
Anaconda + NumPy + Pandas + Matplotlib 实战入门:Python 数据科学从入门到精通,助你成为数据大神!
本文详细介绍了 Anaconda、NumPy、Pandas 和 Matplotlib 这四个 Python 数据科学核心库。内容涵盖了 Anaconda 的安装与使用,NumPy 的数组操作、常用函数和矩阵乘法,Pandas 的 Series 和 DataFrame 创建、常用属性与方法,以及数据的导入导出。最后,文章还介绍了 Matplotlib 和 Seaborn 的可视化功能,帮助你更好地展示数据分析结果。通过学习本文,你将掌握 Python 数据科学的基本技能,为后续深入学习打下坚实基础。
Anaconda
Anaconda 官网地址:https://www.anaconda.com/
Anaconda = Python + 包和环境管理器(Conda)+ 常用库 + 集成工具。
Numpy
numpy 是 Python 中科学计算的基础包。
它是一个包含 ndarray 和所有操作它的函数 / 工具的完整 Python 库,提供多维数组对象、各种派
生对象(例如掩码数组和矩阵)以及用于对数组进行快速操作的各种方法,包括数学、逻辑、形
状操作、排序、选择、I/O 、离散傅里叶变换、基本线性代数、基本统计运算、随机模拟等等。
1、array()、asarray()
array()**:**将输入数据转换为 ndarray,会进行 copy。
asarray()**:**将输入数据转换为 ndarray,如果输入本身是 ndarray 则不会进行 copy。
2、zeros()、ones()、empty()与 zeros_like()、ones_like()、empty_like()
zeros():返回给定形状和类型的新数组,用 0 填充。
ones():返回给定形状和类型的新数组,用 1 填充。
empty():返回给定形状和类型的未初始化的新数组。
zeros_like():返回与给定数组具有相同形状和类型的 0 新数组。
ones_like():返回与给定数组具有相同形状和类型的 1 新数组。
empty_like():返回与给定数组具有相同形状和类型的未初始化的新数组。
3、full()、 full_like()
full():返回给定形状和类型的新数组,用指定的值填充。
full_like():返回与给定数组具有相同形状和类型的用指定值填充的新数组。
4、arange()
arange():返回在给定范围内用均匀间隔的值填充的一维数组。
5、linspace()、logspace()
linspace():返回指定范围和元素个数的等差数列。数组元素类型为浮点型。
logspace():返回指定指数范围、元素个数、底数的等比数列。
6、创建随机数数组
random.rand():返回给定形状的数组,用 [0, 1) 上均匀分布的随机样本填充。
random.randint():返回给定形状的数组,用从低位(包含)到高位(不包含)上均匀分布的随机整数填充。
random.uniform():返回给定形状的数组,用从低位(包含)到高位(不包含)上均匀分布的随机浮点数填充。
random.randn():返回给定形状的数组,用标准正态分布(均值为 0,标准差为 1)的随机样本填充。
7、matrix()
matrix 为 ndarray 的子类,只能生成二维的矩阵。
8、ndarray 切片和索引
import numpy as nparr = np.arange(10)print(arr)[0 1 2 3 4 5 6 7 8 9]#获取索引为 2 的数据print(arr[2])2# 从索引 2 开始到索引 9(不包含)停止,间隔为 2print(arr[slice(2,9,2)])[2 4 6 8]# 从索引 2 开始到索引 9(不包含)停止,间隔为 2print(arr[2:9:2])[2 4 6 8]# 从索引 2 开始到最后(不包含),默认间隔为 1print(arr[2:])[2 3 4 5 6 7 8 9]# 从索引 2 开始到索引 9(不包含)结束,默认间隔为 1print(arr[2:9])[2 3 4 5 6 7 8]
9、numpy 常用函数
基本函数
| 函数 | 说明 |
|---|---|
| np.abs() | 元素的绝对值,参数是 number 或 array |
| np.ceil() | 向上取整,参数是 number 或 array |
| np.floor() | 向下取整,参数是 number 或 array |
| np.rint() | 四舍五入,参数是 number 或 array 四舍六入:当需要舍入的数字小于 5 时,直接舍去;当需要舍入的数字大于 5 时,进位。 五成双:当需要舍入的数字恰好是 5 时,会看 5 前面的数字,如果是偶数则直接舍去 5,如果是奇数则进位。 |
| np.isnan() | 判断元素是否为 NaN(Not a Number),参数是 number 或 array |
| np.multiply() | 元素相乘,参数是 number 或 array。如果第二个参数传递的是 number,原数组中所有元素乘以这个数字,返回新的数组;如果第二个参数也是一个数组,是将两个数组中对应位置的元素相乘,返回一个新的数组,其形状与输入数组相同。 |
| np.divide() | 元素相除,参数是 number 或 array |
| np.where(condition, x, y) | 三元运算符,x if condition else y |
统计函数
| 函数 | 说明 |
|---|---|
| np.mean() | 所有元素的平均值 |
| np.sum() | 所有元素的和 |
| np.max() | 所有元素的最大值 |
| np.min() | 所有元素的最小值 |
| np.std() | 所有元素的标准差 |
| np.var() | 所有元素的方差 |
| np.argmax() | 最大值的下标索引值 |
| np.argmin() | 最小值的下标索引值 |
| np.cumsum() | 返回一个一维数组,每个元素都是之前所有元素的累加和 |
| np.cumprod() | 返回一个一维数组,每个元素都是之前所有元素的累乘积 |
比较函数
| 函数 | 说明 |
|---|---|
| np.any() | 至少有一个元素满足指定条件,就返回 True |
| np.all() | 所有的元素都满足指定条件,才返回 True |
排序函数
ndarray.sort()**:**就地排序(直接修改原数组)
np.sort()**:**返回排序后的副本(创建新的数组)
去重函数
np.unique()**:**计算唯一值并返回有序结果。
10、矩阵乘法
通过*运算符和 np.multiply()对两个数组相乘进行的是对位乘法而非矩阵乘法运算
arr1 = np.array([[1, 2, 3], [4, 5, 6]])arr2 = np.array([[6, 5, 4], [3, 2, 1]])print(arr1 * arr2)[[ 6 10 12] [12 10 6]]print(np.multiply(arr1, arr2))[[ 6 10 12] [12 10 6]]
使用 np.dot()、ndarray.dot()、@可以进行矩阵乘法运算
arr1 = np.array([[1, 2, 3], [4, 5, 6]])arr2 = np.array([[6, 5], [4, 3], [2, 1]])#对于矩阵乘法来说,要求第一个矩阵的列数等于第二个矩阵的行数#结果矩阵第一行第一列:1*6 + 2*4 + 3*2 = 20#结果矩阵第一行第二列:1*5 + 2*3 + 3*1 = 14#结果矩阵第二行第一列:4*6 + 5*4 + 6*2 = 56#结果矩阵第二行第二列:4*5 + 5*3 + 6*1 = 41print(np.dot(arr1, arr2))[[20 14] [56 41]]print(arr1.dot(arr2))[[20 14] [56 41]]print(arr1 @ arr2)[[20 14] [56 41]]# 一个二维数组跟一个大小合适的一维数组的矩阵点积运算之后将会得到一个一维数组arr3 = np.array([6, 5, 4])print(arr1 @ arr3)[28 73]
Pandas
Pandas 是一个开源的数据分析和数据处理库,它是基于 Python 编程语言的。
用得最多的 pandas 对象是 Series,一个一维的标签化数组对象,另一个是 DataFrame,它是一个面向列的二维表结构。
Series
1、创建
通过列表创建series:
pd.Series([4, 7, -5, 3])
通过列表创建 Series 时指定索引:
pd.Series([4, 7, -5, 3], index=[“a”, “b”, “c”, “d”])
通过列表创建 Series 时指定索引和名称:
pd.Series([4, 7, -5, 3], index=[“a”, “b”, “c”, “d”],name=“hello_python”)
通过字典创建 Series:
pd.Series({“a”: 4, “b”: 7, “c”: -5, “d”: 3})
2、Series 的常用属性
| 属性 | 说明 |
|---|---|
| index | Series 的索引对象 |
| values | Series 的值 |
| ndim | Series 的维度 |
| shape | Series 的形状 |
| size | Series 的元素个数 |
| dtype 或 dtypes | Series 的元素类型 |
| name | Series 的名称 |
| loc[] | 显式索引,按标签索引或切片 |
| iloc[] | 隐式索引,按位置索引或切片 |
| at[] | 使用标签访问单个元素 |
| iat[] | 使用位置访问单个元素 |
3、Series 的常用方法
| 方法 | 说明 |
|---|---|
| head() | 查看前 n 行数据,默认 5 行 |
| tail() | 查看后 n 行数据,默认 5 行 |
| isin() | 元素是否包含在参数集合中 |
| isna() | 元素是否为缺失值(通常为 NaN 或 None) |
| sum() | 求和,会忽略 Series 中的缺失值 |
| mean() | 平均值 |
| min() | 最小值 |
| max() | 最大值 |
| var() | 方差 |
| std() | 标准差 |
| median() | 中位数 |
| mode() | 众数(出现频率最高的值),如果有多个值出现的频率相同且都是最高频率,这些值都会被包含在返回的 Series 中 |
| quantile(q, interpolation) | 指定位置的分位数 q 的取值范围是 0 到 1 之间的浮点数或浮点数列表,如 quantile(0.5) 表示计算中位数(即第 50 百分位数); interpolation:指定在计算分位数时,如果分位数位置不在数据点上,采用的插值方法。默认值是线性插值 ‘linear’,还有其他 可选值如 ‘lower’、‘higher’、‘midpoint’、‘nearest’ 等 |
| describe() | 常见统计信息 |
| value_count() | 每个元素的个数 |
| count() | 非缺失值元素的个数,如果要包含缺失值,用 len() |
| drop_duplicates() | 去重 |
| unique() | 去重后的数组 |
| nunique() | 去重后元素个数 |
| sample() | 随机采样 |
| sort_index() | 按索引排序 |
| sort_values() | 按值排序 |
| replace() | 用指定值代替原有值 |
| to_frame() | 将 Series 转换为 DataFrame |
| equals() | 判断两个 Series 是否相同 |
| keys() | 返回 Series 的索引对象 |
| corr() | 计算与另一个 Series 的相关系数 默认使用皮尔逊相关系数(Pearson correlation coefficient)来计算相关性。要求参与比较的数组元素类型都是数值型。 当相关系数为 1 时,表示两个变量完全正相关,即一个变量增加,另一个变量也随之增加。 当相关系数为 -1 时,表示两个变量完全负相关,即一个变量增加,另一个变量随之减少。 当相关系数为 0 时,表示两个变量之间不存在线性相关性。 例如,分析某地区的气温和冰淇淋销量之间的关系 |
| cov() | 计算与另一个 Series 的协方差 |
| hist() | 绘制直方图,用于展示数据的分布情况。它将数据划分为若干个区间(也称为“bins”),并统计每个区间内数据的频数。 需要安装 matplotlib 包 |
| items() | 获取索引名以及值 |
DataFrame
1、创建
通过字典创建 DataFrame:pd.DataFrame({“id”: [101, 102, 103], “name”: [“张三”, “李四”, “王五”], “age”: [20, 30, 40]})
通过字典创建时指定列的顺序和行索引:pd.DataFrame(data={“age”: [20, 30, 40], “name”: [“张三”, “李四”, “王五”]}, columns=[“name”, “age”], index=[101, 102, 103]
2、DataFrame 的常用属性
| 属性 | 说明 |
|---|---|
| index | DataFrame 的行索引 |
| columns | DataFrame 的列标签 |
| values | DataFrame 的值 |
| ndim | DataFrame 的维度 |
| shape | DataFrame 的形状 |
| size | DataFrame 的元素个数 |
| dtypes | DataFrame 的元素类型 |
| T | 行列转置 |
| loc[] | 显式索引,按行列标签索引或切片 |
| iloc[] | 隐式索引,按行列位置索引或切片 |
| at[] | 使用行列标签访问单个元素 |
| iat[] | 使用行列位置访问单个元素 |
3、DataFrame 的常用方法
| 方法 | 说明 |
|---|---|
| head() | 查看前 n 行数据,默认 5 行 |
| tail() | 查看后 n 行数据,默认 5 行 |
| isin() | 元素是否包含在参数集合中 |
| isna() | 元素是否为缺失值 |
| sum() | 求和 |
| mean() | 平均值 |
| min() | 最小值 |
| max() | 最大值 |
| var() | 方差 |
| std() | 标准差 |
| median() | 中位数 |
| mode() | 众数 |
| quantile() | 指定位置的分位数,如 quantile(0.5) |
| describe() | 常见统计信息 |
| info() | 基本信息 |
| value_counts() | 每个元素的个数 |
| count() | 非空元素的个数 |
| drop_duplicates() | 去重 |
| sample() | 随机采样 |
| replace() | 用指定值代替原有值 |
| equals() | 判断两个 DataFrame 是否相同 |
| cummax() | 累计最大值 |
| cummin() | 累计最小值 |
| cumsum() | 累计和 |
| cumprod() | 累计积 |
| diff() | 一阶差分,对序列中的元素进行差分运算,也就是用当前元素减去前一个元素得到差值,默认情况下,它会计算一阶差分,即相邻元素之间的差值。参数: periods:整数,默认为 1。表示要向前或向后移动的周期数,用于计算差值。正数表示向前移动,负数表示向后移动。 axis:指定计算的轴方向。0 或 ‘index’ 表示按列计算,1 或 ‘columns’ 表示按行计算,默认值为 0。 |
| sort_index() | 按行索引排序 |
| sort_values() | 按某列的值排序,可传入列表来按多列排序,并通过 ascending 参数设置升序或降序 |
| nlargest() | 返回某列最大的 n 条数据 |
| nsmallest() | 返回某列最小的 n 条数据 |
4、DataFrame 数据的导入与导出
导出数据
| 方法 | 说明 |
|---|---|
| to_csv() | 将数据保存为 csv 格式文件,数据之间以逗号分隔,可通过 sep参数设置使用其他分隔符,可通过 index 参数设置是否保存行标签,可通过 header 参数设置是否保存列标签 |
| to_pickle() | 如要保存的对象是计算的中间结果,或者保存的对象以后会在 Python 中复用,可把对象保存为 .pickle 文件。如果保存成 pickle 文件,只能在 python 中使用。文件的扩展名可以是 .p、.pkl、.pickle。 |
| to_excel() | 保存为 Excel 文件,需安装 openpyxl 包。 |
| to_clipboard() | 保存到剪切板。 |
| to_dict() | 保存为字典。 |
| to_hdf() | 保存为 HDF 格式,需安装 tables 包。 |
| to_html() | 保存为 HTML 格式,需安装 lxml、html5lib、beautifulsoup4 包。 |
| to_json() | 保存为 JSON 格式。 |
| to_feather() | feather 是一种文件格式,用于存储二进制对象。feather 对象也可以加载到 R 语言中使用。feather 格式的主要优点是在 Python 和 R 语言之间的读写速度要比 csv 文件快。feather 数据格式通常只用中间数据格式,用于 Python 和 R 之间传递数据,一般不用做保存最终数据。需安装 pyarrow 包。 |
| to_sql() | 保存到数据库。 |
导入数据
| 方法 | 说明 |
|---|---|
| read_csv() | 加载 csv 格式的数据。可通过 sep 参数指定分隔符,可通过 index_col 参数指定行索引。 |
| read_pickle() | 加载 pickle 格式的数据。 |
| read_excel() | 加载 Excel 格式的数据。 |
| read_clipboard() | 加载剪切板中的数据。 |
| read_hdf() | 加载 HDF 格式的数据。 |
| read_html() | 加载 HTML 格式的数据。 |
| read_json() | 加载 JSON 格式的数据。 |
| read_feather() | 加载 feather 格式的数据。 |
| read_sql() | 加载数据库中的数据。 |
Padas 的数据组合函数
**concat 连接:**沿着一条轴将多个对象堆叠到一起,可通过 axis 参数设置沿哪一条轴连接。
**merge 合并:**通过一个或多个列将行连接。
Padas 的缺失值处理函数
pandas 使用浮点值 NaN(Not a Number)表示缺失数据,使用 NA(Not Available)表示缺失值。可以通过 isnull()、isna()或 notnull()、notna()方法判断某个值是否为缺失值。
Padas 的 apply 函数
apply()函数可以对 DataFrame 或 Series 的数据进行逐行、逐列或逐元素的操作。可以使用自定义函数对数据进行变换、计算或处理,通常用于处理复杂的变换逻辑,或者处理不能通过向量化操作轻松完成的任务。
Pandas 透视表
pandas 中提供了 DataFrame.pivot_table()和 pandas.pivot_table()方法来生成透视表。两者的区别是 pandas.pivot_table()需要额外传入一个 data 参数指定对哪个 DataFrame 进行处理。
pivot_table()的参数如下:
| 参数 | 说明 |
|---|---|
| values | 待聚合的列,默认聚合所有数值列。 |
| index | 用作透视表行索引的列。即通过哪个(些)行来对数据进行分组,行索引决定了透视表的行维度 |
| columns | 用作透视表列索引的列。即通过哪个(些)列来对数据进行分组。组,列索引决定了透视表的列维度。 |
| aggfunc | 聚合函数或函数列表,默认为 mean。 |
| fill_value | 用于替换结果表中的缺失值。 |
| margins | 是否在透视表的边缘添加汇总行和列,显示总计。默认值是 False,如果设置为 True,会添加 “总计” 行和列,方便查看数据的总体汇总。 |
| dropna | 是否排除包含缺失值的行和列。默认为 True,即如果某个组合的行列数据中包含缺失值,则会被排除在外。如果设置为 False,则会保留这些含有缺失值的行和列。 |
| observed | 是否显示所有组合数据,True: 只显示实际存在的组合 |
Matplotlib可视化
Matplotlib 是一个 Python 绘图库,广泛用于创建各种类型的静态、动态和交互式图表。它是数据科学、机器学习、工程和科学计算领域中常用的绘图工具之一。
➢ 支持多种图表类型:折线图(Line plots)、散点图(Scatter plots)、柱状图(Bar charts)、直方图(Histograms)、饼图(Pie charts)、热图(Heatmaps)、箱型图(Box plots)、极坐标图(Polar plots)、3D 图(3D plots,配合 mpl_toolkits.mplot3d)。
➢ 高度自定义:允许用户自定义图表的每个部分,包括标题、轴标签、刻度、图例等。 支持多种颜色、字体和线条样式。提供精确的图形渲染控制,如坐标轴范围、图形大小、字体大小等。
➢ 兼容性:与 NumPy、Pandas 等库紧密集成,特别适用于绘制基于数据框和数组的数据可视化。可以输出到多种格式(如 PNG、PDF、SVG、EPS 等)。
➢ 交互式绘图:在 Jupyter Notebook 中,Matplotlib 支持交互式绘图,可以动态更新图表。支持图形缩放、平移等交互操作。
➢ 动态图表:可以生成动画(使用 FuncAnimation 类),为用户提供动态数据的可视化。
Pandas 可视化
pandas 提供了非常方便的绘图功能,可以直接在 DataFrame 或 Series 上调用 plot()方法来生成各种类型的图表。底层实现依赖于 Matplotlib,pandas 的绘图功能集成了许多常见的图形类型,易于使用。
Seaborn 可视化
Seaborn 是一个基于 Matplotlib 的 Python 可视化库,旨在简化数据可视化的过程。它提供了更高级的接口,用于生成漂亮和复杂的统计图表,同时也能保持与 Pandas 数据结构的良好兼容性。
说真的,这两年看着身边一个个搞Java、C++、前端、数据、架构的开始卷大模型,挺唏嘘的。大家最开始都是写接口、搞Spring Boot、连数据库、配Redis,稳稳当当过日子。
结果GPT、DeepSeek火了之后,整条线上的人都开始有点慌了,大家都在想:“我是不是要学大模型,不然这饭碗还能保多久?”
我先给出最直接的答案:一定要把现有的技术和大模型结合起来,而不是抛弃你们现有技术!掌握AI能力的Java工程师比纯Java岗要吃香的多。
即使现在裁员、降薪、团队解散的比比皆是……但后续的趋势一定是AI应用落地!大模型方向才是实现职业升级、提升薪资待遇的绝佳机遇!
这绝非空谈。数据说话
2025年的最后一个月,脉脉高聘发布了《2025年度人才迁徙报告》,披露了2025年前10个月的招聘市场现状。
AI领域的人才需求呈现出极为迫切的“井喷”态势
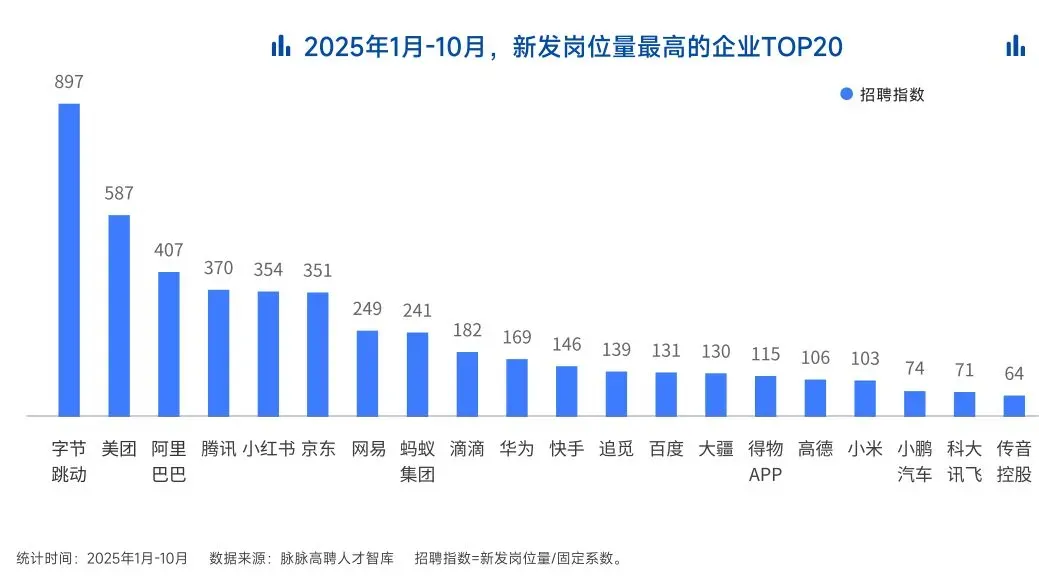
2025年前10个月,新发AI岗位量同比增长543%,9月单月同比增幅超11倍。同时,在薪资方面,AI领域也显著领先。其中,月薪排名前20的高薪岗位平均月薪均超过6万元,而这些席位大部分被AI研发岗占据。
与此相对应,市场为AI人才支付了显著的溢价:算法工程师中,专攻AIGC方向的岗位平均薪资较普通算法工程师高出近18%;产品经理岗位中,AI方向的产品经理薪资也领先约20%。
当你意识到“技术+AI”是个人突围的最佳路径时,整个就业市场的数据也印证了同一个事实:AI大模型正成为高薪机会的最大源头。
最后
我在一线科技企业深耕十二载,见证过太多因技术卡位而跃迁的案例。那些率先拥抱 AI 的同事,早已在效率与薪资上形成代际优势,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在大模型的学习中的很多困惑。
我整理出这套 AI 大模型突围资料包【允许白嫖】:
- ✅从入门到精通的全套视频教程
- ✅AI大模型学习路线图(0基础到项目实战仅需90天)
- ✅大模型书籍与技术文档PDF
- ✅各大厂大模型面试题目详解
- ✅640套AI大模型报告合集
- ✅大模型入门实战训练
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

①从入门到精通的全套视频教程
包含提示词工程、RAG、Agent等技术点

② AI大模型学习路线图(0基础到项目实战仅需90天)
全过程AI大模型学习路线
③学习电子书籍和技术文档
市面上的大模型书籍确实太多了,这些是我精选出来的

④各大厂大模型面试题目详解

⑤640套AI大模型报告合集

⑥大模型入门实战训练

👉获取方式:
有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

更多推荐

 10
10 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)