
Java 转大模型开发:从场景选择到效果验证
聊《Java 转大模型开发:从场景选择到效果验证》之前,先说一句实在的:别急着背概念,先看它在真实项目里到底解决什么问题。
摘要
本文概述文章目标、核心观点和实践价值。
> 摘要:本文梳理 Java 后端工程师转向大模型应用开发的实战路径。避开盲目补算法理论的误区,聚焦工程能力迁移、技术栈选型(Spring AI/LangChain4j)、RAG 项目构建与面试表达策略。附带关键代码示例与避坑指南,适合准备转型的后端开发者参考。
目录
- Java 开发者的优势
- 需要补齐的 AI 技能
- Spring AI 与 LangChain4j
- 项目练习
- 面试准备
- 总结
Java 开发者的优势
刚把公司内部的文档检索系统从传统 Elasticsearch 迁移到 RAG 架构时,我踩过不少坑。很多 Java 兄弟看到“大模型开发”就想去啃 PyTorch 或者从头推导 Transformer 底层。说实话,这条路走偏了。企业招的不是算法研究员,是能把手头业务接上 LLM 并跑通工程链路的人。
别低估你们手里的牌。大模型应用目前大半工作量还是工程活:并发控制、缓存策略、异步编排、API 契约设计、权限校验、日志追踪。这些你们闭着眼睛都能写。AI 团队最头疼的往往不是模型调参,而是怎么把幻觉控制在可接受范围,怎么保证接口在高并发下不崩,怎么把非结构化数据清洗入库。你们习惯的单元测试、CI/CD、微服务治理,直接平移过去就是降维打击。
但有个陷阱要避开:过度设计。以前做电商订单系统,你得搞状态机、补偿事务、分布式锁。接到 LLM 任务时,如果上来就套完整的领域驱动设计加复杂的工作流引擎,反而会把简单问题复杂化。大模型的输入输出是概率性的,流程容错率和确定性系统完全不同。先跑通主链路,再考虑优雅降级,这是工程思维的转变。
需要补齐的 AI 技能
学习顺序比学什么更重要。我建议按这个优先级来,少走弯路:
第一层,Python 基础语法和常用库(requests, pandas)。不用精通,能看懂社区案例、跑通官方 Demo 就行。很多现成的工具链只维护 Python 版,硬用 Java 轮子效率极低,沟通成本也会拉高。
第二层,Prompt 工程不是背模板,而是理解上下文窗口、Token 计费逻辑和结构化的输出约束。学会用 Few-shot 和 JSON Schema 让模型乖乖吐你要的格式。遇到模型偶尔“抽风”,先查指令边界,再调 temperature。
第三层,向量数据库与分块策略(Chunking)。这是 RAG 的命门。怎么切文档?Overlap 设多少?元数据怎么打?切不好,后面检索永远对不上号。别一上来就追求最新开源模型,先把本地 Milvus 或 ChromaDB 跑起来,用你手头的 PDF 练手。记录每次切分粒度对应的检索命中率,用数据说话。
第四层,评估指标。准确率、召回率、延迟、成本。没有量化标准,AI 项目永远没法交差。学会用 Ragas 或自写脚本对比不同 prompt 和检索策略的效果。
误区提示:别去死磕数学公式。注意力机制原理知道即可,重点是用好封装好的 SDK。你的价值在于把模型能力封装成稳定可靠的业务接口,而不是重新发明轮子。

Spring AI 与 LangChain4j
Java 生态这两年其实挺务实的。主流框架就两个:LangChain4j 和 Spring AI。个人建议,如果你已经在用 Spring Boot,优先看 Spring AI。它跟 ApplicationContext 整合得更顺,配置声明式,Bean 管理顺手,团队交接成本低。LangChain4j 胜在灵活,插件生态丰富,但上手曲线陡一点,配置分散。
拿 Spring AI 举个例子,接入一个合规的 LLM 并不复杂。关键是统一抽象,别让业务代码里到处飘 HTTP 请求调模型接口。下面这段代码演示了如何把检索和生成解耦,保持业务逻辑干净:
@Service
public class DocumentQaService {
private final ChatClient chatClient;
private final VectorStore vectorStore;
public DocumentQaService(ChatClient.Builder chatClientBuilder, VectorStore vectorStore) {
this.chatClient = chatClientBuilder.build();
this.vectorStore = vectorStore;
}
public String answer(String question) {
// 1. 检索相关片段
List<ChatMemoryMessage> context = vectorStore.search(question);
if (context.isEmpty()) {
return "当前知识库暂无匹配内容,请补充文档或调整检索策略。";
}
// 2. 组装提示词
String prompt = """
基于以下已知信息,简洁准确地回答用户问题。
如果无法回答,请直接说明“未找到相关信息”。
\n已知信息:%s
\n用户问题:%s
""".formatted(context.stream().map(Object::toString).collect(Collectors.joining("\n")), question);
// 3. 调用模型
return chatClient.prompt()
.user(prompt)
.call()
.content();
}
}注意代码里的 `vectorStore.search` 在生产环境需要处理分页、相似度阈值过滤(比如 cosineSimilarity < 0.6 直接丢弃)。这段代码的核心意图是展示如何将检索和生成解耦,保持业务逻辑干净。实际项目中,建议加上流式输出(Streaming)和超时熔断,否则一次慢查询能把线程池拖垮。
项目练习
简历上放“基于 LangChain 的聊天机器人”基本等于没写。面试官每天看几十个这种 demo。换个思路,做一个带完整工程规范的内部知识库助手。比如:支持多格式文档上传(PDF/Markdown)、自动清洗排版乱码、分段向量化、支持对话历史记忆、提供管理后台查看检索命中详情。
难点不在接模型,而在数据流转。比如用户上传了一份 50 页的技术规范,里面夹杂大量表格和代码块。传统的文本切割会直接把表格内容打散,导致检索失效。你得引入 OCR 预处理,或者用特定规则识别代码块边界,单独存入向量库并打上 `code_block` 标签。这种细节才是区分“调包侠”和“能干活的人”的分水岭。
验收标准定死三条:响应时间控制在 3 秒内(首字输出),检索命中率(Top-3)不低于 70%,能抗住 50 QPS 的并发请求。达不到这三条,项目就别往上贴。把压测报告、Bad Case 分析表、监控看板截图整理进 README,比堆砌技术名词管用得多。
面试准备
转型期面试,业务面试官怕你不懂工程,算法面试官嫌你没理论基础。怎么破?主动掌握话语权。
自我介绍别光报框架名,讲清楚你解决过的具体问题。例如:“我在 XX 项目中负责 RAG 链路改造,主要挑战是长文档检索精度低。我通过优化 chunk 策略为按段落+语义双级切分,引入元数据过滤,将 Top-K 准确率从 60% 提升到 82%,同时通过流式输出降低感知延迟。”
技术面常问:怎么处理模型幻觉?答:不要只说“调温度参数”。要从架构层面说:限制检索范围、设置严格输出格式校验(正则或 JSON schema)、引入人工复核兜底机制、建立 Bad Case 回流标注集。提到具体拦截规则和处理代价,面试官就知道你真正跑过生产。
薪资谈判时,突出你的工程壁垒。AI 应用层人才缺口大,但能写出高可用、可观测、易维护系统的 Java 程序员依然稀缺。把原来的微服务经验包装成“高并发 AI 网关”、“流式响应缓冲策略”、“向量库索引优化”,竞争力直接拉满。
总结
从 Java 后端转大模型开发,本质是把确定性工程的经验,适配到概率性推理的场景里。别被术语吓住,先搭起 RAG 骨架,再把工程护城河挖深。技术栈会变,但读日志、抓瓶颈、做压测、管数据的习惯不会过时。选一个垂直场景扎进去,跑出数据,拿到结果,路自然就通了。
资料展示
下面是我整理的AI大模型学习资料和工具包预览,适合收藏后按主题逐步学习。

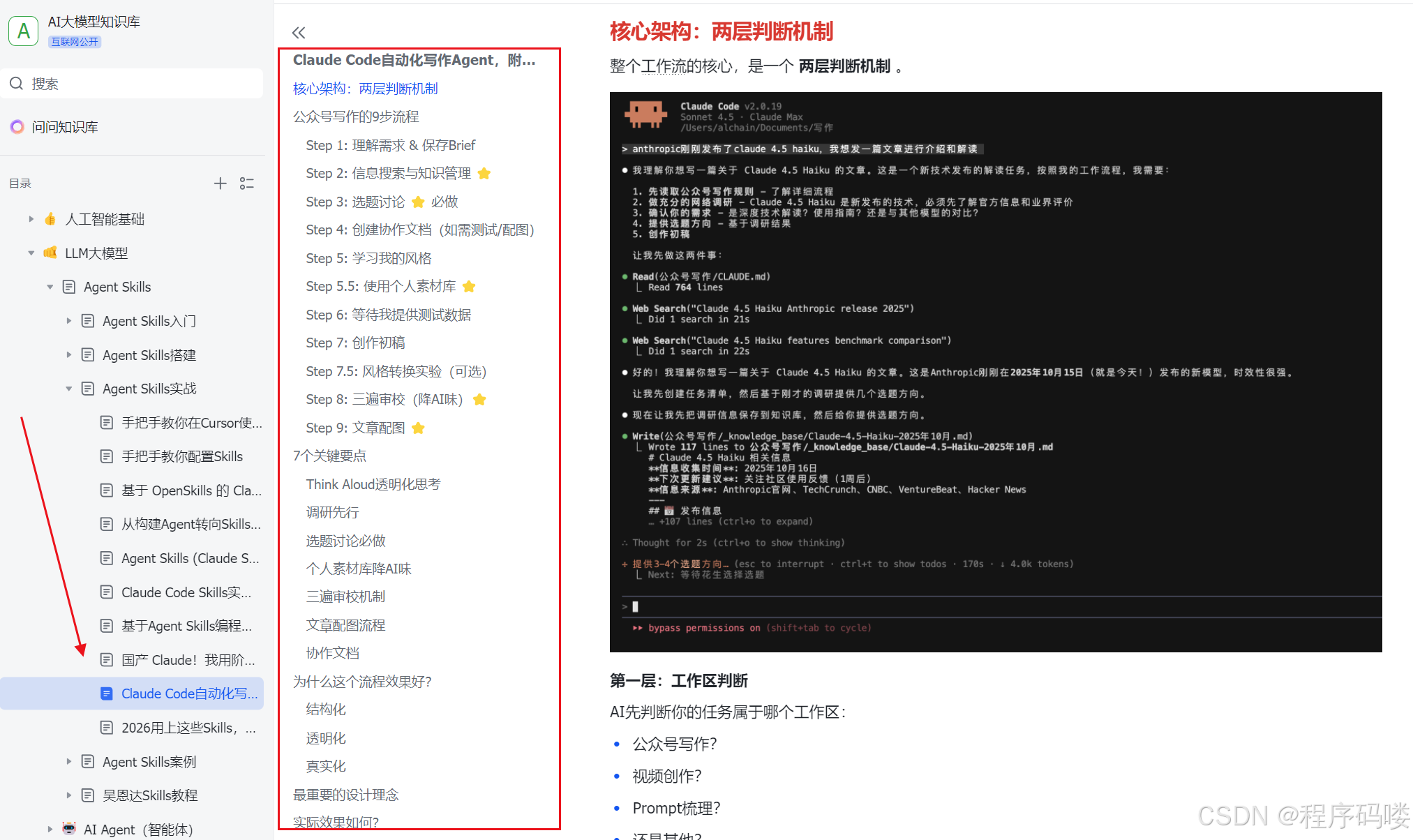
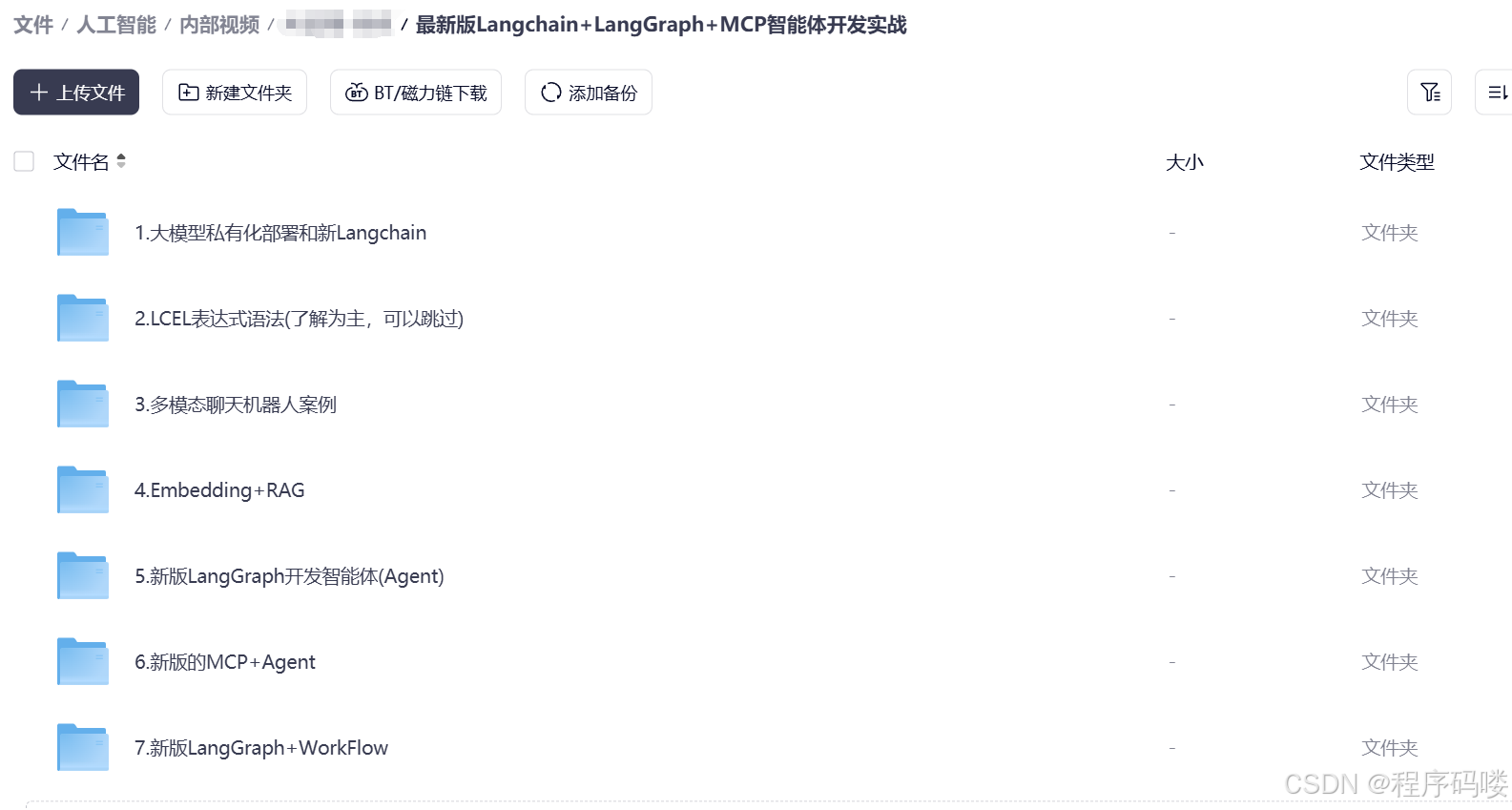
如果你想看完整资料目录,可以在评论区留言「资料」;也欢迎告诉我你更关注AI大模型里的哪类内容。

更多推荐
 5
5 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)