
单卡 NPU 跑通 Qwen2.5-1.5B-Instruct verl GRPO
单卡 NPU 跑通 Qwen2.5-1.5B-Instruct verl GRPO

1. 写在最前面
版权声明:本文为原创,遵循 CC 4.0 BY-SA 协议。转载请注明出处。
随着 DeepSeek 等越来越多国产大模型适配昇腾等国产软硬件环境,很多开发者也开始希望上手体验 NPU 训练与推理。如果你准备在昇腾 NPU 上基于 CANN 云开发环境运行 Qwen2.5-1.5B-Instruct + verl,这篇文档可以作为一条可复现、可验收的实践路径。
本文将围绕一次真实可跑通的实验流程展开,覆盖容器环境配置、CANN/NNAL 依赖安装、代码拉取、训练启动、运行监控、日志绘图、结果验收,以及实际工程中遇到的兼容性问题和修复办法。目标不是只给出零散命令,而是帮助读者从环境搭建到训练闭环,完整体验国产 NPU 生态下大模型强化学习训练的运行过程。
本次测评在单卡 Ascend 910B3 (云环境配置 )上成功完成了 Qwen2.5-1.5B-Instruct + verl GRPO 的强化学习训练验证,数据集采用 MATH-lighteval。按 1 epoch 统计,训练完整覆盖 global_step=1–28,rollout、奖励计算、ref log prob、old log prob 与 actor update 等核心链路均正常完成,体现该组合在昇腾 NPU 与 CANN 云开发环境下具备较好的可运行性和工程落地基础。
验证奖励 val-core/DigitalLearningGmbH/MATH-lighteval/reward/mean@1 从 step 10 的 0.246875 提升到 step 20 的 0.355937,绝对提升 0.109062,相对提升 44.18%。在 data.val_max_samples=32 的快速验证口径下,这一变化说明训练早期已经出现可观察的奖励提升。
稳定性方面,actor/kl_loss 全程位于 0 到 0.000514,actor/grad_norm 位于 0.2095 到 0.4083,actor/pg_clipfrac 全程为 0,response/aborted_ratio 全程为 0。策略更新幅度、梯度规模和 response 生成状态均处于可控区间。
效率方面,perf/throughput 均值为 1163.71 tokens/s,perf/time_per_step 均值为 137.64s,28 step 合计处理 4,486,511 tokens。耗时主要来自生成阶段,timing_s/gen 均值 71.94s,占平均 step 时间约 52.27%。
显存方面,perf/max_memory_allocated_gb 峰值约 70.58GB,perf/max_memory_reserved_gb 峰值约 88.92GB。当前配置能够在单卡 Ascend 910B 上完成 1 epoch 训练,后续增大 rollout.n、batch size 或 max_response_length 时,需要重新检查显存余量。
| 维度 | 关键结论 | 支撑数据 |
|---|---|---|
| 训练链路 | 单卡 NPU 完成 GRPO 训练链路 | global_step=1~28;rollout、reward、ref、old_log_prob、actor update 均完成 |
| 奖励趋势 | 快速验证奖励上升 | 0.246875 → 0.355937,+0.109062 |
| 策略模型健康度 | KL 与梯度稳定 | actor/kl_loss max=0.000514;actor/grad_norm max=0.4083 |
| 生成完整性 | 截断比例低,aborted 为 0 | response_length/clip_ratio mean=3.19%;response/aborted_ratio=0 |
| 训练效率 | 生成阶段是主要耗时项 | timing_s/gen mean=71.94s;perf/throughput mean=1163.71 tokens/s |
| 模型效果验证 | 本轮保留训练过程评估口径 | 未生成 step 28 checkpoint;后续建议补 OpenCompass 全量 accuracy |
2. 测评背景与目标
样例基于 Qwen2.5-1.5B-Instruct、verl 强化学习框架和 MATH-lighteval 数学推理数据集,目标是提升小模型在复杂数学问题上的分步推理能力,使其能够生成逻辑严密且结果可验证的推理过程。样例最低只需要单卡 Atlas A2 环境,面向昇腾 NPU 上的 RL 训练快速上手。
测评参考文档:cann-recipes-train/llm_rl/qwen2_5/verl_npu_demo · CANN/cann-recipes-train - AtomGit | GitCode
本轮测评选择 1 epoch,重点放在单卡可跑通性、训练稳定性、奖励趋势和性能开销,主要关注训练过程指标和小规模验证奖励。
验证单卡 Ascend 910B 是否能完成 verl GRPO 训练链路。
观察 MATH-lighteval 任务在 1 epoch 内的 val-core/…/reward/mean@1 与 critic/score/mean 变化。
检查 actor/entropy、actor/kl_loss、actor/pg_loss、actor/grad_norm、actor/pg_clipfrac 等策略模型健康度指标。
评估 response_length/clip_ratio、response/aborted_ratio、perf/throughput、perf/time_per_step 和显存指标。
沉淀依赖冲突、数据下载、训练前验证、response 截断和 checkpoint 保存频率等工程问题的处理方法。
3. 环境准备、权重准备与数据集准备
3.1 硬件与软件版本
硬件侧使用单卡 Ascend 910B,通过 ASCEND_RT_VISIBLE_DEVICES=0 指定单卡运行。官方样例声明支持 Atlas A2/A3 系列产品;本轮实际测评环境属于单卡 NPU 快速验证场景。
| 组件 | 版本 / 配置 |
|---|---|
| 硬件 | 单卡 Ascend 910B |
| 设备选择 | ASCEND_RT_VISIBLE_DEVICES=0 |
| torch | 2.7.1+cpu |
| torch_npu | 2.7.1.post2.dev20251226 |
| vllm | 0.11.0 |
| vllm-ascend | 0.11.0 |
| transformers | 4.57.1 |
| datasets | 5.0.0 |
| ray | 2.55.1 |
| modelscope | 1.37.1 |
使用的是官方云开发环境(需要在 cann/cann-recipes-train 仓打开 CANNLab 并创建云开发环境):
3.2 环境准备关键命令
按流程要求安装 vllm、vllm-ascend、requirements.txt 依赖并安装 verl。
# 安装 vllm
pip install -v vllm==0.11.0
# 安装 vllm-ascend
pip install -v vllm-ascend==0.11.0
# verl 源码请下载到 qwen2_5/verl_npu_demo/ 目录下
git clone https://github.com/volcengine/verl.git
cd verl
git checkout release/v0.6.1
pip install -e .
完成后当前目录为 verl_npu_demo/verl。
3.3 权重准备与 Tokenizer 配置
模型使用 Qwen2.5-1.5B-Instruct。官方文档优先推荐 ModelScope 命令行下载,Hugging Face 下载作为备用路径。模型权重文件最终存放路径为 verl_npu_demo/verl/model/Qwen2_5_1_5B_Instruct。
# 在 verl_npu_demo/verl 目录下执行
modelscope download --model Qwen/Qwen2.5-1.5B-Instruct --local_dir model/Qwen2_5_1_5B_Instruct/
# Hugging Face 备用路径(等待两三分钟)
hf download Qwen/Qwen2.5-1.5B-Instruct --local-dir model/Qwen2_5_1_5B_Instruct/
Tokenizer 配置文件沿用官方样例中的优化版本,将 tokenizer_config.json 移动到 verl/model/Qwen2_5_1_5B_Instruct/ 目录并覆盖。该步骤能够让训练脚本和模型推理使用样例提供的 Tokenizer 配置。
cd ..
mv -f tokenizer_config.json verl/model/Qwen2_5_1_5B_Instruct/
3.4 数据集准备
数据集使用 DigitalLearningGmbH/MATH-lighteval。预处理脚本 examples/data_preprocess/math_dataset.py 会在线获取数据集并处理成 verl 所需的 train.parquet 与 test.parquet。由于本轮环境无法直连 Hugging Face Hub,设置 HF_ENDPOINT 后完成预处理。
export HF_ENDPOINT=https://hf-mirror.com
cd verl/examples/data_preprocess/
python3 math_dataset.py --local_dir ../../data/math/data
| 数据项 | 数量 / 路径 | 说明 |
|---|---|---|
| 训练集原始样本 | 7500 条 | MATH-lighteval train split |
| 训练时过滤后样本 | 7381 条 | 由训练日志和数据处理结果汇总 |
| 验证集原始样本 | 5000 条 | MATH-lighteval test split |
| 本轮验证样本 | data.val_max_samples=32 | 单卡快速验证,降低 test_freq 验证开销 |
| 训练文件 | train.parquet | verl 训练所需格式 |
| 验证文件 | test.parquet | verl 验证所需格式 |
4. 强化学习训练配置
本轮训练脚本为 run_qwen2_5_1_5b_single.sh,训练目录为 verl_npu_demo/verl。奖励函数使用官方样例优化后的 new_math_reward.py,并通过 custom_reward_function.path 参数挂载。
cd ../../..
bash run_qwen2_5_1_5b_single.sh
# 奖励函数调用路径
custom_reward_function.path=./verl/utils/reward_score/new_math_reward.py
| 参数 | 本轮取值 | 作用 / 口径 |
|---|---|---|
| data.train_batch_size | 256 | 单步训练 batch |
| data.max_prompt_length | 512 | prompt 最大长度;本轮 prompt_length/clip_ratio=0 |
| data.max_response_length | 1024 | response 最大长度;数学推理任务需要保证答案结构完整 |
| data.val_max_samples | 32 | 快速验证样本数 |
| actor_rollout_ref.rollout.n | 1 | 单卡降低 rollout generation 成本 |
| actor_rollout_ref.actor.ppo_mini_batch_size | 256 | 与 train_batch_size 对齐 |
| trainer.test_freq | 10 | 每 10 step 执行一次验证 |
| trainer.val_before_train | False | 跳过训练前全量验证,降低单卡等待成本 |
| trainer.total_epochs | 1 | 本轮统计范围 |
| trainer.save_freq | 28 | 后续重跑时可在 1 epoch 结束保存 checkpoint |
| actor/kl_coef | 0.001 | KL 约束系数,28 step 内保持不变 |
| actor/lr | 0 → 1.0e-6 | TensorBoard 标量显示学习率升至约 1e-6 |
4.1 max_response_length=1024 的选择
前置 smoke / sample eval 曾尝试 max_response_length=256。数学推理回答在该长度下容易截断,样例未形成合法的 <answer>\boxed{...}</answer> 结构,奖励函数给分为 0.0。
正式训练恢复 data.max_response_length=1024 后,response_length/clip_ratio 均值为 0.031948,末值为 0.011719;response/aborted_ratio 全程为 0。该设置更适合 MATH-lighteval 的长推理场景。
4.2 新奖励函数口径
样例说明中,verl 框架中 MATH 任务的原生奖励函数采用字符串等价性判断,在数学含义等价但字符串形式不同的场景可能产生误判,且 0/1 二元评分会让奖励信号稀疏。new_math_reward.py 引入基于数学语义等价性的判断机制,并加入格式规范性和思维链完整性两类分级奖励。
新奖励函数采用“答案正确性优先”设计原则:答案本身正确后,再纳入格式规范性与思维链完整性评分。该设计让优化目标集中在精准求解,同时通过多维度信号改善奖励稀疏问题。
5. 训练过程可视化与指标口径
官方文档将训练过程可视化分为 SwanLab 和 TensorBoard 两类工具。本轮实际使用 TensorBoard 标量数据,路径为 tensorboard_log/verl_grpo_example_math/qwen2_5_1_5b_math_single/。
为提高读者理解效率,本文按官方 README 的训练指标分类来组织分析:策略模型健康度指标、性能与奖励指标、训练稳定性指标、训练效率指标。
| 分类 | 指标 | 解释口径 |
|---|---|---|
| 策略模型健康度指标 | actor/entropy | 模型输出的不确定性或探索性;过低需要警惕模式崩溃 |
| 策略模型健康度指标 | actor/kl_loss | 当前模型与参考模型行为差异的代价;需结合 kl_coef 观察 |
| 策略模型健康度指标 | actor/pg_loss | 策略梯度损失;重点观察数值是否稳定以及是否出现 nan |
| 性能与奖励指标 | val-core/…/reward/mean@1 | 验证集平均奖励;训练直接优化目标之一,需要结合 accuracy 防止奖励黑客 |
| 性能与奖励指标 | critic/score/mean | GRPO 中训练 batch 内 response 的原始 reward 均值;区别于 Advantage |
| 训练稳定性指标 | actor/pg_clipfrac | PPO 剪辑比例;过高提示更新过猛,过低提示更新较保守 |
| 训练稳定性指标 | actor/grad_norm | 梯度范数;突然增大可能提示梯度爆炸风险 |
| 训练稳定性指标 | response_length/mean | 生成 response 平均 token 长度;异常上升或下降都需要排查 |
| 训练稳定性指标 | response_length/clip_ratio | response 触达 max_response_length 的比例;越高越容易影响奖励函数评分 |
| 训练效率指标 | perf/mfu/actor | 模型浮点利用率;RLHF 中受生成开销影响通常不会特别高 |
| 训练效率指标 | perf/throughput | 每秒处理 token 数;直接反映训练速度 |
| 训练效率指标 | timing_s/* | 单 step 内不同阶段耗时,用于定位性能瓶颈 |
6 Epoch 核心结果
1 epoch 共统计 28 个训练 step。TensorBoard 中 training/epoch=0 对应第 1 个 epoch 的零基索引;本文使用 global_step=1~28 作为正式统计范围。
| 指标 | 首步 | 首值 | 末步 | 末值 | 最小值 | 最大值 | 均值 |
|---|---|---|---|---|---|---|---|
| actor/entropy | 1 | 0.4643 | 28 | 0.3524 | 0.3456 | 0.4982 | 0.4196 |
| actor/kl_loss | 1 | 0.000000 | 28 | 0.000514 | 0.000000 | 0.000514 | 0.000111 |
| actor/pg_loss | 1 | -0.0081 | 28 | -0.0093 | -0.0109 | -0.0070 | -0.0085 |
| actor/grad_norm | 1 | 0.2481 | 28 | 0.4083 | 0.2095 | 0.4083 | 0.2857 |
| actor/pg_clipfrac | 1 | 0.0000 | 28 | 0.0000 | 0.0000 | 0.0000 | 0.0000 |
| critic/score/mean | 1 | 0.2523 | 28 | 0.2801 | 0.2198 | 0.3337 | 0.2626 |
| val-core/…/reward/mean@1 | 10 | 0.2469 | 20 | 0.3559 | 0.2469 | 0.3559 | 0.3014 |
| response_length/mean | 1 | 464.50 | 28 | 319.13 | 319.13 | 494.06 | 418.86 |
| response_length/clip_ratio | 1 | 0.0273 | 28 | 0.0117 | 0.0117 | 0.0625 | 0.0319 |
| perf/mfu/actor | 1 | 0.1572 | 28 | 0.1212 | 0.1212 | 0.1629 | 0.1449 |
| perf/throughput | 1 | 1174.87 | 28 | 997.65 | 997.65 | 1295.95 | 1163.71 |
| perf/time_per_step | 1 | 146.28 | 28 | 135.00 | 135.00 | 146.28 | 137.64 |
6.1 验证奖励
| step | val-core/DigitalLearningGmbH/MATH-lighteval/reward/mean@1 | 说明 |
|---|---|---|
| 10 | 0.246875 | 第一次按 trainer.test_freq=10 触发验证 |
| 20 | 0.355937 | 较 step 10 提升 0.109062,相对提升 44.18% |
6.2 资源与效率汇总
| 资源 / 性能项 | 首值 | 末值 | 最小值 | 最大值 | 均值 / 合计 |
|---|---|---|---|---|---|
| perf/throughput | 1174.87 | 997.65 | 997.65 | 1295.95 | 1163.71 tokens/s |
| perf/time_per_step | 146.28s | 135.00s | 135.00s | 146.28s | 137.64s |
| perf/total_num_tokens | 171856 | 134687 | 134687 | 180126 | 均值 160232.54;合计 4,486,511 |
| perf/cpu_memory_used_gb | 33.82 | 34.16 | 33.82 | 34.17 | 34.05GB |
| perf/max_memory_allocated_gb | 64.83 | 70.58 | 64.83 | 70.58 | 70.37GB |
| perf/max_memory_reserved_gb | 81.98 | 88.92 | 81.98 | 88.92 | 88.67GB |
6.3 单 step 耗时拆解
| 阶段指标 | 均值 | 占平均 step 时间 | 解读 |
|---|---|---|---|
| timing_s/gen | 71.94s | 52.27% | 生成阶段,当前最大耗时项 |
| timing_s/update_actor | 34.57s | 25.12% | actor 参数更新阶段 |
| timing_s/ref | 14.41s | 10.47% | 参考模型 log prob 相关计算 |
| timing_s/old_log_prob | 12.49s | 9.08% | 旧策略 log prob 计算 |
| timing_s/reward | 3.88s | 2.82% | 奖励函数计算 |
| timing_s/adv | 0.0248s | 0.0180% | 优势相关计算,耗时占比很低 |
| timing_s/step | 137.64s | 100% | 平均单 step 总耗时 |
7. 指标解读
7.1 性能与奖励指标:快速验证奖励有明显上升
val-core/…/reward/mean@1 从 0.246875 增至 0.355937。该指标是验证集上奖励函数给生成答案的平均打分,属于训练追求的直接目标之一。由于 data.val_max_samples=32,结果更适合判断短程趋势,后续仍建议通过 OpenCompass accuracy 检验泛化能力。
critic/score/mean 首值为 0.2523,末值为 0.2801,最大值为 0.3337,均值为 0.2626。按照 README 的口径,在 GRPO 中没有独立 Critic 模型,此处 score 指 new_math_reward.py 对训练 batch 内 response 打出的原始 reward 均值。Advantage 是后续基于分组相对比较再归一化得到的量,对应 critic/advantages/* 相关 key。
7.2 策略模型健康度指标:KL 很低,entropy 逐步收敛
actor/entropy 从 0.4643 降至 0.3524,均值 0.4196。该变化说明模型输出分布在训练早期逐步收敛,同时最小值仍为 0.3456,没有贴近 0 的模式崩溃信号。
actor/kl_loss 最大值为 0.000514,actor/kl_coef 稳定为 0.001。该组合说明当前策略与参考模型之间的行为差异很小,训练过程没有出现过大的策略漂移。
actor/pg_loss 在 -0.01090 到 -0.00701 之间波动,未出现 nan。不同实现对策略梯度损失的符号约定可能不同,本文重点关注数值稳定性和异常值。
7.3 训练稳定性指标:梯度稳定,PPO 剪辑未被频繁触发
actor/grad_norm 位于 0.2095 到 0.4083,均值 0.2857,属于较小且稳定的梯度范数区间。actor/pg_clipfrac 和 actor/pg_clipfrac_lower 全程为 0,说明本轮策略更新幅度没有频繁触发 PPO 剪辑机制。
prompt_length/clip_ratio 全程为 0,prompt_length/max 最大值 511,低于 data.max_prompt_length=512;response/aborted_ratio 全程为 0。结合 response_length/clip_ratio 均值 3.19%,本轮输入输出长度控制较稳。
7.4 训练效率指标:生成阶段决定主要耗时
perf/mfu/actor 均值 0.1449,最大值 0.1629。RLHF / RLVR 类训练包含大量 rollout generation,MFU 通常会受到序列生成、ref 计算和同步调度影响。
perf/throughput 均值 1163.71 tokens/s,最大值 1295.95 tokens/s;perf/time_per_step 均值 137.64s。timing_s/gen 均值占平均 step 时间 52.27%,后续性能优化应优先关注 rollout generation 路径,包括 vLLM-Ascend 参数、max_response_length、rollout.n、batch size 和序列长度分布。
8. TensorBoard 曲线解读
以下图表来自本轮 TensorBoard 标量导出。图中 step 范围均限制在 global_step=1~28,验证奖励只在 test_freq=10 的触发点出现。
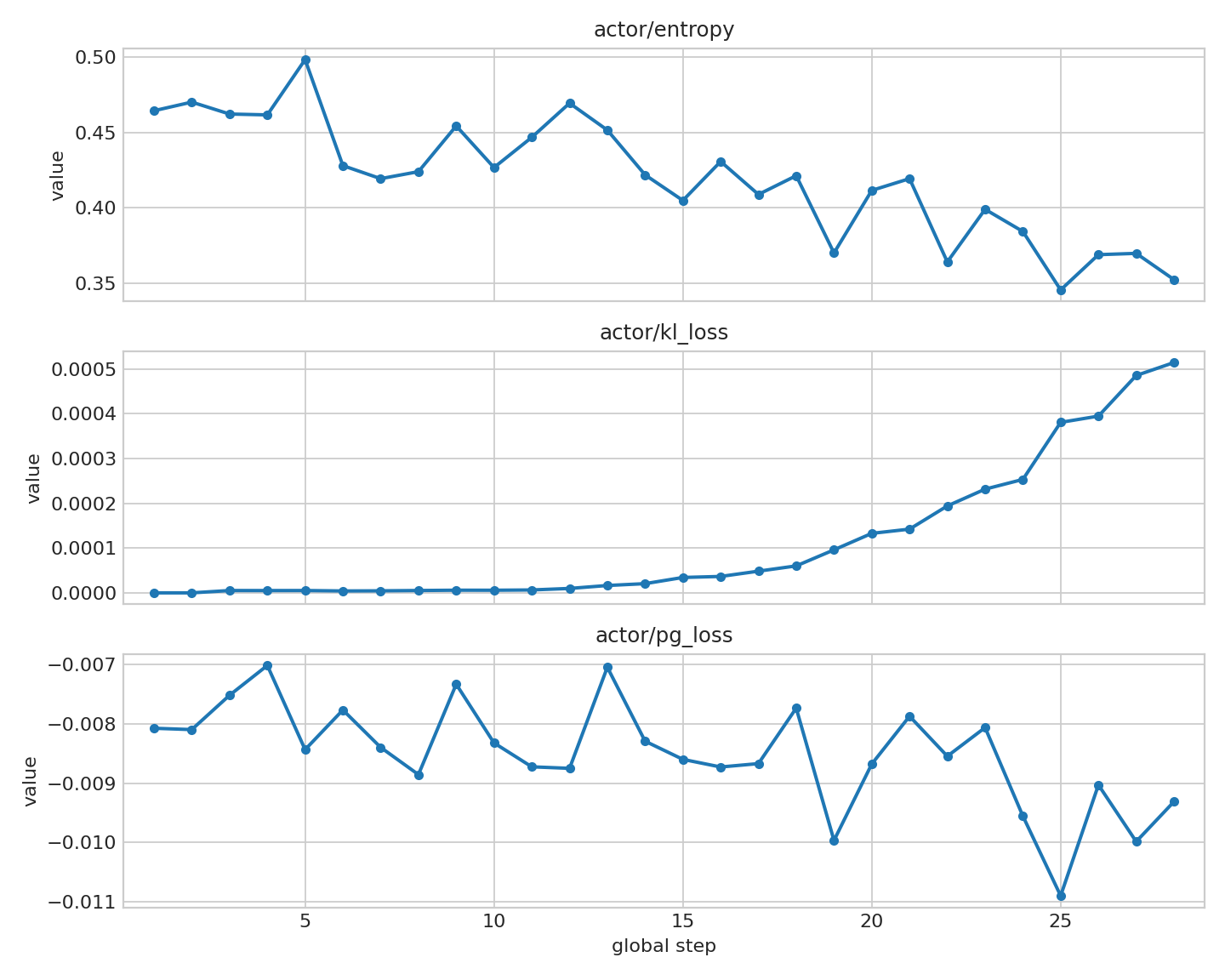
图 1:策略模型健康度指标(actor/entropy、actor/kl_loss、actor/pg_loss)
图 1 显示 entropy 在 1 epoch 内整体下降,kl_loss 维持低位,pg_loss 没有出现 nan 或剧烈跳变。该组合符合短程稳定训练的预期。
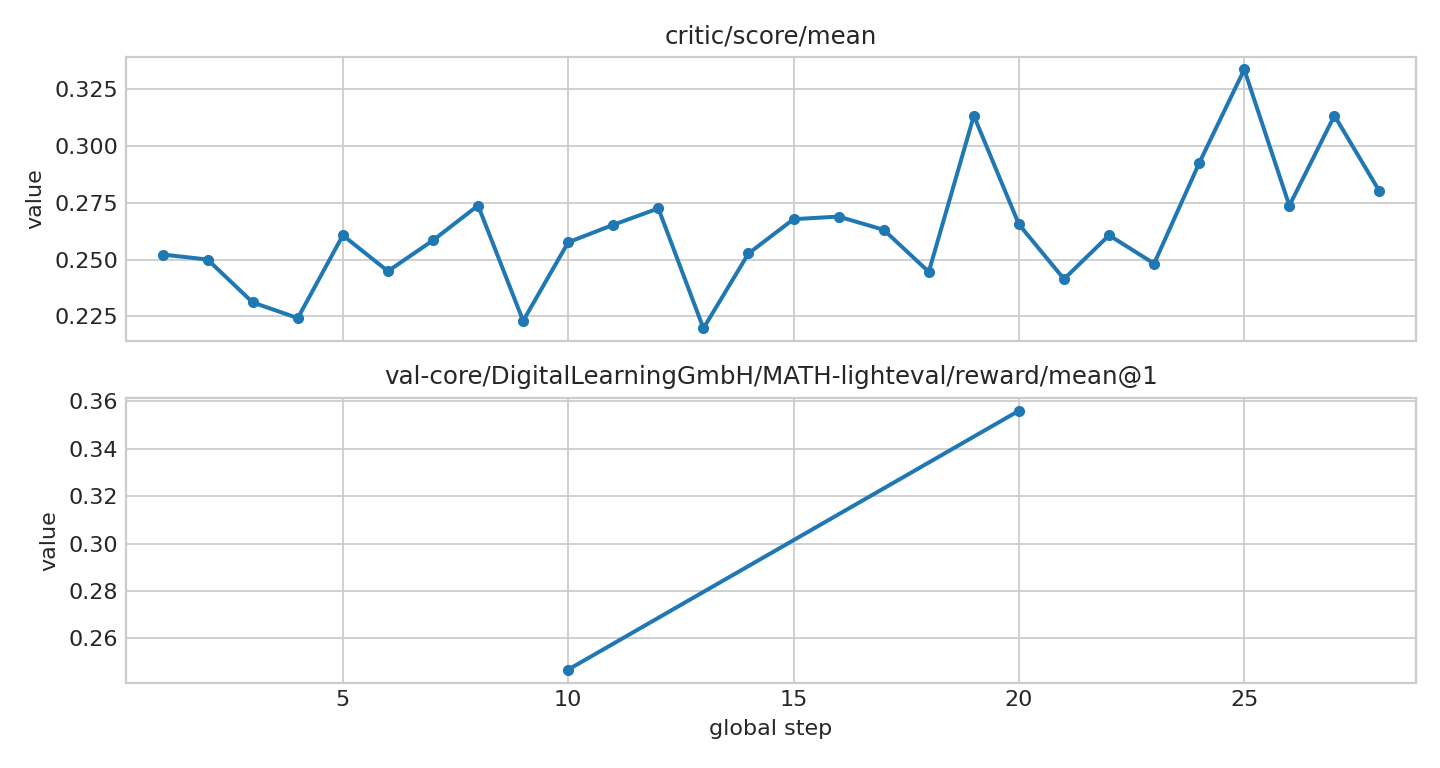
图 2:性能与奖励指标(验证奖励与 critic/score/mean)
图 2 显示验证奖励在 step 20 高于 step 10,critic/score/mean 在训练 step 内存在 batch 难度引起的波动。两者同向改善时,可以作为奖励函数链路有效的早期信号。
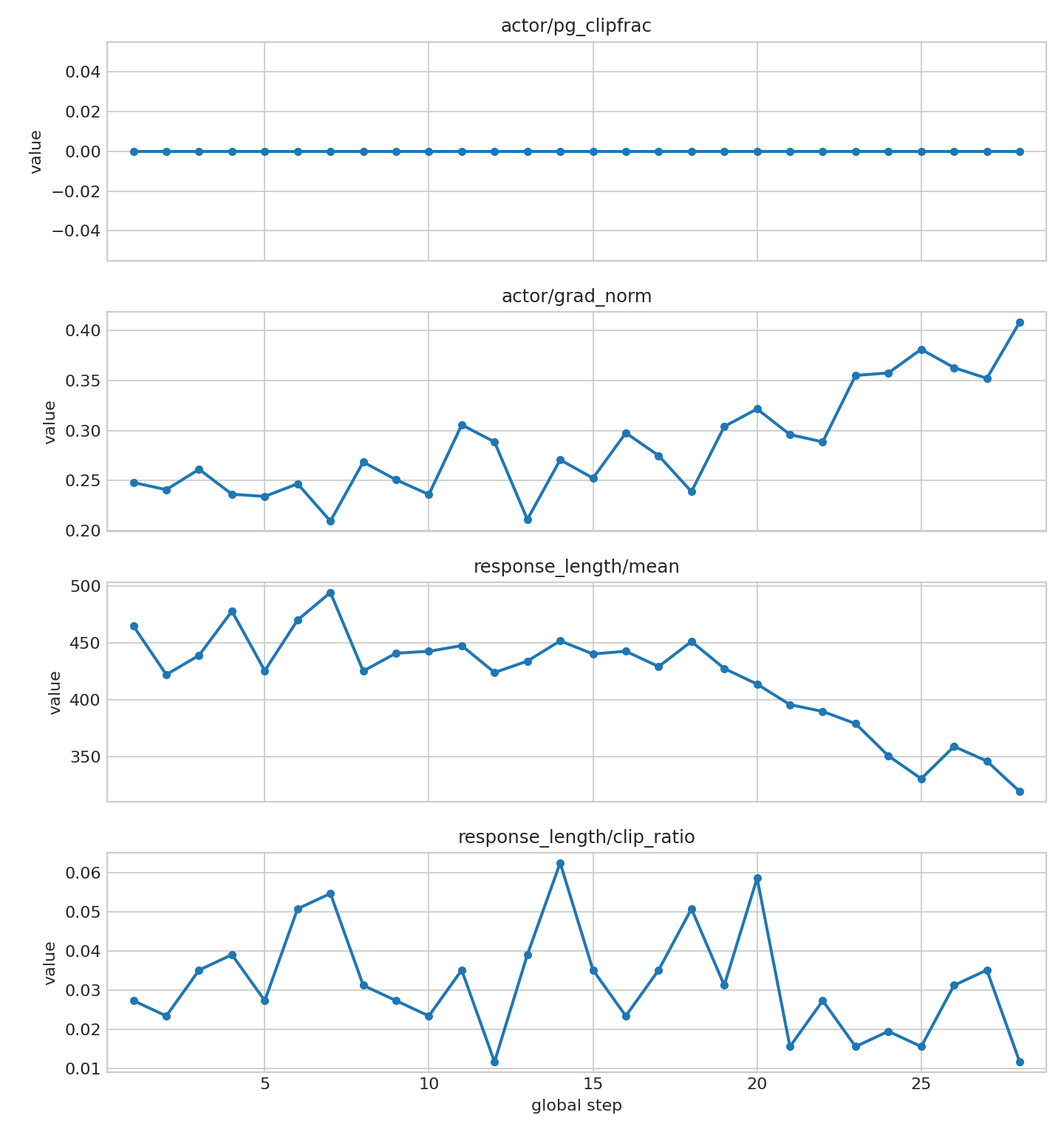
图 3:训练稳定性指标(pg_clipfrac、grad_norm、response length)
图 3 显示 grad_norm 区间稳定,pg_clipfrac 持续为 0,response_length/mean 在 319 到 494 tokens 之间波动。response_length/clip_ratio 最高为 6.25%,均值约 3.19%。
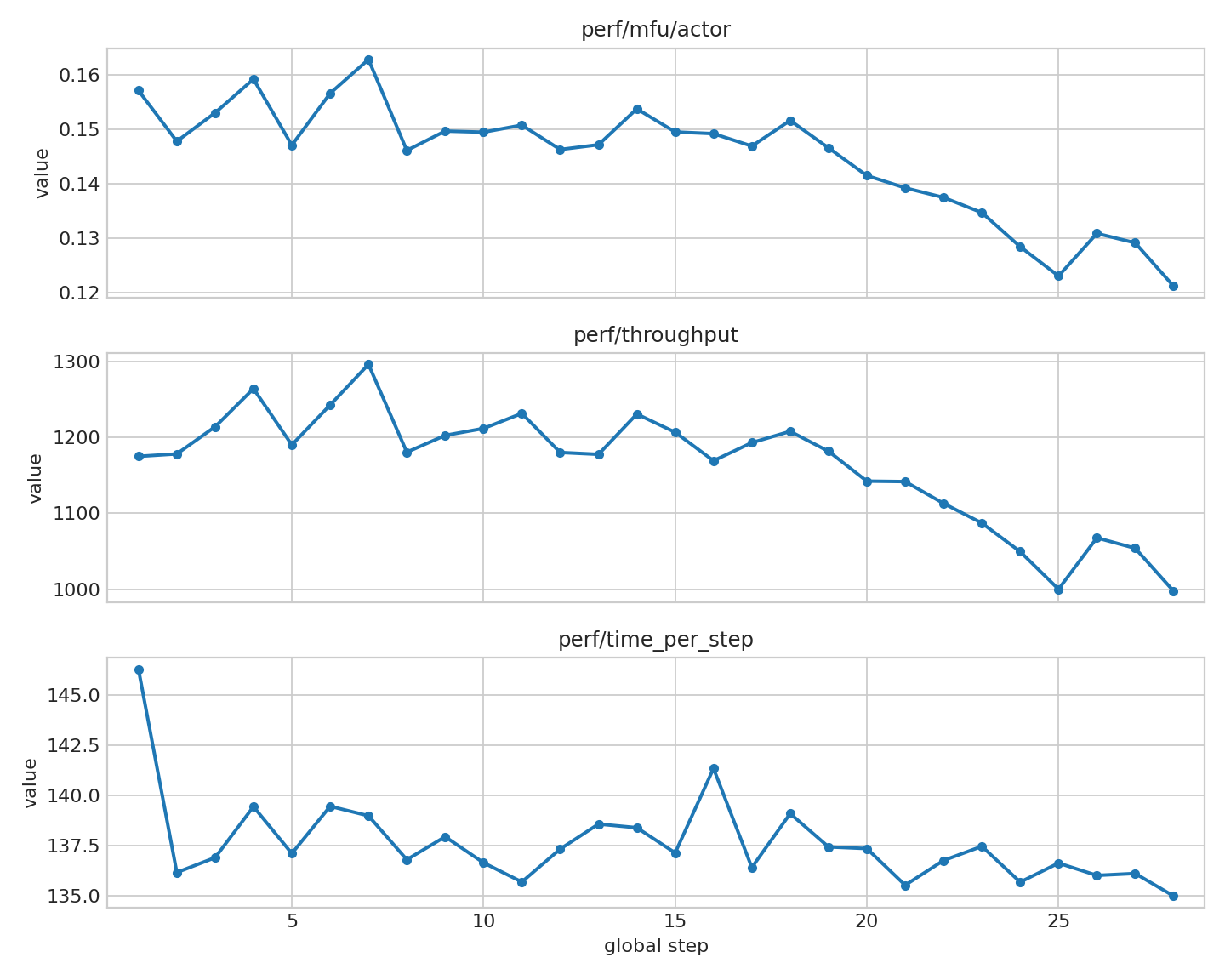
图 4:训练效率指标(MFU、throughput、time_per_step)
图 4 显示吞吐和单步耗时存在轻微波动,整体处于可解释范围。step 末段 response_length/mean 降至 319.13,throughput 同时降至 997.65 tokens/s,说明性能仍受多阶段调度和生成分布共同影响。
9. 与 OpenCompass 参考结果的关系
这里给出本次测评的模型效果验证流程:训练完成后合并模型权重,再使用 OpenCompass 开源大模型测试框架对基模和强化学习训练模型使用同一测试数据进行对比测试。官方示例强调该步骤可以降低奖励黑客(Reward Hacking)带来的误判风险。
| 模型 | step | dataset | metric | mode | accuracy |
|---|---|---|---|---|---|
| qwen2.5-1.5b-instruct | 0 | MATH-lighteval | accuracy | gen | 43.48 |
| qwen2.5-1.5b-instruct-rl-140 | 140 | MATH-lighteval | accuracy | gen | 53.26 |
参考结果从 43.48 提升到 53.26,绝对提升 9.78 个百分点,相对提升约 22.49%。该结果对应 5 epoch / 140 step 的训练与合并后的 checkpoint。
本轮测评的训练范围为 1 epoch / 28 step,且最初脚本保存频率为 save_freq=70,停止时没有自然生成 step 28 checkpoint。因此本轮保留训练过程指标和小规模验证奖励作为结论依据。后续重跑时已建议将 trainer.save_freq=28、trainer.total_epochs=1 写入脚本,得到 global_step_28/actor/huggingface 后再执行 OpenCompass。
python3 -m verl.model_merger merge \
--backend fsdp \
--local_dir checkpoints/verl_grpo_example_math/qwen2_5_1_5b_math/global_step_28/actor \
--target_dir checkpoints/verl_grpo_example_math/qwen2_5_1_5b_math/global_step_28/actor/huggingface
# OpenCompass 模型配置核心字段
abbr='qwen2.5-1.5b-instruct-rl-28'
path='<...>/global_step_28/actor/huggingface'
max_out_len=1024
batch_size=32
10. 踩坑与处理记录
| 问题 | 日志 / 现象 | 处理方法 | 复盘建议 |
|---|---|---|---|
| vLLM 与 vLLM-Ascend 依赖冲突 | vllm 0.11.0 depends on torch== 2.8.0;vllm-ascend 0.11.0 depends on torch==2.7.1 | 保留 Ascend 可用 torch==2.7.1 与 torch_npu ==2.7.1,对 vllm 和 vllm-ascend 使用 --no-deps 安装,再补齐运行依赖 | NPU 环境优先保证 torch_npu 与 CANN 组合可用 |
| Hugging Face 数据集无法直连 | ConnectionError: Couldn’t reach DigitalLearningGmbH/MATH-lighteval | 设置 HF_ENDPOINT=https://hf-mirror.com 后重新执行 math_dataset.py | 生产环境建议准备本地 parquet 与 --local_dataset_path 路径 |
| 训练前全量验证耗时过长 | ray.exceptions.ActorUnavailableError / UnexpectedSystemExit / SIGTERM | 设置 trainer.val_before_train=False,并使用 data.val_max_samples=32 | 单卡调试阶段先跑快速验证,稳定后再全量验证 |
| vLLM CUDA 扩展导入警告 | Failed to import from vllm._C with ImportError libcudart.so.12 | 当前运行走 vLLM-Ascend 后端,后续 Ascend backend 注册并完成 rollout,警告未阻断训练 | 记录后端注册日志,确认实际 rollout backend |
| max_response_length=256 截断 | sample eval 中首条样例未形成 <answer>\boxed{...}</answer>,reward=0.0 |
正式训练恢复 data.max_response_length=1024 | 数学推理任务优先保证答案结构完整 |
| 1 epoch 停止后缺少 checkpoint | 初始 save_freq=70;1 epoch 在 step 28 结束 | 后续脚本调整 trainer.save_freq=28、trainer.total_epochs=1 | 短跑测评需让 save_freq 对齐目标 epoch 结束点 |
附录 A. 核心配置清单
| 类别 | 项目 | 取值 / 路径 |
|---|---|---|
| 源码目录 | 样例目录 | llm_rl/qwen2_5/verl_npu_demo |
| 训练目录 | verl 目录 | llm_rl/qwen2_5/verl_npu_demo/verl |
| 模型权重 | Qwen2.5-1.5B-Instruct | model/Qwen2_5_1_5B_Instruct/ |
| Tokenizer | tokenizer_config.json | verl/model/Qwen2_5_1_5B_Instruct/tokenizer_config.json |
| 数据预处理 | math_dataset.py | examples/data_preprocess/math_dataset.py |
| 训练数据 | train.parquet | data/math/data/train.parquet |
| 验证数据 | test.parquet | data/math/data/test.parquet |
| 训练脚本 | 单卡脚本 | run_qwen2_5_1_5b_single.sh |
| 奖励函数 | new_math_reward.py | verl/utils/reward_score/new_math_reward.py |
| 训练日志 | run_log | run_log/qwen2_5_1_5b_math_single*.log |
| TensorBoard | 日志目录 | tensorboard_log/verl_grpo_example_math/qwen2_5_1_5b_math_single/ |
| 导出数据 | 逐 step 指标 | analysis/metrics_step1_28.csv |
| 导出数据 | 汇总指标 | analysis/metrics_summary_step1_28.csv |
附录 B. 逐 step 核心指标表
该表保留 28 个 step 的核心指标,便于复查曲线波动。val_reward 仅在 test_freq=10 触发验证的 step 有值。
| step | val_reward | score_mean | entropy | kl_loss | grad_norm | resp_mean | clip_ratio | throughput | time/step |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 0.2523 | 0.4643 | 0.000000 | 0.2481 | 464.50 | 2.73% | 1174.87 | 146.28s | |
| 2 | 0.2500 | 0.4700 | 0.000000 | 0.2409 | 421.85 | 2.34% | 1178.08 | 136.17s | |
| 3 | 0.2312 | 0.4621 | 0.000005 | 0.2613 | 438.88 | 3.52% | 1213.84 | 136.91s | |
| 4 | 0.2243 | 0.4616 | 0.000005 | 0.2364 | 477.70 | 3.91% | 1263.98 | 139.45s | |
| 5 | 0.2607 | 0.4982 | 0.000005 | 0.2342 | 425.28 | 2.73% | 1189.99 | 137.12s | |
| 6 | 0.2449 | 0.4279 | 0.000004 | 0.2468 | 469.86 | 5.08% | 1242.51 | 139.46s | |
| 7 | 0.2585 | 0.4193 | 0.000005 | 0.2095 | 494.06 | 5.47% | 1295.95 | 138.99s | |
| 8 | 0.2738 | 0.4239 | 0.000005 | 0.2686 | 425.03 | 3.12% | 1180.39 | 136.81s | |
| 9 | 0.2231 | 0.4543 | 0.000006 | 0.2508 | 440.71 | 2.73% | 1202.46 | 137.95s | |
| 10 | 0.246875 | 0.2576 | 0.4267 | 0.000006 | 0.2361 | 442.36 | 2.34% | 1211.57 | 136.66s |
| 11 | 0.2653 | 0.4467 | 0.000006 | 0.3057 | 447.40 | 3.52% | 1231.38 | 135.70s | |
| 12 | 0.2725 | 0.4693 | 0.000010 | 0.2886 | 423.72 | 1.17% | 1180.01 | 137.34s | |
| 13 | 0.2198 | 0.4515 | 0.000016 | 0.2112 | 433.71 | 3.91% | 1177.53 | 138.58s | |
| 14 | 0.2527 | 0.4218 | 0.000021 | 0.2708 | 451.56 | 6.25% | 1230.56 | 138.40s | |
| 15 | 0.2678 | 0.4049 | 0.000034 | 0.2525 | 440.01 | 3.52% | 1206.58 | 137.15s | |
| 16 | 0.2689 | 0.4307 | 0.000037 | 0.2977 | 442.43 | 2.34% | 1169.12 | 141.35s | |
| 17 | 0.2631 | 0.4088 | 0.000048 | 0.2750 | 428.91 | 3.52% | 1192.91 | 136.42s | |
| 18 | 0.2446 | 0.4213 | 0.000060 | 0.2390 | 450.98 | 5.08% | 1207.72 | 139.10s | |
| 19 | 0.3133 | 0.3701 | 0.000096 | 0.3041 | 427.27 | 3.12% | 1181.55 | 137.44s | |
| 20 | 0.355937 | 0.2655 | 0.4115 | 0.000133 | 0.3216 | 413.52 | 5.86% | 1142.28 | 137.36s |
| 21 | 0.2415 | 0.4193 | 0.000142 | 0.2960 | 395.48 | 1.56% | 1141.68 | 135.54s | |
| 22 | 0.2607 | 0.3641 | 0.000194 | 0.2886 | 389.49 | 2.73% | 1113.04 | 136.77s | |
| 23 | 0.2483 | 0.3990 | 0.000231 | 0.3551 | 378.79 | 1.56% | 1087.10 | 137.47s | |
| 24 | 0.2925 | 0.3843 | 0.000253 | 0.3576 | 350.48 | 1.95% | 1049.49 | 135.69s | |
| 25 | 0.3337 | 0.3456 | 0.000381 | 0.3812 | 330.38 | 1.56% | 1000.10 | 136.64s | |
| 26 | 0.2738 | 0.3689 | 0.000395 | 0.3628 | 358.73 | 3.12% | 1067.66 | 136.03s | |
| 27 | 0.3134 | 0.3698 | 0.000485 | 0.3522 | 345.88 | 3.52% | 1053.97 | 136.12s | |
| 28 | 0.2801 | 0.3524 | 0.000514 | 0.4083 | 319.13 | 1.17% | 997.65 | 135.00s |
附录 C. 输出文件清单
| 文件 | 用途 |
|---|---|
| analysis/qwen2_5_verl_npu_one_epoch_report.md | 原始 1 epoch 测评报告 |
| analysis/metrics_step1_28.csv | 逐 step TensorBoard 标量导出 |
| analysis/metrics_summary_step1_28.csv | 核心指标首值、末值、最小值、最大值、均值 |
| analysis/policy_health.png | 策略模型健康度曲线 |
| analysis/reward_metrics.png | 性能与奖励曲线 |
| analysis/stability_metrics.png | 训练稳定性曲线 |
| analysis/efficiency_metrics.png | 训练效率曲线 |
| analysis/reference_md/README_single.md | 一站式平台单卡快速启动材料 |
| analysis/reference_md/README_demo.md | Qwen2.5 verl 强化学习实践样例材料 |
| analysis/reference_md/README_verl.md | verl 官方 README 材料 |
hello,这里是 晓雨的笔记本 。如果你喜欢我的文章,欢迎三连给我鼓励和支持:👍点赞 📁 关注 💬评论,我会给大家带来更多有用有趣的文章。
原文链接 👉 ,⚡️更新更及时。
欢迎大家点开下面名片,添加好友交流。
更多推荐


 161
161 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)