
【C++】STL关联式容器:set与map高效查找秘籍
map与set的奥秘
一、序列式容器与关联式容器
1. 前言
我们在之前已经学过了STL的部分容器,如:string、vector、list等,它们都是序列式容器,其逻辑存储结构是线性的,两个位置存储的值之间一般没有紧密的关联关系,它们被称为序列式容器。顺序容器中的元素是按他们在容器中的存储位置来顺序保存和访问的
2. 序列式容器的缺陷
在介绍关联式容器之前,我们来看看序列式容器有哪些缺陷,数据量N,在序列式容器中查找一元素,所需的时间复杂度为:O(N),当N足够大时,那么查找的效率会大打折扣,那有没有效率更高的容器呢?有的,兄弟,有的!接下来引入我们今天的主角:关联式容器。
3. 关联式容器
关联式容器也是用来存储数据的,与序列式容器不同,关联式容器存储结构通常是非线性结构,两个位置之间有紧密的关系,交换一下,结构就被破坏了,比如说我们之前学过的二叉搜索树就是关联式容器。
我们今天要要学习的就是STL提供的四个容器:
| 容器 | 功能 |
|---|---|
| set | 有序去重 |
| map | 有序键值对 |
| multiset | 有序可重复 |
| multimap | 键可重复 |
本文讲解的map和set底层是红黑树,红黑树是一颗平衡二叉搜索树。set是key搜索场景的结构,map是key/value搜索
二、set系列的使用
1. set的介绍

- 这是set的声明,set在头文件< set >中,T是底层关键字类型,默认要求比较比较是小于比较,如果不支持或想实现其他比较方式,可以自己实现仿函数传参
- set的底层是红黑树,增删查的效率是O(logN),迭代器遍历走的是中序,因此set是有序的
- set的接口与list/vector等极为相似,这里就不多做介绍了
set的特点:
自动排序
元素唯一
不能修改元素
2. set的构造与迭代器
set支持正反向迭代器,因为底层是二叉搜索树,因此它的迭代器遍历是中序遍历,且它支持范围for,它不能直接修改数据,一旦修改数据就破坏了二叉搜索树的结构。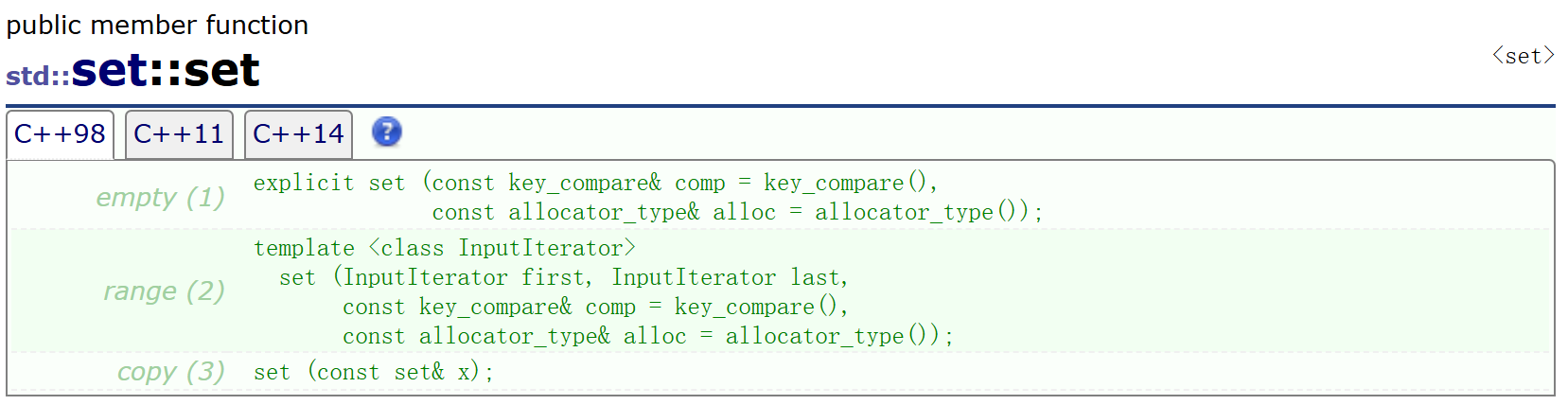
// 迭代器是⼀个双向迭代器
iterator -> a bidirectional iterator to const value_type
// 正向迭代器
iterator begin();
iterator end();
// 反向迭代器
reverse_iterator rbegin();
reverse_iterator rend();
set使用的是双向迭代器,可以++和- -,但是不支持operator[]或直接+或-
3. set的增删查
我们要熟悉set以下的接口:
Member types
key_type -> The first template parameter (T)
value_type -> The first template parameter (T)
// 单个数据插⼊,如果已经存在则插⼊失败
pair<iterator,bool> insert (const value_type& val);
// 列表插⼊,已经在容器中存在的值不会插⼊
void insert (initializer_list<value_type> il);
// 迭代器区间插⼊,已经在容器中存在的值不会插⼊
template <class InputIterator>
void insert (InputIterator first, InputIterator last);
// 查找val,返回val所在的迭代器,没有找到返回end()
iterator find (const value_type& val);
// 查找val,返回Val的个数
size_type count (const value_type& val) const;
// 删除⼀个迭代器位置的值
iterator erase (const_iterator position);
// 删除val,val不存在返回0,存在返回1
size_type erase (const value_type& val);
// 删除⼀段迭代器区间的值
iterator erase (const_iterator first, const_iterator last);
// 返回⼤于等val位置的迭代器
iterator lower_bound (const value_type& val) const;
// 返回⼤于val位置的迭代器
iterator upper_bound (const value_type& val) const;
3.1 insert
//升序
set<int> s;
//降序
//set<int, greater<int>> s;
s.insert(2);
s.insert(1);
s.insert(4);
s.insert(3);
s.insert(2);
for (auto i : s)
{
// error C3892: “i”: 不能给常量赋值
// *i = 1;
cout << i << ' ';
}
结果:
1 2 3 4
可见insert去重插入,迭代器默认升序输出。
在原来的s中插入initializer_list:
s.insert({ 3,2,6,7 });
for (auto i : s)
{
cout << i << ' ';
}
1,2,3,4,6,7
依旧是去重插入。
3.2 find和erase
erase
set<int> s = { 4,2,6,5,7,6,8 };
for (auto i : s)
{
cout << i << ' ';
}
cout << endl;
//删最小
s.erase(s.begin());
for (auto i : s)
{
cout << i << ' ';
}
cout << endl;
//删5
s.erase(5);
for (auto i : s)
{
cout << i << ' ';
}
2 4 5 6 7 8
4 5 6 7 8
4 6 7 8
find
set<int> s = { 10,20,30,40,50 };
for (auto i : s)
{
cout << i << ' ';
}
cout << endl;
auto it1 = s.find(20);
auto it2 = s.find(40);
auto it3 = s.find(60);
if (it1 != s.end() && it2 != s.end()) s.erase(it1, it2);
for (auto i : s)
{
cout << i << ' ';
}
cout << endl;
10 20 30 40 50
10 40 50
erase可支持迭代器区间左开右闭删除,find找到了返回对应的迭代器,找不到时返回s.end()
set<int> s = { 1,2,3,4,5,6,7,8,9 };
int x;
cin >> x;
// 算法库的查找 O(N)
auto pos1 = find(s.begin(), s.end(), x);
// set自身实现的查找 O(logN)
auto pos2 = s.find(x);
// 利用count间接实现快速查找
if (s.count(x))
{
cout << x << "在!" << endl;
}
else
{
cout << x << "不存在!" << endl;
}
利用count可以快速实现查找,元素存在返回1(set元素不重复),元素不在返回0。
迭代器失效
set也是存在迭代器失效的问题
set<int> s = { 1,2,3,4,5 };
auto it = s.begin();
s.erase(it);
cout << *it << endl;
程序会直接报错,it迭代器已经失效
3.3 lower_bound和upper_bound
这两个也是用来查找元素的
set<int> s = { 10,20,30,40,50,60,70,80,90 };
for (auto i : s)
{
cout << i << ' ';
}
cout << endl;
//返回>=30
auto itlow = s.lower_bound(30);
//返回<30
auto itup = s.upper_bound(60);
//删除[30,60)的元素
s.erase(itlow, itup);
for (auto i : s)
{
cout << i << ' ';
}
cout << endl;
10 20 30 40 50 60 70 80 90
10 20 70 80 90
- upper_bound返回的是第一个大于指定元素的迭代器
- lower_bound返回的是第一个大于等于指定元素的迭代器
4. multiset
multiset与set使用方法完全类似,主要区别在于multiset支持值冗余,那么我们来看看它们接口的差异
// 相⽐set不同的是,multiset是排序,但是不去重
multiset<int> s = { 4,2,7,2,4,8,4,5,4,9 };
auto it = s.begin();
while (it != s.end())
{
cout << *it << " ";
++it;
}
cout << endl;
// 相⽐set不同的是,x可能会存在多个,find查找中序的第⼀个
int x;
cin >> x;
auto pos = s.find(x);
while (pos != s.end() && *pos == x)
{
cout << *pos << " ";
++pos;
}
cout << endl;
// 相⽐set不同的是,count会返回x的实际个数
cout << s.count(x) << endl;
// 相⽐set不同的是,erase给值时会删除所有的x
s.erase(x);
for (auto e : s)
{
cout << e << " ";
}
cout << endl;
2 2 4 4 4 4 5 7 8 9
4
4 4 4 4
4
2 2 5 7 8 9
| 接口/特性 | set |
multiset |
|---|---|---|
| 元素是否重复 | 不允许 | 允许 |
| 元素是否有序 | 自动有序 | 自动有序 |
find(key) |
返回唯一元素位置 | 返回第一个相同元素位置 |
count(key) |
0 或 1 | 返回实际个数 |
erase(key) |
删除 0 或 1 个元素 | 删除所有相同元素 |
5. LeetCode实践
5.1 两个数的交集
具体见:两个数的交集
class Solution {
public:
vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {
set<int> s1(nums1.begin(),nums1.end());
set<int> s2(nums2.begin(),nums2.end());
vector<int> ret;
auto it1=s1.begin();
auto it2=s2.begin();
while(it1!=s1.end()&&it2!=s2.end())
{
if(*it1<*it2) it1++;
else if(*it1>*it2) it2++;
else
{
ret.push_back(*it1);
it1++;
it2++;
}
}
return ret;
}
};
5.2 环形链表II
具体见:环形链表II
class Solution {
public:
ListNode *detectCycle(ListNode *head) {
set<ListNode*> s;
ListNode* it=head;
while(it)
{
if(s.count(it)) return it;
s.insert(it);
it=it->next;
}
return nullptr;
}
};
这道题,我们在初学链表时用了一个比较复杂的方法去解决:先判断是否带环,再去找环入口,证明过程也比较麻烦。有了set,我们可以直接降维打击它,直接遍历链表,把节点指针存入set,如果带环,那在遍历时必定会遇到重复的节点,此节点就是环入口。
三、map系列的使用
1. map的介绍

- 这是map的声明,Key就是map底层键的类型,T就是map底层值的类型,默认要求是小于比较,如果不支持或自己想实现其他比较方式,可以自己传仿函数来实现
- map底层是红黑树实现,增删查改的效率是O(logN),迭代器遍历走的是中序遍历,所以是按key有序顺序遍历的
2. pair类型介绍
使用pair< Key,T >存储键值对数据。
typedef pair<const Key, T> value_type;
template <class T1, class T2>
struct pair
{
typedef T1 first_type;
typedef T2 second_type;
T1 first;
T2 second;
pair(): first(T1()), second(T2())
{}
pair(const T1& a, const T2& b): first(a), second(b)
{}
template<class U, class V>
pair (const pair<U,V>& pr): first(pr.first), second(pr.second)
{}
};
template <class T1,class T2>
inline pair<T1,T2> make_pair (T1 x, T2 y)
{
return ( pair<T1,T2>(x,y) );
}
pair是一个类,里有两个成员T1 first和T2 second,其默认构造就是调用两个成员的默认构造T1()和T2(),我们还可以通过make_pair来构造一个pair。
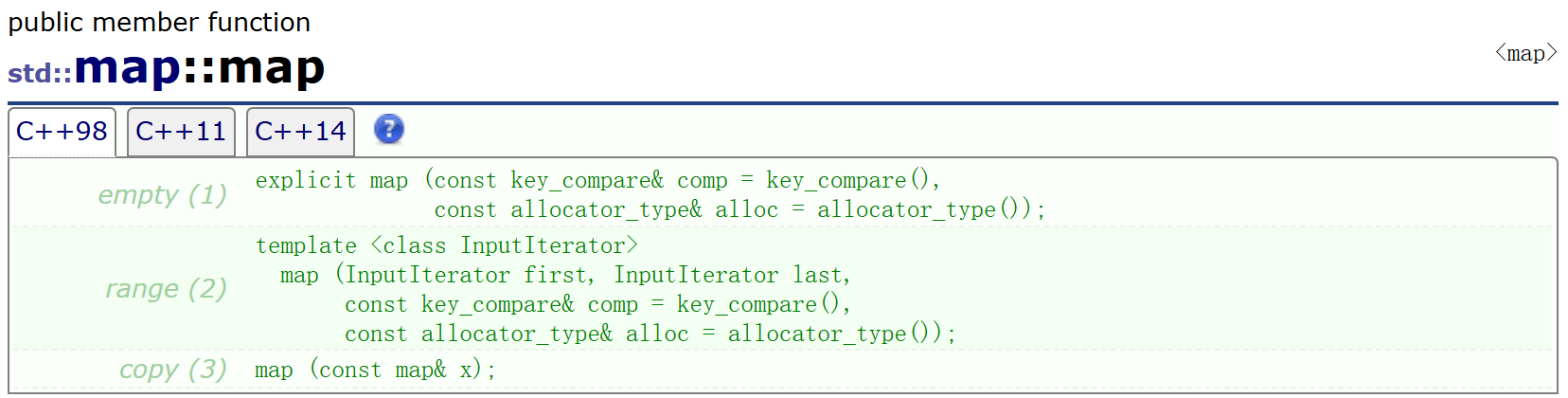
3. map的构造
map跟set一样,也是支持正向和反向迭代器,遍历默认以Key升序排列,因为底层是二叉搜索树,迭代器遍历走的是中序;支持迭代器就意味着支持范围for,map支持修改value数据,不支持修改Key数据,与set相同,修改Key就破坏了底层搜索树的结构。
// 迭代器是⼀个双向迭代器
iterator -> a bidirectional iterator to const value_type
// 正向迭代器
iterator begin();
iterator end();
// 反向迭代器
reverse_iterator rbegin();
reverse_iterator rend();
//单个pair构造
map<int, int> mp1({ 1,2 });
//多参数类型转换
map<int, int> mp2(1, 2);
//迭代区间构造
vector<pair<int, int>> v({ {1,2},{2,3},{3,4} });
map<int, int> mp3(v.begin(),v.end());
//initializer_list<pair>构造
map<int, int> mp4({ {1,2},{2,3},{3,4} });
4. equal_range
了解了pair之后,我们来看看四个关联式容器共有的一个小接口:
它会返回一个pair,存储的是键为k的开始迭代器和结束迭代器
5. map的增删查
map的删和查接口与set几乎相同,这里就不再赘述了,至于insert,我们将它与map的改一起讲
Member types
key_type -> The first template parameter (Key)
mapped_type -> The second template parameter (T)
value_type -> pair<const key_type,mapped_type>
// 查找k,返回k所在的迭代器,没有找到返回end()
iterator find (const key_type& k);
// 查找k,返回k的个数
size_type count (const key_type& k) const;
// 删除⼀个迭代器位置的值
iterator erase (const_iterator position);
// 删除k,k存在返回0,存在返回1
size_type erase (const key_type& k);
// 删除⼀段迭代器区间的值
iterator erase (const_iterator first, const_iterator last);
6. map的数据修改
前面我们提到map支持修改mapped_type数据,不支持修改Key数据。
6.1 find查找修改数据
// 查找k,返回k所在的迭代器,没有找到返回end()
iterator find (const key_type& k);
我们可以通过find找数据,如果找到了通过iterator可以修改Key对应的mapped_type值
6.2 insert
我们来看看insert是怎么个事?
// 单个数据插⼊,如果已经key存在则插⼊失败,key存在相等value不相等也会插⼊失败
pair<iterator,bool> insert (const value_type& val);
// 列表插⼊,已经在容器中存在的值不会插⼊
void insert (initializer_list<value_type> il);
// 迭代器区间插⼊,已经在容器中存在的值不会插⼊
template <class InputIterator>
void insert (InputIterator first, InputIterator last);
我们看第一个单个数据插入的insert,它是插入单个pair,返回一个pair<iterator,bool>对象:
- 如果Key已存在,插入失败,则返回pair的first是Key所在节点的迭代器,second为false
- 如果Key不存在,插入成功,则返回pair的first是新插入Key所在节点的迭代器,second为true
- 因此无论插入是否成功,first始终为Key所在的迭代器。那么这样来看,如果插入失败,那insert就相当于查找功能,因此,insert可以用来实现operator[]
6.3 operator[]
map还可以支持operator[],但是operator[]不仅仅支持修改,还支持插入数据和查找数据。需要注意一点:从内部实现角度,map这里把我们传统说的value值,给的是T类型,typedef成mapped_type。而value_type是红黑树节点中存储的pair键值对。
mapped_type& operator[] (const key_type& k);
- 如果k不在map中,insert会插入k和mapped_type(value)的默认值,同时返回mapped_type(value)的引用,因此我们通过[]实现插入+修改功能
- 如果k在map,insert插入失败,返回k所在节点的迭代器,而[]返回节点中mapped_type的引用,因此我们通过[]实现查找+修改功能
7. multimap
multimap和map使用基本完全类似,主要区别在于multimap支持关键值Key冗余,至于接口的差异,与set和multiset完全一样,这里就不多讲了,可以直接去看文档
8.multimap大小比较
记住一点:四种容器的大小比较标准是key或pair的first,从来不是value或second,那有人就要问了:“那multimap怎么办,它可能有first相同的怎么排序?”,实践出真知,我们来看下面一段程序:
multimap<int, int> mmp({ {1,2},{1,1},{1,3} });
for (auto i : mmp)
{
cout << i.second << ' ';
}
2 1 3
我们把第二个pair的second的1改成4:
multimap<int, int> mmp({ {1,2},{1,4},{1,3} });
for (auto i : mmp)
{
cout << i.second << ' ';
}
2 4 3
因此我们可以得到multimap遇到相同的first时,排列顺序与插入顺序有关
9. LeetCode实践——复杂链表的复制
复杂链表的复制
我们可以先复制一个next连接的链表,然后再把原链表的节点与与复制链表的节点通过map一一映射,最后在遍历原链表时,就可以通过map定位到复制链表。
class Solution {
public:
Node* copyRandomList(Node* head) {
map<Node*,Node*> NodeMap;
Node* copyhead=nullptr,*copytail=nullptr;
Node* cur=head;
while(cur)
{
if(copytail==nullptr)
{
copyhead=new Node(cur->val);
copytail=copyhead;
}
else
{
copytail->next=new Node(cur->val);
copytail=copytail->next;
}
NodeMap[cur]=copytail;
cur=cur->next;
}
cur=head;
Node* copy=copyhead;
while(copy)
{
if(cur->random==nullptr)
{
copy->random=nullptr;
}
else
{
copy->random=NodeMap[cur->random];
}
cur=cur->next;
copy=copy->next;
}
return copyhead;
}
};更多推荐


 12
12 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)