
Java 程序员第 43 阶段16:微服务整合大模型,跨服务调用架构设计实战,Kubernetes编排大模型服务
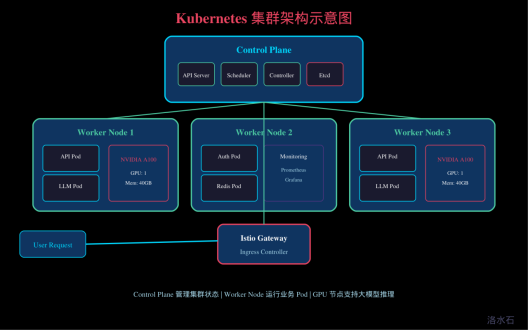 Kubernetes(简称 K8s)已成为容器编排领域的标准,是现代云原生应用的基础设施平台。当微服务架构与大模型服务相结合时,Kubernetes 提供了强大的服务管理能力,包括自动化部署、弹性伸缩、自我修复、配置管理等关键功能。本章将深入探讨如何利用 Kubernetes 编排和管理大模型服务,构建高可用、可扩展的智能应用平台。
Kubernetes(简称 K8s)已成为容器编排领域的标准,是现代云原生应用的基础设施平台。当微服务架构与大模型服务相结合时,Kubernetes 提供了强大的服务管理能力,包括自动化部署、弹性伸缩、自我修复、配置管理等关键功能。本章将深入探讨如何利用 Kubernetes 编排和管理大模型服务,构建高可用、可扩展的智能应用平台。
16.1.1 Kubernetes 架构概述
Kubernetes 源于 Google 内部的 Borg 系统,于 2015 年捐赠给 CNCF 并成为开源项目。Kubernetes 的核心目标是实现容器化应用的自动化运维,包括容器部署、负载均衡、服务发现、弹性伸缩、故障恢复等。
Kubernetes 的架构采用主从分布式设计。Master 节点(Control Plane)负责整个集群的管理和控制,包括 API Server、Etcd、Scheduler、Controller Manager 等组件;Worker 节点负责运行实际的容器负载,每个节点上运行 Kubelet、Kube-Proxy 和容器运行时(如 Docker 或 containerd)。
API Server 是 Kubernetes 控制平面的核心组件,提供了 RESTful API 接口,所有 kubectl 命令和客户端 SDK 都通过 API Server 与集群交互。Scheduler 负责将新建的 Pod 调度到合适的 Worker 节点,考虑资源需求、亲和性规则、拓扑分布等因素。Controller Manager 运行各种控制器进程,如 ReplicaSet Controller、Deployment Controller、Service Controller 等,确保集群状态达到期望状态。
Etcd 是高可用的分布式键值存储,用于保存集群的所有配置数据和状态信息。Etcd 的重要性决定了它通常需要专门的备份和高可用策略。
16.1.2 核心资源对象解析
Kubernetes 将所有管理对象抽象为资源对象,通过 YAML 或 JSON 格式的清单文件(Manifest)进行声明式管理。理解核心资源对象是掌握 Kubernetes 的基础。
Pod 是 Kubernetes 的最小调度单元,一个 Pod 可以包含一个或多个共享网络和存储的容器。通常建议每个 Pod 只运行一个容器(Sidecar 模式除外),这样可以简化管理并提高灵活性。Pod 本身是有临时性的,Kubernetes 通过更高层次的资源对象(如 Deployment)来保证 Pod 的可用性。
# Pod 资源清单示例
apiVersion: v1
kind: Pod
metadata:
name: llm-inference-pod
labels:
app: llm-inference
version: v1
spec:
containers:
- name: llm-inference
image: llm-inference:v1.0
ports:
- containerPort: 8000
resources:
requests:
memory: "4Gi"
cpu: "2"
nvidia.com/gpu: "1"
limits:
memory: "8Gi"
cpu: "4"
nvidia.com/gpu: "1"
env:
- name: MODEL_PATH
value: "/models/chatglm3-6b"
volumeMounts:
- name: model-volume
mountPath: /models
livenessProbe:
httpGet:
path: /health
port: 8000
initialDelaySeconds: 60
periodSeconds: 10
readinessProbe:
httpGet:
path: /ready
port: 8000
initialDelaySeconds: 30
periodSeconds: 5
volumes:
- name: model-volume
persistentVolumeClaim:
claimName: model-pvc
Deployment 是最常用的 workload 资源,用于声明式地管理 Pod 的副本数、更新策略、滚动回滚等。一个 Deployment 会创建对应的 ReplicaSet,ReplicaSet 再管理实际的 Pod。通过 Deployment,可以实现应用的滚动更新(Rolling Update)和回滚(Rollback)功能。
# Deployment 资源清单示例
apiVersion: apps/v1
kind: Deployment
metadata:
name: llm-api-deployment
labels:
app: llm-api
spec:
replicas: 3
selector:
matchLabels:
app: llm-api
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 1
maxUnavailable: 0
template:
metadata:
labels:
app: llm-api
version: v1
spec:
containers:
- name: llm-api
image: llm-api:v1.0
ports:
- containerPort: 8080
env:
- name: SPRING_PROFILES_ACTIVE
value: "production"
resources:
requests:
memory: "512Mi"
cpu: "500m"
limits:
memory: "2Gi"
cpu: "2000m"
readinessProbe:
httpGet:
path: /actuator/health/readiness
port: 8080
Service 为一组 Pod 提供稳定的访问入口,屏蔽了 Pod 的 IP 变化和负载均衡问题。ClusterIP 类型的 Service 在集群内部提供访问;NodePort 在每个节点上开放端口;LoadBalancer 类型的 Service 整合云提供商的负载均衡器。
16.1.3 大模型服务在 Kubernetes 上的特殊需求
大模型服务在 Kubernetes 上的部署面临一些独特的挑战,需要特殊的设计和配置。
GPU 资源调度是大模型服务最核心的需求。大模型推理需要 GPU 加速,Kubernetes 通过 device plugin 机制支持 GPU 资源的调度和隔离。配置 GPU 调度需要安装 NVIDIA Device Plugin,并正确配置 nodeSelector 或 tolerations 来调度 Pod 到配备 GPU 的节点。
# GPU 调度的节点标签配置
apiVersion: v1
kind: Node
metadata:
name: gpu-node-1
labels:
node.kubernetes.io/gpu-count: "1"
nvidia.com/gpu.product: "NVIDIA-A100-PCIE-40GB"
显存管理是 GPU 调度的关键问题。不同模型对显存的需求差异很大,从几 GB 到几十 GB 不等。Kubernetes 目前对 GPU 显存的管理还比较粗粒度,主要通过资源 limits 来限制。实际部署中需要考虑模型的量化版本选择,确保模型能够适配可用的 GPU 显存。
模型文件的存储和加载也需要特殊处理。大型模型文件不适合打包在容器镜像中,通常通过 PersistentVolumeClaim(PVC)挂载存储卷来加载模型。模型加载时间可能很长(数分钟),这会影响到 Pod 的启动时间和就绪探针的配置。
16.2.1 服务网格概述
服务网格(Service Mesh)是微服务架构中处理服务间通信的基础设施层,通常以 Sidecar 代理的形式部署,为每个服务实例提供可靠的通信能力。Istio 是目前最流行的服务网格实现,与 Kubernetes 深度集成,提供了流量管理、安全加固、可观测性等核心功能。
在大模型微服务架构中,服务网格的价值体现在:流量管理方面,可以通过 VirtualService 和 DestinationRule 实现精细的流量控制,如灰度发布、A/B 测试、流量镜像等;安全方面,提供 mTLS 加密、服务身份认证、授权策略等能力;可观测性方面,自动收集所有服务的追踪、指标和日志数据。
Istio 的核心组件包括:控制平面组件(Istiod)负责配置管理和证书颁发;数据平面组件(Envoy Sidecar)作为代理处理所有入站和出站流量; Ingress Gateway 和 Egress Gateway 分别处理入口和出口流量。
16.2.2 Istio 流量管理实战
Istio 的流量管理功能非常强大,支持基于权重、Header、Cookie 等多种条件的流量路由。对于大模型服务,常见的应用场景包括:模型版本的灰度发布、AB 测试不同模型的输出质量、多模型间的流量分配等。
# Istio VirtualService - 灰度发布配置
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: llm-service
spec:
hosts:
- llm-service
http:
- match:
- headers:
X-Canary:
exact: "true"
route:
- destination:
host: llm-service
subset: v2 # 灰度版本
weight: 100
- route:
- destination:
host: llm-service
subset: v1 # 主版本
weight: 90
- destination:
host: llm-service
subset: v2
weight: 10 # 10% 流量切到新版本
apiVersion: networking.istio.io/v1alpha3
kind: DestinationRule
metadata:
name: llm-service
spec:
host: llm-service
trafficPolicy:
connectionPool:
tcp:
maxConnections: 100
http:
h2UpgradePolicy: UPGRADE
http1MaxPendingRequests: 100
http2MaxRequests: 1000
loadBalancer:
simple: LEAST_REQUEST
subsets:
- name: v1
labels:
version: v1
- name: v2
labels:
version: v2
16.2.3 大模型服务的流量治理策略
在大模型服务场景中,流量治理需要考虑一些特殊因素。大模型调用的响应时间差异很大(从几百毫秒到几十秒),传统的超时配置可能不适用;Token 消耗与成本直接相关,需要精细的流量控制来避免意外的费用激增;多模型场景下,需要根据模型能力和负载情况进行智能路由。
建议的大模型服务流量治理策略包括:为不同类型的模型调用设置不同的超时时间;配置熔断规则,防止下游模型服务故障影响整体可用性;使用流量镜像功能,将生产请求复制到新版本进行测试,而不影响实际用户。
# 大模型服务的超时和熔断配置
apiVersion: networking.istio.io/v1alpha3
kind: DestinationRule
metadata:
name: llm-api-destination
spec:
host: llm-api
trafficPolicy:
connectionPool:
tcp:
maxConnections: 50
http:
h2UpgradePolicy: UPGRADE
http1MaxPendingRequests: 50
http2MaxRequests: 100
maxRequestsPerConnection: 10
outlierDetection:
consecutiveGatewayErrors: 5
interval: 30s
baseEjectionTime: 30s
maxEjectionPercent: 50
minHealthPercent: 30
# 大模型调用超时配置
http2ProtocolOptions:
maxConcurrentStreams: 100
# 模型级别的超时覆盖
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: llm-api-vs
spec:
hosts:
- llm-api
http:
- match:
- headers:
x-model-type:
exact: gpt4
timeout: 120s # GPT-4 超时120秒
route:
- destination:
host: llm-api-gpt4
- match:
- headers:
x-model-type:
exact: gpt35
timeout: 30s # GPT-3.5 超时30秒
route:
- destination:
host: llm-api-gpt35
- route:
- destination:
host: llm-api
timeout: 60s # 默认超时60秒
16.3.1 Horizontal Pod Autoscaler 实现
Kubernetes 的 Horizontal Pod Autoscaler(HPA)根据 CPU、内存等指标自动调整 Pod 的副本数量。结合 Prometheus 或其他监控系统的自定义指标,HPA 可以实现更加智能的伸缩策略。
对于大模型服务,传统的 CPU 和内存指标可能无法准确反映实际的负载情况。例如,当模型推理是 GPU 密集型任务时,CPU 使用率可能很低但 GPU 已经满载。因此,需要基于大模型特有的指标(如请求队列长度、Token 处理速率等)来实现弹性伸缩。
# 基于自定义指标的 HPA 配置
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: llm-api-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: llm-api-deployment
minReplicas: 2
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 70
- type: Resource
resource:
name: memory
target:
type: Utilization
averageUtilization: 80
- type: Pods
pods:
metric:
name: llm_request_queue_length # 自定义指标
target:
type: AverageValue
averageValue: "10"
behavior:
scaleDown:
stabilizationWindowSeconds: 300
policies:
- type: Percent
value: 10
periodSeconds: 60
scaleUp:
stabilizationWindowSeconds: 0
policies:
- type: Percent
value: 100
periodSeconds: 15
- type: Pods
value: 4
periodSeconds: 60
selectPolicy: Max
16.3.2 Vertical Pod Autoscaler 与节点池管理
Vertical Pod Autoscaler(VPA)自动调整 Pod 的资源请求,帮助优化资源利用。对于大模型服务,正确设置资源请求尤为重要——请求过多造成资源浪费,请求过少导致 OOMKill。
节点池管理是集群级别的重要优化手段。通过为不同类型的负载配置专门的节点池,可以提高资源利用效率。例如,将 GPU 节点和普通节点分开,让 GPU 密集型 workloads 调度到专门的 GPU 节点池。
# 节点池配置示例
apiVersion: v1
kind: NodePool
metadata:
name: gpu-pool
namespace: default
spec:
config:
machineType: a2-highgpu-1g # NVIDIA A100
diskSize: 100GB
diskType: pd-ssd
labels:
gpu: "true"
nvidia.com/gpu.product: NVIDIA-A100-PCIE-40GB
taints:
- key: nvidia.com/gpu
value: "present"
effect: NoSchedule
minNodes: 1
maxNodes: 5
autoprovisioning:
enabled: true
minNodes: 0
maxNodes: 3
coolDownPeriod: 300s
16.3.3 高可用架构设计
大模型服务的高可用设计需要考虑多个层面的冗余和故障转移。
Pod 级别的高可用通过 Deployment 的多副本部署实现。建议生产环境至少部署 2 个副本,分布在不同的可用区(Availability Zone)。通过 Pod Disruption Budget(PDB)限制单次 disruption 影响的 Pod 数量。
# PodDisruptionBudget 配置
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
name: llm-api-pdb
spec:
minAvailable: 2 # 至少保持2个可用 Pod
selector:
matchLabels:
app: llm-api
服务级别的高可用通过多 Service 端点和负载均衡实现。结合 Readiness Probe,只有就绪的 Pod 才会接收流量。通过反亲和性规则(Anti-Affinity)可以将 Pod 调度到不同的节点,进一步提高可用性。
全局层面的高可用可能需要跨集群或跨地域的部署架构。使用 Istio 的多集群配置,可以实现跨 Kubernetes 集群的服务发现和流量管理。
16.4.1 ConfigMap 与 Secret 的使用
ConfigMap 用于存储非敏感的配置文件和环境变量,Secret 用于存储敏感数据如密码、API 密钥、证书等。在大模型服务中,API 密钥的存储尤为重要。
Secret 有多种类型,其中 Opaque 是最常用的通用类型。对于 TLS 证书等特殊数据,可以使用 kubernetes.io/tls 类型。更好的做法是使用 Vault 或 AWS Secrets Manager 等专门的密钥管理服务,Kubernetes 通过 CSI 驱动或 External Secrets Operator 与之集成。
# Secret 资源清单示例
apiVersion: v1
kind: Secret
metadata:
name: llm-api-secrets
type: Opaque
stringData:
OPENAI_API_KEY: "sk-xxxxxx"
ANTHROPIC_API_KEY: "sk-ant-xxxxxx"
JWT_SECRET: "your-jwt-secret-key"
# Deployment 中引用 Secret
apiVersion: apps/v1
kind: Deployment
metadata:
name: llm-api-deployment
spec:
template:
spec:
containers:
- name: llm-api
env:
- name: OPENAI_API_KEY
valueFrom:
secretKeyRef:
name: llm-api-secrets
key: OPENAI_API_KEY
- name: ANTHROPIC_API_KEY
valueFrom:
secretKeyRef:
name: llm-api-secrets
key: ANTHROPIC_API_KEY
16.4.2 External Secrets Operator
External Secrets Operator(ESO)是 Kubernetes 生态中用于管理外部密钥库的 CRD 控制器。通过 ESO,可以将 AWS Secrets Manager、Azure Key Vault、GCP Secret Manager、HashiCorp Vault 等外部密钥服务与 Kubernetes Secret 无缝集成。
使用 ESO 的优势在于:密钥可以集中管理,支持自动轮换;Secret 数据以加密形式存储在 Kubernetes 中;支持同步更新,当外部密钥更新时,Kubernetes Secret 自动更新。
# ExternalSecret 配置示例
apiVersion: external-secrets.io/v1beta1
kind: ExternalSecret
metadata:
name: llm-api-external-secrets
spec:
refreshInterval: 1h # 每小时检查更新
secretStoreRef:
name: vault-backend
kind: ClusterSecretStore
target:
name: llm-api-secrets # 创建的 Secret 名称
creationPolicy: Owner
data:
- secretKey: OPENAI_API_KEY
remoteRef:
key: production/llm/openai
property: api_key
- secretKey: ANTHROPIC_API_KEY
remoteRef:
key: production/llm/anthropic
property: api_key
apiVersion: external-secrets.io/v1beta1
kind: ClusterSecretStore
metadata:
name: vault-backend
spec:
vault:
server: "https://vault.example.com"
path: "secret"
version: "v2"
auth:
kubernetes:
mountPath: kubernetes
role: "llm-app"
16.4.3 大模型配置的集中管理
在大模型服务中,模型配置、Prompt 模板、Agent 策略等业务配置需要集中管理,便于版本控制和动态更新。建议将配置分为三个层次:
基础配置通过环境变量注入,包括服务端口、日志级别等;业务配置使用 ConfigMap 存储,如 Prompt 模板、RAG 配置、Agent 策略等;密钥配置使用 External Secrets 管理。
对于需要频繁更新的配置,可以使用 ConfigMap 的 subPath 挂载结合热更新机制,或者使用配置中心(如 Apollo、Nacos)实现动态配置。
# 大模型业务配置 ConfigMap
apiVersion: v1
kind: ConfigMap
metadata:
name: llm-config
data:
config.yaml: |
models:
gpt4:
provider: openai
version: "gpt-4-turbo"
maxTokens: 4096
temperature: 0.7
claude3:
provider: anthropic
version: "claude-3-opus"
maxTokens: 4096
temperature: 0.7
rag:
enabled: true
topK: 5
similarityThreshold: 0.75
vectorStore: pinecone
prompt:
systemTemplate: |
You are a helpful AI assistant.
Current user: {{user_name}}
Current time: {{current_time}}
maxContextLength: 8192
16.5.1 整体部署架构
综合前面章节的内容,本节给出一个完整的大模型微服务 Kubernetes 部署方案。该方案采用分层架构,包括接入层、控制平面和数据平面。
接入层包含 Ingress Controller(使用 Istio Gateway)和 API 网关服务,负责请求的路由、认证和限流。
控制平面包含 Istiod、Prometheus、Grafana、Loki、Tempo 等监控组件,以及 External Secrets Operator、Cert Manager 等基础设施组件。
数据平面包含实际的微服务和大模型推理服务,按照业务域划分部署单元。
# 完整的命名空间划分
apiVersion: v1
kind: Namespace
metadata:
name: llm-system
apiVersion: v1
kind: Namespace
metadata:
name: llm-production
labels:
istio-injection: enabled
apiVersion: v1
kind: Namespace
metadata:
name: monitoring
16.5.2 大模型推理服务的部署配置
大模型推理服务是整个系统中最关键的组件,需要特别关注资源限制、健康检查和启动顺序。
# 大模型推理服务完整部署配置
apiVersion: apps/v1
kind: Deployment
metadata:
name: llm-inference
namespace: llm-production
labels:
app: llm-inference
version: v1
spec:
replicas: 2
selector:
matchLabels:
app: llm-inference
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 1
maxUnavailable: 0
template:
metadata:
labels:
app: llm-inference
version: v1
annotations:
prometheus.io/scrape: "true"
prometheus.io/port: "8000"
prometheus.io/path: "/metrics"
spec:
# 亲和性配置:优先调度到 GPU 节点
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: nvidia.com/gpu
operator: Exists
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchLabels:
app: llm-inference
topologyKey: kubernetes.io/hostname
tolerations:
- key: nvidia.com/gpu
operator: Exists
effect: NoSchedule
containers:
- name: inference
image: llm-inference:v1.0
ports:
- containerPort: 8000
name: http
- containerPort: 8001
name: grpc
resources:
requests:
memory: "16Gi"
cpu: "4"
nvidia.com/gpu: "1"
limits:
memory: "32Gi"
cpu: "8"
nvidia.com/gpu: "1"
env:
- name: MODEL_NAME
value: "chatglm3-6b"
- name: MODEL_PATH
value: "/models/chatglm3-6b"
- name: MAX_CONCURRENT_REQUESTS
value: "10"
- name: MAX_BATCH_SIZE
value: "8"
volumeMounts:
- name: model-volume
mountPath: /models
- name: tmp-volume
mountPath: /tmp
livenessProbe:
httpGet:
path: /health
port: 8000
initialDelaySeconds: 120
periodSeconds: 30
timeoutSeconds: 10
failureThreshold: 3
readinessProbe:
httpGet:
path: /ready
port: 8000
initialDelaySeconds: 60
periodSeconds: 10
timeoutSeconds: 5
failureThreshold: 3
lifecycle:
preStop:
exec:
command: ["/bin/sh", "-c", "sleep 10"]
volumes:
- name: model-volume
persistentVolumeClaim:
claimName: model-pvc
- name: tmp-volume
emptyDir:
medium: Memory
sizeLimit: 8Gi
# 优雅终止时间
terminationGracePeriodSeconds: 60
apiVersion: v1
kind: Service
metadata:
name: llm-inference
namespace: llm-production
spec:
type: ClusterIP
ports:
- port: 8000
targetPort: 8000
protocol: TCP
name: http
- port: 8001
targetPort: 8001
protocol: TCP
name: grpc
selector:
app: llm-inference
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: llm-inference-hpa
namespace: llm-production
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: llm-inference
minReplicas: 2
maxReplicas: 8
metrics:
- type: Resource
resource:
name: nvidia.com/gpu
target:
type: Utilization
averageUtilization: 80
- type: Pods
pods:
metric:
name: inference_request_in_flight
target:
type: AverageValue
averageValue: "5"
16.5.3 监控与告警配置
完整的监控告警配置是保障大模型服务稳定运行的关键。
# Prometheus 监控配置
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: llm-inference-monitor
namespace: monitoring
labels:
release: prometheus
spec:
selector:
matchLabels:
app: llm-inference
namespaceSelector:
matchNames:
- llm-production
endpoints:
- port: http
path: /metrics
interval: 15s
scheme: http
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
name: llm-inference-alerts
namespace: monitoring
spec:
groups:
- name: llm-inference.rules
rules:
- alert: LLMInferenceHighLatency
expr: histogram_quantile(0.95, rate(inference_request_duration_seconds_bucket[5m])) > 10
for: 5m
labels:
severity: warning
annotations:
summary: "LLM inference latency is high"
description: "P95 latency is {{ $value }}s"
- alert: LLMInferenceErrorRateHigh
expr: rate(inference_requests_total{status="error"}[5m]) / rate(inference_requests_total[5m]) > 0.05
for: 2m
labels:
severity: critical
annotations:
summary: "LLM inference error rate is high"
description: "Error rate is {{ $value | humanizePercentage }}"
- alert: GPUUtilizationLow
expr: avg(nvidia_gpu_utilization) < 30
for: 10m
labels:
severity: info
annotations:
summary: "GPU utilization is low"
本章系统性地介绍了 Kubernetes 编排大模型服务的核心技术。
从 Kubernetes 架构和核心资源对象出发,我们理解了 Pod、Deployment、Service 等基础资源的声明式管理方式,以及大模型服务在 GPU 调度、显存管理、模型加载等方面的特殊需求。
服务网格章节介绍了 Istio 的流量管理能力,包括灰度发布、A/B 测试、流量镜像等高级功能,为大模型服务的精细化运营提供了技术基础。
弹性伸缩与高可用设计部分,详细介绍了 HPA、VPA 的配置方法,以及多层次的高可用架构设计,确保大模型服务在生产环境中的稳定运行。
配置管理与密钥安全章节,介绍了 ConfigMap、Secret 的使用,以及 External Secrets Operator 实现与外部密钥库的集成,保障了大模型 API 密钥等敏感数据的安全。
最后的实战章节给出了一个完整的大模型服务 Kubernetes 部署方案,涵盖从命名空间划分、资源调度、弹性伸缩到监控告警的全部配置。
随着大模型技术的持续发展,Kubernetes 在大模型服务领域的应用也将不断深化。建议读者持续关注 GPU 资源管理、模型服务网格、Serverless 推理等领域的最新发展,构建更加智能和高效的大模型服务平台。
更多推荐
 4
4 0
0- 0



 已为社区贡献106条内容
已为社区贡献106条内容

所有评论(0)