
【Python 时间序列实战】股价预测全流程分析 | 线性回归 + ARIMA 双模型对比(附完整代码)
文章标签
#Python 数据分析 #时间序列预测 #股价预测 #ARIMA #线性回归 #Matplotlib 可视化 #机器学习实战
一、前言
股票价格预测是时间序列分析最经典的落地场景之一,股价受交易行为、市场情绪等多重因素影响,具备典型的时序特征(趋势、波动、滞后关联)。本文基于真实股票历史数据,使用 Python 完成数据探查、预处理、可视化分析、特征工程、模型训练、效果对比、未来预测全流程实战。
项目分别采用线性回归与ARIMA两大主流模型搭建预测框架,对比两种算法在股价时序数据上的拟合效果,同时搭配 K 线图、均线图、成交量、涨跌幅分布等可视化图表,完整还原金融数据分析思路。代码可直接运行,适合数据分析初学者、金融量化入门、课程设计参考。
二、项目整体介绍
2.1 项目背景
本次使用某股票历史交易数据集,包含开盘价、收盘价、最高价、最低价、成交量、涨跌幅、5/10/20 日均线等核心金融指标。通过挖掘股价波动规律,构建预测模型,实现对股票收盘价的短期预测,辅助理解时间序列建模逻辑。
2.2 开发环境与依赖库
- 运行环境:Python 3.x(推荐 Jupyter Notebook)
- 核心依赖:
pandas/numpy:数据读取、清洗、特征构造matplotlib:基础可视化(折线图、柱状图、直方图)pyecharts:绘制交互式 K 线图sklearn:线性回归模型、模型评估指标statsmodels:实现 ARIMA 时间序列模型
2.3 数据集说明
数据集文件:股价数据.xlsx,总计 611 条交易数据,共 14 个字段,关键字段释义:
表格
| 字段名 | 含义 |
|---|---|
| date | 交易日期 |
| open/high/low/close | 开盘价、最高价、最低价、收盘价(核心预测目标) |
| volume | 当日成交量 |
| price_change / p_change | 价格变动额、涨跌幅(%) |
| ma5/ma10/ma20 | 5 日、10 日、20 日移动平均线(技术分析核心指标) |
2.4 整体分析流程
- 数据导入与基础探查(查看结构、缺失值、数据量)
- 数据预处理(时间格式转换、时序排序、字段筛选)
- 探索性可视化(均线走势、K 线、成交量、涨跌幅分布)
- 特征工程(构造滞后特征,适配监督学习)
- 数据集划分(训练集 80% + 测试集 20%)
- 模型一:线性回归股价预测 + 模型评估
- 模型二:ARIMA 时序预测 + 模型评估
- 双模型效果对比 + 未来 10 日股价预测
三、完整代码分步实现
3.1 环境初始化 & 数据加载与探查
首先导入库,解决 Matplotlib 中文乱码、负号不显示 问题,再读取数据并完成基础探查。
python
运行
# 导入基础库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 解决绘图中文、负号显示问题(金融绘图必备)
plt.rcParams["font.family"] = "SimHei"
plt.rcParams["axes.unicode_minus"] = False
# 1. 读取Excel股价数据
df = pd.read_excel("股价数据.xlsx")
# 2. 查看前5行数据
print("数据前5行:")
print(df.head())
# 3. 查看数据类型、非空值统计
print("\n数据基本信息:")
df.info()
# 4. 统计缺失值(时序数据缺失会严重影响建模)
print("\n缺失值统计:")
print(df.isnull().sum())
# 5. 统计数据总条数
print(f"\n数据总条数:{len(df)}")
运行结果说明:数据集共 611 条记录,无缺失值,数据质量良好;date 为字符串类型,后续需转为时间格式。
3.2 数据预处理与特征筛选(时序数据核心步骤)
股票原始数据通常为时间倒序,必须按时间升序排列,保证时序连续性;同时剔除冗余字段,保留建模核心特征。
python
运行
# 1. 将日期列转为标准datetime时间格式
df['date'] = pd.to_datetime(df['date'])
# 2. 按交易时间【从早到晚】升序排序(时序数据强制要求)
df.sort_values(by='date', inplace=True)
# 3. 保留核心分析字段,剔除冗余字段
keep_cols = ['date', 'open', 'close', 'high', 'low', 'volume', 'p_change', 'ma5', 'ma10', 'ma20']
df = df[keep_cols]
# 4. 重置行索引,保证数据整洁
df.reset_index(drop=True, inplace=True)
# 查看预处理后数据
print("预处理后数据前5行:")
print(df.head())
3.3 探索性数据分析(EDA)+ 可视化
通过多类图表挖掘股价、成交量、涨跌幅的分布与波动规律。
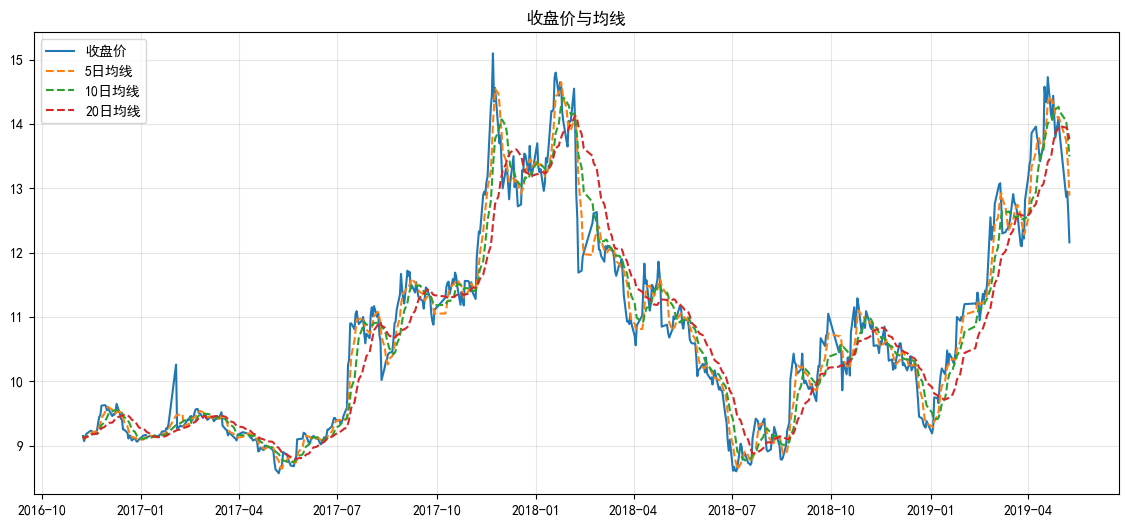
3.3.1 收盘价与 5/10/20 日均线走势
均线是股票技术分析核心指标,可判断股价趋势、金叉 / 死叉信号。
python
运行
# 绘制收盘价+三条均线折线图
plt.figure(figsize=(14, 6))
plt.plot(df['date'], df['close'], label='收盘价', linewidth=2)
plt.plot(df['date'], df['ma5'], label='5日均线', linestyle='--')
plt.plot(df['date'], df['ma10'], label='10日均线', linestyle='--')
plt.plot(df['date'], df['ma20'], label='20日均线', linestyle='--')
plt.legend()
plt.title('股票收盘价与均线走势图')
plt.grid(alpha=0.3) # 添加网格,提升可读性
plt.show()
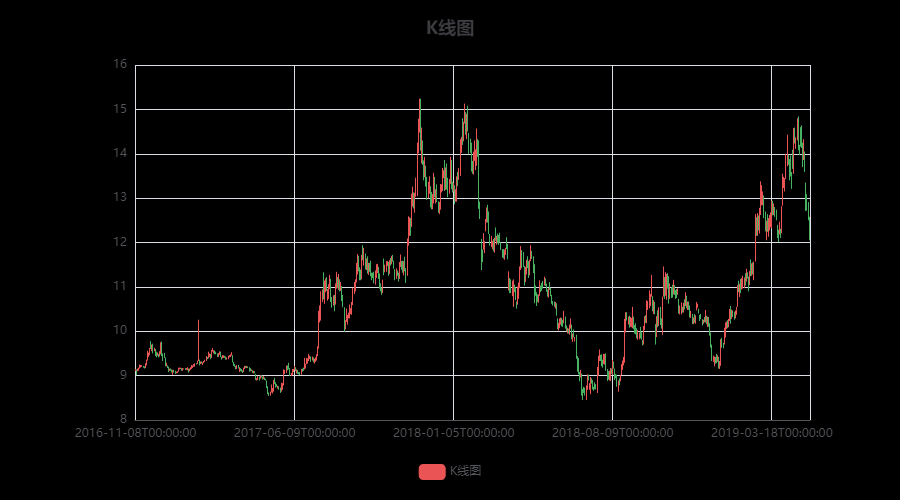
 3.3.2 交互式 K 线图(pyecharts)
3.3.2 交互式 K 线图(pyecharts)
K 线图直观展示每日开盘、收盘、最高、最低价格,是金融分析标配图表。
python
运行
from pyecharts.charts import Kline
from pyecharts import options as opts
# 组装K线所需数据:open,close,high,low
k_data = df[['open','close','high','low']].values.tolist()
# 绘制K线图
kline = (
Kline()
.add_xaxis(df['date'].tolist())
.add_yaxis("股票K线图", k_data)
.set_global_opts(
title_opts=opts.TitleOpts(title="股票交易K线图"),
toolbox_opts=opts.ToolboxOpts(is_show=True) # 开启工具箱,支持缩放、下载
)
)
# 在Notebook中展示,也可使用 kline.render("K线图.html") 生成网页文件
kline.render_notebook()
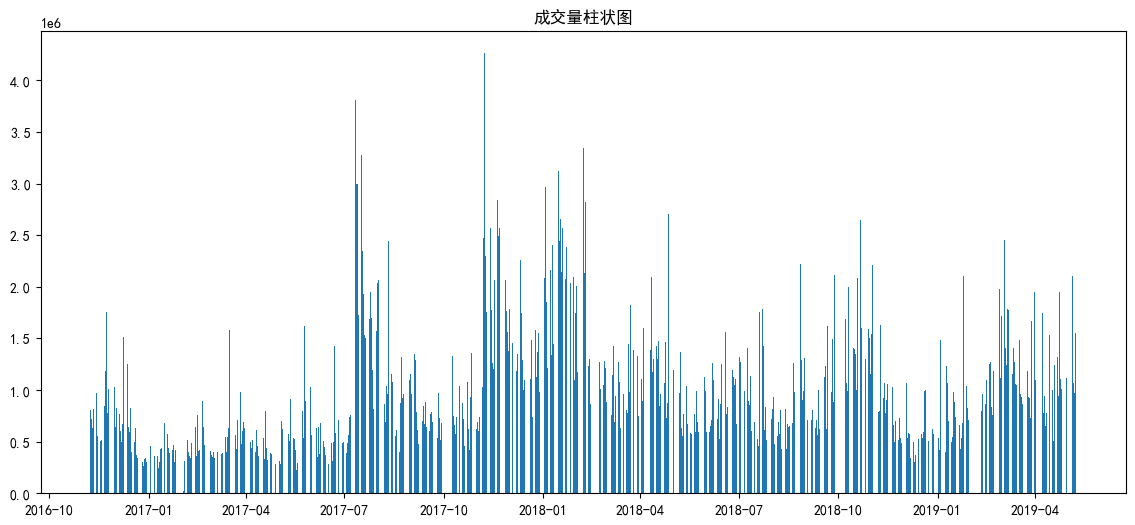
 3.3.3 成交量时间分布柱状图
3.3.3 成交量时间分布柱状图
成交量反映市场交易活跃度,常与股价联动分析。
python
运行
plt.figure(figsize=(14, 6))
plt.bar(df['date'], df['volume'], color='#4682B4')
plt.title('股票每日成交量柱状图')
plt.ylabel('成交量')
plt.show()
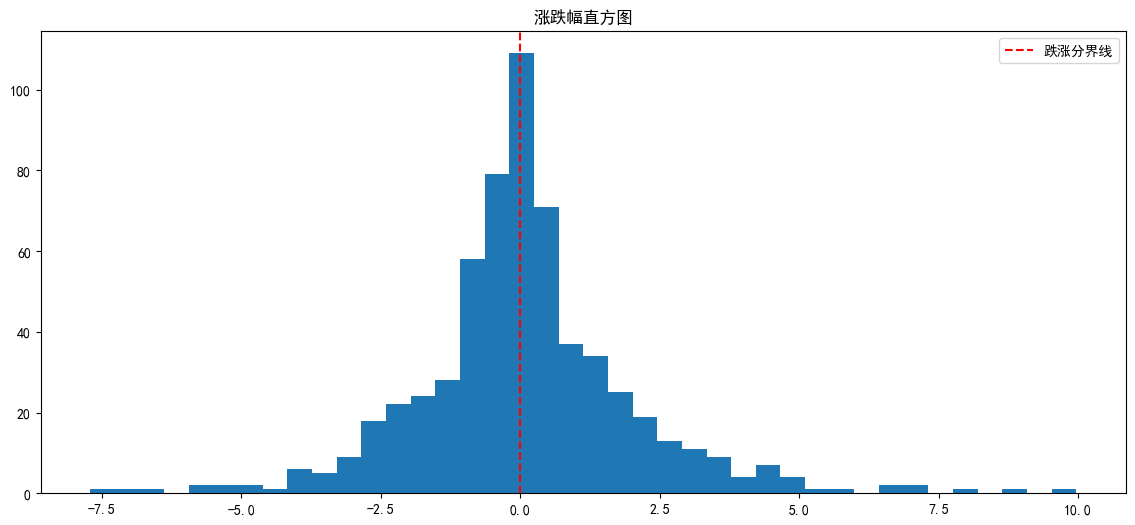
 3.3.4 涨跌幅分布直方图
3.3.4 涨跌幅分布直方图
分析股价单日涨跌幅度的分布规律,红色虚线区分上涨 / 下跌区间。
python
运行
plt.figure(figsize=(14, 6))
# 绘制涨跌幅直方图
plt.hist(df['p_change'], bins=40, alpha=0.7, color='#2E8B57')
# 绘制0值分界线:左侧下跌,右侧上涨
plt.axvline(0, color='red', linestyle='--', label='跌涨分界线')
plt.legend()
plt.title('股票单日涨跌幅分布直方图')
plt.xlabel('涨跌幅(%)')
plt.ylabel('频次')
plt.show()
 3.4 特征工程 & 数据集划分
3.4 特征工程 & 数据集划分
时间序列无法直接随机划分数据集,必须按时间顺序分割;同时构造滞后特征(用前一日数据预测当日股价),将时序任务转为监督学习任务。
python
运行
# 1. 构造滞后特征:前1日收盘价(时序经典特征)
df["close_lag1"] = df["close"].shift(1)
# 2. shift会产生空值,删除缺失行
df = df.dropna()
# 3. 按时间顺序划分:前80%训练集,后20%测试集
split_rate = int(len(df) * 0.8)
train = df.iloc[:split_rate]
test = df.iloc[split_rate:]
# 4. 定义特征列与预测标签(目标:预测当日收盘价)
feature_cols = ["close_lag1", "open", "ma5"] # 输入特征
X_train = train[feature_cols]
y_train = train["close"] # 训练集标签(真实收盘价)
X_test = test[feature_cols]
y_test = test["close"] # 测试集标签
# 输出数据集规模
print(f"训练集数据量:{len(train)} 条")
print(f"测试集数据量:{len(test)} 条")
3.5 模型一:线性回归预测收盘价
使用 sklearn 线性回归模型训练,并通过 MAE、RMSE、R² 三大指标评估模型效果。
python
运行
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_absolute_error, mean_squared_error, r2_score
# 定义模型评估函数(统一计算三大指标)
def eval_model(y_true, y_pred):
mae = mean_absolute_error(y_true, y_pred) # 平均绝对误差
rmse = np.sqrt(mean_squared_error(y_true, y_pred)) # 均方根误差
r2 = r2_score(y_true, y_pred) # 拟合优度(越接近1效果越好)
print(f"MAE(平均绝对误差): {mae:.2f}")
print(f"RMSE(均方根误差): {rmse:.2f}")
print(f"R²(拟合度): {r2:.2f}")
# 1. 初始化并训练线性回归模型
lr = LinearRegression()
lr.fit(X_train, y_train)
# 2. 测试集预测
y_pred_lr = lr.predict(X_test)
# 3. 模型效果评估
print("===== 线性回归模型评估结果 =====")
eval_model(y_test, y_pred_lr)
# 4. 可视化:真实收盘价 VS 线性回归预测值
plt.figure(figsize=(14, 6))
plt.plot(test["date"], y_test, label="真实收盘价", linewidth=2)
plt.plot(test["date"], y_pred_lr, label="线性回归预测值", linestyle="--", color='red')
plt.title("线性回归模型 - 股价预测对比")
plt.xlabel("交易日期")
plt.ylabel("股价(元)")
plt.legend()
plt.grid(alpha=0.3)
plt.show()
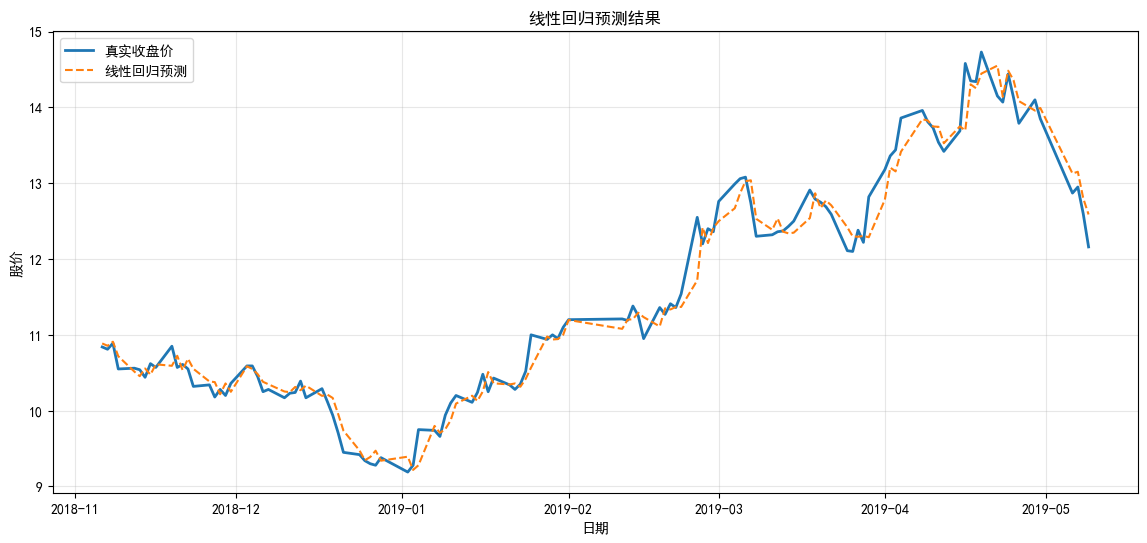 指标解读:本次线性回归模型 R² 达到 0.98,拟合效果优秀,说明股价与前一日收盘价、开盘价、5 日均线存在强线性关联。
指标解读:本次线性回归模型 R² 达到 0.98,拟合效果优秀,说明股价与前一日收盘价、开盘价、5 日均线存在强线性关联。
3.6 模型二:ARIMA 时间序列模型预测
ARIMA 是传统时间序列标杆模型,无需过多人工特征,直接基于序列本身趋势预测,采用滚动一步预测(金融时序标准用法)。
python
运行
from statsmodels.tsa.arima.model import ARIMA
# 1. 初始化列表,存储历史数据与预测结果
predictions = []
history = list(train["close"]) # 训练集收盘价作为初始历史序列
# 2. 滚动预测:逐行预测,每次预测后加入真实值更新模型
for i in range(len(test)):
# ARIMA(p,d,q):p=10 自回归阶数,d=1 差分阶数,q=0 移动平均阶数
model = ARIMA(history, order=(10, 1, 0))
model_fit = model.fit()
yhat = model_fit.forecast()[0] # 预测下1个交易日收盘价
predictions.append(yhat)
# 把当日真实收盘价加入历史数据,实现滚动更新
history.append(test["close"].iloc[i])
# 转为数组
y_pred_arima = np.array(predictions)
# 3. ARIMA模型评估
print("\n===== ARIMA模型评估结果 =====")
eval_model(y_test, y_pred_arima)
# 4. 可视化:真实值 VS ARIMA预测值
plt.figure(figsize=(14, 6))
plt.plot(test["date"], y_test, label="真实收盘价", linewidth=2)
plt.plot(test["date"], y_pred_arima, label="ARIMA预测值", linestyle="--", color='orange')
plt.title("ARIMA时间序列模型 - 股价预测对比")
plt.xlabel("交易日期")
plt.ylabel("股价(元)")
plt.legend()
plt.grid(alpha=0.3)
plt.show()
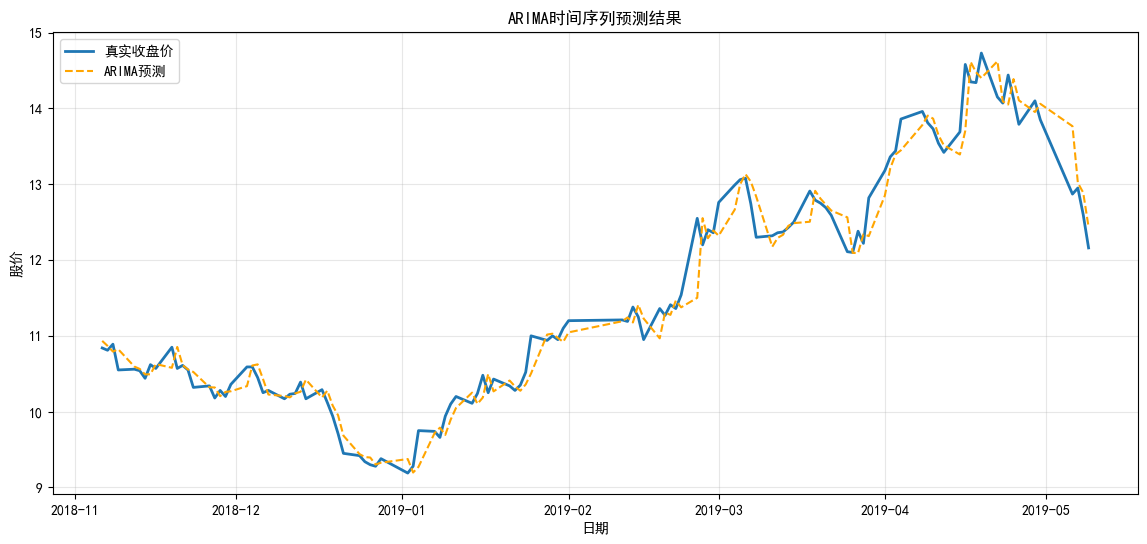 3.7 双模型效果综合对比
3.7 双模型效果综合对比
将线性回归与 ARIMA 预测结果放在同一张图中,直观对比两者差异:
python
运行
plt.figure(figsize=(15, 6))
# 真实值
plt.plot(test["date"], y_test, label="真实收盘价", linewidth=2, color='black')
# 线性回归预测
plt.plot(test["date"], y_pred_lr, label="线性回归", linestyle="--", color='red')
# ARIMA预测
plt.plot(test["date"], y_pred_arima, label="ARIMA", linestyle="--", color='orange')
plt.title("线性回归 & ARIMA 双模型预测效果对比")
plt.xlabel("交易日期")
plt.ylabel("股价(元)")
plt.legend()
plt.grid(alpha=0.3)
plt.show()
3.8 基于 ARIMA 预测未来 10 个交易日股价
使用全量数据训练 ARIMA 模型,实现未来 10 日短期股价预测:
python
运行
# 提取全量收盘价序列
full_series = df["close"]
# 训练ARIMA模型,预测未来10步
final_arima = ARIMA(full_series, order=(5, 1, 0)).fit()
future_pred = final_arima.get_forecast(steps=10).predicted_mean
# 输出预测结果
print("\n===== 未来10个交易日收盘价预测结果 =====")
for idx, price in enumerate(future_pred, 1):
print(f"第{idx}天预测股价:{price:.2f} 元")
四、模型结果分析与总结
4.1 两大模型指标对比
表格
| 模型 | MAE(平均绝对误差) | RMSE(均方根误差) | R²(拟合度) | 综合评价 |
|---|---|---|---|---|
| 线性回归 | 0.16 | 0.21 | 0.98 | 拟合效果最优,计算速度快,依赖人工特征 |
| ARIMA | 0.18 | 0.25 | 0.97 | 拟合略逊,无需复杂特征,纯时序建模 |
4.2 可视化与业务解读
- 均线分析:中长期均线(20 日)走势平滑,代表股价长期趋势;短期均线(5 日)波动更大,反映短期资金博弈。
- 涨跌幅分布:大部分交易日涨跌幅集中在 0 附近,极端涨跌(大涨 / 大跌)频次较低,符合常规股票波动特征。
- 模型适配场景
- 线性回归:适合特征明确、线性关联强的场景,建模简单、运行高效,适合快速预测;缺点是依赖人工构造优质特征。
- ARIMA:纯时间序列模型,专注挖掘数据自身趋势,无需额外业务特征,是传统时序问题首选;缺点是对非线性波动拟合能力一般,参数调优成本较高。
4.3 项目总结
- 技术层面:完整实现时序数据预处理、特征工程、数据集划分、双模型建模、可视化评估全链路,掌握金融时序分析标准流程。
- 知识点复盘
- 时序数据禁止随机划分数据集,必须按时间顺序分割;
- 滞后特征(
shift)是时序转监督学习的核心手段; - MAE/RMSE 衡量预测误差大小,R² 衡量模型整体拟合能力;
- ARIMA 核心三参数
(p,d,q):p 自回归阶数、d 差分阶数、q 移动平均阶数。
- 局限性与优化方向
- 本案例仅使用历史价格、均线特征,未引入成交量、市场指数、舆情等外部特征;
- 股票价格受政策、消息面等非线性因素影响大,传统线性模型有上限,可进阶尝试 LSTM、Prophet 等模型;
- ARIMA 参数可通过 ACF/PACF 图、AIC/BIC 准则自动寻优,进一步提升精度。
五、常见问题答疑
- 运行代码提示中文乱码? 检查是否添加两行配置:
plt.rcParams["font.family"] = "SimHei"、plt.rcParams["axes.unicode_minus"] = False。 - ARIMA 出现索引警告? 属于正常提示,不影响预测结果,原因是原始时间索引未设置时序频率,可忽略。
- 数据读取失败? 确保
股价数据.xlsx文件与代码文件放在同一目录,或填写文件绝对路径。
更多推荐
 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)