
Python爬取北京未来七天天气预报
·
Python爬虫实战:爬取北京未来七天天气预报(保姆级教程)
零基础也能学会!手把手教你分析网页、编写代码、保存数据
📌 前言
天气预报是我们日常生活中经常用到的数据。作为Python初学者,用爬虫抓取天气数据是一个非常经典且有趣的练手项目。
本文将带你使用 requests + BeautifulSoup 爬取【中国天气网】北京未来七天的天气预报,并教你如何将数据保存到 CSV 文件中。
技术栈:
- Python 3.6+
- Requests(发送HTTP请求)
- BeautifulSoup4(解析HTML网页)
一、 准备工作(环境搭建)
在开始之前,请确保你的电脑安装了 Python。然后打开终端(CMD / Terminal),安装所需的第三方库:
pip install requests beautifulsoup4
## 二、分析目标网页
写爬虫的第一步不是敲代码,而是分析网页结构。
打开浏览器,访问北京天气页面:https://www.weather.com.cn/weather/101280601.shtml
按下键盘上的 F12 打开开发者工具(检查元素)。
点击左上角的“选择元素”箭头(或按 Ctrl+Shift+C),点击网页上的日期,查看对应的 HTML 代码。
通过分析,我们发现:
7天的数据都包裹在 <div id="7d"> 里面。
每一天的数据是一个 <li> 标签。
每个 <li> 里面:
<h1> 存放日期(如“24日星期二”)
第一个 <p> 存放天气状况(如“晴”)
第二个 <p> 存放温度(<span> 是最高温,<i> 是最低温)
第三个 <p> 存放风向和风级(<span> 存风向,<i> 存风级)
注意:有些日子可能没有最高温(<span> 标签不存在),代码里需要做判空处理。
```python
import requests
from bs4 import BeautifulSoup
def get_weather():
url = 'https://www.weather.com.cn/weather/101280601.shtml'
# 模拟浏览器请求头,防止被网站拦截
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36'
}
try:
r = requests.get(url, headers=headers, timeout=10)
r.raise_for_status() # 如果状态码不是200,抛出异常
r.encoding = r.apparent_encoding # 自动检测编码,解决中文乱码
return r.text
except Exception as e:
print(f"请求失败:{e}")
return None
二、 解析 HTML 并提取数据
def parse_weather(html):
soup = BeautifulSoup(html, 'html.parser')
# 1. 找到 id="7d" 的 div
div_7d = soup.find('div', {'id': '7d'})
# 2. 找到 ul 标签
ul = div_7d.find('ul')
# 3. 找到所有 li 标签(未来7天)
li_list = ul.find_all('li')
weather_data = []
for day in li_list:
# 日期(例如:"24日星期二")
date = day.find('h1').string
# 所有 p 标签:0-天气,1-温度,2-风向风级
p_list = day.find_all('p')
# 天气状况
weather_desc = p_list[0].string
# ---- 温度提取 ----
# 最低温(在 <i> 标签里)
low_temp = p_list[1].find('i').string
# 最高温(在 <span> 标签里,可能不存在)
high_span = p_list[1].find('span')
if high_span:
high_temp = high_span.string + '℃'
else:
high_temp = '无数据'
# ---- 风向风级提取 ----
# 找出所有 span(通常第一个是风向,第二个是风级)
wind_spans = p_list[2].find_all('span')
# 风向(取 title 属性,中文名称)
if len(wind_spans) > 0:
wind_direction = wind_spans[0].get('title', '未知风向')
else:
wind_direction = '未知'
# 风级(在 <i> 标签里)
wind_scale = p_list[2].find('i').string
# 组装成字典
item = {
'date': date,
'weather': weather_desc,
'low_temp': low_temp,
'high_temp': high_temp,
'wind_direction': wind_direction,
'wind_scale': wind_scale
}
weather_data.append(item)
return weather_data
2.1 主程序运行与打印
if __name__ == '__main__':
html = get_weather()
if html:
data_list = parse_weather(html)
print("\n========== 北京未来七天天气预报 ==========\n")
for item in data_list:
print(f"📅 日期:{item['date']}")
print(f"☁️ 天气:{item['weather']}")
print(f"🌡️ 温度:{item['low_temp']} ~ {item['high_temp']}")
print(f"💨 风向:{item['wind_direction']}")
print(f"🌀 风级:{item['wind_scale']}")
print("-" * 30)
三、完整代码展示图
# coding:utf-8
'''
Python爬取北京未来七天的天气预报数据,并保存为CSV文件
'''
import requests
import re
import os
import csv # 新增:用于保存CSV
from bs4 import BeautifulSoup
# 需更换地区的到这里面去找:
# http://www.weather.com.cn/textFC/hb.shtml
def now_weather():
'''返回七天对应天气信息'''
url = 'https://www.weather.com.cn/weather/101280601.shtml'
# 添加请求头模拟浏览器,防止反爬
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36'
}
r = requests.get(url, headers=headers, timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
html = r.text
final = [] # 初始化一个列表保存数据
bs = BeautifulSoup(html, "html.parser") # 创建BeautifulSoup对象
body = bs.body
data = body.find('div', {'id': '7d'}) # 找到div标签且id = 7d
ul = data.find('ul') # 找到所有的ul标签
li = ul.find_all('li') # 找到所有的li标签
temp = [] # 临时存放每天的数据
for day in li: # 遍历找到的每一个li
date = day.find('h1').string # 得到日期
dateday = date[0:date.index('日')] # 取出日期号
inf = day.find_all('p') # 找出li下面的p标签,提取第一个p标签的值,即天气
tem_low = inf[1].find('i').string # 找到最低气温
if inf[1].find('span') is None: # 天气预报可能没有最高气温
tem_high = '无数据'
else:
tem_high = inf[1].find('span').string + '℃' # 找到最高气温并加上单位
wind = inf[2].find_all('span') # 找到风向
# 修复:原来两个都是 wind[0],改为 wind[0] 和 wind[1]
# 有些地区可能只有一个span,做一下判断
if len(wind) >= 2:
windstr = wind[0]['title'] + '-' + wind[1]['title']
else:
windstr = wind[0]['title'] if wind else '未知'
wind_scale = inf[2].find('i').string # 找到风级
dircy = {
'date': date,
'dateday': dateday,
'inf': inf[0].string,
'tem_low': tem_low,
'tem_high': tem_high,
'windstr': windstr,
'wind_scale': wind_scale
}
temp.append(dircy)
return temp
if __name__ == "__main__":
print('\n')
tlist = now_weather()
# 1. 打印到终端
for te in tlist:
print(f'日期:{te["date"]}\n地区:北京\n天气:{te["inf"]}\n最低气温:{te["tem_low"]}\
\n最高气温:{te["tem_high"]}\n风向:{te["windstr"]}\n风级:{te["wind_scale"]}')
print('\n')
# 2. 保存为CSV文件
filename = '北京未来七天天气.csv'
with open(filename, 'w', newline='', encoding='utf-8-sig') as csvfile:
fieldnames = ['date', 'dateday', 'inf', 'tem_low', 'tem_high', 'windstr', 'wind_scale']
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader() # 写入表头
writer.writerows(tlist) # 写入所有数据
print(f'✅ 数据已保存到:{filename}')
3.1运行结果展示图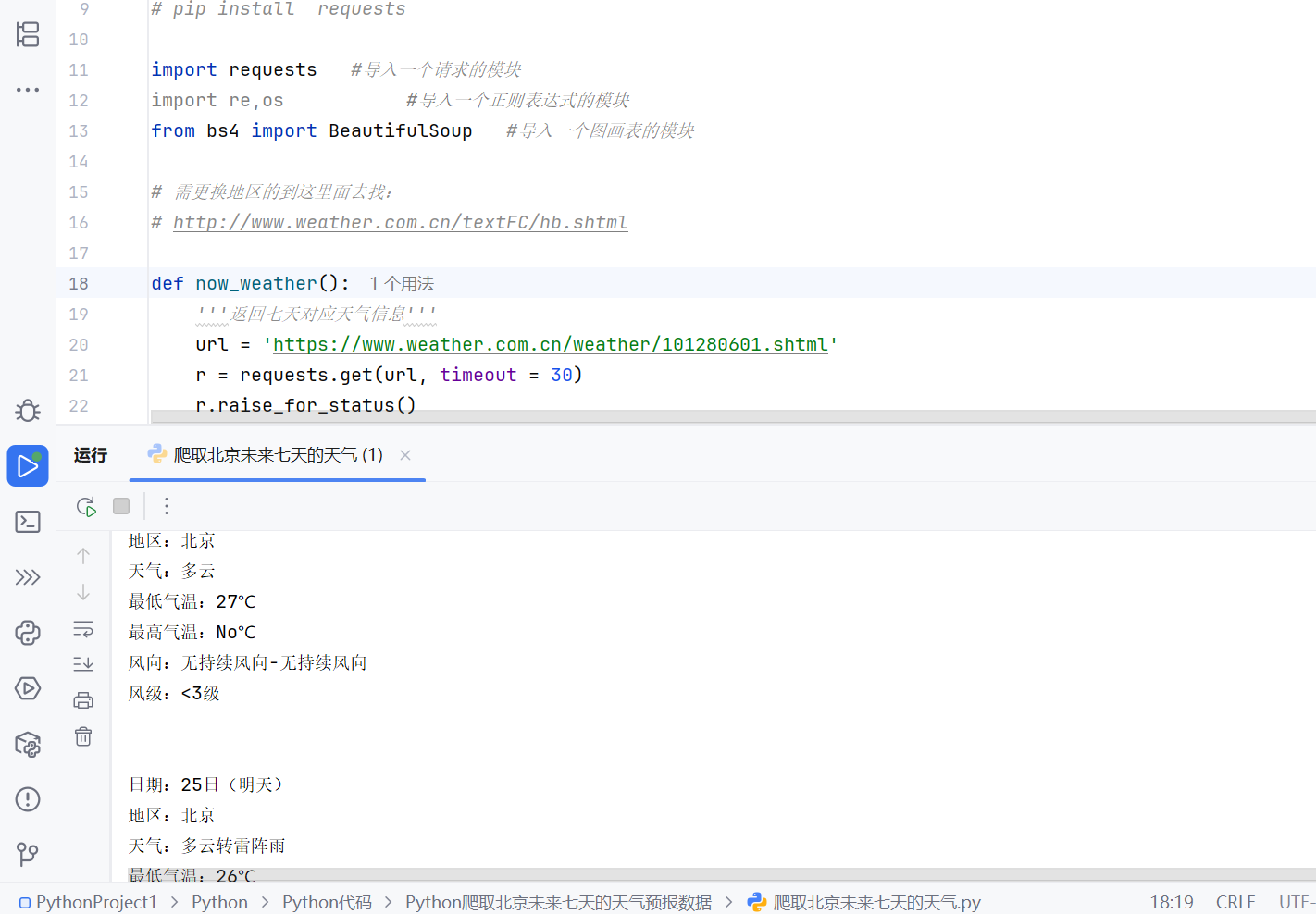
3.2拓展:将数据保存为 CSV 文件
仅仅在终端打印是不够的,我们通常需要保存数据。下面演示如何将爬取的数据导出为 weather.csv 文件。
在 if name == ‘main’: 中增加以下代码:
import csv
# ...(获取和解析数据的代码不变)...
if html:
weathers = parse_weather(html)
# 保存为 CSV
with open('北京天气.csv', 'w', newline='', encoding='utf-8-sig') as f:
writer = csv.DictWriter(f, fieldnames=['date', 'weather', 'low_temp', 'high_temp', 'wind_direction', 'wind_scale'])
writer.writeheader()
writer.writerows(weathers)
print("✅ 数据已成功保存到 北京天气.csv")
总结: encoding=‘utf-8-sig’ 可以保证 Excel 打开 CSV 时中文不乱码。
更多推荐
 4
4 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)