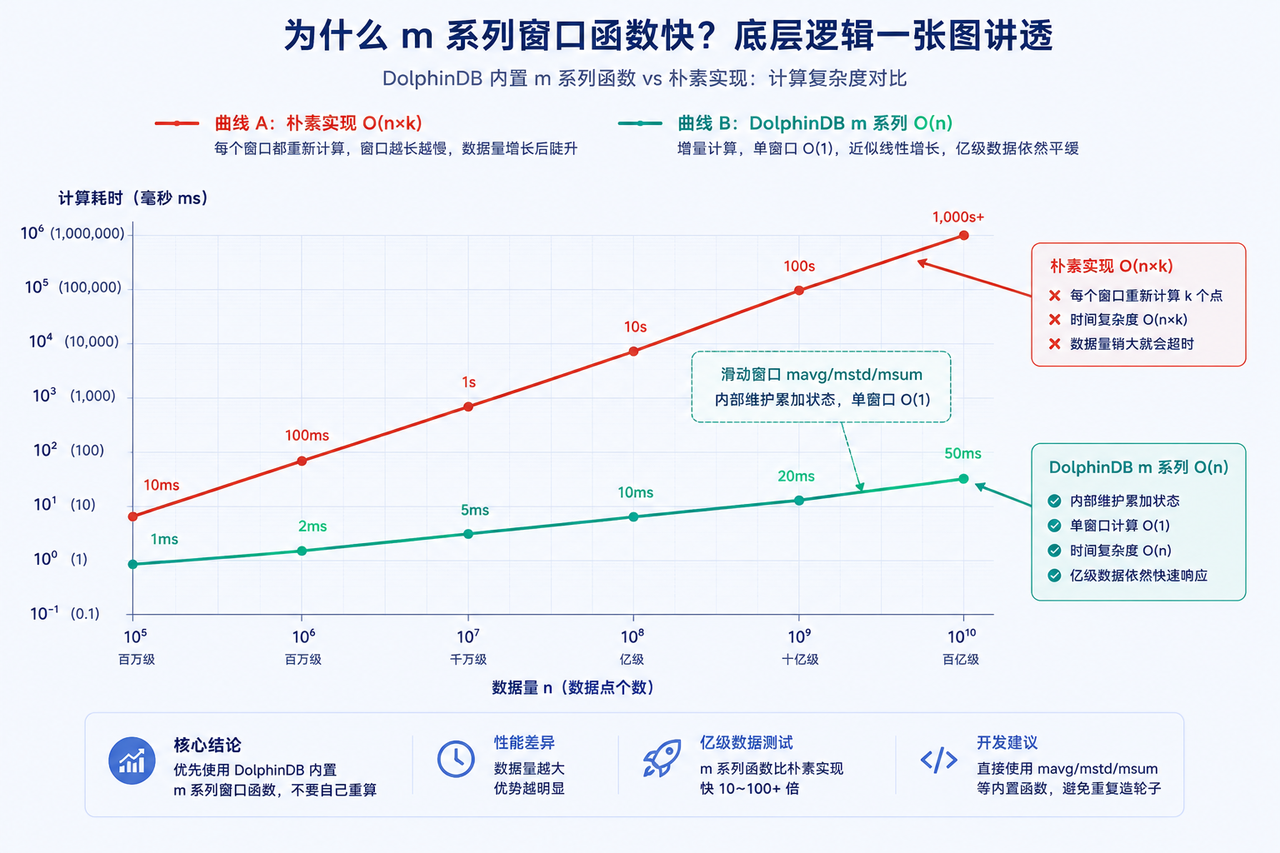
6.3 增量计算:O(n) → O(1)
这是 DolphinDB 在时序分析上性能领先的底层原因之一。
举个例子,计算一个长度为 60 的滑动窗口均值。朴素实现是每来一个点,对最近 60 个点重新求平均,复杂度 O(n×k),数据量一大就崩。DolphinDB 的内置窗口函数(mavg、mstd、msum 等)用了增量计算,通过维护一个累加状态,把每个窗口的计算压到 O(1),整体降到 O(n)。
-- 这些函数内部都做了增量优化,复杂度 O(n) 而非 O(n*k)
select deviceId, ts,
mavg(vibration, 60) as vib_ma60,
mstd(vibration, 60) as vib_std60,
mmax(vibration, 60) as vib_max60
from sensor
context by deviceId csort ts实际效果是:同样的滑动窗口计算,数据量从百万行涨到亿级,耗时不会断崖式上升,而是接近线性增长。所以在 DolphinDB 里做时序分析,优先用内置的 m 系列窗口函数,而不是自己写 SQL 重新算——后者既慢又容易写错。
七、局限与适用场景
前面讲了不少优点,但客观说,DolphinDB 在 IoT 数据治理上也有它不擅长的场景,选型时要心里有数:
-
轻量级 IoT 场景没必要上。如果只有几十个传感器、数据量不大、只需要 Grafana 看个板,InfluxDB + Grafana 更轻、上手更快。DolphinDB 的价值在数据量大、计算复杂、需要长期治理的场景下才能体现出来。
-
脚本语言有学习成本。虽然支持标准 SQL,但分区、流计算、定时任务这些核心能力都要用 DolphinDB 自有的脚本语法。从零到能独立写出上面的降采样管道,大概需要 1~2 周熟悉期。
-
可视化依赖第三方。DolphinDB 本身不做可视化,需要对接 Grafana(有官方插件)或自研前端。对希望"开箱即用看大屏"的团队,这一步要额外投入。
-
冷热分层和对象存储的对接,在不同版本上能力有差异,落地前最好确认清楚你用的版本支持哪些存储后端。
小结
把上面这些串起来,一个工业 IoT 时序数据的治理框架大概是这样:
传感器 → 流表(实时入口) → 分布式表(原始层, 按天+设备HASH分区)
│
┌────────────┼────────────┐
▼ ▼ ▼
降采样管道 查询优化 TTL清理
(scheduleJob) (分区/列裁剪 (dropPartition
分钟/小时层 +csort 删30天前原始)
长期保留) +增量计算)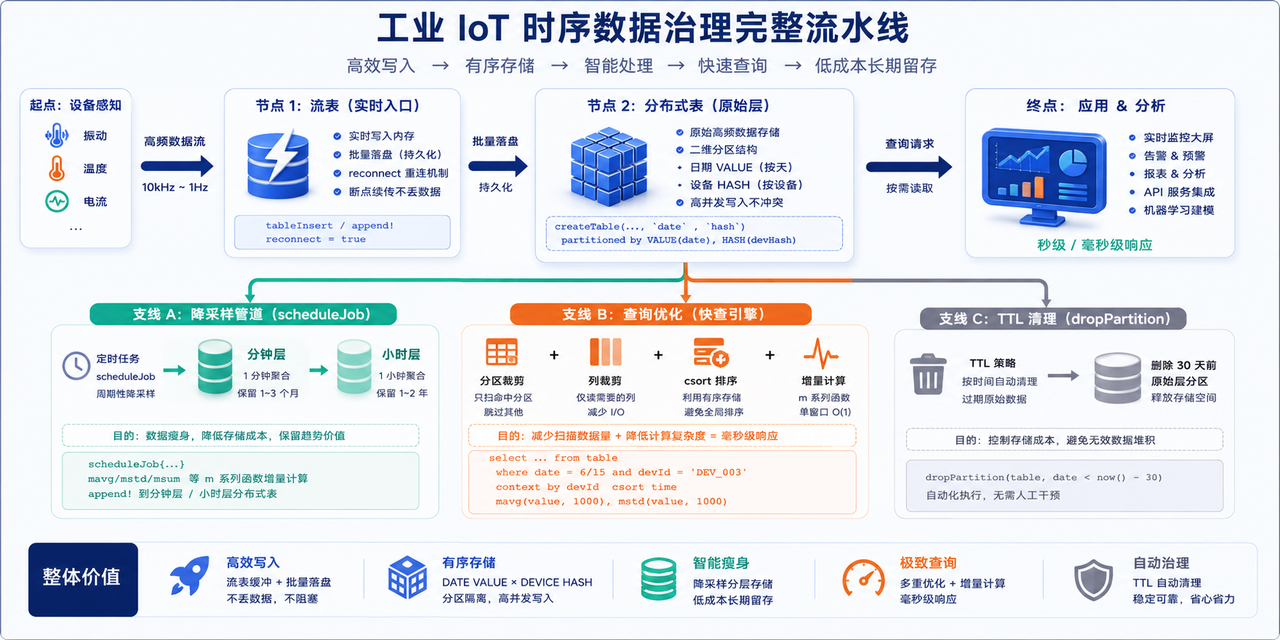
核心就几句话:
-
写入用流表订阅,靠批量落盘扛住高频;
-
分区用日期 VALUE + 设备 HASH,让查询能精确裁剪;
-
降采样把高频原始数据"瘦身"成可长期保留的聚合层;
-
TTL按分区清理,原始层只留近期;
-
查询靠分区裁剪、列裁剪、csort 顺序、增量计算四件套,保住亿级数据的毫秒响应。
这些细节单拎出来都不复杂,但组合在一起,决定了一个 IoT 数据平台是"跑 demo 很炫、上线三个月就卡",还是"能稳定承载长期业务"。数据治理这件事,没有什么惊天动地的黑科技,全是把对的细节在对的地方做对。
参考链接
更多推荐
 2
2 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)