
Numpy教程《Python for Data Analysis》
第4章 NumPy基础:数组与向量化计算
NumPy(Numerical Python的缩写)是Python数值计算最重要的基础包之一。许多提供科学计算功能的包都使用NumPy的数组对象作为数据交换的标准接口“通用语”。我所介绍的NumPy知识大多也能迁移到pandas中。
以下是NumPy的一些核心内容:
- ndarray:一种高效的多维数组,提供快速的面向数组的算术运算和灵活的广播(broadcasting)能力。
- 数学函数:无需编写循环即可对整个数据数组进行快速操作。
- 输入/输出工具:用于将数组数据读写到磁盘以及处理内存映射文件。
- 线性代数、随机数生成、傅里叶变换功能。
- C API:用于将NumPy与用C、C++或FORTRAN编写的库连接起来。
由于NumPy提供了完善且有详尽文档的C API,因此可以轻松地将数据传递给用低级语言编写的外部库,也可以让外部库以NumPy数组的形式将数据返回给Python。这一特性使Python成为封装遗留C、C++或FORTRAN代码库,并为其提供动态、易用接口的首选语言。
虽然NumPy本身并不提供建模或科学计算功能,但理解NumPy数组和面向数组的计算将帮助你更有效地使用具备数组计算语义的工具,比如pandas。由于NumPy是一个庞大的主题,我将在后文中更深入地介绍许多高级NumPy特性,例如广播(参见附录A:高级NumPy)。阅读本书其余部分并不需要掌握所有这些高级特性,但在你深入Python科学计算领域时,它们可能会给你带来帮助。
对于大多数数据分析应用,我将重点介绍以下几个核心功能领域:
- 用于数据清洗(munging/cleaning)、子集筛选(subsetting/filtering)、变换(transformation)及其他各类计算的快速基于数组的运算。
- 常用的数组算法,如排序(sorting)、唯一值(unique)和集合(set)运算。
- 高效的描述性统计与数据聚合/汇总。
- 数据对齐和用于合并、连接异构数据集的关系型数据操作。
- 使用数组表达式而非
if-elif-else分支和循环来表达条件逻辑。 - 分组数据操作(聚合、变换和函数应用)。
尽管NumPy为通用数值数据处理提供了计算基础,但许多读者会希望将pandas作为大多数统计或分析(尤其是表格数据)的基础。此外,pandas还提供了一些NumPy不具备的、更特定于领域的功能,如时间序列操作。
注意:Python中面向数组的计算可以追溯到1995年,当时Jim Hugunin创建了Numeric库。在接下来的十年里,许多科学编程社区开始在Python中进行数组编程,但库的生态系统在21世纪初变得碎片化。2005年,Travis Oliphant从当时的Numeric和Numarray项目整合出了NumPy项目,将社区团结在一个统一的数组计算框架周围。
NumPy之所以对Python数值计算如此重要,其中一个原因是它针对大规模数据数组的效率进行了设计。这背后有几个原因:
- NumPy在内存中连续存储数据,与Python内置对象相互独立。NumPy用C语言编写的算法库可以直接操作这片内存,无需任何类型检查或其他开销。NumPy数组也比Python内置序列占用的内存少得多。
- NumPy操作能够对整个数组执行复杂计算,而无需使用Python的
for循环。对于大型序列,Python循环往往很慢。NumPy比普通Python代码更快,因为它基于C的算法避免了普通解释型Python代码的开销。
为了让你对性能差异有个直观认识,下面比较一个包含一百万个整数的NumPy数组和等价的Python列表:
In [7]: import numpy as np
In [8]: my_arr = np.arange(1_000_000)
In [9]: my_list = list(range(1_000_000))
现在将每个序列乘以2:
In [10]: %timeit my_arr2 = my_arr * 2
309 us +- 7.48 us per loop (mean +- std. dev. of 7 runs, 1000 loops each)
In [11]: %timeit my_list2 = [x * 2 for x in my_list]
46.4 ms +- 526 us per loop (mean +- std. dev. of 7 runs, 10 loops each)
基于NumPy的算法通常比纯Python实现快10到100倍(甚至更多),并且使用的内存显著更少。
4.1 NumPy ndarray:多维数组对象
NumPy的核心特性之一是N维数组对象,即ndarray。它是一个快速、灵活的Python大型数据集容器。数组允许你使用与标量元素间操作相似的语法,对整个数据块进行数学运算。
为了展示NumPy如何以类似Python内置对象标量值的语法实现批量计算,我先导入NumPy并创建一个小型数组:
In [12]: import numpy as np
In [13]: data = np.array([[1.5, -0.1, 3], [0, -3, 6.5]])
In [14]: data
Out[14]:
array([[ 1.5, -0.1, 3. ],
[ 0. , -3. , 6.5]])
然后我写下针对 data 的数学运算:
In [15]: data * 10
Out[15]:
array([[ 15., -1., 30.],
[ 0., -30., 65.]])
In [16]: data + data
Out[16]:
array([[ 3. , -0.2, 6. ],
[ 0. , -6. , 13. ]])
在第一个示例中,所有元素都乘以了10。在第二个示例中,数组中每个“单元格”的对应值相加。
注意:在本章及整本书中,我遵循标准的NumPy约定,始终使用
import numpy as np。你可以在代码中使用from numpy import *来省去np.前缀,但我不建议养成这种习惯。numpy命名空间很大,包含许多与Python内置函数重名的函数(如min和max)。像这样遵循标准约定几乎总是个好主意。
ndarray是一个通用的多维同质数据容器;也就是说,所有元素必须是相同类型。每个数组都有一个 shape(形状,一个表示各维度大小的元组)和一个 dtype(数据类型,描述数组数据类型的一个对象):
In [17]: data.shape
Out[17]: (2, 3)
In [18]: data.dtype
Out[18]: dtype('float64')
本章将介绍使用NumPy数组的基础知识,这些足以让你跟上本书的剩余部分。虽然对于许多数据分析应用来说,没有必要对NumPy有非常深入的理解,但熟练掌握面向数组的编程和思维方式是成为科学Python专家的关键一步。
注意:在本书中,每当看到“数组”、“NumPy数组”或“ndarray”时,大多数情况下它们指的都是ndarray对象。
创建ndarray
创建数组最简单的方法是使用 array 函数。它接受任何序列类对象(包括其他数组),并生成一个包含传入数据的新NumPy数组。例如,列表是一个很好的转换候选:
In [19]: data1 = [6, 7.5, 8, 0, 1]
In [20]: arr1 = np.array(data1)
In [21]: arr1
Out[21]: array([6. , 7.5, 8. , 0. , 1. ])
嵌套序列,例如由等长列表组成的列表,将被转换为多维数组:
In [22]: data2 = [[1, 2, 3, 4], [5, 6, 7, 8]]
In [23]: arr2 = np.array(data2)
In [24]: arr2
Out[24]:
array([[1, 2, 3, 4],
[5, 6, 7, 8]])
由于 data2 是一个列表的列表,NumPy数组 arr2 具有两个维度,其形状根据数据推断而来。我们可以通过检查 ndim 和 shape 属性来确认:
In [25]: arr2.ndim
Out[25]: 2
In [26]: arr2.shape
Out[26]: (2, 4)
补充讲解:
ndim属性返回数组的维度数(秩),而shape是一个元组,给出了每个维度的大小。对于本例,2表示有两个维度(行和列),(2, 4)表示2行4列。这是理解NumPy数组结构的基础。
除非显式指定(将在“ndarray的数据类型”中讨论),np.array 会尝试为其创建的数组推断一个合适的数据类型。数据类型存储在一个特殊的元数据对象 dtype 中;例如,在前两个例子中我们有:
In [27]: arr1.dtype
Out[27]: dtype('float64')
In [28]: arr2.dtype
Out[28]: dtype('int64')
除了 np.array 之外,还有许多其他用于创建新数组的函数。例如,np.zeros 和 np.ones 分别创建指定长度或形状的全0或全1数组。np.empty 创建一个数组,但不将其值初始化为任何特定值。要使用这些方法创建高维数组,需要为 shape 参数传入一个元组:
In [29]: np.zeros(10)
Out[29]: array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0.])
In [30]: np.zeros((3, 6))
Out[30]:
array([[0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0.]])
In [31]: np.empty((2, 3, 2))
Out[31]:
array([[[0., 0.],
[0., 0.],
[0., 0.]],
[[0., 0.],
[0., 0.],
[0., 0.]]])
警告:假设
np.empty会返回一个全零数组是不安全的。这个函数返回未初始化的内存,因此可能包含非零的“垃圾”值。仅当你打算随后用数据填充新数组时,才应使用此函数。
💡 建议:在需要占位符数组的场合,如果后续会完全覆写数据,可以用
np.empty来节省初始化的开销;否则,最好使用np.zeros或np.ones,以确保程序行为可预测、可重现。
np.arange 是Python内置 range 函数的数组版本:
In [32]: np.arange(15)
Out[32]: array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14])
表4.1列出了标准数组创建函数的简短列表。由于NumPy专注于数值计算,如果不指定,数据类型在大多数情况下将是 float64(浮点数)。
表4.1:一些重要的NumPy数组创建函数
| 函数 | 描述 |
|---|---|
array |
将输入数据(列表、元组、数组或其他序列类型)转换为ndarray,可通过推断或显式指定数据类型;默认复制输入数据 |
asarray |
将输入转换为ndarray,但如果输入已经是ndarray,则不进行复制 |
arange |
类似于内置的 range,但返回的是ndarray而不是列表 |
ones, ones_like |
根据给定的形状和数据类型创建一个全1数组;ones_like 接受另一个数组,并生成形状和数据类型相同的全1数组 |
zeros, zeros_like |
类似于 ones 和 ones_like,但生成的是全0数组 |
empty, empty_like |
通过分配新内存来创建数组,但不像 ones 和 zeros 那样填充任何值 |
full, full_like |
生成一个给定形状和数据类型的数组,并将所有值设置为指定的“填充值”;full_like 接受另一个数组,并生成形状和数据类型相同的填充数组 |
eye, identity |
创建一个 N×N 的单位矩阵(对角线为1,其余为0) |
补充讲解:
asarray函数尤其有用,当你需要确保输入是数组,但如果输入已经是ndarray时,希望避免不必要的内存复制。这在库函数中很常见,可以提升性能。
ndarray的数据类型
数据类型或 dtype 是一个特殊对象,包含了ndarray将一块内存解释为特定数据类型所需的信息(或元数据):
In [33]: arr1 = np.array([1, 2, 3], dtype=np.float64)
In [34]: arr2 = np.array([1, 2, 3], dtype=np.int32)
In [35]: arr1.dtype
Out[35]: dtype('float64')
In [36]: arr2.dtype
Out[36]: dtype('int32')
数据类型是NumPy能够灵活地与来自其他系统的数据交互的根源之一。在大多数情况下,它们提供了直接映射到底层磁盘或内存表示的方式,这使得读写二进制数据流以及连接用低级语言(如C或FORTRAN)编写的代码成为可能。数值数据类型的命名方式相同:一个类型名称,如 float 或 int,后跟一个表示每个元素位数的数字。一个标准的双精度浮点值(Python的 float 对象底层所使用的那种)占用8字节或64位。因此,这种类型在NumPy中被称为 float64。表4.2列出了NumPy支持的完整数据类型。
注意:不用担心需要记住NumPy的数据类型,特别是对于新用户而言。通常只需要关心你正在处理的数据的通用类别——浮点、复数、整数、布尔、字符串或通用Python对象。当你需要更精细地控制数据在内存和磁盘上的存储方式时,尤其是在处理大型数据集时,了解你能够控制存储类型是很有用的。
表4.2:NumPy数据类型
| 类型 | 类型代码 | 描述 |
|---|---|---|
int8, uint8 |
i1, u1 |
有符号和无符号的8位(1字节)整数类型 |
int16, uint16 |
i2, u2 |
有符号和无符号的16位整数类型 |
int32, uint32 |
i4, u4 |
有符号和无符号的32位整数类型 |
int64, uint64 |
i8, u8 |
有符号和无符号的64位整数类型 |
float16 |
f2 |
半精度浮点数 |
float32 |
f4 或 f |
标准单精度浮点数;与C的 float 兼容 |
float64 |
f8 或 d |
标准双精度浮点数;与C的 double 和Python的 float 对象兼容 |
float128 |
f16 或 g |
扩展精度浮点数 |
complex64, complex128, complex256 |
c8, c16, c32 |
分别用两个32、64或128位浮点数表示的复数 |
bool |
? |
布尔类型,存储 True 和 False 值 |
object |
O |
Python对象类型;值可以是任意Python对象 |
string_ |
S |
固定长度的ASCII字符串类型(每字符1字节);例如,要创建长度为10的字符串数据类型,使用 'S10' |
unicode_ |
U |
固定长度的Unicode类型(字节数因平台而异);语义规范与 string_ 相同(例如 'U10') |
注意:存在有符号和无符号整数类型,许多读者可能不熟悉这个术语。有符号整数可以表示正整数和负整数,而无符号整数只能表示非负整数。例如,
int8(有符号8位整数)可以表示从-128到127(含)的整数,而uint8(无符号8位整数)可以表示0到255。
你可以使用ndarray的 astype 方法显式地将数组从一种数据类型转换或“转型”为另一种:
In [37]: arr = np.array([1, 2, 3, 4, 5])
In [38]: arr.dtype
Out[38]: dtype('int64')
In [39]: float_arr = arr.astype(np.float64)
In [40]: float_arr
Out[40]: array([1., 2., 3., 4., 5.])
In [41]: float_arr.dtype
Out[41]: dtype('float64')
在这个例子中,整数被转型为浮点数。如果我将一些浮点数转型为整数数据类型,小数部分会被截断:
In [42]: arr = np.array([3.7, -1.2, -2.6, 0.5, 12.9, 10.1])
In [43]: arr
Out[43]: array([ 3.7, -1.2, -2.6, 0.5, 12.9, 10.1])
In [44]: arr.astype(np.int32)
Out[44]: array([ 3, -1, -2, 0, 12, 10], dtype=int32)
如果你有一个表示数字的字符串数组,可以使用 astype 将它们转换为数值形式:
In [45]: numeric_strings = np.array(["1.25", "-9.6", "42"], dtype=np.string_)
In [46]: numeric_strings.astype(float)
Out[46]: array([ 1.25, -9.6 , 42. ])
警告:使用
numpy.string_类型时要小心,因为NumPy中的字符串数据是固定大小的,可能会在没有警告的情况下截断输入。pandas对非数值数据具有更直观的“开箱即用”行为。
如果转型因某种原因失败(例如一个无法转换为 float64 的字符串),将会引发 ValueError。在这之前我有点偷懒,写的是 float 而不是 np.float64;NumPy会自动将Python类型别名映射到其等效的数据类型。
你也可以使用另一个数组的 dtype 属性:
In [47]: int_array = np.arange(10)
In [48]: calibers = np.array([.22, .270, .357, .380, .44, .50], dtype=np.float64)
In [49]: int_array.astype(calibers.dtype)
Out[49]: array([0., 1., 2., 3., 4., 5., 6., 7., 8., 9.])
你还可以使用简写的类型代码字符串来引用 dtype:
In [50]: zeros_uint32 = np.zeros(8, dtype="u4")
In [51]: zeros_uint32
Out[51]: array([0, 0, 0, 0, 0, 0, 0, 0], dtype=uint32)
注意:调用
astype始终会创建一个新数组(数据的一个副本),即使新的数据类型与旧的数据类型相同。
💡 建议:在进行数据预处理时,根据数据规模合理选择数据类型(如从
float64降到float32)可以显著节省内存,但要注意数值精度损失。对于整数,确保取值范围不超出目标类型的表示范围,否则会发生静默溢出(overflow),这在调试时可能很难发现。
NumPy数组的算术运算
数组之所以重要,是因为它们允许你在不编写任何 for 循环的情况下表达批量数据操作。NumPy用户称之为向量化(vectorization)。任何等尺寸数组之间的算术运算都是逐元素进行的:
In [52]: arr = np.array([[1., 2., 3.], [4., 5., 6.]])
In [53]: arr
Out[53]:
array([[1., 2., 3.],
[4., 5., 6.]])
In [54]: arr * arr
Out[54]:
array([[ 1., 4., 9.],
[16., 25., 36.]])
In [55]: arr - arr
Out[55]:
array([[0., 0., 0.],
[0., 0., 0.]])
与标量的算术运算会将标量参数传播(广播)到数组的每个元素:
In [56]: 1 / arr
Out[56]:
array([[1. , 0.5 , 0.3333],
[0.25 , 0.2 , 0.1667]])
In [57]: arr ** 2
Out[57]:
array([[ 1., 4., 9.],
[16., 25., 36.]])
相同大小的数组之间的比较会产生布尔数组:
In [58]: arr2 = np.array([[0., 4., 1.], [7., 2., 12.]])
In [59]: arr2
Out[59]:
array([[ 0., 4., 1.],
[ 7., 2., 12.]])
In [60]: arr2 > arr
Out[60]:
array([[False, True, False],
[ True, False, True]])
不同大小的数组之间的运算被称为广播(broadcasting),将在附录A:高级NumPy中详细讨论。阅读本书的大部分内容并不需要深入理解广播。
补充讲解:广播是一种强大的机制,它允许NumPy在执行算术运算时处理不同形状的数组。通俗地说,广播会尝试将较小的数组“拉伸”成与较大数组兼容的形状,前提是它们在每一个维度上要么长度相同,要么其中一方的长度为1。比如将一个标量与一个数组相加,标量实际上被广播成了与数组同形状的全标量数组。掌握广播是写出简洁高效NumPy代码的关键。
基础索引与切片
NumPy数组索引是一个深入的话题,因为你可能有很多种方式来选取数据的子集或单个元素。一维数组比较简单,从表面看,它们的行为类似于Python列表:
In [61]: arr = np.arange(10)
In [62]: arr
Out[62]: array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
In [63]: arr[5]
Out[63]: 5
In [64]: arr[5:8]
Out[64]: array([5, 6, 7])
In [65]: arr[5:8] = 12
In [66]: arr
Out[66]: array([ 0, 1, 2, 3, 4, 12, 12, 12, 8, 9])
正如你所见,如果你将标量值赋给一个切片,就像 arr[5:8] = 12,该值会传播(或广播)到整个选区。
注意:与Python内置列表的一个重要区别是,数组切片是原始数组的视图(view)。这意味着数据不会被复制,对视图的任何修改都会反映在源数组上。
为了举例说明这一点,我首先创建 arr 的一个切片:
In [67]: arr_slice = arr[5:8]
In [68]: arr_slice
Out[68]: array([12, 12, 12])
现在,当我修改 arr_slice 中的值时,这些变化会反映在原始数组 arr 中:
In [69]: arr_slice[1] = 12345
In [70]: arr
Out[70]:
array([ 0, 1, 2, 3, 4, 12, 12345, 12, 8,
9])
“裸”切片 [:] 会为数组中的所有值赋值:
In [71]: arr_slice[:] = 64
In [72]: arr
Out[72]: array([ 0, 1, 2, 3, 4, 64, 64, 64, 8, 9])
如果你是NumPy新手,这可能会让你感到惊讶,特别是如果你使用过其他更倾向于复制数据的数组编程语言。由于NumPy被设计为能够处理非常大的数组,你可以想象,如果NumPy坚持总是复制数据,可能会引发性能和内存问题。
警告:如果你想要ndarray切片的一个副本而不是视图,则需要显式复制该数组,例如
arr[5:8].copy()。正如你将在后续内容中看到的,pandas 也是以这种方式工作的。
💡 建议:视图机制是一把双刃剑。它避免了不必要的内存拷贝,提升了性能,但可能导致意想不到的副作用。在编写函数时,如果你不希望对外部传入的数组进行原地修改,可以在函数内部使用
arr.copy()创建一个副本再操作。同时,如果你确实想修改原数组的一部分,则可以利用视图特性。
对于更高维的数组,你拥有更多选择。在二维数组中,每个索引处的元素不再是标量,而是一维数组:
In [73]: arr2d = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
In [74]: arr2d[2]
Out[74]: array([7, 8, 9])
因此,单个元素可以递归访问。但那样有点太麻烦了,所以你可以传入一个由逗号分隔的索引列表来选取单个元素。因此以下两者是等价的:
In [75]: arr2d[0][2]
Out[75]: 3
In [76]: arr2d[0, 2]
Out[76]: 3
图4.1展示了二维数组索引的示意图。我发现将轴0想象为数组的“行”,轴1想象为“列”会很有帮助。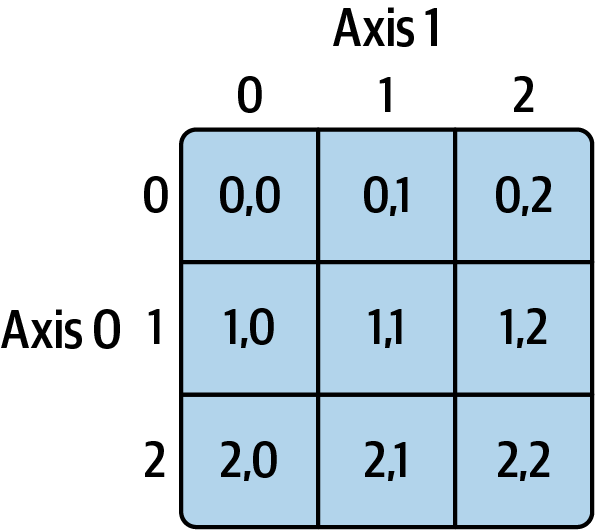
(图4.1:NumPy数组中的元素索引)
在多维数组中,如果你省略了后面的索引,返回的对象将是一个较低维度的ndarray,它包含了沿着较高维度的所有数据。所以在一个 2 × 2 × 3 的数组 arr3d 中:
In [77]: arr3d = np.array([[[1, 2, 3], [4, 5, 6]], [[7, 8, 9], [10, 11, 12]]])
In [78]: arr3d
Out[78]:
array([[[ 1, 2, 3],
[ 4, 5, 6]],
[[ 7, 8, 9],
[10, 11, 12]]])
arr3d[0] 是一个 2 × 3 的数组:
In [79]: arr3d[0]
Out[79]:
array([[1, 2, 3],
[4, 5, 6]])
标量值和数组都可以赋值给 arr3d[0]:
In [80]: old_values = arr3d[0].copy()
In [81]: arr3d[0] = 42
In [82]: arr3d
Out[82]:
array([[[42, 42, 42],
[42, 42, 42]],
[[ 7, 8, 9],
[10, 11, 12]]])
In [83]: arr3d[0] = old_values
In [84]: arr3d
Out[84]:
array([[[ 1, 2, 3],
[ 4, 5, 6]],
[[ 7, 8, 9],
[10, 11, 12]]])
类似地,arr3d[1, 0] 会给你所有索引以 (1, 0) 开头的值,形成一个一维数组:
In [85]: arr3d[1, 0]
Out[85]: array([7, 8, 9])
这个表达式等同于分两步进行索引:
In [86]: x = arr3d[1]
In [87]: x
Out[87]:
array([[ 7, 8, 9],
[10, 11, 12]])
In [88]: x[0]
Out[88]: array([7, 8, 9])
请注意,在所有这些选择了数组子区域的情况下,返回的数组都是视图。
警告:这种NumPy数组的多维索引语法不适用于常规Python对象,例如列表的列表。
使用切片索引
与Python列表这样的一维对象类似,ndarray可以使用熟悉的语法进行切片:
In [89]: arr
Out[89]: array([ 0, 1, 2, 3, 4, 64, 64, 64, 8, 9])
In [90]: arr[1:6]
Out[90]: array([ 1, 2, 3, 4, 64])
考虑之前的二维数组 arr2d。对这个数组进行切片稍有不同:
In [91]: arr2d
Out[91]:
array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
In [92]: arr2d[:2]
Out[92]:
array([[1, 2, 3],
[4, 5, 6]])
正如你所见,它沿着轴0(第一个轴)进行了切片。因此,一个切片会选择沿某个轴的元素范围。将表达式 arr2d[:2] 读作“选取 arr2d 的前两行”会很有帮助。
你可以像传入多个索引一样传入多个切片:
In [93]: arr2d[:2, 1:]
Out[93]:
array([[2, 3],
[5, 6]])
当像这样切片时,你总是获得相同维度数的数组视图。通过混合整数索引和切片,你会得到较低维度的切片。
例如,我可以选择第二行但仅前两列,就像这样:
In [94]: lower_dim_slice = arr2d[1, :2]
这里,虽然 arr2d 是二维的,但 lower_dim_slice 是一维的,其形状是一个只有一个轴大小的元组:
In [95]: lower_dim_slice.shape
Out[95]: (2,)
类似地,我可以选择第三列但仅前两行:
In [96]: arr2d[:2, 2]
Out[96]: array([3, 6])
见图4.2的图示。请注意,单独的冒号表示取整个轴,因此你可以通过以下方式仅对较高维度的轴进行切片:
In [97]: arr2d[:, :1]
Out[97]:
array([[1],
[4],
[7]])
当然,对切片表达式赋值会将值赋给整个选区:
In [98]: arr2d[:2, 1:] = 0
In [99]: arr2d
Out[99]:
array([[1, 0, 0],
[4, 0, 0],
[7, 8, 9]])
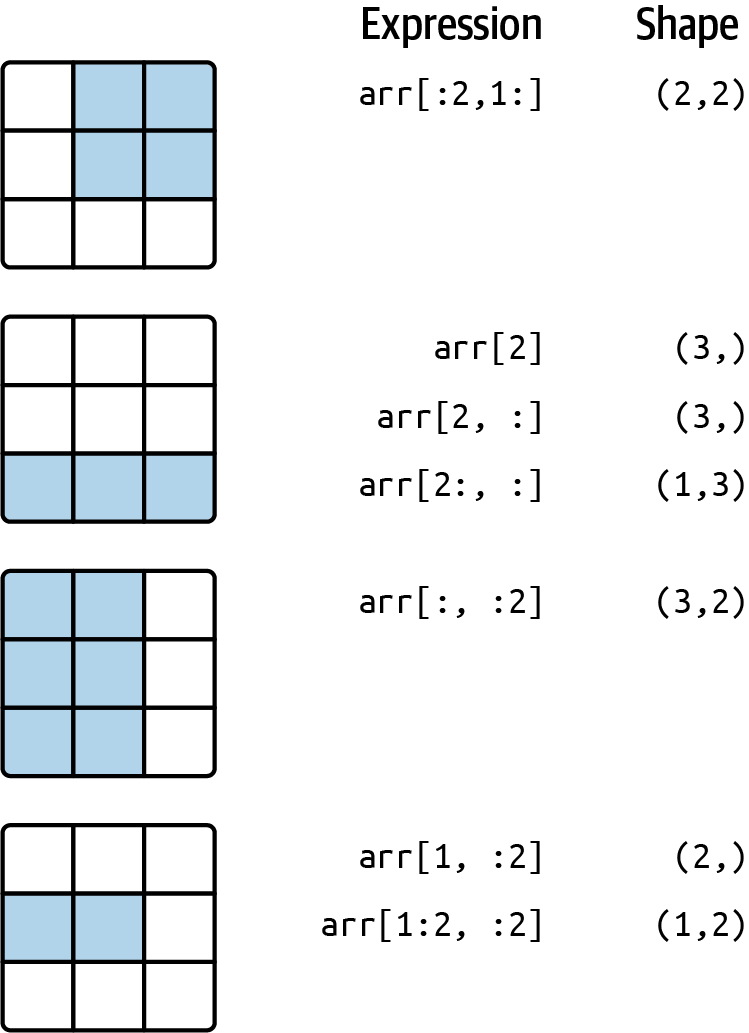
(图4.2:二维数组切片)
补充讲解:混合使用整数和切片会降低返回数组的维度,这是由NumPy索引规则决定的。如果你想保持维度(例如,让一列仍是一个二维列向量),可以使用切片
[:, 2:3]而不是整数索引[:, 2]。这在某些需要保持维度以便广播或矩阵运算的场景下非常有用。
布尔索引
让我们考虑一个例子:我们有一个数组 data 和一个包含重复值的名字数组 names:
In [100]: names = np.array(["Bob", "Joe", "Will", "Bob", "Will", "Joe", "Joe"])
In [101]: data = np.array([[4, 7], [0, 2], [-5, 6], [0, 0], [1, 2],
.....: [-12, -4], [3, 4]])
In [102]: names
Out[102]: array(['Bob', 'Joe', 'Will', 'Bob', 'Will', 'Joe', 'Joe'], dtype='<U4')
In [103]: data
Out[103]:
array([[ 4, 7],
[ 0, 2],
[ -5, 6],
[ 0, 0],
[ 1, 2],
[-12, -4],
[ 3, 4]])
假设每个名字对应 data 数组中的一行,而我们想选择所有对应名字为 "Bob" 的行。与算术运算一样,数组之间的比较(如 ==)也是向量化的。因此,比较 names 和字符串 "Bob" 会产生一个布尔数组:
In [104]: names == "Bob"
Out[104]: array([ True, False, False, True, False, False, False])
这个布尔数组可以在索引数组时传入:
In [105]: data[names == "Bob"]
Out[105]:
array([[4, 7],
[0, 0]])
布尔数组的长度必须与其索引的数组轴的长度相同。你甚至可以将布尔数组与切片或整数(或整数序列,稍后会详细介绍)混合使用。
在以下示例中,我选择了 names == "Bob" 的行,同时也索引了列:
In [106]: data[names == "Bob", 1:]
Out[106]:
array([[7],
[0]])
In [107]: data[names == "Bob", 1]
Out[107]: array([7, 0])
要选择除 "Bob" 之外的所有内容,你可以使用 != 或通过 ~ 对条件取反:
In [108]: names != "Bob"
Out[108]: array([False, True, True, False, True, True, True])
In [109]: ~(names == "Bob")
Out[109]: array([False, True, True, False, True, True, True])
In [110]: data[~(names == "Bob")]
Out[110]:
array([[ 0, 2],
[ -5, 6],
[ 1, 2],
[-12, -4],
[ 3, 4]])
当你想反转一个由变量引用的布尔数组时,~ 运算符非常有用:
In [111]: cond = names == "Bob"
In [112]: data[~cond]
Out[112]:
array([[ 0, 2],
[ -5, 6],
[ 1, 2],
[-12, -4],
[ 3, 4]])
要选择三个名字中的两个,组合多个布尔条件时,需要使用布尔算术运算符,如 &(与)和 |(或):
In [113]: mask = (names == "Bob") | (names == "Will")
In [114]: mask
Out[114]: array([ True, False, True, True, True, False, False])
In [115]: data[mask]
Out[115]:
array([[ 4, 7],
[-5, 6],
[ 0, 0],
[ 1, 2]])
通过布尔索引从数组中选择数据并将结果赋给新变量时,始终会创建数据的副本,即使返回的数组没有变化。
警告:Python的
and和or关键字无法用于布尔数组。请使用&(与)和|(或)代替。
💡 强烈建议:由于按位运算符
&、|的优先级高于比较运算符,在使用它们组合条件时,每个条件两侧务必加上括号。例如(names == "Bob") | (names == "Will")。遗漏括号是使用布尔索引时最常见的错误之一,会产生令人困惑的结果或错误。
使用布尔数组设置值的方式是,将右侧的值替换到布尔数组值为 True 的位置。要将 data 中的所有负值设置为0,我们只需要这样做:
In [116]: data[data < 0] = 0
In [117]: data
Out[117]:
array([[4, 7],
[0, 2],
[0, 6],
[0, 0],
[1, 2],
[0, 0],
[3, 4]])
你也可以使用一维布尔数组来设置整行或整列:
In [118]: data[names != "Joe"] = 7
In [119]: data
Out[119]:
array([[7, 7],
[0, 2],
[7, 7],
[7, 7],
[7, 7],
[0, 0],
[3, 4]])
正如我们稍后将看到的,在pandas中对二维数据进行这些类型的操作会非常方便。
花式索引
花式索引(Fancy indexing)是NumPy采用的术语,用来描述使用整数数组进行索引。假设我们有一个 8 × 4 的数组:
In [120]: arr = np.zeros((8, 4))
In [121]: for i in range(8):
.....: arr[i] = i
In [122]: arr
Out[122]:
array([[0., 0., 0., 0.],
[1., 1., 1., 1.],
[2., 2., 2., 2.],
[3., 3., 3., 3.],
[4., 4., 4., 4.],
[5., 5., 5., 5.],
[6., 6., 6., 6.],
[7., 7., 7., 7.]])
要按特定顺序选择行的子集,你可以简单地传入一个指定所需顺序的整数列表或ndarray:
In [123]: arr[[4, 3, 0, 6]]
Out[123]:
array([[4., 4., 4., 4.],
[3., 3., 3., 3.],
[0., 0., 0., 0.],
[6., 6., 6., 6.]])
希望这段代码如你所预期!使用负索引会从末尾开始选择行:
In [124]: arr[[-3, -5, -7]]
Out[124]:
array([[5., 5., 5., 5.],
[3., 3., 3., 3.],
[1., 1., 1., 1.]])
传入多个索引数组的行为略有不同;它会选择与每个索引元组对应的一维元素数组:
In [125]: arr = np.arange(32).reshape((8, 4))
In [126]: arr
Out[126]:
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11],
[12, 13, 14, 15],
[16, 17, 18, 19],
[20, 21, 22, 23],
[24, 25, 26, 27],
[28, 29, 30, 31]])
In [127]: arr[[1, 5, 7, 2], [0, 3, 1, 2]]
Out[127]: array([ 4, 23, 29, 10])
要了解更多关于 reshape 方法的信息,请参阅附录A:高级NumPy。
这里选择了元素 (1, 0)、(5, 3)、(7, 1) 和 (2, 2)。当传入的索引数组数量与轴的数量相同时,花式索引的结果始终是一维的。
在这种情况下,花式索引的行为可能与一些用户(包括我自己)预期的有所不同,即期望选中矩阵行和列的子集形成的矩形区域。以下是实现该目标的一种方法:
In [128]: arr[[1, 5, 7, 2]][:, [0, 3, 1, 2]]
Out[128]:
array([[ 4, 7, 5, 6],
[20, 23, 21, 22],
[28, 31, 29, 30],
[ 8, 11, 9, 10]])
请记住,与切片不同,花式索引在将结果赋给新变量时始终会将数据复制到新数组。如果你通过花式索引来赋值,则被索引的值将会被修改:
In [129]: arr[[1, 5, 7, 2], [0, 3, 1, 2]]
Out[129]: array([ 4, 23, 29, 10])
In [130]: arr[[1, 5, 7, 2], [0, 3, 1, 2]] = 0
In [131]: arr
Out[131]:
array([[ 0, 1, 2, 3],
[ 0, 5, 6, 7],
[ 8, 9, 0, 11],
[12, 13, 14, 15],
[16, 17, 18, 19],
[20, 21, 22, 0],
[24, 25, 26, 27],
[28, 0, 30, 31]])
补充讲解:花式索引的“坐标对”行为是NumPy设计上的一个特点。如果想要获取矩形子集,正确的做法是像
arr[[1,5,7,2]][:, [0,3,1,2]]这样分步进行,或者使用np.ix_函数:arr[np.ix_([1,5,7,2], [0,3,1,2])]。np.ix_能将两个一维整数数组转换成可进行矩形区域选择的索引器,这往往更清晰高效。
数组转置与轴交换
转置是重塑的一种特殊形式,它同样返回底层数据的视图而不复制任何内容。数组有 transpose 方法和特殊的 T 属性:
In [132]: arr = np.arange(15).reshape((3, 5))
In [133]: arr
Out[133]:
array([[ 0, 1, 2, 3, 4],
[ 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14]])
In [134]: arr.T
Out[134]:
array([[ 0, 5, 10],
[ 1, 6, 11],
[ 2, 7, 12],
[ 3, 8, 13],
[ 4, 9, 14]])
在进行矩阵计算时,你可能经常这样做——例如,在使用 np.dot 计算内积时:
In [135]: arr = np.array([[0, 1, 0], [1, 2, -2], [6, 3, 2], [-1, 0, -1], [1, 0, 1
]])
In [136]: arr
Out[136]:
array([[ 0, 1, 0],
[ 1, 2, -2],
[ 6, 3, 2],
[-1, 0, -1],
[ 1, 0, 1]])
In [137]: np.dot(arr.T, arr)
Out[137]:
array([[39, 20, 12],
[20, 14, 2],
[12, 2, 10]])
中缀运算符 @ 是进行矩阵乘法的另一种方式:
In [138]: arr.T @ arr
Out[138]:
array([[39, 20, 12],
[20, 14, 2],
[12, 2, 10]])
使用 .T 进行简单转置是轴交换的一个特例。ndarray还有一个 swapaxes 方法,它接受一对轴编号并交换指定的轴以重新排列数据:
In [139]: arr
Out[139]:
array([[ 0, 1, 0],
[ 1, 2, -2],
[ 6, 3, 2],
[-1, 0, -1],
[ 1, 0, 1]])
In [140]: arr.swapaxes(0, 1)
Out[140]:
array([[ 0, 1, 6, -1, 1],
[ 1, 2, 3, 0, 0],
[ 0, -2, 2, -1, 1]])
swapaxes 同样返回数据的视图而不进行复制。
💡 建议:在处理高于二维的图像数据或时间序列多维数组时,
transpose和swapaxes非常有用。它们可以让你在不移动数据的情况下重新组织轴的顺序,从而高效地适配不同算法的输入要求。
4.2 伪随机数生成
numpy.random 模块补充了Python内置的 random 模块,提供了从多种概率分布中高效生成整个样本值数组的函数。例如,你可以使用 numpy.random.standard_normal 获得来自标准正态分布的 4 × 4 样本数组:
In [141]: samples = np.random.standard_normal(size=(4, 4))
In [142]: samples
Out[142]:
array([[-0.2047, 0.4789, -0.5194, -0.5557],
[ 1.9658, 1.3934, 0.0929, 0.2817],
[ 0.769 , 1.2464, 1.0072, -1.2962],
[ 0.275 , 0.2289, 1.3529, 0.8864]])
相比之下,Python的内置 random 模块一次只能采样一个值。从这个基准测试可以看出,numpy.random 在生成非常大的样本时,速度快了一个数量级以上:
In [143]: from random import normalvariate
In [144]: N = 1_000_000
In [145]: %timeit samples = [normalvariate(0, 1) for _ in range(N)]
490 ms +- 2.23 ms per loop (mean +- std. dev. of 7 runs, 1 loop each)
In [146]: %timeit np.random.standard_normal(N)
32.6 ms +- 271 us per loop (mean +- std. dev. of 7 runs, 10 loops each)
这些随机数并不是真正的随机(而是伪随机),它们由一个可配置的随机数生成器确定性地生成。像 numpy.random.standard_normal 这样的函数使用 numpy.random 模块的默认随机数生成器,但你的代码可以配置为使用显式生成器:
In [147]: rng = np.random.default_rng(seed=12345)
In [148]: data = rng.standard_normal((2, 3))
seed 参数决定了生成器的初始状态,并且每次使用 rng 对象生成数据时,其状态都会改变。这个生成器对象 rng 也与可能使用 numpy.random 模块的其他代码隔离开来:
In [149]: type(rng)
Out[149]: numpy.random._generator.Generator
表4.3列出了像 rng 这样的随机生成器对象上可用的部分方法。我将在本章剩余部分使用上面创建的 rng 对象来生成随机数据。
表4.3:NumPy随机数生成器方法
| 方法 | 描述 |
|---|---|
permutation |
返回一个序列的随机排列,或返回一个排列后的范围 |
shuffle |
就地对一个序列进行随机排列 |
uniform |
从均匀分布中抽取样本 |
integers |
从给定的低-高范围内抽取随机整数 |
standard_normal |
从均值为0、标准差为1的正态分布中抽取样本 |
binomial |
从二项分布中抽取样本 |
normal |
从正态(高斯)分布中抽取样本 |
beta |
从贝塔分布中抽取样本 |
chisquare |
从卡方分布中抽取样本 |
gamma |
从伽马分布中抽取样本 |
uniform |
从均匀 [0, 1) 分布中抽取样本 |
💡 强烈建议:从NumPy 1.17开始,推荐使用
np.random.default_rng()创建随机数生成器实例,而不是直接使用np.random.seed()等旧有全局方法。新式生成器不仅提供了更好的统计特性,也避免了全局状态带来的隐式问题,让随机数生成更加可控、可复现。在数据分析和机器学习中,固定种子对于实验的可复现性至关重要。
4.3 通用函数:快速的逐元素数组函数
通用函数(universal function),或称 ufunc,是一种在ndarray中的数据上执行逐元素操作的函数。你可以将它们视为简单函数的快速向量化包装器,这些简单函数接受一个或多个标量值,并产生一个或多个标量结果。
许多ufunc是简单的逐元素变换,如 np.sqrt 或 np.exp:
In [150]: arr = np.arange(10)
In [151]: arr
Out[151]: array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
In [152]: np.sqrt(arr)
Out[152]:
array([0. , 1. , 1.4142, 1.7321, 2. , 2.2361, 2.4495, 2.6458,
2.8284, 3. ])
In [153]: np.exp(arr)
Out[153]:
array([ 1. , 2.7183, 7.3891, 20.0855, 54.5982, 148.4132,
403.4288, 1096.6332, 2980.958 , 8103.0839])
这些被称为一元ufunc。其他的,如 np.add 或 np.maximum,接受两个数组(因此是二元ufunc),并返回一个数组作为结果:
In [154]: x = rng.standard_normal(8)
In [155]: y = rng.standard_normal(8)
In [156]: x
Out[156]:
array([-1.3678, 0.6489, 0.3611, -1.9529, 2.3474, 0.9685, -0.7594,
0.9022])
In [157]: y
Out[157]:
array([-0.467 , -0.0607, 0.7888, -1.2567, 0.5759, 1.399 , 1.3223,
-0.2997])
In [158]: np.maximum(x, y)
Out[158]:
array([-0.467 , 0.6489, 0.7888, -1.2567, 2.3474, 1.399 , 1.3223,
0.9022])
在这个例子中,np.maximum 计算了 x 和 y 中逐元素的最大值。
虽然不常见,但一个ufunc可以返回多个数组。np.modf 就是一个例子:它是Python内置 math.modf 的向量化版本,返回浮点数组的小数部分和整数部分:
In [159]: arr = rng.standard_normal(7) * 5
In [160]: arr
Out[160]: array([ 4.5146, -8.1079, -0.7909, 2.2474, -6.718 , -0.4084, 8.6237])
In [161]: remainder, whole_part = np.modf(arr)
In [162]: remainder
Out[162]: array([ 0.5146, -0.1079, -0.7909, 0.2474, -0.718 , -0.4084, 0.6237])
In [163]: whole_part
Out[163]: array([ 4., -8., -0., 2., -6., -0., 8.])
Ufunc接受一个可选的 out 参数,允许它们将结果存入现有数组,而不是创建新数组:
In [164]: arr
Out[164]: array([ 4.5146, -8.1079, -0.7909, 2.2474, -6.718 , -0.4084, 8.6237])
In [165]: out = np.zeros_like(arr)
In [166]: np.add(arr, 1)
Out[166]: array([ 5.5146, -7.1079, 0.2091, 3.2474, -5.718 , 0.5916, 9.6237])
In [167]: np.add(arr, 1, out=out)
Out[167]: array([ 5.5146, -7.1079, 0.2091, 3.2474, -5.718 , 0.5916, 9.6237])
In [168]: out
Out[168]: array([ 5.5146, -7.1079, 0.2091, 3.2474, -5.718 , 0.5916, 9.6237])
表4.4和表4.5列出了一些NumPy的ufunc。NumPy仍在持续添加新的ufunc,因此查阅在线NumPy文档是获取完整列表并保持更新的最佳方式。
表4.4:一些一元通用函数
| 函数 | 描述 |
|---|---|
abs, fabs |
逐元素计算整数、浮点数或复数的绝对值 |
sqrt |
计算每个元素的平方根(等价于 arr ** 0.5) |
square |
计算每个元素的平方(等价于 arr ** 2) |
exp |
计算每个元素的指数 e^x |
log, log10, log2, log1p |
自然对数(底数 e)、以10为底的对数、以2为底的对数、以及 log(1 + x) |
sign |
计算每个元素的符号:1(正数)、0(零)、或 –1(负数) |
ceil |
计算每个元素的上限(即大于或等于该数的最小整数) |
floor |
计算每个元素的下限(即小于或等于每个元素的最大整数) |
rint |
将元素舍入到最近的整数,并保留原有的 dtype |
modf |
将数组的小数部分和整数部分作为独立的数组返回 |
isnan |
返回一个布尔数组,指示每个值是否为 NaN(非数值) |
isfinite, isinf |
返回一个布尔数组,指示每个元素是否有限(非 inf, 非 NaN)或无限 |
cos, cosh, sin, sinh, tan, tanh |
常规和双曲三角函数 |
arccos, arccosh, arcsin, arcsinh, arctan, arctanh |
反三角函数 |
logical_not |
逐元素计算逻辑非(等价于 ~arr) |
表4.5:一些二元通用函数
| 函数 | 描述 |
|---|---|
add |
将数组中对应的元素相加 |
subtract |
从第一个数组中减去第二个数组的元素 |
multiply |
数组元素相乘 |
divide, floor_divide |
除法或地板除(截断余数) |
power |
将第一个数组中的元素按第二个数组中指定的幂进行指数运算 |
maximum, fmax |
逐元素最大值;fmax 忽略 NaN |
minimum, fmin |
逐元素最小值;fmin 忽略 NaN |
mod |
逐元素取模(除法的余数) |
copysign |
将第二个参数中值的符号复制给第一个参数中的值 |
greater, greater_equal, less, less_equal, equal, not_equal |
执行逐元素比较,产生布尔数组(等价于中缀运算符 >, >=, <, <=, ==, !=) |
logical_and |
逐元素计算逻辑与(&)操作 |
logical_or |
逐元素计算逻辑或(` |
logical_xor |
逐元素计算逻辑异或(^)操作 |
💡 建议:在需要对数组进行复杂数学运算时,优先查找NumPy是否提供了相应的ufunc。它们通常比使用Python循环或列表推导式快得多,且代码更简洁。熟练使用ufunc是写出“NumPy风格”代码的关键一步。
4.4 面向数组的编程
使用NumPy数组能够让你将许多数据处理任务表达为简洁的数组表达式,而无需编写循环。这种用数组表达式替换显式循环的做法,被一些人称为向量化。通常,向量化数组操作会比纯Python等价实现快得多,在任何类型的数值计算中效果尤为显著。稍后在附录A:高级NumPy中,我将解释广播,这是一种强大的向量化计算技术。
举一个简单的例子,假设我们想在一个规则的值网格上计算函数 sqrt(x^2 + y^2)。np.meshgrid 函数接受两个一维数组,并根据两个数组中所有 (x, y) 对生成两个二维矩阵:
In [169]: points = np.arange(-5, 5, 0.01) # 1000 个等距点
In [170]: xs, ys = np.meshgrid(points, points)
In [171]: ys
Out[171]:
array([[-5. , -5. , -5. , ..., -5. , -5. , -5. ],
[-4.99, -4.99, -4.99, ..., -4.99, -4.99, -4.99],
[-4.98, -4.98, -4.98, ..., -4.98, -4.98, -4.98],
...,
[ 4.97, 4.97, 4.97, ..., 4.97, 4.97, 4.97],
[ 4.98, 4.98, 4.98, ..., 4.98, 4.98, 4.98],
[ 4.99, 4.99, 4.99, ..., 4.99, 4.99, 4.99]])
现在,计算函数就像写下处理两个点的同样表达式一样简单:
In [172]: z = np.sqrt(xs ** 2 + ys ** 2)
In [173]: z
Out[173]:
array([[7.0711, 7.064 , 7.0569, ..., 7.0499, 7.0569, 7.064 ],
[7.064 , 7.0569, 7.0499, ..., 7.0428, 7.0499, 7.0569],
[7.0569, 7.0499, 7.0428, ..., 7.0357, 7.0428, 7.0499],
...,
[7.0499, 7.0428, 7.0357, ..., 7.0286, 7.0357, 7.0428],
[7.0569, 7.0499, 7.0428, ..., 7.0357, 7.0428, 7.0499],
[7.064 , 7.0569, 7.0499, ..., 7.0428, 7.0499, 7.0569]])
作为第9章:绘图与可视化的一个预览,我使用matplotlib来创建这个二维数组的可视化:
In [174]: import matplotlib.pyplot as plt
In [175]: plt.imshow(z, cmap=plt.cm.gray, extent=[-5, 5, -5, 5])
Out[175]: <matplotlib.image.AxesImage at 0x17f04b040>
In [176]: plt.colorbar()
Out[176]: <matplotlib.colorbar.Colorbar at 0x1810661a0>
In [177]: plt.title("Image plot of $\sqrt{x^2 + y^2}$ for a grid of values")
Out[177]: Text(0.5, 1.0, 'Image plot of $\\sqrt{x^2 + y^2}$ for a grid of values'
)
在绘制网格上的函数值图时,我使用了matplotlib的 imshow 函数从函数值的二维数组创建了一个图像图。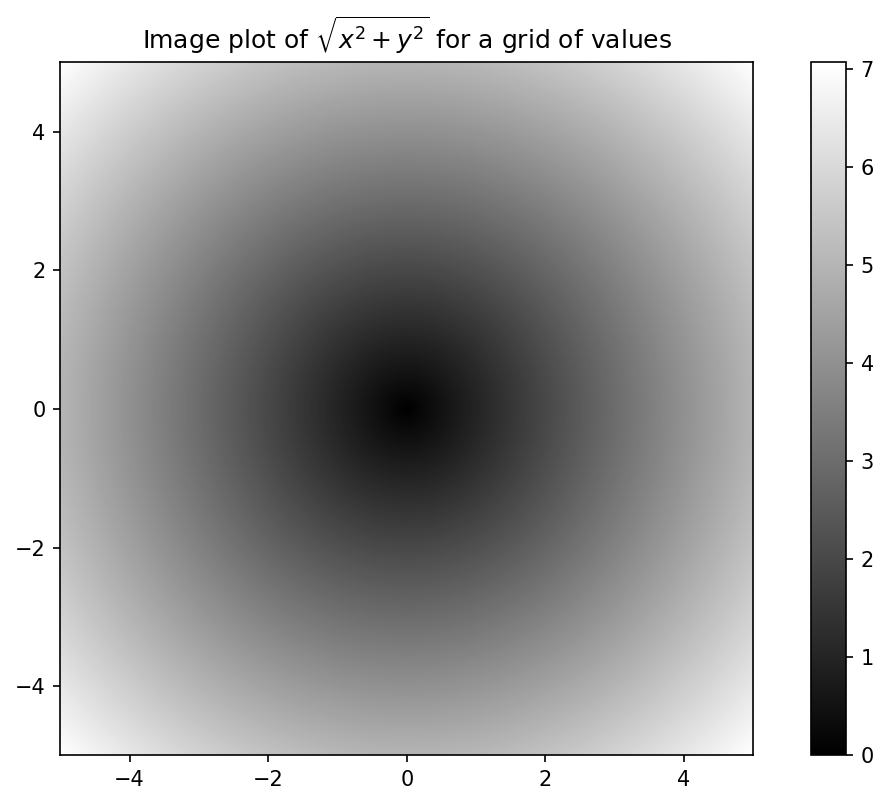
(图4.3:网格上函数值的图像图)
如果你在IPython中工作,可以执行 plt.close("all") 来关闭所有打开的绘图窗口:
In [179]: plt.close("all")
注意:术语向量化在计算机科学中用来描述一些其他概念,但在本书中,我用它来描述一次性在整个数据数组上进行操作,而不是通过Python的
for循环逐个值地处理。
将条件逻辑表达为数组操作
numpy.where 函数是三元表达式 x if condition else y 的向量化版本。假设我们有一个布尔数组和两个值数组:
In [180]: xarr = np.array([1.1, 1.2, 1.3, 1.4, 1.5])
In [181]: yarr = np.array([2.1, 2.2, 2.3, 2.4, 2.5])
In [182]: cond = np.array([True, False, True, True, False])
假设我们想根据 cond 中的值,当为 True 时从 xarr 中取值,否则从 yarr 中取值。用列表推导式实现可能如下:
In [183]: result = [(x if c else y)
.....: for x, y, c in zip(xarr, yarr, cond)]
In [184]: result
Out[184]: [1.1, 2.2, 1.3, 1.4, 2.5]
这存在几个问题。首先,对于大型数组来说,它不会很快(因为所有工作都在解释型Python代码中完成)。其次,它无法用于多维数组。使用 np.where,你可以通过一个函数调用来完成:
In [185]: result = np.where(cond, xarr, yarr)
In [186]: result
Out[186]: array([1.1, 2.2, 1.3, 1.4, 2.5])
np.where 的第二和第三个参数不一定是数组;它们中的一个或两个都可以是标量。在数据分析中,where 的一个典型用途是根据另一个数组产生一个新的值数组。假设你有一个随机生成的数据矩阵,并且你想将所有正值替换为2,将所有负值替换为-2。使用 np.where 可以实现:
In [187]: arr = rng.standard_normal((4, 4))
In [188]: arr
Out[188]:
array([[ 2.6182, 0.7774, 0.8286, -0.959 ],
[-1.2094, -1.4123, 0.5415, 0.7519],
[-0.6588, -1.2287, 0.2576, 0.3129],
[-0.1308, 1.27 , -0.093 , -0.0662]])
In [189]: arr > 0
Out[189]:
array([[ True, True, True, False],
[False, False, True, True],
[False, False, True, True],
[False, True, False, False]])
In [190]: np.where(arr > 0, 2, -2)
Out[190]:
array([[ 2, 2, 2, -2],
[-2, -2, 2, 2],
[-2, -2, 2, 2],
[-2, 2, -2, -2]])
你可以将标量和数组组合在一起使用 np.where。例如,我可以像这样将 arr 中的所有正值替换为常数2:
In [191]: np.where(arr > 0, 2, arr) # 只将正值设为2
Out[191]:
array([[ 2. , 2. , 2. , -0.959 ],
[-1.2094, -1.4123, 2. , 2. ],
[-0.6588, -1.2287, 2. , 2. ],
[-0.1308, 2. , -0.093 , -0.0662]])
补充讲解:
np.where在嵌套条件或多重判断时非常强大。你也可以将np.where的结果作为另一个np.where的参数,或者与np.select结合使用来处理多条件情况。np.select(condlist, choicelist, default)可以按照顺序检查多个条件,并返回第一个为真条件对应的选择,这是对多重if-elif-else结构的向量化。
数学与统计方法
一组计算整个数组或沿某个轴的数据统计量的数学函数,可以作为数组类的方法来调用。你可以使用聚合函数(有时称为规约(reduction)),如 sum、mean 和 std(标准差),既可以通过调用数组实例方法,也可以使用顶层的NumPy函数。当你使用NumPy函数时,比如 np.sum,你必须将想要聚合的数组作为第一个参数传入。
这里我生成一些正态分布的随机数据,并计算一些聚合统计量:
In [192]: arr = rng.standard_normal((5, 4))
In [193]: arr
Out[193]:
array([[-1.1082, 0.136 , 1.3471, 0.0611],
[ 0.0709, 0.4337, 0.2775, 0.5303],
[ 0.5367, 0.6184, -0.795 , 0.3 ],
[-1.6027, 0.2668, -1.2616, -0.0713],
[ 0.474 , -0.4149, 0.0977, -1.6404]])
In [194]: arr.mean()
Out[194]: -0.08719744457434529
In [195]: np.mean(arr)
Out[195]: -0.08719744457434529
In [196]: arr.sum()
Out[196]: -1.743948891486906
像 mean 和 sum 这样的函数接受一个可选的 axis 参数,该参数用于沿给定轴计算统计量,产生一个少一维的数组:
In [197]: arr.mean(axis=1)
Out[197]: array([ 0.109 , 0.3281, 0.165 , -0.6672, -0.3709])
In [198]: arr.sum(axis=0)
Out[198]: array([-1.6292, 1.0399, -0.3344, -0.8203])
这里,arr.mean(axis=1) 表示“跨列计算均值”,而 arr.sum(axis=0) 表示“沿行向下求和”。
💡 建议:
axis参数的概念是NumPy中的核心思想之一。你可以想象axis=0指沿着行的方向向下操作(作用于列),结果是压缩了行;axis=1指沿着列的方向操作(作用于行),结果是压缩了列。掌握这一点对于多维数组处理至关重要。
其他方法,如 cumsum 和 cumprod,则不进行聚合,而是产生包含中间结果的数组:
In [199]: arr = np.array([0, 1, 2, 3, 4, 5, 6, 7])
In [200]: arr.cumsum()
Out[200]: array([ 0, 1, 3, 6, 10, 15, 21, 28])
在多维数组中,像 cumsum 这样的累积函数返回一个相同大小的数组,但会沿指定轴根据每个较低维度的切片计算部分聚合值:
In [201]: arr = np.array([[0, 1, 2], [3, 4, 5], [6, 7, 8]])
In [202]: arr
Out[202]:
array([[0, 1, 2],
[3, 4, 5],
[6, 7, 8]])
表达式 arr.cumsum(axis=0) 沿行计算累积和,而 arr.cumsum(axis=1) 则跨列计算累积和:
In [203]: arr.cumsum(axis=0)
Out[203]:
array([[ 0, 1, 2],
[ 3, 5, 7],
[ 9, 12, 15]])
In [204]: arr.cumsum(axis=1)
Out[204]:
array([[ 0, 1, 3],
[ 3, 7, 12],
[ 6, 13, 21]])
完整列表见表4.6。我们将在后续章节中看到许多这些方法的应用示例。
表4.6:基础数组统计方法
| 方法 | 描述 |
|---|---|
sum |
数组中所有元素或沿某个轴的元素之和;零长度数组的和为0 |
mean |
算术平均值;对于零长度数组无效(返回 NaN) |
std, var |
分别为标准差和方差 |
min, max |
最小值和最大值 |
argmin, argmax |
分别为最小值和最大值的索引 |
cumsum |
从0开始元素的累积和 |
cumprod |
从1开始元素的累积乘积 |
布尔数组的方法
布尔值在这些方法中会被强制转换为1(True)和0(False)。因此,sum 常被用作统计布尔数组中 True 值个数的一种手段:
In [205]: arr = rng.standard_normal(100)
In [206]: (arr > 0).sum() # 正值的个数
Out[206]: 48
In [207]: (arr <= 0).sum() # 非正值的个数
Out[207]: 52
表达式 (arr > 0).sum() 中的括号是必需的,以便能够在 arr > 0 的临时结果上调用 sum()。
另外两个方法 any 和 all 对于布尔数组尤其有用。any 测试数组中是否有一个或多个值为 True,而 all 检查是否所有值都是 True:
In [208]: bools = np.array([False, False, True, False])
In [209]: bools.any()
Out[209]: True
In [210]: bools.all()
Out[210]: False
这些方法也适用于非布尔数组,其中非零元素被视为 True。
排序
像Python内置的列表类型一样,NumPy数组可以使用 sort 方法进行就地排序:
In [211]: arr = rng.standard_normal(6)
In [212]: arr
Out[212]: array([ 0.0773, -0.6839, -0.7208, 1.1206, -0.0548, -0.0824])
In [213]: arr.sort()
In [214]: arr
Out[214]: array([-0.7208, -0.6839, -0.0824, -0.0548, 0.0773, 1.1206])
你可以通过将轴编号传递给 sort 来就地对多维数组沿某个轴的每个一维数据段进行排序。以这个数据为例:
In [215]: arr = rng.standard_normal((5, 3))
In [216]: arr
Out[216]:
array([[ 0.936 , 1.2385, 1.2728],
[ 0.4059, -0.0503, 0.2893],
[ 0.1793, 1.3975, 0.292 ],
[ 0.6384, -0.0279, 1.3711],
[-2.0528, 0.3805, 0.7554]])
arr.sort(axis=0) 排序每一列中的值,而 arr.sort(axis=1) 则排序每一行中的值:
In [217]: arr.sort(axis=0)
In [218]: arr
Out[218]:
array([[-2.0528, -0.0503, 0.2893],
[ 0.1793, -0.0279, 0.292 ],
[ 0.4059, 0.3805, 0.7554],
[ 0.6384, 1.2385, 1.2728],
[ 0.936 , 1.3975, 1.3711]])
In [219]: arr.sort(axis=1)
In [220]: arr
Out[220]:
array([[-2.0528, -0.0503, 0.2893],
[-0.0279, 0.1793, 0.292 ],
[ 0.3805, 0.4059, 0.7554],
[ 0.6384, 1.2385, 1.2728],
[ 0.936 , 1.3711, 1.3975]])
顶层的 np.sort 方法返回数组的排序后副本(类似于Python内置的 sorted 函数),而不是就地修改数组。例如:
In [221]: arr2 = np.array([5, -10, 7, 1, 0, -3])
In [222]: sorted_arr2 = np.sort(arr2)
In [223]: sorted_arr2
Out[223]: array([-10, -3, 0, 1, 5, 7])
关于使用NumPy排序方法以及诸如间接排序等更高级技术的更多细节,请参阅附录A:高级NumPy。其他几种与排序相关的数据操作(例如,按一列或多列对数据表进行排序)也可以在pandas中找到。
唯一值与其他集合逻辑
NumPy为一维ndarray提供了一些基本的集合操作。一个常用的函数是 np.unique,它返回数组中排序后的唯一值:
In [224]: names = np.array(["Bob", "Will", "Joe", "Bob", "Will", "Joe", "Joe"])
In [225]: np.unique(names)
Out[225]: array(['Bob', 'Joe', 'Will'], dtype='<U4')
In [226]: ints = np.array([3, 3, 3, 2, 2, 1, 1, 4, 4])
In [227]: np.unique(ints)
Out[227]: array([1, 2, 3, 4])
将 np.unique 与纯Python的替代方案进行比较:
In [228]: sorted(set(names))
Out[228]: ['Bob', 'Joe', 'Will']
在许多情况下,NumPy版本更快,并且返回的是NumPy数组而不是Python列表。
另一个函数 np.in1d 测试一个数组中的值是否在另一个数组中,返回一个布尔数组:
In [229]: values = np.array([6, 0, 0, 3, 2, 5, 6])
In [230]: np.in1d(values, [2, 3, 6])
Out[230]: array([ True, False, False, True, True, False, True])
NumPy中的数组集合操作列表见表4.7。
表4.7:数组集合操作
| 方法 | 描述 |
|---|---|
unique(x) |
计算 x 中排序后的唯一元素 |
intersect1d(x, y) |
计算 x 和 y 中排序后的公共元素 |
union1d(x, y) |
计算元素的排序并集 |
in1d(x, y) |
计算一个布尔数组,指示 x 中的每个元素是否包含在 y 中 |
setdiff1d(x, y) |
集合差,在 x 中但不在 y 中的元素 |
setxor1d(x, y) |
集合对称差;在任一数组中但不同时在两者中的元素 |
4.5 数组的文件输入与输出
NumPy能够以一些文本或二进制格式将数据保存到磁盘以及从磁盘加载。在本节中,我只讨论NumPy的内置二进制格式,因为大多数用户会更倾向于使用pandas和其他工具来加载文本或表格数据(详见第6章:数据载入、存储与文件格式)。
np.save 和 np.load 是高效保存和加载磁盘数组数据的两个主力函数。默认情况下,数组以未压缩的原始二进制格式保存,文件扩展名为 .npy:
In [231]: arr = np.arange(10)
In [232]: np.save("some_array", arr)
如果文件路径尚未以 .npy 结尾,扩展名会被自动附加。然后可以用 np.load 加载磁盘上的数组:
In [233]: np.load("some_array.npy")
Out[233]: array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
你可以使用 np.savez 将多个数组保存到一个未压缩的归档文件中,并将数组作为关键字参数传入:
In [234]: np.savez("array_archive.npz", a=arr, b=arr)
加载 .npz 文件时,你会得到一个类似字典的对象,它可以延迟加载各个数组:
In [235]: arch = np.load("array_archive.npz")
In [236]: arch["b"]
Out[236]: array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
如果你的数据压缩效果良好,你可能希望使用 np.savez_compressed:
In [237]: np.savez_compressed("arrays_compressed.npz", a=arr, b=arr)
💡 建议:对于中小规模的数值数组,
.npy格式是序列化到磁盘的最快方式,并且能保持精度和形状元数据。但对于需要跨语言共享或长期存档的场景,像HDF5(结合h5py或PyTables)或Apache Parquet等格式可能更具优势。此外,np.savez_compressed默认使用zip压缩,对于稀疏或重复性高的数据可以大幅缩减文件体积。
4.6 线性代数
线性代数操作,例如矩阵乘法、分解、行列式以及其他方阵数学,是许多数组库的重要组成部分。用 * 将两个二维数组相乘是逐元素乘积,而矩阵乘法需要使用 dot 函数或中缀运算符 @。dot 既是一个数组方法,也是 numpy 命名空间中的一个函数,用于执行矩阵乘法:
In [241]: x = np.array([[1., 2., 3.], [4., 5., 6.]])
In [242]: y = np.array([[6., 23.], [-1, 7], [8, 9]])
In [243]: x
Out[243]:
array([[1., 2., 3.],
[4., 5., 6.]])
In [244]: y
Out[244]:
array([[ 6., 23.],
[-1., 7.],
[ 8., 9.]])
In [245]: x.dot(y)
Out[245]:
array([[ 28., 64.],
[ 67., 181.]])
x.dot(y) 等价于 np.dot(x, y):
In [246]: np.dot(x, y)
Out[246]:
array([[ 28., 64.],
[ 67., 181.]])
一个二维数组与一个尺寸合适的一维数组之间的矩阵乘积会产生一个一维数组:
In [247]: x @ np.ones(3)
Out[247]: array([ 6., 15.])
numpy.linalg 提供了一套标准的矩阵分解以及诸如逆和行列式等操作:
In [248]: from numpy.linalg import inv, qr
In [249]: X = rng.standard_normal((5, 5))
In [250]: mat = X.T @ X
In [251]: inv(mat)
Out[251]:
array([[ 3.4993, 2.8444, 3.5956, -16.5538, 4.4733],
[ 2.8444, 2.5667, 2.9002, -13.5774, 3.7678],
[ 3.5956, 2.9002, 4.4823, -18.3453, 4.7066],
[-16.5538, -13.5774, -18.3453, 84.0102, -22.0484],
[ 4.4733, 3.7678, 4.7066, -22.0484, 6.0525]])
In [252]: mat @ inv(mat)
Out[252]:
array([[ 1., 0., 0., 0., 0.],
[ 0., 1., 0., 0., 0.],
[ 0., 0., 1., -0., 0.],
[ 0., 0., 0., 1., 0.],
[-0., 0., 0., 0., 1.]])
表达式 X.T.dot(X) 计算 X 与其转置 X.T 的点积。
表4.8列出了一些最常用的线性代数函数。
表4.8:numpy.linalg 中常用的函数
| 函数 | 描述 |
|---|---|
diag |
将方阵的对角线(或非对角线)元素返回为一维数组,或将一维数组转换为对角线外为零的方阵 |
dot |
矩阵乘法 |
trace |
计算对角线元素之和 |
det |
计算矩阵行列式 |
eig |
计算方阵的特征值和特征向量 |
inv |
计算方阵的逆 |
pinv |
计算矩阵的Moore-Penrose伪逆 |
qr |
计算QR分解 |
svd |
计算奇异值分解(SVD) |
solve |
求解线性系统 Ax = b 中的 x,其中 A 是方阵 |
lstsq |
计算 Ax = b 的最小二乘解 |
补充讲解:线性代数模块
numpy.linalg对于科学计算和机器学习非常重要。特别是pinv(伪逆)在处理奇异矩阵或非方阵时很有用;svd(奇异值分解)在降维(如PCA)、推荐系统等领域有广泛应用。记住,大部分矩阵分解函数返回的结果是元组,需要按照文档解包使用。在处理大型矩阵时,也可以考虑使用scipy.linalg,它提供了更多高级功能且有时效率更高。
4.7 示例:随机游走
随机游走的模拟是应用数组操作的一个说明性例子。我们首先考虑一个简单的随机游走,从0开始,步长为1和-1,并以相等的概率出现。
下面是用纯Python方式使用内置 random 模块实现一个1000步的单次随机游走:
#! blockstart
import random
position = 0
walk = [position]
nsteps = 1000
for _ in range(nsteps):
step = 1 if random.randint(0, 1) else -1
position += step
walk.append(position)
#! blockend
图4.4展示了其中一次随机游走前100个值的示例图:
In [255]: plt.plot(walk[:100])
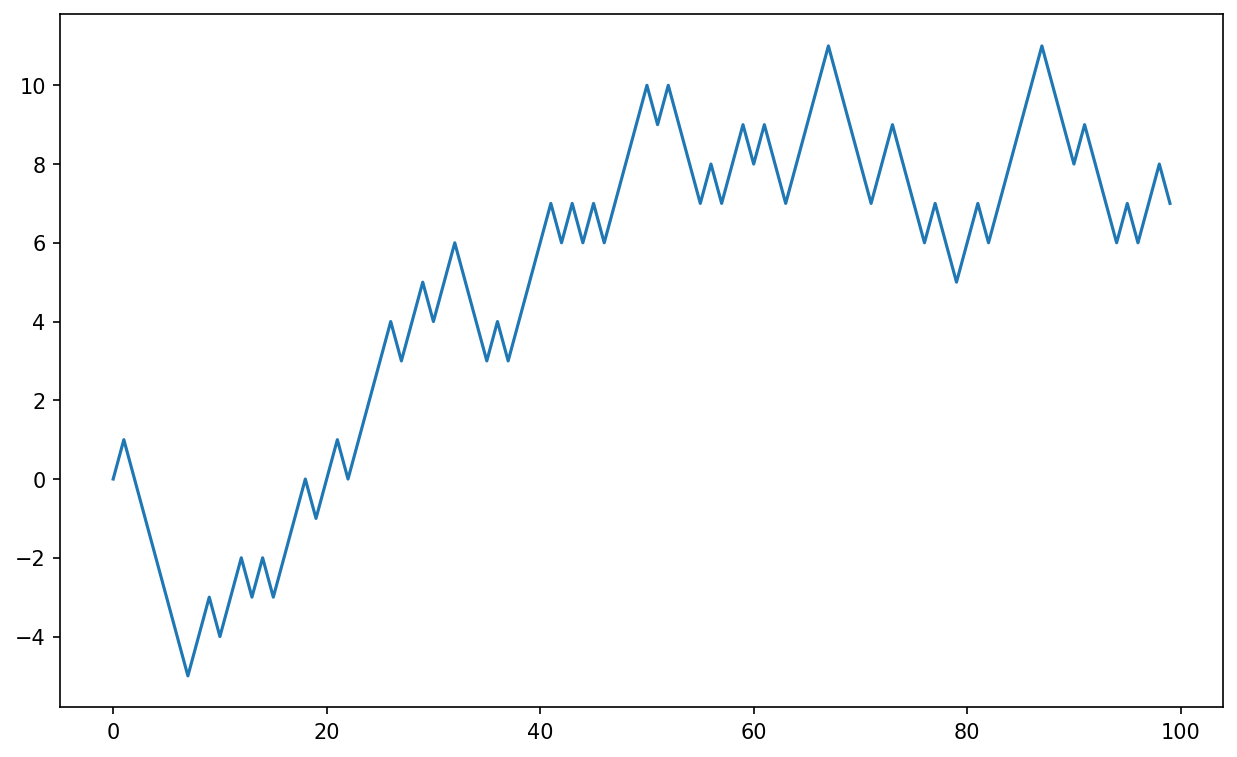
(图4.4:一个简单的随机游走)
你可能会观察到,walk 是随机步长的累积和,可以通过数组表达式计算。因此,我使用 np.random 模块一次抽取1000次投掷硬币的结果,将它们设置为1和-1,然后计算累积和:
In [256]: nsteps = 1000
In [257]: rng = np.random.default_rng(seed=12345) # 新随机数生成器
In [258]: draws = rng.integers(0, 2, size=nsteps)
In [259]: steps = np.where(draws == 0, 1, -1)
In [260]: walk = steps.cumsum()
从这里我们可以开始提取统计量,比如游走轨迹上的最小值和最大值:
In [261]: walk.min()
Out[261]: -8
In [262]: walk.max()
Out[262]: 50
一个更复杂的统计量是首次穿越时间(first crossing time),即随机游走到达某个特定值的步数。这里我们可能想知道随机游走到达距离原点0至少10步的位置(无论哪个方向)花了多长时间。np.abs(walk) >= 10 给了我们一个布尔数组,指示游走何时达到或超过10,但我们想要第一个10或-10的索引。事实证明,我们可以用 argmax 来计算,它会返回布尔数组中最大值(True 是最大值)的第一个索引:
In [263]: (np.abs(walk) >= 10).argmax()
Out[263]: 155
补充讲解:请注意,这里使用
argmax并非总是高效的,因为它总是会对数组进行完整扫描。在这种特殊情况下,一旦观察到True,我们就知道它是最大值。但对于一次性的计算,这通常不是问题,代码简洁性更重要。如果你需要监控超大规模游走中的首次穿越,可以考虑用循环并在条件满足时提前终止。
一次模拟多次随机游走
如果你的目标是模拟多次随机游走,比如5000次,你可以通过对前面的代码进行微小修改来一次性生成所有随机游走。如果向 np.random 函数传入一个2元组,size 参数将生成一个二维抽取数组,我们可以为每一行计算累积和,从而一次性计算所有5000次随机游走:
In [264]: nwalks = 5000
In [265]: nsteps = 1000
In [266]: draws = rng.integers(0, 2, size=(nwalks, nsteps)) # 0 或 1
In [267]: steps = np.where(draws > 0, 1, -1)
In [268]: walks = steps.cumsum(axis=1)
In [269]: walks
Out[269]:
array([[ 1, 2, 3, ..., 22, 23, 22],
[ 1, 0, -1, ..., -50, -49, -48],
[ 1, 2, 3, ..., 50, 49, 48],
...,
[ -1, -2, -1, ..., -10, -9, -10],
[ -1, -2, -3, ..., 8, 9, 8],
[ -1, 0, 1, ..., -4, -3, -2]])
现在,我们可以计算所有游走中获得的最大值和最小值:
In [270]: walks.max()
Out[270]: 114
In [271]: walks.min()
Out[271]: -120
在这些游走中,让我们计算首次穿越到30或-30的最小时间。这稍微有点棘手,因为5000次游走中并非所有的都能达到30。我们可以使用 any 方法来检查:
In [272]: hits30 = (np.abs(walks) >= 30).any(axis=1)
In [273]: hits30
Out[273]: array([False, True, True, ..., True, False, True])
In [274]: hits30.sum() # 达到30或-30的数量
Out[274]: 3395
我们可以用这个布尔数组来选择 walks 中实际穿越绝对30水平的行,并沿着轴1调用 argmax 来获取穿越时间:
In [275]: crossing_times = (np.abs(walks[hits30]) >= 30).argmax(axis=1)
In [276]: crossing_times
Out[276]: array([201, 491, 283, ..., 219, 259, 541])
最后,我们计算平均最小穿越时间:
In [277]: crossing_times.mean()
Out[277]: 500.5699558173785
你可以尝试为步长使用除等概率硬币投掷之外的其他分布。你只需要使用不同的随机生成器方法,例如 standard_normal 来生成具有某个均值和标准差的正态分布步长:
In [278]: draws = 0.25 * rng.standard_normal((nwalks, nsteps))
注意:请记住,这种向量化方法需要创建一个包含
nwalks * nsteps个元素的数组,对于大规模模拟来说可能使用大量内存。如果内存更加受限,则需要采用不同的方法。
💡 建议:这个随机游走示例完美展示了向量化思维的力量。在pandas或纯Python中,你可能会想到用循环处理每次游走和每个步长,但NumPy允许你在高维数组上进行“批量”操作。这种思维模式在金融模拟、物理建模等需要大量随机路径的场景中极为重要。如果你的模拟大到内存无法容纳整个数组,可以考虑分批(chunk)计算或使用基于生成器的流式处理,例如Dask。
4.8 结论
虽然本书其余部分的大部分内容将侧重于使用pandas构建数据整理技能,但我们将继续以类似的基于数组的风格工作。在附录A:高级NumPy中,我们将更深入地挖掘NumPy特性,帮助你进一步发展数组计算技能。
更多推荐
 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)