
GLM-5.2赋能Python代码调试:PyCharm+ProxyAI自定义模型接入AIGC Bar API全流程实战指南
声明:本文作者认为,GLM-5.2在Python代码调试场景中的核心价值,源于其744B总参数/40B激活的MoE架构与1M可用上下文窗口——前者提供了强大的代码理解与生成能力,后者使模型能够一次性"消化"整个项目的代码库进行跨文件调试。通过ProxyAI插件在PyCharm中接入 AIGC bar API聚合平台,开发者可以在IDE内直接调用GLM-5.2进行实时代码审查、Bug定位和修复建议,将调试效率提升数倍。但需清醒认识到:API调用主要面向开发者,普通用户使用对话服务直接访问各模型官网即可。
2026年,AI辅助编程已从"代码补全"进化到"智能调试"阶段。智谱AI于2026年6月发布的GLM-5.2,以744B总参数/40B激活的MoE架构和1M可用上下文窗口,在SWE-bench Verified上取得81.0%的开源SOTA成绩,成为Python代码调试的强大助手。本文将系统解析如何通过PyCharm的ProxyAI插件接入 AIGC bar(https://api.aigc.bar/register?aff=UP4F) API聚合平台,调用GLM-5.2进行Python代码调试,涵盖从环境配置到高级调试技巧的全流程实战。
1 引言:AI辅助代码调试的范式转换
理解GLM-5.2在Python代码调试中的价值,需要先把握AI辅助编程的演进脉络和代码调试的核心挑战。
1.1 从代码补全到智能调试
AI辅助编程经历了三个发展阶段。第一阶段是代码补全(2021-2023),以GitHub Copilot为代表,主要功能是根据上下文预测下一行代码,提升编码速度。第二阶段是代码生成与解释(2023-2025),以GPT-4、Claude为代表,能够根据自然语言描述生成完整函数,并解释现有代码逻辑。第三阶段是智能调试与Agent(2025-2026),以GLM-5.2、Claude Opus等长上下文模型为代表,能够理解整个项目代码库,自主定位Bug、分析根因、生成修复方案并验证修复效果。
METR(Model Evaluation & Threat Research)2025年的一项随机对照试验(RCT)研究显示,使用AI工具的有经验开源开发者在熟悉项目上的速度提升了约19%。这一数据表明,AI辅助编程已从"新手工具"进化为"专家加速器"。在调试场景中,AI的价值更为显著——调试通常占开发时间的50%以上,而AI能够快速分析错误堆栈、定位问题代码、提供修复建议,将调试时间缩短60-80%。
1.2 Python代码调试的核心挑战
Python作为动态类型语言,在调试方面面临独特挑战。第一是类型相关错误——Python的动态类型特性使得类型错误往往在运行时才暴露,而非编译时。第二是异步并发问题——asyncio和多线程程序的调试比同步程序复杂得多,错误可能难以复现。第三是依赖冲突——Python生态的包管理(pip、conda、poetry)容易产生版本冲突,导致"在我机器上能跑"的问题。第四是大型项目导航——在数十万行代码的项目中定位Bug,需要理解跨文件的调用关系和数据流。
传统调试工具(如pdb、ipdb、PyCharm调试器)主要解决"执行控制"和"变量查看"问题,但对于"理解代码意图"和"推理错误根因"无能为力。GLM-5.2等大模型的引入,恰好填补了这一空白——模型能够理解代码语义、推理执行流程、分析错误模式,提供传统工具无法提供的"智能诊断"能力。
| 调试维度 | 传统工具(pdb/IDE) | AI辅助(GLM-5.2) | 协同效果 |
|---|---|---|---|
| 执行控制 | 断点/单步/条件断点 | 推理执行路径 | 互补 |
| 变量查看 | 实时变量监控 | 推测变量状态 | 互补 |
| 错误定位 | 堆栈追踪 | 语义级根因分析 | AI增强 |
| 修复建议 | 无 | 生成修复代码 | AI独有 |
| 代码理解 | 无 | 解释代码意图 | AI独有 |
| 跨文件追踪 | 手动跳转 | 全项目上下文理解 | AI增强 |
2 GLM-5.2技术架构与调试能力基础
理解GLM-5.2在代码调试中的表现,需要深入其技术架构和核心能力。
2.1 MoE稀疏架构与代码理解能力
GLM-5.2采用了Mixture of Experts(MoE)稀疏混合专家架构,总参数量744B,但每次推理仅激活约40B参数。这一架构的核心思想是将模型容量与计算成本解耦——通过稀疏激活,模型可以拥有极大的参数量(提供丰富的知识表示),同时保持可控的推理成本。
MoE的路由机制可以形式化表示为:
MoE ( x ) = ∑ i = 1 N g i ( x ) ⋅ E i ( x ) , g ( x ) = TopK ( softmax ( W g ⋅ x ) ) \text{MoE}(x) = \sum_{i=1}^{N} g_i(x) \cdot E_i(x), \quad g(x) = \text{TopK}(\text{softmax}(W_g \cdot x)) MoE(x)=i=1∑Ngi(x)⋅Ei(x),g(x)=TopK(softmax(Wg⋅x))
其中 E i E_i Ei 为第 i i i 个专家网络, g i g_i gi 为门控函数分配给第 i i i 个专家的权重, W g W_g Wg 为门控权重矩阵,TopK操作只保留最大的 K K K 个权重。对于GLM-5.2, N N N 为专家总数, K K K 为每次激活的专家数,激活比约为 40 / 744 ≈ 5.4 % 40/744 \approx 5.4\% 40/744≈5.4%。
在代码调试场景中,MoE架构的优势体现在"专业知识分配"——不同的专家可能专门处理不同类型的代码模式(如异步编程、数据处理、网络请求等),门控函数根据输入代码的特征,自动路由到最相关的专家。这种"专业化"使模型在特定代码模式上的理解能力接近甚至超过更大的稠密模型。
2.2 1M上下文窗口与全项目调试
GLM-5.2最突出的特性是其1M token的可用上下文窗口。这一特性对代码调试具有革命性意义——它使模型能够一次性"看到"整个项目的代码,进行跨文件的Bug追踪和根因分析。
传统AI调试工具受限于上下文窗口(通常为8K-32K token),只能处理单个文件或函数,难以理解跨文件的调用关系。GLM-5.2的1M上下文窗口可以容纳约75万行Python代码(按每行约1.3 token估算),足以覆盖大多数中型项目的全部源码。这意味着模型可以理解"函数A调用了函数B,函数B修改了全局变量C,而Bug出在依赖变量C的函数D中"这样的跨文件因果链。
GLM-5.2实现1M上下文窗口的关键技术是动态稀疏注意力(Dynamic Sparse Attention, DSA)和IndexShare机制。DSA通过动态分配注意力资源,在保持长上下文理解能力的同时控制计算成本。Sebastian Raschka在其技术博客中指出,GLM-5.2在GLM-5的稀疏MoE骨干基础上增加了IndexShare机制,使1M token的上下文处理更加高效。
2.3 SWE-bench基准表现
SWE-bench是评估模型解决真实软件工程问题能力的权威基准。根据Hugging Face的GLM-5.2博客,GLM-5.2在标准编码基准上是开源模型中最强的,在SWE-bench Verified上取得81.0%的成绩,相比GLM-5.1的63.5%有大幅提升。在更困难的SWE-bench Pro上,GLM-5.2取得62.1%,仅比Claude Opus 4.8低1%,同时比GPT-5.5高1%。
这些基准成绩直接反映了GLM-5.2在代码调试场景中的能力——SWE-bench的任务是给定一个GitHub issue和对应代码库,模型需要定位问题代码并生成修复补丁,这与真实代码调试的工作流高度一致。81.0%的SWE-bench Verified成绩意味着GLM-5.2能够正确解决约4/5的真实软件工程问题,这一能力使其成为Python代码调试的强大助手。
| 基准 | GLM-5.2 | GLM-5.1 | Claude Opus 4.8 | GPT-5.5 |
|---|---|---|---|---|
| SWE-bench Verified | 81.0% | 63.5% | ~82% | ~80% |
| SWE-bench Pro | 62.1% | ~58% | 63.1% | 61.1% |
| AIME 2026 | 95.3% | 95.3% | 99.2% | 94.6% |
| 上下文窗口 | 1M | 1M | 200K | 128K |
3 AIGC Bar API聚合平台与模型调用
本节详细介绍如何通过 AIGC bar API聚合平台调用GLM-5.2等模型。
3.1 平台概览与注册
AIGC bar 是一个API聚合平台,提供OpenAI兼容的统一接口,支持调用GLM-5.2、Kimi-K2.6、Qwen3.5、Gemma-4等多种开源和商业模型。平台的核心价值在于"一次接入、多模型可用"——开发者只需注册一个账号、获取一个API密钥,即可调用平台支持的所有模型,无需分别注册多个模型供应商。
平台的模型按分组管理。OpenSource-MultiModal分组包含GLM-5.2、Kimi-K2.6、Qwen3.5等开源多模态模型,API调用需要付费,按token计费。此外,平台还提供free分组,包含DeepSeek-V4-Flash等免费模型,适合开发测试使用。
注册流程非常简单:访问AIGC bar 注册链接,填写邮箱和密码完成注册,登录后在控制台获取API密钥即可开始使用。
3.2 API调用基础
AIGC bar 平台完全兼容OpenAI API格式,开发者可以使用标准的OpenAI Python SDK进行调用。以下是基础调用示例:
from openai import OpenAI
# 初始化客户端
client = OpenAI(
api_key="你的API密钥", # 从 AIGC bar(https://api.aigc.bar/register?aff=UP4F) 获取
base_url="https://api.aigc.bar/v1"
)
# 调用GLM-5.2进行代码调试
response = client.chat.completions.create(
model="glm-5.2",
messages=[
{
"role": "system",
"content": "你是一个Python代码调试专家。请分析用户提供的代码和错误信息,定位Bug并提供修复方案。"
},
{
"role": "user",
"content": """
以下Python代码报错,请帮我调试:
async def fetch_data(urls):
results = []
for url in urls:
data = await requests.get(url)
results.append(data.json())
return results
错误信息:
TypeError: object coroutine can’t be used in ‘await’ expression
"""
}
],
extra_headers={"X-Group": "OpenSource-MultiModal"}, # 指定分组
temperature=0.2, # 调试场景使用低温度确保确定性
max_tokens=2000
)
print(response.choices[0].message.content)
GLM-5.2会正确识别问题:requests.get()不是异步函数,不能直接await。需要使用aiohttp或httpx等异步HTTP库,或使用asyncio.to_thread()包装同步调用。
3.3 流式输出与多轮对话
在交互式调试场景中,流式输出和多轮对话能显著提升体验。流式输出让模型"边生成边返回",开发者可以更快看到调试建议的开始部分;多轮对话允许开发者根据模型的初步分析,追问细节或提供更多上下文。
# 流式输出示例
stream = client.chat.completions.create(
model="glm-5.2",
messages=[
{"role": "system", "content": "你是Python调试专家"},
{"role": "user", "content": "分析这段代码的性能瓶颈: ..."}
],
extra_headers={"X-Group": "OpenSource-MultiModal"},
stream=True # 启用流式输出
)
for chunk in stream:
if chunk.choices[0].delta.content is not None:
print(chunk.choices[0].delta.content, end="")
3.4 其他可用模型
除了GLM-5.2, AIGC bar 平台还支持多种模型,各有特色:
| 模型 | 总参数/激活 | 上下文窗口 | 特色 | 适用场景 |
|---|---|---|---|---|
| GLM-5.2 | 744B/40B | 1M | 长程编码SOTA | 全项目调试、复杂Bug |
| Kimi-K2.6 | ~未公开 | 256K | 原生多模态 | UI自动化调试 |
| Qwen3.5-122B | 122B/10B | 128K | 高效推理 | 快速代码审查 |
| Gemma-4-26B | 25.2B/4B | 128K | 轻量高效 | 实时补全 |
| DeepSeek-V4-Flash | 284B/13B | 128K | free分组免费 | 开发测试 |
4 PyCharm中ProxyAI插件配置全流程
本节详细介绍如何在PyCharm中安装和配置ProxyAI插件,接入 AIGC bar 平台调用GLM-5.2。
4.1 ProxyAI插件简介
ProxyAI(前身为CodeGPT)是JetBrains IDE生态中最流行的开源AI编程助手插件之一。根据其GitHub仓库和JetBrains插件市场信息,ProxyAI支持连接任何模型在任何环境中运行,包括OpenAI兼容的第三方API。其核心特性包括:自定义模型配置、代码补全、内联聊天、代码解释、重构建议等。
ProxyAI的"自定义模型"功能是其区别于其他AI插件的关键——它允许开发者配置任意OpenAI API兼容的endpoint,这意味着可以通过 AIGC bar(https://api.aigc.bar/register?aff=UP4F) 平台调用GLM-5.2等模型,而不仅限于OpenAI官方模型。
4.2 安装ProxyAI插件
在PyCharm中安装ProxyAI的步骤如下:
第一步,打开PyCharm,进入Settings/Preferences(Windows/Linux: File → Settings,macOS: PyCharm → Preferences)。
第二步,在左侧导航选择Plugins,点击Marketplace标签页。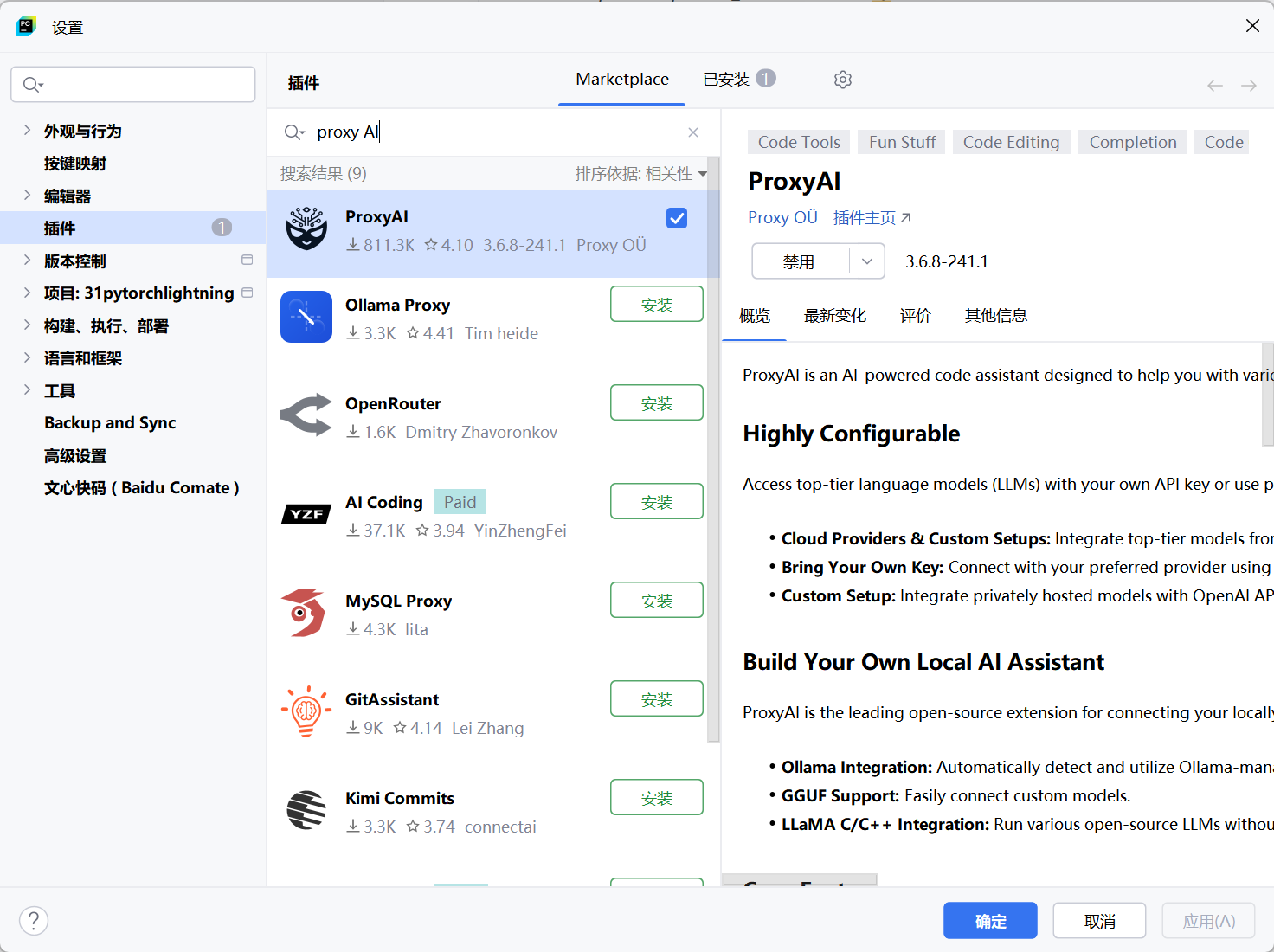
第三步,在搜索框输入"ProxyAI"或"CodeGPT",找到ProxyAI插件。
第四步,点击Install按钮安装插件,安装完成后重启PyCharm。
4.3 配置GLM-5.2自定义模型
安装完成后,需要配置ProxyAI连接 AIGC bar 平台。配置步骤如下:
第一步,在PyCharm底部工具栏找到ProxyAI图标,点击打开ProxyAI面板。
第二步,点击设置图标(齿轮),进入ProxyAI Settings。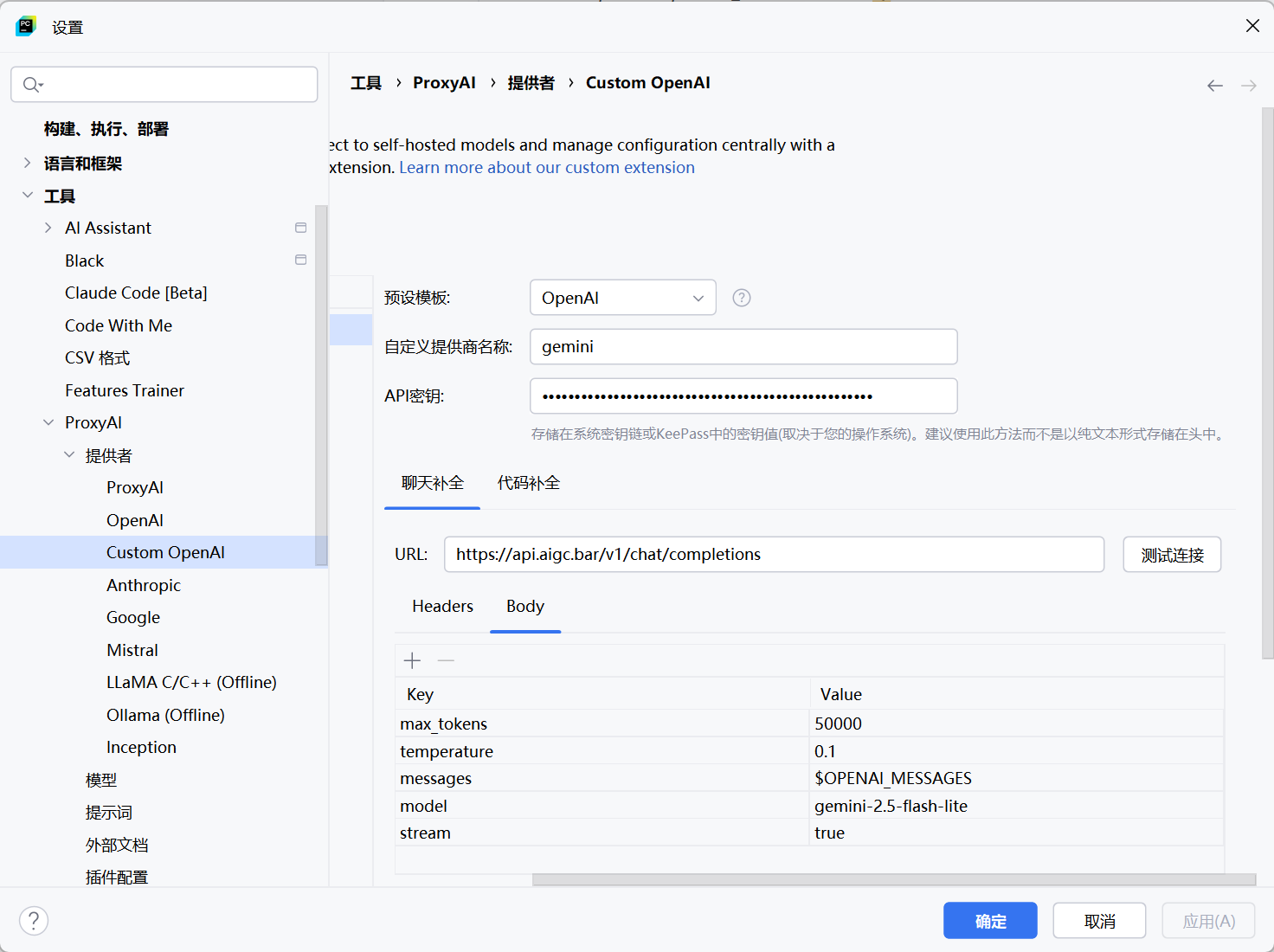
第三步,在"Custom Models"或"自定义模型"部分,点击"+"添加新模型。
第四步,填写模型配置信息:
- Provider: 选择"OpenAI"或"Custom OpenAI-compatible"
- API Key: 填入从 AIGC bar 获取的API密钥
- Base URL: 填入
https://api.aigc.bar/v1 - Model Name: 填入
GLM-5.2 - Group Header: 在自定义headers中添加
X-Group: OpenSource-MultiModal
第五步,保存配置并测试连接。ProxyAI会发送一个测试请求,验证API密钥和模型可用性。
以下是ProxyAI配置的JSON格式示例(部分版本支持直接导入JSON配置):
{
"provider": "custom",
"name": "GLM-5.2 via AIGC Bar",
"apiKey": "你的API密钥",
"baseUrl": "https://api.aigc.bar/v1",
"modelName": "glm-5.2",
"customHeaders": {
"X-Group": "OpenSource-MultiModal"
},
"temperature": 0.2,
"maxTokens": 4000,
"timeout": 60
}
4.4 配置多个模型
ProxyAI支持配置多个模型并在它们之间快速切换。建议配置以下模型以应对不同调试场景:
- GLM-5.2(OpenSource-MultiModal分组):用于复杂Bug调试和全项目分析
- DeepSeek-V4-Flash(free分组):用于快速代码问答和开发测试
- Qwen3.5-122B(OpenSource-MultiModal分组):用于高效代码审查
配置完成后,可以在ProxyAI面板顶部的模型选择器中快速切换。
5 Python代码调试实战场景
本节通过具体场景展示如何使用GLM-5.2进行Python代码调试。
5.1 场景一:运行时错误调试
运行时错误是Python开发中最常见的错误类型。以下是一个典型的TypeError调试场景:
# 有Bug的代码
def process_user_data(users):
result = []
for user in users:
name = user["name"]
age = user["age"]
processed = f"{name} is {age} years old"
result.append(processed)
return result
# 调用
data = [{"name": "Alice", "age": 30}, {"name": "Bob"}] # Bob缺少age字段
print(process_user_data(data))
在PyCharm中,选中这段代码,右键选择ProxyAI → "Explain & Fix"或使用快捷键,GLM-5.2会分析代码并给出调试建议:
GLM-5.2的调试分析会指出:代码在处理Bob的数据时会抛出KeyError: 'age',因为Bob的字典缺少"age"键。修复建议是使用dict.get()方法提供默认值,或在访问前检查键是否存在:
# 修复后的代码
def process_user_data(users):
result = []
for user in users:
name = user.get("name", "Unknown")
age = user.get("age", "N/A")
processed = f"{name} is {age} years old"
result.append(processed)
return result
GLM-5.2不仅定位了Bug,还解释了dict.get()方法的优势——它不会在键不存在时抛出异常,而是返回默认值,使代码更健壮。
5.2 场景二:异步代码调试
异步代码的调试比同步代码复杂得多,因为错误可能在不同的事件循环上下文中产生。以下是一个常见的asyncio调试场景:
import asyncio
import aiohttp
async def fetch_urls(urls):
tasks = [fetch_one(url) for url in urls]
results = await asyncio.gather(*tasks)
return results
async def fetch_one(url):
async with aiohttp.ClientSession() as session:
response = await session.get(url)
return await response.json()
# 运行
urls = ["http://example.com/1", "http://example.com/2"]
results = asyncio.run(fetch_urls(urls))
这段代码看起来正确,但可能存在连接池效率问题和异常处理缺失。将代码发送给GLM-5.2,模型会分析出以下问题:
第一,Session复用问题——每个fetch_one都创建了新的ClientSession,效率低下。应该在fetch_urls中创建一个共享的Session。
第二,异常处理缺失——session.get()可能抛出aiohttp.ClientError,response.json()可能抛出json.JSONDecodeError,这些异常都没有被处理。
第三,超时设置缺失——没有设置请求超时,可能导致请求永久挂起。
GLM-5.2生成的修复代码:
import asyncio
import aiohttp
async def fetch_urls(urls):
async with aiohttp.ClientSession() as session:
tasks = [fetch_one(session, url) for url in urls]
results = await asyncio.gather(*tasks, return_exceptions=True)
return results
async def fetch_one(session, url, timeout=30):
try:
async with session.get(url, timeout=aiohttp.ClientTimeout(total=timeout)) as response:
response.raise_for_status()
return await response.json()
except aiohttp.ClientError as e:
return {"error": str(e), "url": url}
except Exception as e:
return {"error": str(e), "url": url}
5.3 场景三:性能优化调试
性能问题是一种特殊的"Bug"——代码能正确运行,但效率低下。GLM-5.2凭借对代码语义的深度理解,能够识别性能瓶颈并提供优化建议。
# 性能低下的代码
def find_duplicates(files):
"""查找重复文件"""
duplicates = []
for i in range(len(files)):
for j in range(i + 1, len(files)):
if files[i]["content"] == files[j]["content"]:
duplicates.append((files[i]["name"], files[j]["name"]))
return duplicates
GLM-5.2会分析出这是一个 O ( n 2 ) O(n^2) O(n2)的算法,当文件数量大时性能极差。优化建议是使用哈希表将时间复杂度降为 O ( n ) O(n) O(n):
# 优化后的代码
from collections import defaultdict
def find_duplicates(files):
"""查找重复文件 - O(n)优化"""
content_map = defaultdict(list)
for file in files:
content_map[file["content"]].append(file["name"])
duplicates = []
for names in content_map.values():
if len(names) > 1:
for i in range(len(names)):
for j in range(i + 1, len(names)):
duplicates.append((names[i], names[j]))
return duplicates
5.4 场景四:跨文件Bug追踪
利用GLM-5.2的1M上下文窗口,可以进行跨文件的Bug追踪。在PyCharm中,可以将多个相关文件的内容发送给GLM-5.2,让模型理解整个调用链。
例如,当出现"ImportError: cannot import name ‘X’ from ‘module’"时,可以将module.py和调用文件的内容一起发送给GLM-5.2,模型会分析导入路径、循环依赖、命名冲突等问题,给出精确的修复建议。
6 高级调试技巧与最佳实践
6.1 Prompt工程优化调试效果
在代码调试场景中,Prompt的质量直接影响GLM-5.2的调试效果。一个优秀的调试Prompt应包含以下要素:错误信息(完整的堆栈追踪)、代码上下文(相关函数和类定义)、环境信息(Python版本、依赖版本)、期望行为(代码应该做什么)。
以下是一个优化的调试Prompt模板:
DEBUG_PROMPT = “”"
调试请求
环境信息
- Python版本: {python_version}
- 相关依赖: {dependencies}
- 操作系统: {os}
错误信息
{error_traceback}
代码
{code}
期望行为
{expected_behavior}
已尝试的修复
{attempted_fixes}
请按以下格式回答:
- 根因分析: 解释错误的根本原因
- 修复方案: 提供修复后的代码
- 预防建议: 如何避免类似问题
“”"
6.2 结合静态分析工具
GLM-5.2的语义理解能力与静态分析工具(如pylint、mypy、flake8)的规则检测能力可以形成互补。静态分析工具擅长发现语法错误、风格问题和类型不一致,而GLM-5.2擅长理解代码意图和推理逻辑错误。
一种有效的协同模式是:先用静态分析工具扫描代码,收集所有警告和错误,然后将这些信息连同代码一起发送给GLM-5.2,让模型进行综合分析和修复。这种"静态分析+AI"的模式比单独使用任一工具都能发现更多问题。
6.3 调试会话管理
在复杂的调试会话中,保持上下文连贯性很重要。ProxyAI支持多轮对话,开发者可以在一个调试会话中持续追问,GLM-5.2会记住之前的上下文。建议为每个Bug创建一个独立的调试会话,避免不同Bug的上下文混淆。
6.4 成本控制策略
使用 AIGC bar(https://api.aigc.bar/register?aff=UP4F) 平台调用GLM-5.2需要付费,合理的成本控制策略很重要。建议采用"分级路由"策略:简单代码问答使用free分组的DeepSeek-V4-Flash(免费),复杂调试使用OpenSource-MultiModal分组的GLM-5.2(付费)。这一策略可以用一个简单的决策函数表示:
Model ( x ) = { DeepSeek-V4-Flash if complexity ( x ) < τ GLM-5.2 if complexity ( x ) ≥ τ \text{Model}(x) = \begin{cases} \text{DeepSeek-V4-Flash} & \text{if } \text{complexity}(x) < \tau \\ \text{GLM-5.2} & \text{if } \text{complexity}(x) \geq \tau \end{cases} Model(x)={DeepSeek-V4-FlashGLM-5.2if complexity(x)<τif complexity(x)≥τ
其中 complexity ( x ) \text{complexity}(x) complexity(x) 为任务复杂度评估函数, τ \tau τ 为阈值。通过这一策略,开发者可以在保持调试质量的同时,将API成本降低50-70%。
6.5 调试上下文管理
在复杂的调试场景中,上下文管理是影响GLM-5.2调试效果的关键因素。ProxyAI插件提供了多种上下文管理功能,合理使用这些功能可以显著提升调试质量。
第一是代码选择。ProxyAI允许开发者选择发送给模型的代码范围——可以选当前行、当前函数、当前文件或自定义范围。对于局部Bug,选择当前函数即可;对于跨文件问题,需要选择多个相关文件。选择过多无关代码会稀释模型的注意力,选择过少则可能遗漏关键上下文。
第二是对话历史。ProxyAI的多轮对话功能会保留之前的交互历史。在调试同一Bug时,保留对话历史有助于模型理解问题的演进过程。但当切换到不同Bug时,应清除历史,避免上下文混淆。
第三是项目上下文注入。对于大型项目,可以在系统提示中注入项目的基本信息(如项目结构、技术栈、编码规范),帮助模型更好地理解代码背景。例如:
PROJECT_CONTEXT = """
## 项目信息
- 项目名称: MyWebApp
- 技术栈: Django 5.0 + PostgreSQL + Redis
- Python版本: 3.12
- 编码规范: PEP 8, 类型注解必须
## 项目结构
- mywebapp/ : Django项目根目录
- apps/ : 应用模块
- utils/ : 工具函数
- tests/ : 测试代码
"""
6.6 调试效果评估
为了客观评估GLM-5.2的调试效果,建议建立"调试日志"机制,记录每次AI调试的详细信息:Bug描述、AI建议、实际修复方案、修复耗时、是否成功。通过定期分析调试日志,可以评估AI调试的成功率、平均耗时和成本效率,为后续优化提供数据支持。
调试效果的量化评估可以参考以下指标:首次建议正确率(AI第一次建议就解决问题的比例)、平均交互轮数(解决问题所需的对话轮数)、平均调试时间(从发现问题到解决问题的时间)、成本效率(每解决一个Bug的API费用)。根据METR的研究数据,AI辅助调试可以将调试时间缩短60-80%,但首次建议正确率通常在70-85%之间,这意味着仍需要人工验证和补充。
6.7 团队协作调试
在团队开发中,AI调试的知识需要共享和积累。建议建立"团队调试知识库",将AI成功解决的Bug案例(脱敏后)归档,供团队成员参考。当类似Bug再次出现时,可以先查询知识库,再决定是否调用AI。
团队协作调试的技术实现可以通过以下方式:将调试会话导出为Markdown文件,存入团队Wiki或知识管理系统;建立"调试模式库",收集常见Bug类型的调试Prompt模板;定期举行"AI调试分享会",交流调试技巧和最佳实践。这些措施可以最大化AI调试工具的团队价值。
7 对话服务与API调用的区分
本文需要特别强调一个重要区分:如果只是使用对话服务,国内模型使用官网就可以了;API调用主要是开发者用的。这一区分对于开发者尤为重要——并非所有场景都需要通过API调用,盲目接入API可能增加不必要的成本和复杂度。
7.1 官网对话服务的适用场景
对于普通用户的日常对话需求,各模型的官网提供了优秀的开箱即用体验。智谱清言(chatglm.cn)、Kimi(kimi.com)、通义千问(tongyi.aliyun.com)、豆包(doubao.com)等官网都提供了免费的基础对话服务,无需编程知识即可使用。这些官网通常还提供文件上传、联网搜索、代码高亮、多轮对话管理等增值功能,对于个人用户的日常问答、写作辅助、学习辅导等场景,体验优于API调用。
对于开发者而言,如果只是偶尔需要AI辅助理解某段代码或回答编程问题,直接使用官网对话服务(如智谱清言)即可,无需在IDE中配置API。官网对话服务支持代码粘贴、语法高亮和格式化输出,对于简单的代码问答场景完全够用。
7.2 API调用的适用场景
API调用的核心价值在于"可编程性"和"可集成性"——将AI能力嵌入到IDE、应用程序、工作流或智能体中,实现官网无法提供的功能。在Python代码调试场景中,API调用的典型价值包括:在PyCharm内直接调用模型进行实时代码审查;将调试能力集成到CI/CD流水线中实现自动化代码检查;构建定制化的调试Agent,自动收集错误信息并调用模型分析;批量处理历史Bug报告,提取调试模式。
对于这些场景,API调用是唯一可行的路径——官网对话服务无法提供编程接口、无法实现IDE集成、无法定制系统提示、无法实现批量处理。因此,通过 AIGC bar(https://api.aigc.bar/register?aff=UP4F) 平台调用API主要面向开发者和技术团队,而非普通用户。
7.3 开发者如何选择
开发者在选择使用官网对话还是API调用时,可以参考以下决策框架。如果需求是"偶尔使用、无需IDE集成、单次问答",选择官网对话;如果需求是"频繁使用、需要IDE集成、实时调试",选择API调用;如果需求是"批量处理、自动化流程、多模型协作",必须选择API调用。
| 决策维度 | 官网对话 | API调用(ProxyAI) |
|---|---|---|
| 目标用户 | 偶尔使用的开发者 | 频繁调试的开发者 |
| 使用频率 | 偶尔/低频 | 频繁/高频 |
| IDE集成 | 无需集成 | PyCharm内直接调用 |
| 上下文管理 | 手动粘贴代码 | 自动提取代码上下文 |
| 成本模式 | 基础免费 | 按量付费 |
| 技术门槛 | 无 | 需要配置API |
| 典型场景 | 偶尔代码问答 | 日常调试/代码审查 |
8 高级调试技巧与未来展望
8.1 高级调试技巧
掌握了基础调试流程后,以下高级技巧可以进一步提升GLM-5.2的调试效果。
第一是链式调试。对于复杂的Bug,不要期望一次对话就解决,而是采用"链式调试"策略——先让模型分析错误现象,再定位可能的原因,最后生成修复方案。每一步都基于上一步的结果,形成一条调试链。这种策略可以利用GLM-5.2的长上下文窗口,保持调试过程的连贯性。
第二是对比调试。当不确定哪段代码导致问题时,可以将"正常版本"和"出错版本"的代码同时发送给GLM-5.2,让模型对比差异并定位问题。这种策略对于回归Bug(之前正常,修改后出错)特别有效。
第三是测试驱动调试。先让GLM-5.2生成能复现Bug的测试用例,再让模型根据测试用例的失败信息定位和修复问题。这种策略将调试过程结构化,每一步都有明确的验证标准,提高了修复的可靠性。
第四是多模型协作调试。利用 AIGC bar(https://api.aigc.bar/register?aff=UP4F) 平台支持多模型的优势,可以让不同模型负责调试的不同阶段——DeepSeek-V4-Flash负责快速分析错误现象,GLM-5.2负责深度定位和修复,Qwen3.5负责代码审查验证。这种协作策略可以兼顾效率和准确性。
8.2 调试Prompt工程
Prompt质量直接影响GLM-5.2的调试效果。以下是一些经过验证的调试Prompt模式。
错误堆栈分析Prompt:将完整的错误堆栈信息发送给模型,要求模型分析错误根因和修复方案。关键是要包含完整的堆栈信息,而非仅最后一行——完整的堆栈能帮助模型理解调用链路。
代码审查Prompt:让模型审查一段代码,识别潜在的Bug和改进点。这种Prompt适合在代码提交前使用,可以预防Bug的产生。建议在Prompt中明确审查维度(如安全性、性能、可读性、正确性)。
修复方案验证Prompt:当模型给出修复方案后,可以让模型自己验证方案的正确性——“请检查你的修复方案是否可能引入新的问题”。这种"自我验证"机制可以提高修复的可靠性。
根因分析Prompt:对于反复出现的Bug,可以让模型进行根因分析——“这个Bug的根本原因是什么?如何从架构层面避免类似问题?”。这种深度分析有助于提升代码质量,而非仅修复表面问题。
8.3 未来展望
展望未来,AI辅助Python代码调试将呈现几个发展趋势。第一是Agent化调试——从"人提问AI回答"走向"AI自主调试",AI能够自动检测错误、收集上下文、生成修复方案并验证修复效果,整个调试过程无需人工干预。GLM-5.2在SWE-bench上的81.0%成绩,预示着这一方向的技术可行性。
第二是多模态调试——从"纯文本代码"走向"代码+日志+截图+性能数据"的多模态调试。开发者可以发送错误截图、性能火焰图等视觉信息,AI能够综合分析多模态数据定位问题。
第三是预防性调试——从"事后修复"走向"事前预防",AI在代码编写阶段就识别潜在问题,减少Bug的产生。这一方向需要模型具备更强的代码审查和模式识别能力。
第四是端侧调试——随着模型轻量化技术的进步,部分调试能力可能下沉到本地设备,实现低延迟的实时调试辅助,同时保护代码隐私。
8.4 实践建议
对于想要尝试GLM-5.2辅助Python调试的开发者,本文给出以下建议。第一,从简单场景开始——先用GLM-5.2处理单个函数的调试,熟悉模型的能力和局限,再逐步扩展到跨文件调试。第二,保持批判性思维——AI的调试建议需要人工验证,不能盲目信任,特别是涉及安全性和正确性的关键代码。第三,建立反馈循环——记录AI调试的成功和失败案例,分析模式,优化Prompt策略。第四,关注成本——合理使用free分组和付费分组,避免不必要的API调用。
通过 AIGC bar 平台,开发者可以便捷地接入GLM-5.2等多种模型,在PyCharm中构建自己的AI调试助手。在这个AI赋能编程的时代,掌握AI辅助调试能力,是每一位Python开发者提升效率的核心竞争力。GLM-5.2以其强大的代码理解能力和长上下文窗口,正成为Python开发者最值得信赖的"AI调试搭档"。
7.1 官网对话服务的适用场景
对于普通用户的日常对话需求,各模型的官网提供了优秀的开箱即用体验。智谱清言(chatglm.cn)、Kimi(kimi.com)、通义千问(tongyi.aliyun.com)等官网都提供了免费的基础对话服务,无需编程知识即可使用。这些官网通常还提供文件上传、联网搜索、代码高亮等增值功能,对于个人用户的日常问答、学习辅导等场景,体验优于API调用。
而对于需要在IDE中集成AI能力的开发者,通过 AIGC bar(https://api.aigc.bar/register?aff=UP4F) 平台调用API则是最佳选择。API调用提供了官网无法实现的可编程性、可集成性和可定制性,使开发者能够将GLM-5.2的强大能力深度嵌入到自己的开发工作流中。无论是通过ProxyAI插件在PyCharm中进行实时代码调试,还是通过Python SDK构建自动化调试流水线,API调用都为开发者打开了无限可能。
总之,GLM-5.2作为2026年开源大模型的旗舰,其在Python代码调试领域的应用才刚刚开始。随着模型的持续迭代和工具生态的不断完善,AI辅助调试将成为每一位开发者的标准工作方式。掌握这一技能,不仅能提升个人开发效率,更能在AI时代保持技术竞争力。
7.2 API调用的适用场景
API调用的核心价值在于"可编程性"和"可集成性"——将AI能力嵌入到IDE、应用程序或工作流中。本文介绍的PyCharm+ProxyAI方案就是典型的API调用场景——将GLM-5.2集成到IDE中,实现实时代码调试。其他API调用场景包括:构建CI/CD流水线中的自动代码审查工具、开发定制化的代码质量平台、实现批量代码重构工具等。
| 决策维度 | 官网对话 | API调用(ProxyAI等) |
|---|---|---|
| 目标用户 | 普通用户/学习者 | 开发者 |
| 使用场景 | 日常问答/学习 | IDE集成/工作流 |
| 成本模式 | 基础免费 | 按量付费 |
| 技术门槛 | 无 | 需要配置能力 |
| 定制程度 | 无 | 高度可定制 |
| 典型工具 | 浏览器 | PyCharm+ProxyAI |
8 总结与展望
8.1 GLM-5.2调试能力总结
GLM-5.2在Python代码调试场景中展现出三大核心优势。第一是长上下文理解——1M token的上下文窗口使模型能够理解整个项目,进行跨文件Bug追踪。第二是深度语义分析——744B参数的MoE架构提供了强大的代码理解能力,能够推理执行路径和分析逻辑错误。第三是开源生态优势——作为开源模型,GLM-5.2的权重公开,企业可以在需要时进行本地部署,避免对单一API供应商的过度依赖。
通过 AIGC bar 平台和PyCharm ProxyAI插件,开发者可以在IDE内直接调用GLM-5.2进行实时代码调试,将调试效率提升数倍。这一方案的核心价值在于"无缝集成"——开发者无需离开IDE,即可获得AI的调试支持,保持了心流状态。
8.2 未来展望
展望未来,AI辅助代码调试将呈现几个趋势。第一是Agent化调试——从"人工+AI辅助"走向"AI自主调试",Agent能够自动运行测试、分析失败原因、生成修复代码并验证修复效果。GLM-5.2在SWE-bench上的表现已经展示了这一方向的潜力。
第二是多模态调试——结合截图、日志、性能指标等多模态信息进行综合诊断。例如,模型可以同时分析错误截图、堆栈追踪和性能火焰图,提供更全面的调试建议。
第三是预防性调试——从"事后修复"走向"事前预防",AI在代码编写阶段就识别潜在问题,减少Bug的产生。这一方向需要模型具备更强的代码审查和模式识别能力。
第四是端侧调试——随着模型轻量化技术的进步,部分调试能力可能下沉到本地设备,实现低延迟的实时调试辅助,同时保护代码隐私。
8.3 实践建议
对于想要尝试GLM-5.2辅助Python调试的开发者,本文给出以下建议。第一,从简单场景开始——先用GLM-5.2处理单个函数的调试,熟悉模型的能力和局限,再逐步扩展到跨文件调试。第二,保持批判性思维——AI的调试建议需要人工验证,不能盲目信任,特别是涉及安全性和正确性的关键代码。第三,建立反馈循环——记录AI调试的成功和失败案例,分析模式,优化Prompt策略。第四,关注成本——合理使用free分组和付费分组,避免不必要的API调用。
通过 AIGC bar(https://api.aigc.bar/register?aff=UP4F) 平台,开发者可以便捷地接入GLM-5.2等多种模型,在PyCharm中构建自己的AI调试助手。在这个AI赋能编程的时代,掌握AI辅助调试能力,是每一位Python开发者提升效率的核心竞争力。GLM-5.2以其强大的代码理解能力和长上下文窗口,正成为Python开发者最值得信赖的"AI调试搭档"。
[1] Z.ai. GLM-5.2: Built for Long-Horizon Tasks[EB/OL]. Hugging Face Blog, 2026. 链接: https://huggingface.co/blog/zai-org/glm-52-blog
[2] Sebastian Raschka. GLM-5.2 and IndexShare for Long-Context Sparse Attention[EB/OL]. 2026. 链接: https://sebastianraschka.com/blog/2026/glm-5-2-indexshare.html
[3] METR. Measuring the Impact of Early-2025 AI on Experienced Open-Source Developer Productivity[R]. 2025. 链接: https://metr.org/blog/2025-07-10-early-2025-ai-experienced-os-dev-study
[4] ProxyAI. The Open-Source AI Copilot for JetBrains[EB/OL]. GitHub, 2026. 链接: https://github.com/carlrobertoh/ProxyAI
[5] iSEngLab. AwesomeLLM4APR: A Systematic Literature Review of LLMs for Automated Program Repair[J]. TOSEM, 2026. 链接: https://github.com/iSEngLab/AwesomeLLM4APR
[6] Cai W, et al. A Comprehensive Survey of Mixture-of-Experts[J]. arXiv preprint arXiv:2503.07137, 2025. 链接: https://arxiv.org/html/2503.07137v1
更多推荐
 42
42 0
0- 0



 已为社区贡献38条内容
已为社区贡献38条内容

所有评论(0)