
【万字文档+源码】基于springboot+vue国内旅游景点数据爬虫与可视化分析项目-可用于毕设-课程设计-练手学习-学习资料分享
一、项目背景与目标
1.1 项目背景
随着国内旅游市场持续扩大,游客数量逐年攀升,各类旅游景点、景区、文旅项目快速增长,但行业普遍存在以下问题:
-
旅游景点信息分散在各大平台,缺乏统一、规范、结构化的数据集合;
-
景区运营方缺少对游客偏好、评分分布、景点热度的量化分析;
-
旅游管理部门难以通过数据进行科学规划、资源配置与营销策略制定;
-
传统数据分析方式效率低、周期长,无法满足大数据时代实时性、规模化需求。
在此背景下,本项目依托网络爬虫、大数据存储、数据挖掘、可视化大屏技术,对国内主流旅游平台景点数据进行自动化采集、清洗、存储、分析与展示,形成一套完整可用的旅游数据智能分析系统,为旅游行业提供数据支撑。
1.2 项目目标
-
实现旅游景点数据自动化、批量、稳定爬取;
-
完成原始数据清洗、去重、缺失值处理,提高数据质量;
-
搭建 Hadoop 分布式存储环境,实现海量旅游数据可靠管理;
-
使用 Hive 数据仓库完成景点数据统计、查询、计算;
-
通过 Jupyter Notebook 实现多维度可视化分析,挖掘景点规律;
-
开发前后端分离的可视化大屏,实现旅游数据一站式展示;
-
为游客出行、景区运营、文旅决策提供可落地的数据参考。
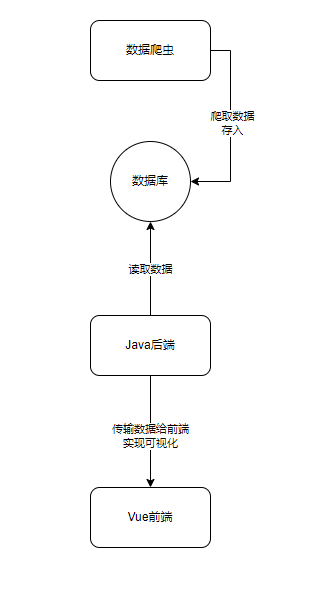
二、项目整体技术架构
本项目采用多层架构 + 大数据生态,整体流程如下:
-
数据采集层:Scrapy 爬虫框架 → 爬取去哪儿网景点信息、评分、评论、价格等;
-
数据预处理层:Python + Pandas → 数据清洗、格式转换、去重、缺失值处理;
-
数据存储层:
-
本地存储:CSV 文件;
-
关系型存储:MySQL 存储结构化景点数据;
-
分布式存储:HDFS 存储海量原始与清洗后数据;
-
-
数据计算层:Hive 数据仓库 → 类 SQL 实现大数据统计分析;
-
数据分析层:Jupyter Notebook + Matplotlib/Seaborn → 可视化挖掘;
-
应用展示层:Vue + Echarts + Java 后端 → 旅游数据可视化大屏。
三、核心技术详细说明
3.1 Scrapy 爬虫框架
Scrapy 是 Python 生态中高效、异步、企业级爬虫框架,本项目使用其实现:
-
高并发爬取,大幅提升数据采集效率;
-
结构化数据解析(XPath / CSS 选择器);
-
自定义爬取规则、翻页策略、请求头伪装;
-
防反爬处理:设置请求间隔、User-Agent、Cookie;
-
Pipeline 管道:统一数据清洗、入库、保存逻辑。
3.2 Python 数据处理与 CSV
-
使用 Pandas 读取、加载、操作结构化数据;
-
处理内容包括:删除冗余列、去除空值、去重、字段类型统一;
-
CSV 作为中间存储格式,轻量、通用、易被 Hive、Excel、数据库识别;
-
支持批量导出、编码统一(UTF-8),避免中文乱码。
3.3 HDFS 分布式文件系统
HDFS 是 Hadoop 核心组件,用于解决海量数据存储问题:
-
数据分块存储,默认三副本机制,保证数据高可靠;
-
支持超大文件存储与高吞吐读写;
-
主从架构:NameNode 管理元数据,DataNode 存储实际数据;
-
适合本项目中长期保存大量景点历史数据、评论数据。
3.4 Hive 数据仓库
Hive 构建在 Hadoop 之上,提供类 SQL 查询能力:
-
支持建表、加载数据、分组统计、聚合计算;
-
自动将查询转为 MapReduce 任务,适合大数据量离线分析;
-
支持分区、分桶,提高查询效率;
-
无需复杂编程,SQL 使用者可快速上手大数据分析。
3.5 Jupyter Notebook 交互式分析
-
支持代码、文本、图表、公式在同一文档展示;
-
适合数据分析迭代调试、可视化展示与报告生成;
-
集成 Matplotlib、Seaborn、Plotly 等绘图库;
-
可直接连接 Hive、MySQL 读取数据进行分析。
3.6 可视化大屏技术
-
前端:Vue.js 构建单页应用;
-
图表:Echarts 绘制折线图、柱状图、饼图、地图、雷达图;
-
后端:Java 提供 RESTful 接口;
-
数据交互:Ajax 异步请求,实现大屏动态刷新。

四、数据来源与爬取详细流程
4.1 数据源说明
本项目数据源为去哪儿网,爬取内容包括:
-
景点基础信息:名称、图片、地址、开放时间、门票价格;
-
评分体系:综合评分、各维度评分、点评人数、景区排名;
-
游玩建议:建议游玩时长、景点类型(自然景观 / 人文古迹 / 主题乐园等);
-
介绍信息:景点简介、特色亮点、交通指南。
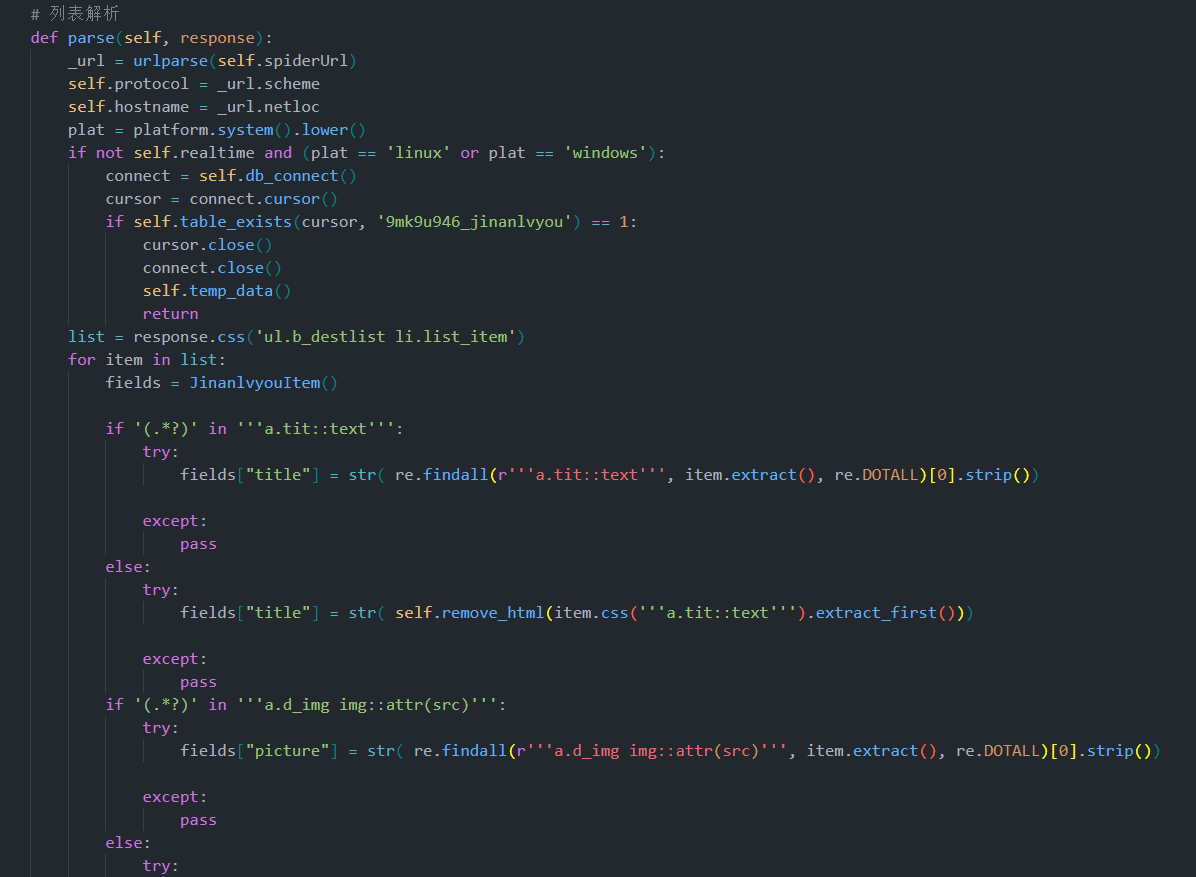
4.2 爬虫开发详细步骤
-
创建 Scrapy 项目,配置 settings:
-
开启爬虫延迟;
-
配置请求头、User-Agent;
-
关闭 ROBOTSTXT_OBEY 避免受限;
-
开启 ITEM_PIPELINES 数据处理管道。
-
-
定义 Item 数据结构:
- 景点名称、图片链接、地址、评分、排名、建议游玩时间、门票、简介等字段。
-
编写 Spider 爬虫逻辑:
-
构造起始 URL;
-
解析列表页,获取景点详情页链接;
-
进入详情页抽取目标数据;
-
自动翻页爬取,实现全量数据采集。
-
-
Pipeline 数据处理:
-
数据去空格、去换行符;
-
过滤无效、异常数据;
-
保存至本地 CSV;
-
同步写入 MySQL 数据库。
-
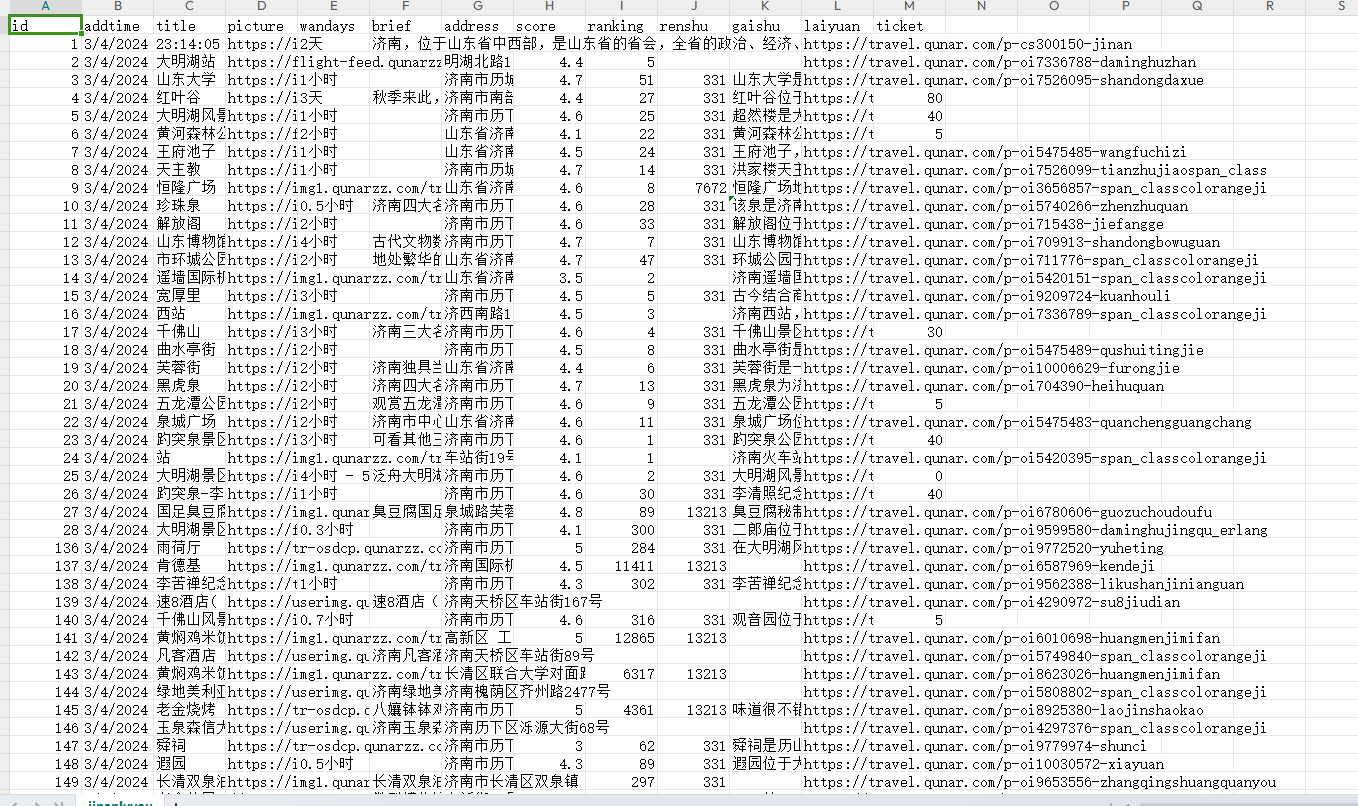
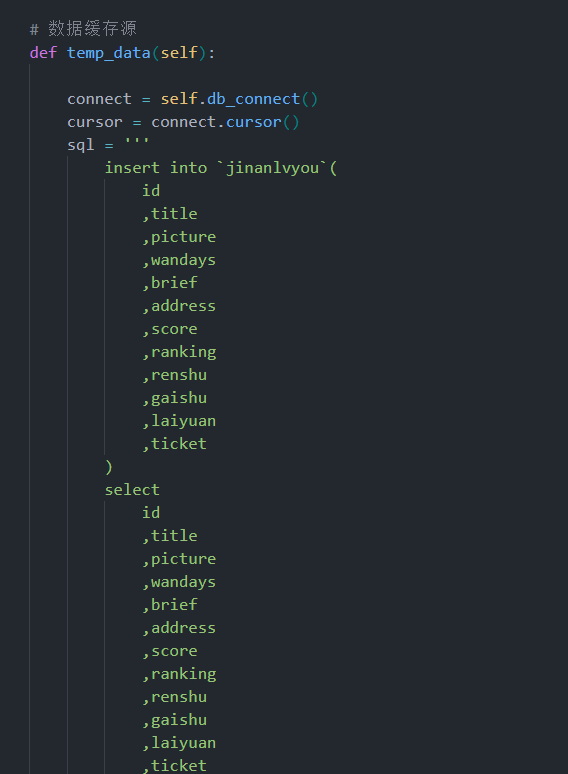
4.3 最终爬取数据字段结构
| 字段名 | 含义 | 数据类型 |
|---|---|---|
| title | 景点名称 | Varchar |
| picture | 景点图片地址 | Varchar |
| wandays | 建议游玩时间 | Int |
| brief | 景点简介 | Varchar |
| address | 景点地址 | Varchar |
| score | 综合评分 | Float |
| ranking | 景点地区排名 | Int |
| renshu | 参与评分人数 | Int |
| gaishu | 景点概述 | Text |
| laiyuan | 数据来源平台 | Varchar |
| ticket | 门票价格 / 政策 | Varchar |
| grade | 景区评级(A/AAAAA) | Varchar |
五、数据预处理详细流程
原始爬取数据存在大量噪声,必须经过预处理才能用于分析。
5.1 读取数据
使用 Pandas 读取 CSV:
import pandas as pd
df = pd.read_csv("lvyou.csv")
5.2 删除无用列
删除自动生成的索引列 Unnamed:0:
df = df.drop(columns=['Unnamed: 0'])
5.3 缺失值检测与处理
df.isnull().sum()
-
若某字段缺失率高,直接删除该列;
-
若少量缺失,删除对应行或使用均值 / 众数填充;
-
本项目经检测无大规模缺失,保留完整数据。
5.4 重复数据处理
df = df.drop_duplicates()
5.5 数据类型统一转换
-
评分、游玩时间、排名转为数值型;
-
名称、简介、地址保留字符串类型。
5.6 保存清洗后数据
df.to_csv("lvyou_clean.csv", index=False, encoding='utf-8')
六、分布式存储(HDFS)详细部署流程
6.1 启动 Hadoop 服务
start-dfs.sh
start-yarn.sh
jps # 查看进程
6.2 在 HDFS 创建数据目录
hdfs dfs -mkdir /tourism
hdfs dfs -mkdir /tourism/data
6.3 上传清洗后 CSV 到 HDFS
hdfs dfs -put lvyou_clean.csv /tourism/data/
6.4 验证文件上传成功
hdfs dfs -ls /tourism/data
hdfs dfs -cat /tourism/data/lvyou_clean.csv
七、Hive 数据查询与计算详细实现
7.1 创建 Hive 旅游数据表
CREATE TABLE IF NOT EXISTS tourism_data (
id INT,
name STRING,
type STRING,
play_time INT,
rating FLOAT,
address STRING,
ticket STRING
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE;
7.2 加载 HDFS 数据到 Hive 表
LOAD DATA INPATH '/tourism/data/lvyou_clean.csv'
OVERWRITE INTO TABLE tourism_data;
7.3 典型统计分析语句
- 查询评分前 10 热门景点
SELECT name, rating FROM tourism_data
ORDER BY rating DESC LIMIT 10;
- 统计各类景点数量
SELECT type, COUNT(*) AS count
FROM tourism_data GROUP BY type;
- 计算平均建议游玩时长
SELECT AVG(play_time) FROM tourism_data;
- 按地区统计景点数量
SELECT address, COUNT(*) FROM tourism_data GROUP BY address;
八、数据可视化详细分析(Jupyter)
通过 Python 连接 Hive 读取数据,使用 Matplotlib/Seaborn 绘图。
8.1 景点类型数量分布柱状图
-
展示自然景观、人文古迹、主题乐园、博物馆等数量对比;
-
可看出城市文旅资源结构。
8.2 景点类型占比饼图
-
直观展示各类景点所占比例;
-
用于判断区域旅游资源侧重。
8.3 评分分布直方图 / 核密度图
-
观察景点评分集中区间;
-
分析整体旅游服务质量水平。
8.4 评分与游玩时间相关性热力图
-
判断景点评分是否与游玩时长正相关;
-
挖掘高评分景点普遍特征。
8.5 热门城市景点数量对比图
-
展示各城市文旅资源丰富度;
-
为游客城市选择提供数据支持。
九、可视化大屏详细设计与实现
9.1 大屏整体功能模块
-
数据概览区
- 景点总数、已爬取数据量、平均评分、最高评分景点。
-
景点类型分布模块
- 环形图 / 饼图展示各类景点占比。
-
评分分布模块
- 柱状图展示 1~5 分景点数量分布。
-
热门景点 TOP10 排行
- 横向柱状图实时滚动展示。
-
城市景点数量统计
- 地图或柱状图展示各城市旅游资源量。
-
建议游玩时间统计
- 折线图 / 柱状图展示游玩时长分布。
9.2 后端接口(Java)
-
提供分页查询接口;
-
提供统计总数、平均值、最大值接口;
-
提供按类型、地区筛选接口;
-
返回 JSON 格式数据供前端调用。
9.3 前端实现(Vue + Echarts)
-
使用 Vue 搭建大屏布局;
-
Echarts 绘制各类图表;
-
Ajax 定时异步刷新数据;
-
深色主题、自适应分辨率,适合演示与监控。
十、项目分析结果与价值总结
10.1 核心分析结论
-
高评分景点集中在一线及旅游名城,偏远地区景点评分普遍偏低;
-
自然景观类景点数量最多,评分普遍高于人文类;
-
建议游玩时长 2~3 小时的景点最受游客欢迎;
-
评分越高的景点,点评人数显著更多;
-
门票免费 / 低价的景点评分普遍高于高价景区。
10.2 项目应用价值
-
对游客:提供客观数据参考,避免踩坑,优化旅行路线;
-
对景区:了解自身排名与短板,提升服务与运营策略;
-
对旅游平台:构建推荐系统,提高用户留存与转化率;
-
对文旅部门:科学规划旅游资源,制定精准扶持政策。
10.3 未来扩展方向
-
接入携程、美团、飞猪多平台数据;
-
增加评论情感分析,判断游客满意度;
-
接入天气、交通数据,构建综合旅游预测模型;
-
使用 Flink 实现实时数据流处理;
-
开发小程序 / App,面向公众开放查询。
十一、项目运行环境要求
-
操作系统:Windows / Linux /macOS
-
JDK 1.8+
-
Python 3.7+
-
Hadoop 3.x
-
Hive 3.x
-
MySQL 5.7+
-
Node.js(Vue 前端)
-
浏览器:Chrome/Edge
十二、项目资料

👇🏻 精彩专栏 推荐订阅 👇🏻 在下方专栏👇🏻不然下次找不到哟
《Java精品推荐项目》
《springboot+vue项目100套》
《ssm项目100套》
《微信小程序合集》
更多推荐
 6
6 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)