
强化学习的数学原理 —— 策略迭代(Policy Iteration)算法推导与 Python 从零实现【附源码】
一、前言
上一篇文章【强化学习的数学原理 —— 值迭代(Value Iteration)算法推导与 Python 从零实现【附源码】】介绍了 值迭代(Value Iteration) 的 Python 代码实现。本篇博文继续基于赵世钰老师《强化学习的数学原理》课程的网格世界例子,从零实现 策略迭代(Policy Iteration) 算法。
二、问题建模
为了方便读者阅读,本节将再次介绍问题有关背景。如已知悉,可跳过本节。
2.1 问题背景
在如图 2.1 所示的 网格世界(grid world) 中,智能体(agent) 需要从一个初始区域出发,最终到达目标区域。其中,白色单元格代表可以进入的区域,黄色单元格代表禁止进入的区域,蓝色单元格代表目标区域。
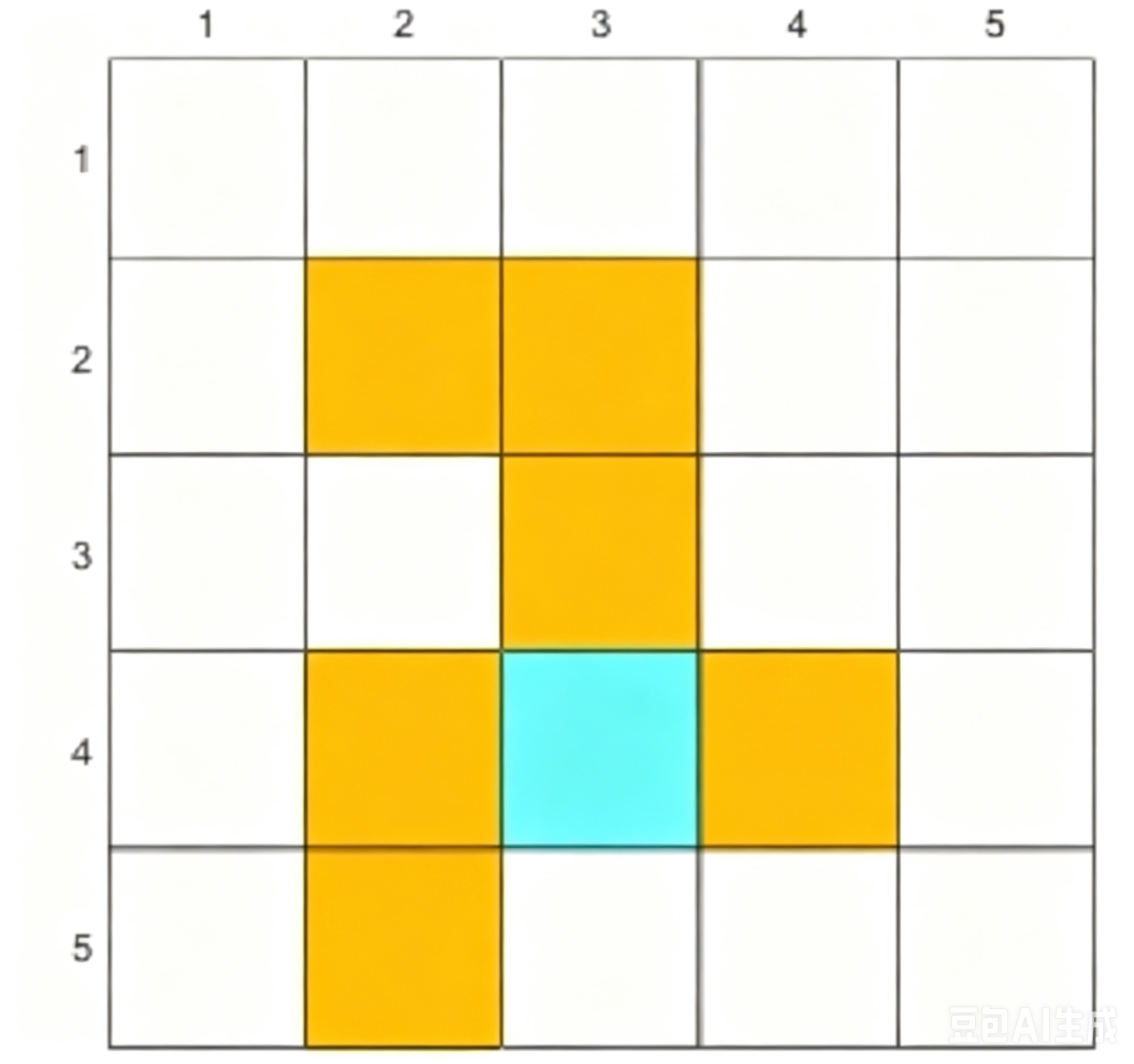
图 2.1 5×5 网格世界:出自赵世钰《强化学习的数学原理》
2.2 状态和动作空间
状态对应智能体所在单元格的位置,如图 2.1 中共有从左上到右下 25 个状态,表示为状态空间(state space) S = { s 1 , s 2 , … , s 25 } \mathcal{S} = \{s_1,s_2,\dots , s_{25}\} S={s1,s2,…,s25}。
在网格世界中,智能体在每一个状态有 5 个可选的动作:向上移动、向右移动、向下移动、向左移动、保持不动。所有动作的集合被称为动作空间(action space) A = { a 1 , a 2 , … , a 5 } \mathcal{A} = \{a_1,a_2,\dots , a_5\} A={a1,a2,…,a5},具体如图 2.2 所示。
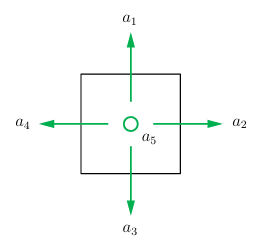
图 2.2 动作空间:出自赵世钰《强化学习的数学原理》原图 1.3 (b)
2.3 奖励
在一个状态执行一个动作后,智能体会得到奖励(reward) ,可以写成 r ( s , a ) r(s,a) r(s,a)。一般来说,正的奖励表示我们鼓励智能体采取相应的动作;负的奖励表示我们不鼓励智能体采取该动作。在图 2.1 的网格世界中,我们设置如下奖励:
- 如果智能体越过四周边界,设 r b o u n d a r y = − 1 r_{boundary}=-1 rboundary=−1;
- 如果智能体试图进入禁止区域,设 r f r o b i d d e n = − 10 r_{frobidden}=-10 rfrobidden=−10;
- 如果智能体到达了目标区域,设 r t a r g e t = + 1 r_{target}=+1 rtarget=+1;
- 在其他情况下,智能体获得的奖励为 r o t h e r = 0 r_{other}=0 rother=0。
三、策略迭代算法
3.1 数学原理
策略迭代算法的第 k k k 次迭代包含 策略评价(policy evaluation) 和 策略改进(policy improvement) 两个步骤,具体如下所述。
-
策略评价:该步骤用来评估上一次迭代得到的策略 π k \pi_k πk 。通过求解下面的贝尔曼方程,从而得到 π k \pi_k πk 的状态值(state value)。
v π k = r π k + γ P π k v π k v_{\pi_k}=r_{\pi_k}+\gamma P_{\pi_k}v_{\pi_k} vπk=rπk+γPπkvπk
采用数值迭代算法,将上式展开,得到:
v π k ( j + 1 ) ( s ) = ∑ a π k ( a ∣ s ) ( ∑ r p ( r ∣ s , a ) r + γ ∑ s ′ p ( s ′ ∣ s , a ) v π k ( j ) ( s ′ ) ) , s ∈ S v_{\pi_k}^{(j+1)}(s)=\sum_a\pi_k(a|s)\left(\sum_rp(r|s,a)r+\gamma\sum_{s'}p(s'|s,a)v_{\pi_k}^{(j)}(s')\right), \quad s \in \mathcal{S} vπk(j+1)(s)=a∑πk(a∣s)(r∑p(r∣s,a)r+γs′∑p(s′∣s,a)vπk(j)(s′)),s∈S -
策略改进:该步骤用来改进策略从而得到更好的新策略。在第一步得到 v π k v_{\pi_k} vπk 之后,利用下式得到新的策略 π k + 1 \pi_{k+1} πk+1 :
π k + 1 = arg max π ( r π + γ P π v π k ) \pi_{k+1}=\arg \max_{\pi}(r_{\pi}+\gamma P_{\pi}v_{\pi_k}) πk+1=argπmax(rπ+γPπvπk)
该式的元素展开形式为
π k + 1 ( s ) = arg max π ∑ a π ( a ∣ s ) ( ∑ r p ( r ∣ s , a ) r + γ ∑ s ′ p ( s ′ ∣ s , a ) v π k ( s ′ ) ) ⏟ q π k ( s , a ) , s ∈ S \pi_{k+1}(s) = \arg \max_{\pi} \sum_{a} \pi(a|s) \underbrace{\left( \sum_{r} p(r|s,a)r + \gamma \sum_{s'} p(s'|s,a)v_{\pi_k}(s') \right)}_{q_{\pi_k}(s,a)}, \quad s \in \mathcal{S} πk+1(s)=argπmaxa∑π(a∣s)qπk(s,a) (r∑p(r∣s,a)r+γs′∑p(s′∣s,a)vπk(s′)),s∈S
其中 q π k ( s , a ) q_{\pi_k}(s,a) qπk(s,a) 是策略 π k \pi_k πk 对应的动作值。令 a k ∗ ( s ) = arg max a q π k ( s , a ) a_k^*(s)=\arg \max_a q_{\pi_k}(s,a) ak∗(s)=argmaxaqπk(s,a) 为最大值动作,那么上述优化问题的解是
π k + 1 ( a ∣ s ) = { 1 a = a k ∗ ( s ) 0 a ≠ a k ∗ ( s ) \pi_{k+1}(a|s)= \begin{cases} 1 & a = a_k^{*}(s)\\ 0 & a \neq a_k^{*}(s) \end{cases} πk+1(a∣s)={10a=ak∗(s)a=ak∗(s)
策略迭代算法可行是因为它能收敛到最优策略。这里给出 定理:由策略迭代算法生成的状态值序列 { v π k } k = 0 ∞ \{v_{\pi_k}\}_{k=0}^\infty {vπk}k=0∞ 收敛于最优状态值 v ∗ v^* v∗ 。因此,策略序列 { π k } k = 0 ∞ \{\pi_k\}_{k=0}^\infty {πk}k=0∞ 收敛于一个最优策略。 证明如下:

3.2 伪代码
总结上述数学原理,该算法的伪代码如图 3.1 所示:

图 3.1 策略迭代伪代码:出自赵世钰《强化学习的数学原理》原算法 4.2
四、Python 代码实现
整套代码开发思路分成:环境定义、交互逻辑、可视化、策略迭代算法四部分,本篇挑选决定算法逻辑的三个核心函数细说,绘图工具类代码不再拆分讲解,最后附上完整源码方便读者一键运行。
4.1 get_reward 函数
get_reward 用来判定当前格子的即时奖励,对照奖励规则:到达目标 + 1、踏入禁区 - 10、普通格子收益 0。
def get_reward(state):
if state == TARGET_STATE:
return R_TARGET
if state in FORBIDDEN_STATES:
return R_FORBIDDEN
return R_NORMAL
4.2 step 函数
step 是智能体执行动作后的状态转移规则,整个网格世界使用 5×5 矩阵表示,i 为行,j 为列。
def step(state, action):
i, j = state
di, dj = action
ni, nj = i + di, j + dj
if ni < 0 or ni >= GRID_SIZE or nj < 0 or nj >= GRID_SIZE:
return (i, j), R_BOUNDARY
next_state = (ni, nj)
return next_state, get_reward(next_state)
- 向网格外侧移动算作越界,原地停留并扣除边界惩罚 -1;
- 在网格内正常移动,落地后调用
get_reward获取对应奖励。
4.3 策略迭代主体算法
def policy_iteration_with_plot():
V = np.zeros((GRID_SIZE, GRID_SIZE))
policy = np.zeros((GRID_SIZE, GRID_SIZE), dtype=int) * 4
iter_cnt = 0
while True:
# 保存本轮迭代开始前的V(上一轮最终价值V_πk)
V_old = np.copy(V)
# ==========内层:策略评估(固定policy,V收敛)==========
while True:
delta = 0
V_new = np.copy(V)
for i in range(GRID_SIZE):
for j in range(GRID_SIZE):
aid = policy[i, j]
a = ACTIONS[aid]
ns, r = step((i, j), a)
ni, nj = ns
v_new = r + GAMMA * V[ni, nj]
delta = max(delta, abs(v_new - V[i, j]))
V_new[i, j] = v_new
V = V_new
if delta < THETA:
break
# ==========策略改进:贪心更新policy==========
for i in range(GRID_SIZE):
for j in range(GRID_SIZE):
qs = []
for a in ACTIONS:
ns, r = step((i, j), a)
ni, nj = ns
q = r + GAMMA * V[ni, nj]
qs.append(q)
best_idx = np.argmax(qs)
policy[i, j] = best_idx
iter_cnt += 1
# =====外层终止条件:本轮V和上一轮V最大差值<THETA =====
outer_delta = np.max(np.abs(V - V_old))
if outer_delta < THETA:
break
return V, policy
- 外层循环整体拆成两步:策略评估 + 策略改进,交替循环迭代;
- 策略评估阶段:固定当前策略不动,逐个遍历全部网格状态,每个格子只执行当前策略规定的单个动作,依靠贝尔曼期望方程反复迭代更新状态价值,用 delta 记录单次评估内价值最大变动,直至 delta 小于阈值,算出这套策略对应的精准 V π V_\pi Vπ ;
- 策略改进阶段:依托收敛完毕的 V V V ,逐个遍历所有状态,遍历全部可选动作求解每个动作 Q Q Q 值,通过 arg max \argmax argmax 贪心选取 Q Q Q 最大的动作,替换为当前格子新策略;
- 每完成一轮「评估 + 改进」,对比本轮整体 V V V 与上一轮保存的旧 V V V,全局价值最大变化小于阈值时,判定算法整体收敛,终止迭代。
4.4 完整源码
import os
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.patches import Rectangle, Circle
# ===================== 超参数与环境配置【全局常量】 =====================
GRID_SIZE = 5
GAMMA = 0.9
THETA = 1e-6
# 奖励设置
R_TARGET = 1
R_FORBIDDEN = -10
R_BOUNDARY = -1
R_NORMAL = 0
# 动作:上、右、下、左、原地不动
ACTIONS = [(0, 0), (-1, 0), (0, 1), (1, 0), (0, -1)]
# 地图设置
FORBIDDEN_STATES = [(1, 1), (1, 2), (2, 2), (3, 1), (3, 3), (4, 1)]
TARGET_STATE = (3, 2)
# 图片保存在代码同级目录
SAVE_IMG = False
IMG_FOLDER = "Policy Iteration/iter_img"
if SAVE_IMG and not os.path.exists(IMG_FOLDER):
os.mkdir(IMG_FOLDER)
# ===================== 环境交互函数 =====================
def get_reward(state):
if state == TARGET_STATE:
return R_TARGET
if state in FORBIDDEN_STATES:
return R_FORBIDDEN
return R_NORMAL
def step(state, action):
i, j = state
di, dj = action
ni, nj = i + di, j + dj
if ni < 0 or ni >= GRID_SIZE or nj < 0 or nj >= GRID_SIZE:
return (i, j), R_BOUNDARY
next_state = (ni, nj)
return next_state, get_reward(next_state)
# ===================== 绘图函数 =====================
def plot_policy(policy, ax):
ax.set_xlim(0, GRID_SIZE)
ax.set_ylim(0, GRID_SIZE)
ax.invert_yaxis()
ax.set_xticks(range(GRID_SIZE))
ax.set_yticks(range(GRID_SIZE))
ax.grid(True, color='black', linewidth=1)
ax.set_title('Optimal Policy', fontsize=12)
for i in range(GRID_SIZE):
for j in range(GRID_SIZE):
rect = Rectangle((j, i), 1, 1, ec='black', lw=1)
ax.add_patch(rect)
if (i, j) in FORBIDDEN_STATES:
rect.set_facecolor('gold')
elif (i, j) == TARGET_STATE:
rect.set_facecolor('cornflowerblue')
else:
rect.set_facecolor('white')
arrow_scale = 0.3
circle_r = 0.15
for i in range(GRID_SIZE):
for j in range(GRID_SIZE):
act_idx = policy[i, j]
xc, yc = j + 0.5, i + 0.5
dx, dy = 0, 0
if act_idx == 1:
dy = -arrow_scale
elif act_idx == 2:
dx = arrow_scale
elif act_idx == 3:
dy = arrow_scale
elif act_idx == 4:
dx = -arrow_scale
elif act_idx == 0:
circ = Circle((xc, yc), circle_r, color='red', fill=False, lw=2)
ax.add_patch(circ)
continue
ax.arrow(xc, yc, dx, dy, head_width=0.12, head_length=0.12, fc='red', ec='red')
def plot_value(V, ax):
im = ax.imshow(V, cmap='coolwarm', origin='upper')
ax.set_xticks(range(GRID_SIZE))
ax.set_yticks(range(GRID_SIZE))
ax.set_title('State Value V(s)', fontsize=12)
for i in range(GRID_SIZE):
for j in range(GRID_SIZE):
ax.text(j, i, f'{V[i, j]:.2f}', ha='center', va='center', fontweight='bold')
return im
def draw_and_save(V, policy, iter_num, save_flag):
plt.figure(figsize=(12, 5))
ax1 = plt.subplot(1, 2, 1)
plot_policy(policy, ax1)
ax2 = plt.subplot(1, 2, 2)
im = plot_value(V, ax2)
plt.colorbar(im, ax=ax2, fraction=0.046, pad=0.04)
plt.suptitle(f'Policy Iteration: {iter_num}', fontsize=14)
plt.tight_layout()
if save_flag:
save_path = os.path.join(IMG_FOLDER, f"iter_{iter_num:04d}.png")
plt.savefig(save_path, dpi=150)
plt.close()
else:
plt.show()
# ===================== 策略迭代核心算法 =====================
def policy_iteration_with_plot():
V = np.zeros((GRID_SIZE, GRID_SIZE))
policy = np.zeros((GRID_SIZE, GRID_SIZE), dtype=int) * 4
iter_cnt = 0
while True:
# 保存本轮迭代开始前的V(上一轮最终价值V_πk)
V_old = np.copy(V)
# ==========内层:策略评估(固定policy,V收敛)==========
while True:
delta = 0
V_new = np.copy(V)
for i in range(GRID_SIZE):
for j in range(GRID_SIZE):
aid = policy[i, j]
a = ACTIONS[aid]
ns, r = step((i, j), a)
ni, nj = ns
v_new = r + GAMMA * V[ni, nj]
delta = max(delta, abs(v_new - V[i, j]))
V_new[i, j] = v_new
V = V_new
if delta < THETA:
break
if SAVE_IMG:
draw_and_save(V, policy, iter_cnt, save_flag=True)
# ==========策略改进:贪心更新policy==========
for i in range(GRID_SIZE):
for j in range(GRID_SIZE):
qs = []
for a in ACTIONS:
ns, r = step((i, j), a)
ni, nj = ns
q = r + GAMMA * V[ni, nj]
qs.append(q)
best_idx = np.argmax(qs)
policy[i, j] = best_idx
iter_cnt += 1
# =====外层终止条件:本轮V和上一轮V最大差值<THETA =====
outer_delta = np.max(np.abs(V - V_old))
if outer_delta < THETA:
break
if not SAVE_IMG:
draw_and_save(V, policy, iter_cnt-1, save_flag=False)
return V, policy
# ===================== 主函数 =====================
def main():
V_opt, policy_opt = policy_iteration_with_plot()
print("策略迭代完成!")
if __name__ == "__main__":
main()
另外,代码增加可视化控制:
SAVE_IMG = True自动保存每一轮迭代图片到\iter_img目录下,方便观察策略与价值的收敛变化;SAVE_IMG = False仅在算法收敛后弹出最终效果图,适合日常调试运行。
五、运行结果
初始状态,设定所有格子的初始策略都为保持原地不动,根据初始策略计算 V π 0 V_{\pi_0} Vπ0 ,策略及状态值如图 5.1 所示。
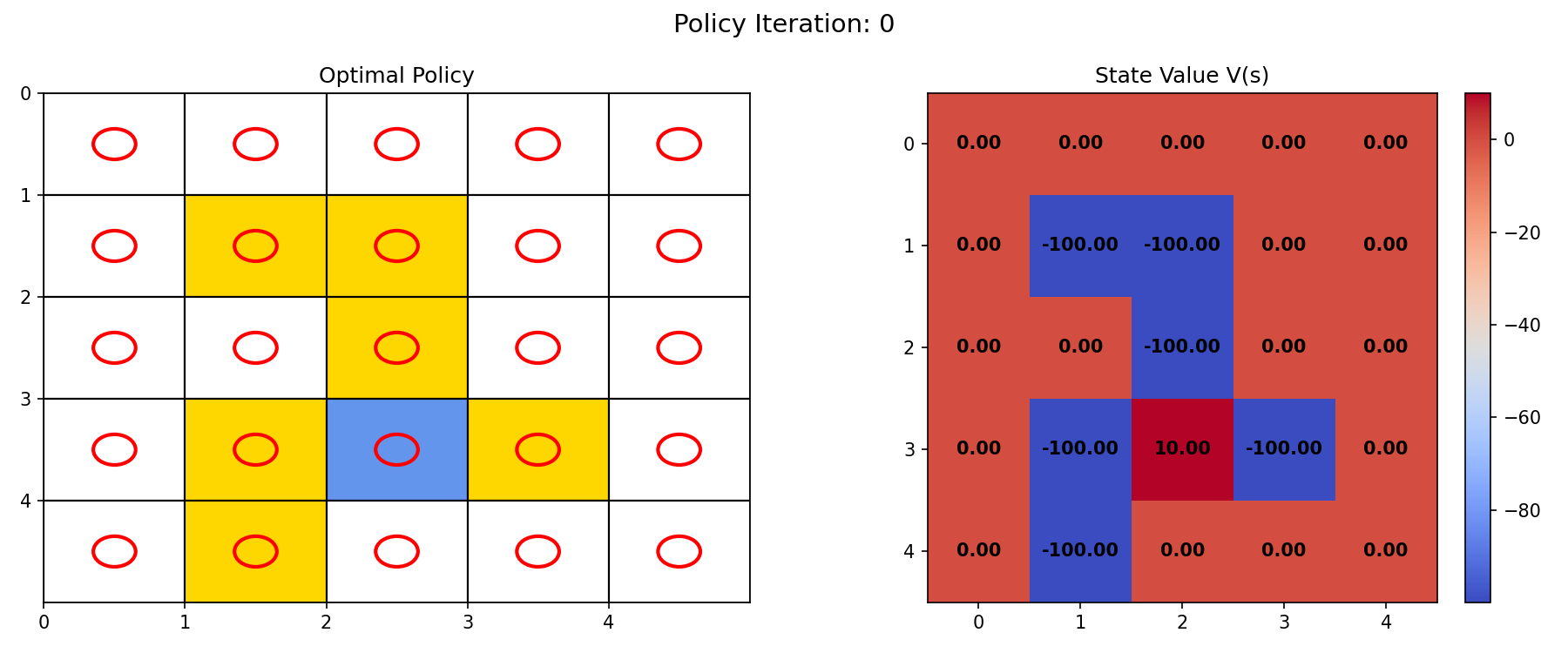
图 5.1 左:策略图;右:状态值图
第 1 轮迭代后,得到图 5.2 结果。可以看到禁区内的策略得到了很好的改善,但其它区域内的策略及 state value 仍不是很好。
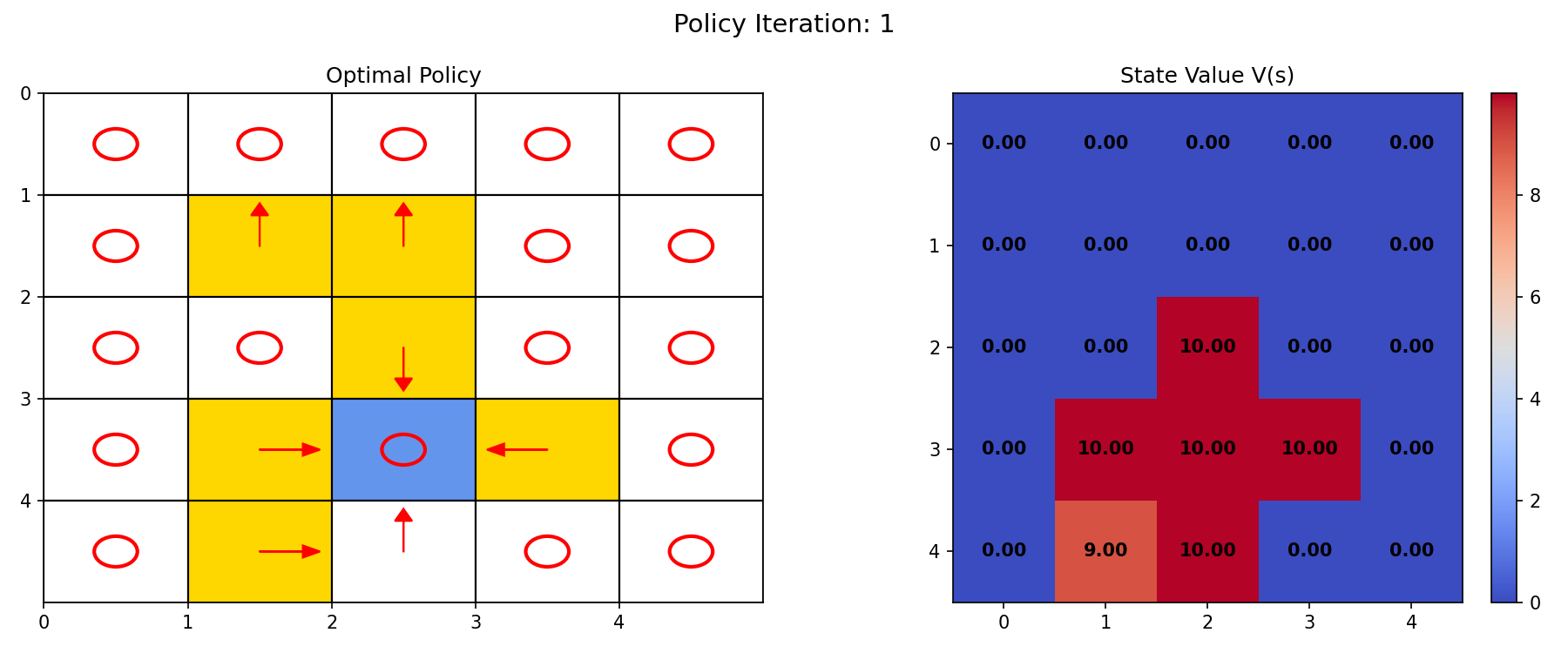
图 5.2 左:策略图;右:状态值图
第 2 轮迭代后,得到图 5.3 结果。可以看到最后一行第四列的格子,策略由原地不动变成了向左移动,策略得到提升。
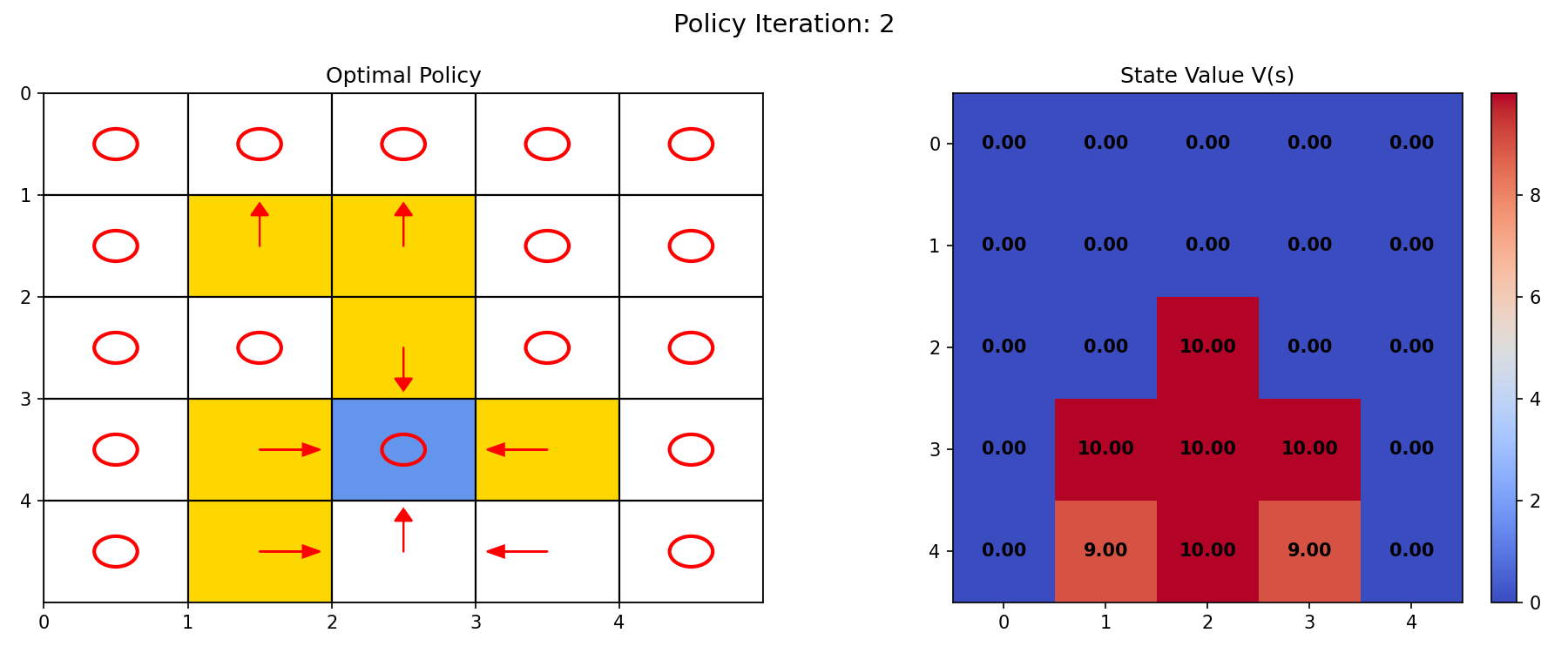
图 5.3 左:策略图;右:状态值图
按照上述过程,策略逐步提升。最终,经历 16 次迭代收敛后,得到最优策略及状态值热力图如图 5.4 所示。
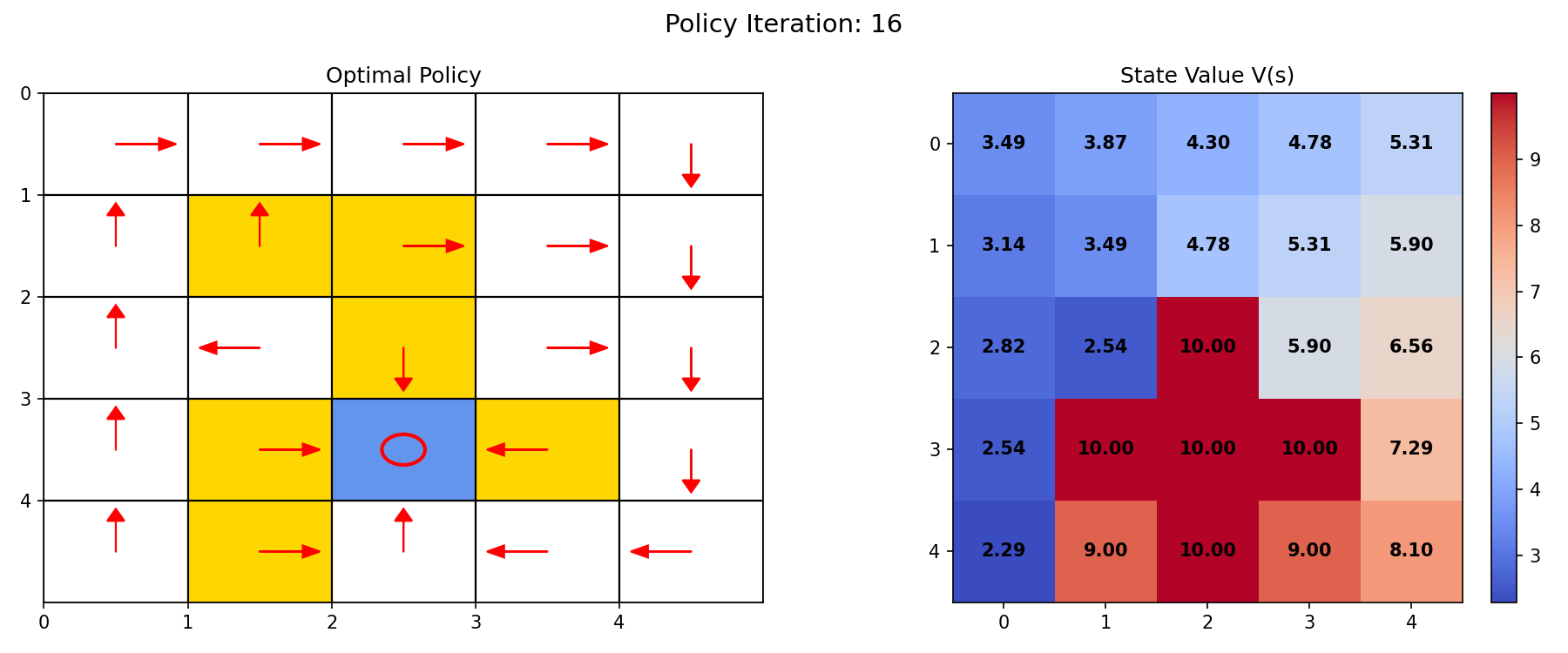
图 5.4 左:策略图;右:状态值图
六、其他说明
本篇博文重在代码实际实现,对于强化学习的基本概念和数学公式推导(如马尔可夫决策、贝尔曼方程等),还需读者自行查阅相关资料。这里附上赵世钰老师的b站讲解视频链接及Github,供读者参考。
更多推荐

 18
18 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)