
python之动态柱状图
全球GDP

用什么结构,不看你画什么图,而看你“按什么查找数据”。
按顺序查 → 列表;按键查 → 字典。
| 场景 | 用列表还是字典 | 根本原因 |
|---|---|---|
| 普通柱状图 | 列表 | 只用一次,不需要“按某字段查找” |
| 折线图 | 列表 | 年份天然有序,直接按位置索引即可 |
| 动态柱状图 | 字典 | 需要 按年份快速获取一组数据 |
| 动态折线图 | 字典 | 需要 按国家快速获取一条时间线 |
关键:看你要“按什么查”
-
列表:适合“顺序访问”(第1个、第2个……)
-
字典:适合“按键查找”(给我
key=1960的数据)
动态柱状图要 按年份取 8 个国家,所以 key=年份,字典最合适。
1.读取 CSV 文件
python
f = open("1960-2019全球GDP数据.csv", "r", encoding="utf-8")
data_lines = f.readlines()
f.close()
data_lines.pop(0)
| 代码 | 解释 |
|---|---|
open("...csv", "r", encoding="utf-8") |
以只读模式打开 CSV 文件,用 UTF-8 编码(确保中文不乱码) |
f.readlines() |
读取文件的所有行,返回一个字符串列表,每行是一个元素 |
f.close() |
关闭文件,释放资源(好习惯) |
data_lines.pop(0) |
删除列表的第一个元素(表头 year,country,gdp),只保留数据行 |
举例:
python
# 原始 data_lines:
["year,country,gdp", "1960,美国,543300000000", "1960,中国,59716467625", ...]
# pop(0) 之后:
["1960,美国,543300000000", "1960,中国,59716467625", ...]
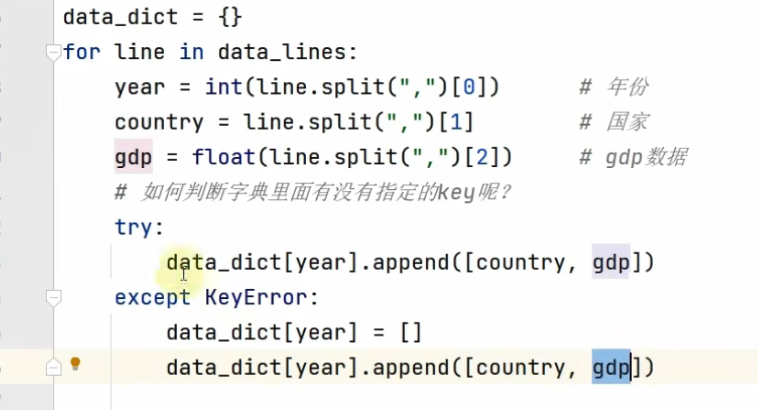
2.将数据整理成字典
python
data_dict = {}
for line in data_lines:
parts = line.strip().split(",")
year = int(parts[0])
country = parts[1]
gdp = float(parts[2])
if year not in data_dict:
data_dict[year] = []
data_dict[year].append([country, gdp])
字典结构
python
data_dict = {
1960: [["美国", 5433], ["中国", 597], ["日本", 443], ...],
1961: [["美国", 5633], ["中国", 500], ["日本", 535], ...],
1962: [["美国", 5800], ["中国", 520], ["日本", 600], ...],
...
}
这是程序运行后,data_dict 在内存中呈现的样子。
| 代码 | 解释 |
|---|---|
data_dict = {} |
创建空字典,格式:{年份: [[国家, GDP], [国家, GDP], ...]} |
for line in data_lines: |
遍历每一行数据 |
line.strip().split(",") |
去掉首尾空格/换行,然后按逗号分割成列表 |
year = int(parts[0]) |
第一列是年份,转成整数 |
country = parts[1] |
第二列是国家名 |
gdp = float(parts[2]) |
第三列是 GDP 数值,转成浮点数 |
if year not in data_dict: |
如果这个年份还没在字典里 |
data_dict[year] = [] |
创建一个空列表 |
data_dict[year].append([country, gdp]) |
把 [国家, GDP] 添加到该年份的列表中 |
最终 data_dict 结构示例:
text
CSV 文件内容: ┌──────────────────────────────────────┐ │ 1960,美国,543300000000 │ ← 第1行 │ 1960,中国,59716467625 │ ← 第2行 │ 1960,日本,44307342950 │ ← 第3行 │ 1961,美国,563300000000 │ ← 第4行 │ 1961,中国,50000000000 │ ← 第5行 └──────────────────────────────────────┘ ↓ 逐行处理 第1行: year=1960, country="美国", gdp=543300000000 → data_dict 中没有 1960 → 创建 data_dict[1960] = [] → data_dict[1960].append(["美国", 543300000000]) 第2行: year=1960, country="中国", gdp=59716467625 → data_dict 中已有 1960 → 直接追加 → data_dict[1960].append(["中国", 59716467625]) 第3行: year=1960, country="日本", gdp=44307342950 → data_dict[1960].append(["日本", 44307342950]) 第4行: year=1961, country="美国", gdp=563300000000 → data_dict 中没有 1961 → 创建 data_dict[1961] = [] → data_dict[1961].append(["美国", 563300000000]) 第5行: year=1961, country="中国", gdp=50000000000 → data_dict[1961].append(["中国", 50000000000]) ↓ 最终结果 data_dict = { 1960: [["美国", 543300000000], ["中国", 59716467625], ["日本", 44307342950]], 1961: [["美国", 563300000000], ["中国", 50000000000]], ... }先按照逗号进行分割,然后如果没有年份的键值,那么就创建一个新的然后在添加元素,组成新的字典。字典里的键值是年份,元素是列表,包括 GDP 和国家。
原始 CSV 一行: "1960,美国,543300000000"
↓ split(",") 分割
["1960", "美国", "543300000000"]
↓ 提取
year = 1960, country = "美国", gdp = 543300000000
↓ 检查字典
if year not in data_dict: ← 1960 在字典里吗?
data_dict[year] = [] ← 不在 → 创建一个空列表↓ 添加
data_dict[1960].append(["美国", 543300000000])
↑
[国家, GDP]把文档里的三个值(年份、国家、GDP),用年份作为键,用国家+GDP 作为值。值是一个列表,里面可以包含很多个
[国家, GDP]。因为年份不重复,所以用年份当键很合适。为什么用年份当键?
类比帮助理解
想象一个文件柜:
text
文件柜(字典 data_dict) ├── 抽屉 1960(键) → 里面放了一叠文件(列表) │ ├── 文件1: ["美国", 5433] │ ├── 文件2: ["中国", 597] │ └── 文件3: ["日本", 443] ├── 抽屉 1961(键) → 里面放了一叠文件(列表) │ ├── 文件1: ["美国", 5633] │ └── 文件2: ["中国", 500] └── 抽屉 1962(键) → 里面放了一叠文件(列表) ├── 文件1: ["美国", 5800] ├── 文件2: ["中国", 520] └── 文件3: ["日本", 600]
文件柜 = 字典
data_dict抽屉标签 = 键(年份)
抽屉里的文件 = 值(列表)
原因 说明 不重复 1960 年只有一个,不会出现两个 1960 唯一标识 每个年份代表一组数据 快速查找 想取 1960 年的数据,直接 data_dict[1960]就行
3.获取所有年份并排序
从为年份开始排序,按照gdp从大到小排序,然后只排序前8个,x轴为国家,y轴为GDP。
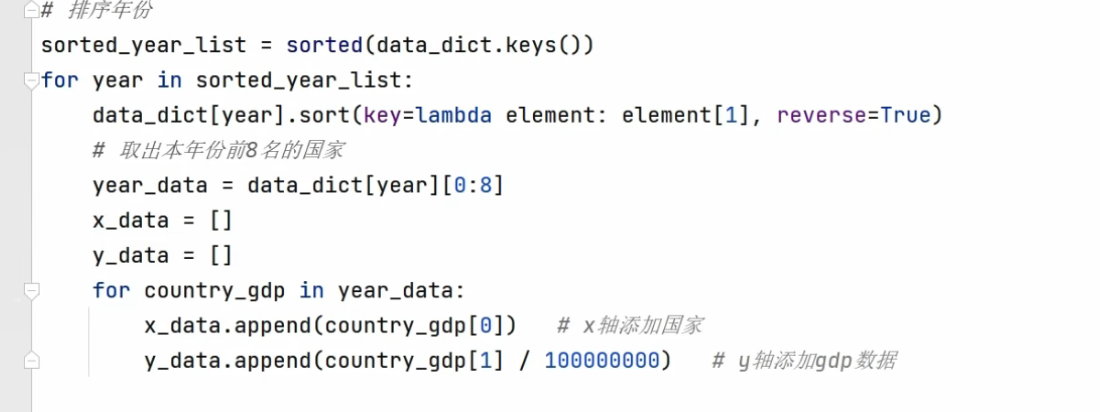
python
# 1. 排序年份 sorted_year_list = sorted(data_dict.keys()) # 2. 遍历每一年 for year in sorted_year_list: # 3. 对该年的数据按 GDP 降序排序(从大到小),lambda data_dict[year].sort(key=lambda element: element[1], reverse=True) # 4. 取前8名 year_data = data_dict[year][0:8] # 5. 准备 x 轴(国家)和 y 轴(GDP)数据 x_data = [] y_data = [] for country_gdp in year_data: x_data.append(country_gdp[0]) # 国家名 y_data.append(country_gdp[1] / 100000000) # GDP 转亿总结
代码 作用 sorted(data_dict.keys())年份排序(1960→2019) data_dict[year].sort(key=lambda x: x[1], reverse=True)该年数据按 GDP 从大到小排序 data_dict[year][0:8]取前 8 名 x_data.append(country_gdp[0])提取国家名 y_data.append(country_gdp[1] / 100000000)提取 GDP 并转成"亿"
核心总结
| 代码 | 作用 |
|---|---|
line.strip() |
去掉换行符 \n 和首尾空格 |
.split(",") |
按逗号切成列表 |
int(parts[0]) |
年份转整数(为了排序) |
parts[1] |
国家名(保持文本) |
float(parts[2]) |
GDP 转浮点数(为了计算) |
python
sorted_years = sorted(data_dict.keys())
| 代码 | 解释 |
|---|---|
data_dict.keys() |
获取字典的所有键(年份) |
sorted() |
对年份升序排序(1960, 1961, 1962...) |
反转 xy 轴就是让国家名在 y 轴、GDP 数值在 x 轴,变成横向柱状图。然后在排序年份之前创建时间线对象,排序好之后,以年份为时间线对象,就得到了动态柱状图。
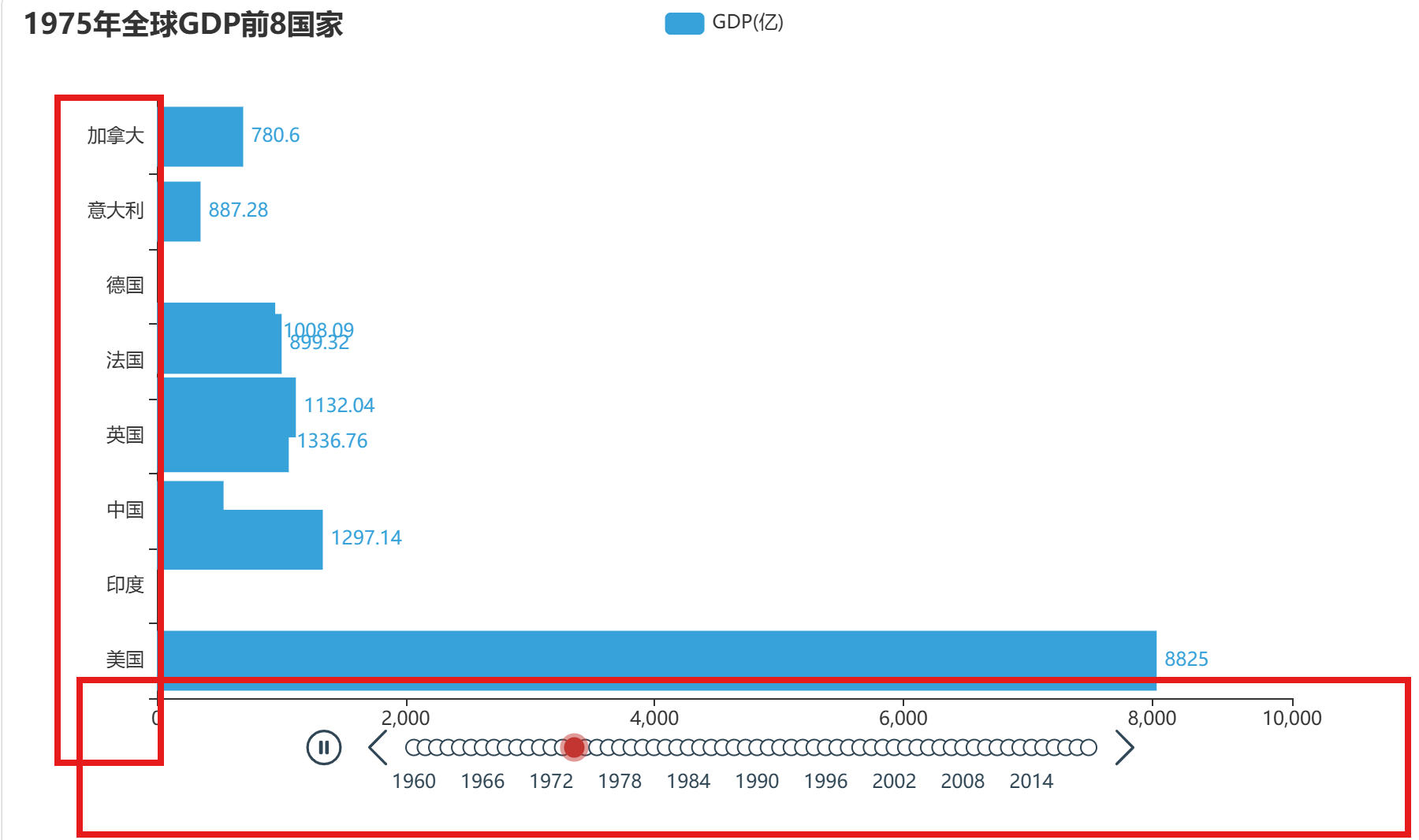
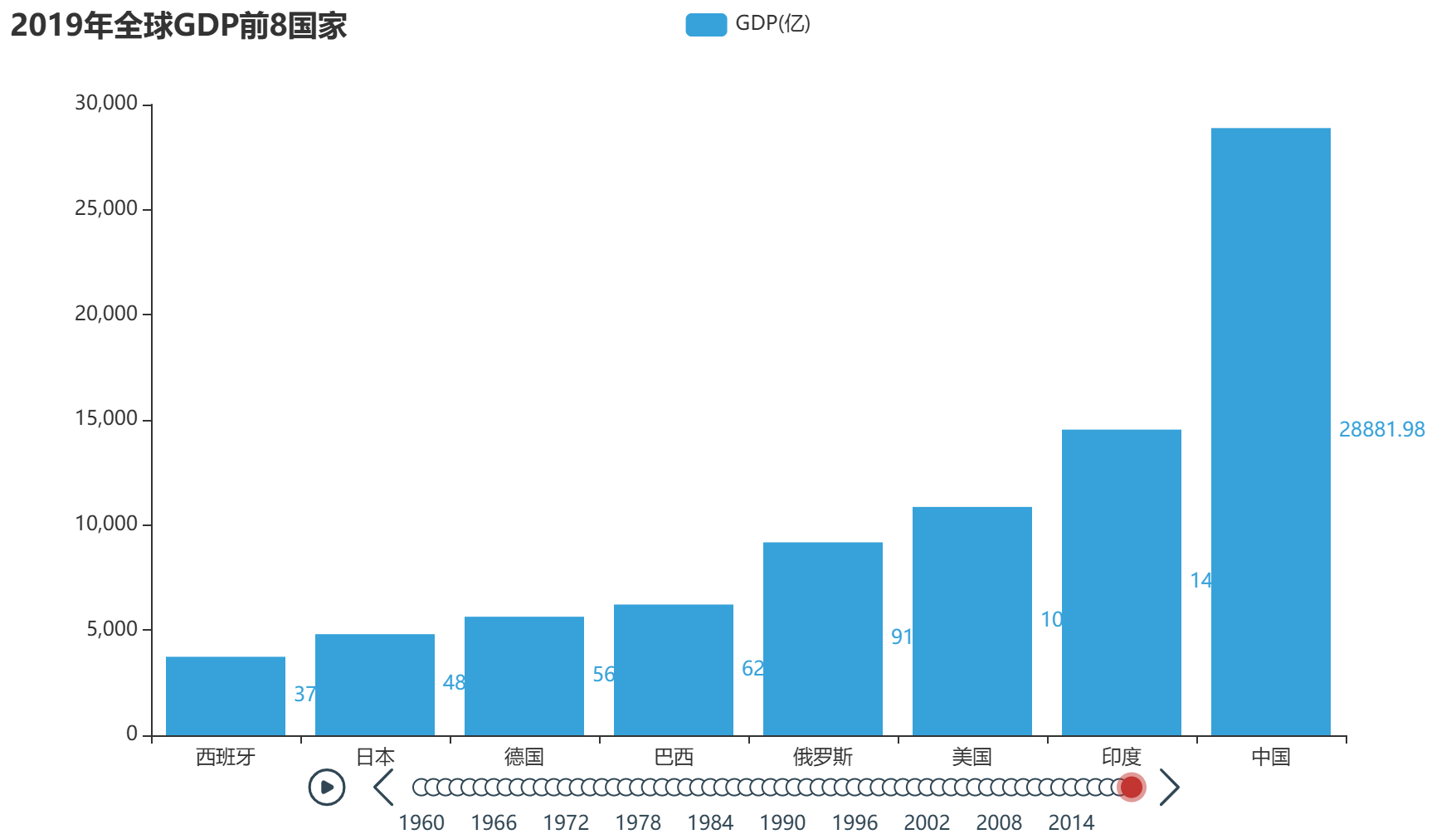
但是还缺了排序,也就是GDP应该从高到低,高的应该排在最上边。
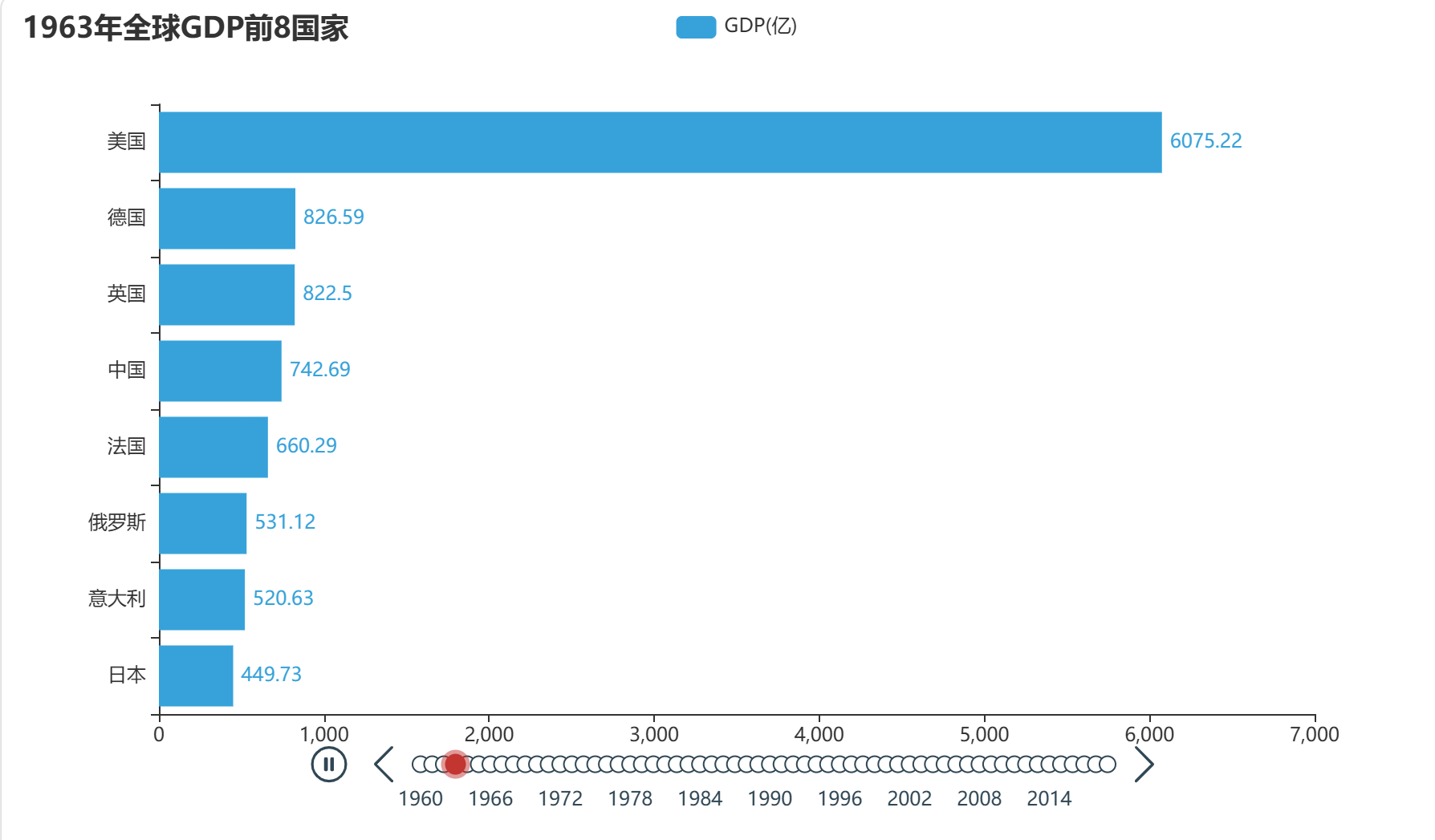
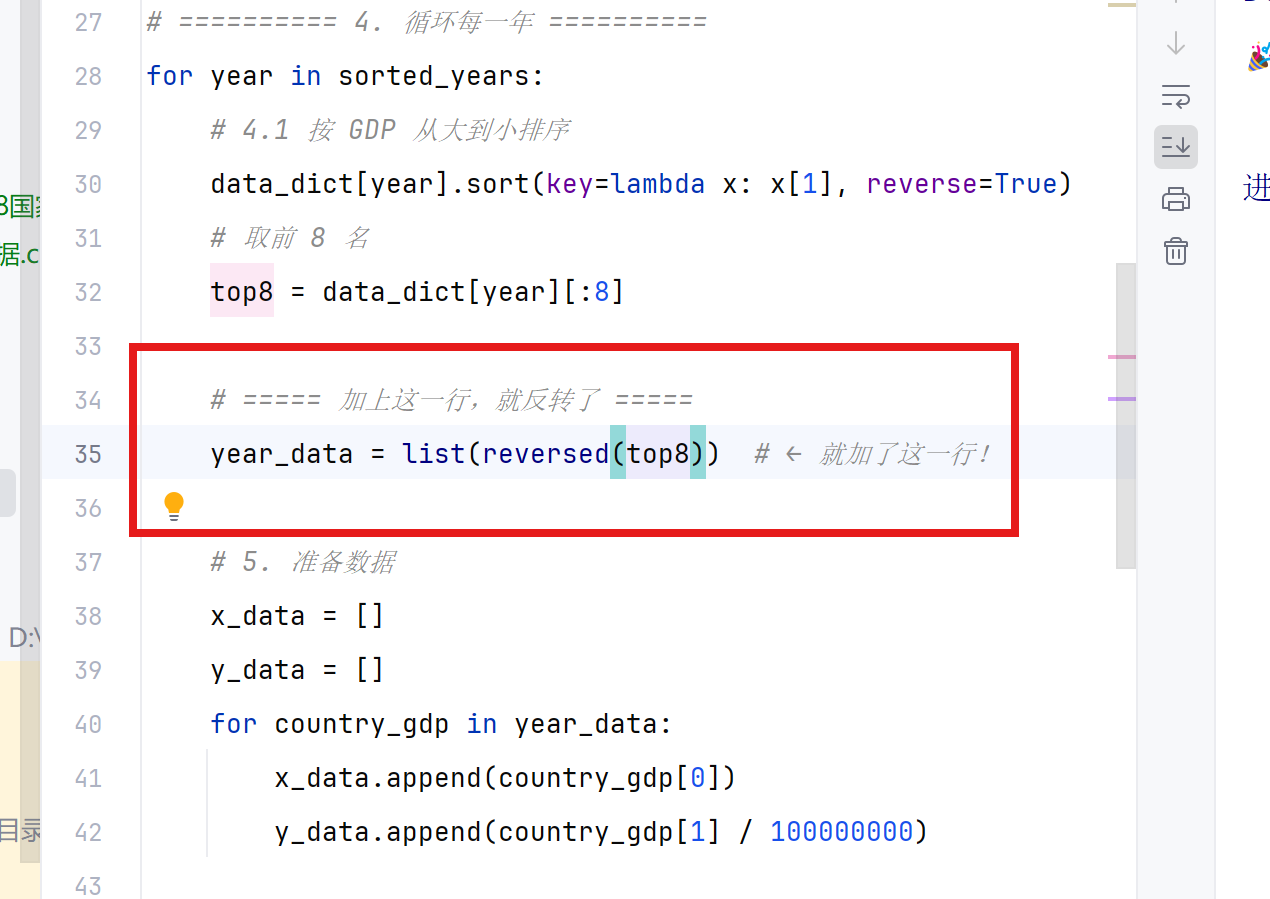
# ===== 关键1:反转数据,让最大的显示在最上面 ===== top8 = list(reversed(top8)) # 准备数据(用反转后的 top8) x_data = [item[0] for item in top8] y_data = [round(item[1] / 100000000, 2) for item in top8]等价于
x_data = []
y_data = []
for country_gdp in year_data:
# country_gdp = ["中国", 2888198000000]
x_data.append(country_gdp[0]) # → "中国"
y_data.append(country_gdp[1] / 100000000) # → 28881.98
# 循环完所有国家,结果一样加上此代码,就可改变。
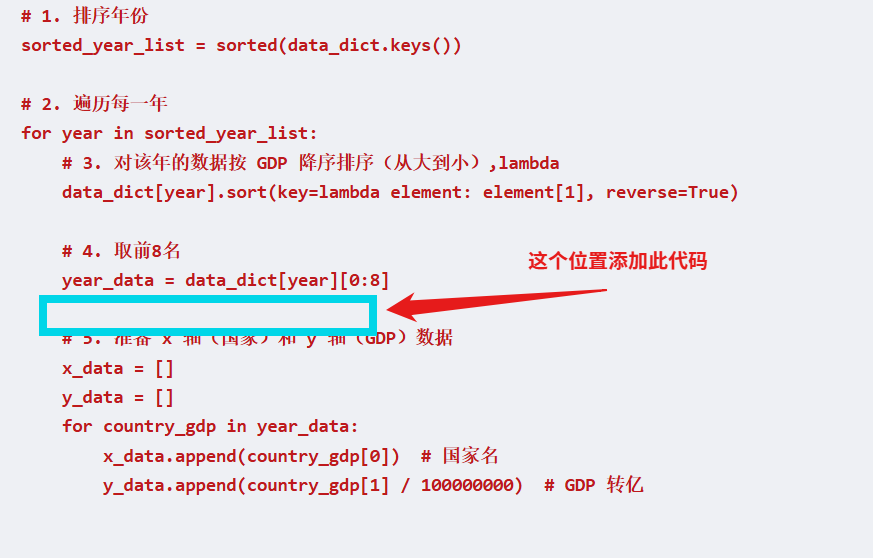
补充:
这段代码是列表推导式,用来从 top8 中提取国家名和 GDP 数据。
第一步:提取国家名
python
x_data = [item[0] for item in top8]
| 部分 | 含义 |
|---|---|
top8 |
一个列表,里面包含 8 个 [国家, GDP] 的小列表 |
for item in top8 |
遍历 top8,每次取出一个小列表赋值给 item |
item[0] |
取小列表的第 1 个元素(国家名) |
[ ... ] |
把所有结果放在一个新列表中 |
执行过程:
python
# 假设 top8 是这样的:
top8 = [
["中国", 2888198000000],
["印度", 1453931000000],
["美国", 1086106000000],
["俄罗斯", 917687000000],
["巴西", 621887000000],
["德国", 563854000000],
["日本", 480920000000],
["西班牙", 373293000000]
]
# 循环过程:
# 第1次:item = ["中国", 2888198000000] → item[0] = "中国"
# 第2次:item = ["印度", 1453931000000] → item[0] = "印度"
# 第3次:item = ["美国", 1086106000000] → item[0] = "美国"
# ...
# 最终结果:
x_data = ["中国", "印度", "美国", "俄罗斯", "巴西", "德国", "日本", "西班牙"]
第二步:提取 GDP 并转换单位
python
y_data = [round(item[1] / 100000000, 2) for item in top8]
| 部分 | 含义 |
|---|---|
item[1] |
取小列表的第 2 个元素(GDP 原始数值,单位是"美元") |
/ 100000000 |
除以 1 亿,把"美元"转成"亿美元" |
round(..., 2) |
四舍五入,保留 2 位小数 |
[ ... ] |
把所有结果放在一个新列表中 |
执行过程:
python
# 假设 top8 是这样的:
top8 = [
["中国", 2888198000000],
["印度", 1453931000000],
...
]
# 循环过程:
# 第1次:item = ["中国", 2888198000000]
# item[1] = 2888198000000
# item[1] / 100000000 = 28881.98
# round(28881.98, 2) = 28881.98
# → y_data 添加 28881.98
# 第2次:item = ["印度", 1453931000000]
# item[1] / 100000000 = 14539.31
# → y_data 添加 14539.31
# 最终结果:
y_data = [28881.98, 14539.31, 10861.06, 9176.87, 6218.87, 5638.54, 4809.20, 3732.93]
注意:
year_data = list(reversed(top8)) |
反转数据顺序 | 数据本身(列表里的元素顺序) |
bar.reversal_axis() |
反转坐标轴 | 图表的 x 轴和 y 轴 |
第一步变成这样:
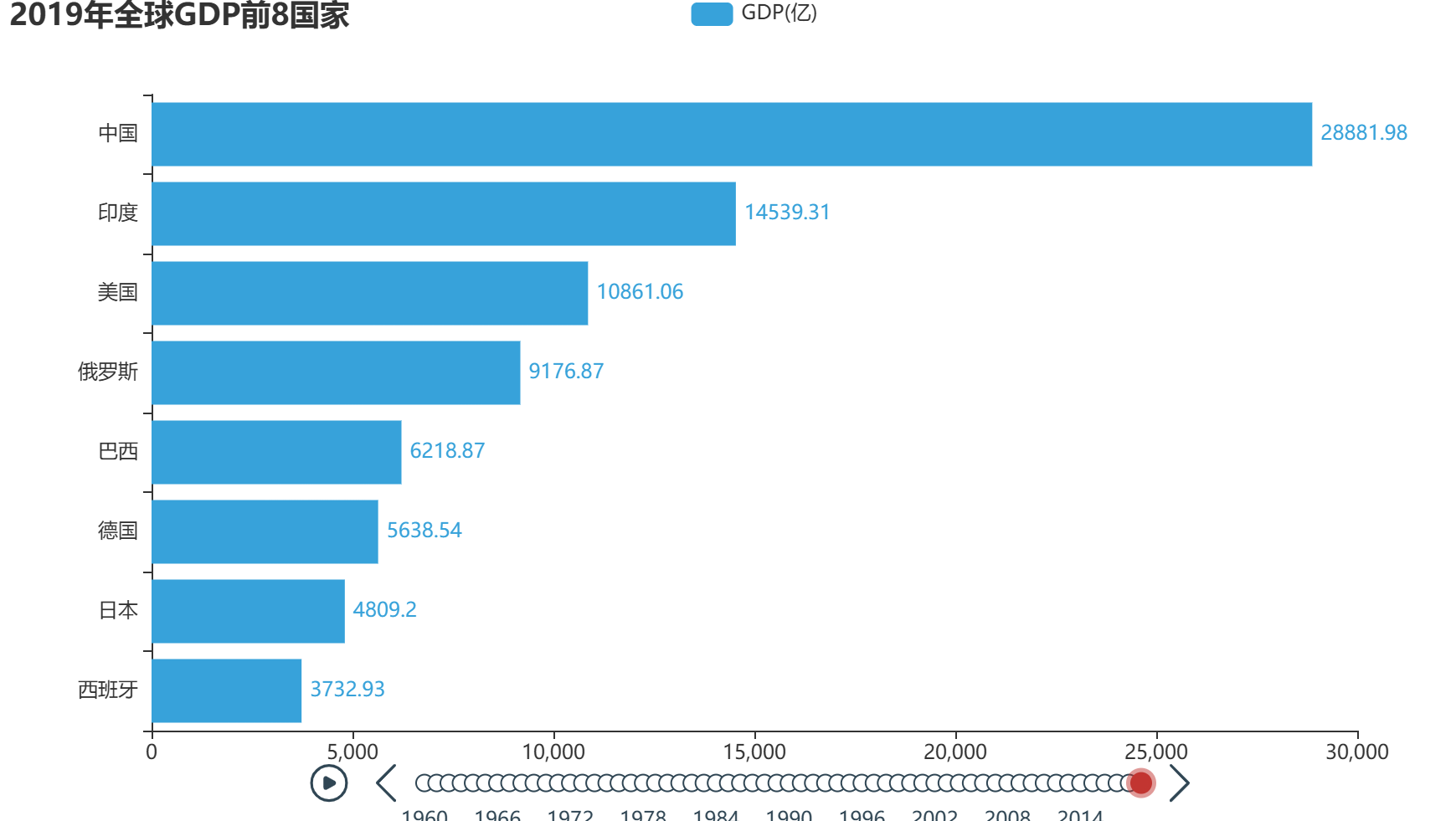
第二步变成这样:
最后总结:
第一步:读取 CSV 数据
↓
第二步:发现数据是按"行"存储的,但我们需要按"年份"取数据 → 用字典整理
↓
第三步:整理成字典 → {年份: [[国家, GDP], [国家, GDP], ...]}
↓
第四步:字典的键(年份)是无序的,需要排序 → sorted(data_dict.keys())
↓
第五步:需要按年份动态播放 → 创建 Timeline 时间线对象
↓
第六步:进入循环,处理每一年
↓
第七步:取出该年的数据后,按 GDP 从大到小排序
↓
第八步:取前 8 名
↓
第九步:【关键1】反转数据 → top8 = list(reversed(top8))
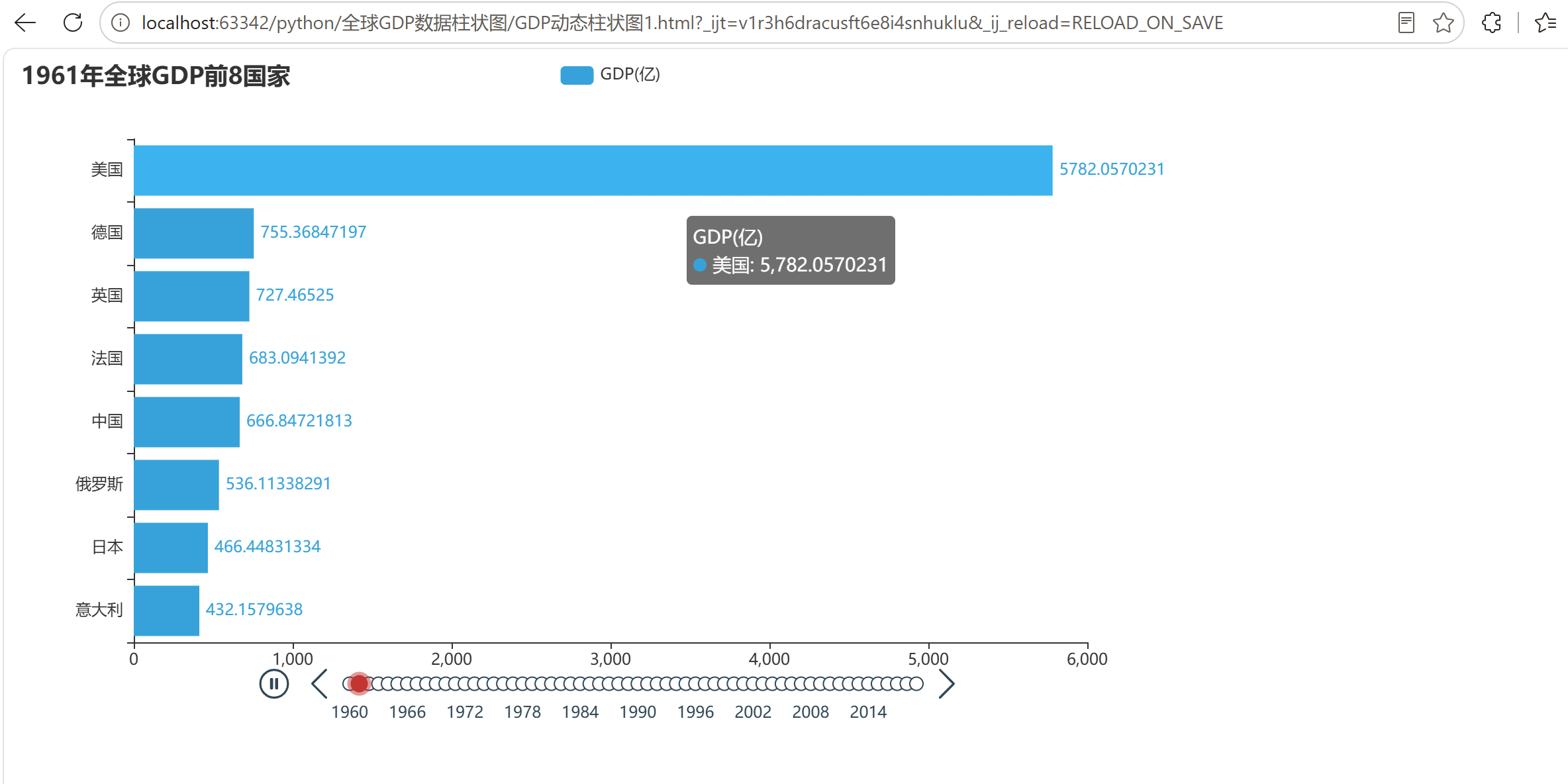
因为排序后是 [中国, 印度, 美国, ...],反转后变成 [..., 美国, 印度, 中国]
反转轴之后,列表最后一个会显示在最上面,所以中国就在最上面了
↓
第十步:准备 x 轴数据(国家名)和 y 轴数据(GDP 转亿)
↓
第十一步:创建 Bar 柱状图对象,添加数据
↓
第十二步:【关键2】反转坐标轴 → bar.reversal_axis()
把纵向柱状图变成横向柱状图
↓
第十三步:设置标题(年份动态变化)
↓
第十四步:添加到时间线
↓
第十五步:所有年份都添加完后,设置时间线自动播放
↓
第十六步:生成 HTML 文件
from pyecharts.charts import Bar, Timeline
from pyecharts import options as opts
from pyecharts.globals import ThemeType
# ========== 1. 读取数据,整理成字典 ==========
f = open("1960-2019全球GDP数据.csv", "r", encoding="utf-8")
data_lines = f.readlines()
f.close()
data_lines.pop(0) # 删除表头
data_dict = {}
for line in data_lines:
parts = line.strip().split(",")
year = int(parts[0])
country = parts[1]
gdp = float(parts[2])
if year not in data_dict:
data_dict[year] = []
data_dict[year].append([country, gdp])
# ========== 2. 排序年份 ==========
sorted_years = sorted(data_dict.keys())
# ========== 3. 创建时间线对象 ==========
timeline = Timeline(init_opts=opts.InitOpts(theme=ThemeType.LIGHT))
# ========== 4. 循环每一年 ==========
for year in sorted_years:
# 4.1 按 GDP 从大到小排序
data_dict[year].sort(key=lambda x: x[1], reverse=True)
# 取前 8 名
top8 = data_dict[year][:8]
# ===== 加上这一行,就反转了 =====
year_data = list(reversed(top8)) # ← 就加了这一行!
# 5. 准备数据
x_data = []
y_data = []
for country_gdp in year_data:
x_data.append(country_gdp[0])
y_data.append(country_gdp[1] / 100000000)
# # ===== 关键:反转数据,让最大的显示在最上面 =====
# # 因为 reversal_axis() 后,列表第一个显示在底部
# top8 = list(reversed(top8)) # ← 直接覆盖 top8,不用新变量
#
# # 准备数据(用反转后的 top8)
# x_data = [item[0] for item in top8]
# y_data = [round(item[1] / 100000000, 2) for item in top8]
bar = Bar()
bar.add_xaxis(x_data)
bar.add_yaxis(
"GDP(亿)",
y_data,
label_opts=opts.LabelOpts(position="right")
)
# 4.5 反转 xy 轴(变成横向)
bar.reversal_axis()
# 4.6 设置标题
bar.set_global_opts(
title_opts=opts.TitleOpts(title=f"{year}年全球GDP前8国家")
)
# 4.7 添加到时间线
timeline.add(bar, str(year))
# ========== 5. 设置自动播放 ==========
timeline.add_schema(
play_interval=1000,
is_timeline_show=True,
is_auto_play=True,
is_loop_play=False
)
# ========== 6. 生成 HTML ==========
timeline.render("GDP动态柱状图1.html")
print("🎉 生成成功!")
更多推荐


 12
12 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)