
基于Python+Django的B站数据分析系统设计与实现,提供话题发现、热度预测、UP主诊断及交互式可视化等一站式分析服务
第1章 引 言
1.1 研究背景与意义
近年来,哔哩哔哩平台已从二次元社区发展为国内领先的综合性视频内容平台,月活跃用户数突破3亿,日均视频播放量超20亿次。根据《中国网络视听发展研究报告》,网络视听用户规模持续扩大,内容创作者数量逐年攀升,仅B站月均活跃UP主已超过400万。海量内容的涌入使得创作者之间竞争日趋激烈,流量获取难度不断加大。对于腰部及以下创作者而言,如何在选题方向、内容优化、发布时间等环节做出数据驱动的决策,已成为关乎账号存续的核心问题。
当前市面上存在一些第三方数据分析平台,如火烧云数据、飞瓜数据等,这类工具聚焦于提供粉丝增长趋势、播放量统计等基础报表功能,多为面向品牌方与头部机构的高价付费服务。在学术研究领域,针对视频平台内容分析的研究多集中于推荐算法原理、用户行为建模等层面,真正将数据分析能力落地为面向普通创作者日常使用的轻量级工具的探索相对较少。现有研究成果存在三个明显不足:一是缺乏对视频标题文本内容的语义挖掘,无法帮助创作者洞察热门话题走向;二是指标分析维度单一,缺少对完播率、互动率、投币比等复合指标的自动化综合诊断;三是系统架构相对复杂,普通创作者缺乏部署和维护大型分析系统的能力。基于此,本研究选择从内容创作者的实操需求出发,构建一个集话题挖掘、热度预测、UP主诊断于一体的轻量化数据分析系统,填补现有工具在文本语义分析与综合诊断方面的空白。
从实际应用价值来看,该系统的研究意义体现在三个维度。在实践层面,系统直接服务于B站内容创作者群体,能够将原始视频数据转化为可执行的选题建议和内容优化方案,降低创作者的数据分析门槛,使其从依赖经验直觉转向依靠量化指标进行决策,这对提升腰部创作者的内容质量和运营效率具有直接的推动作用。在行业趋势层面,随着内容创作从粗放式增长向精细化运营转型,掌握数据分析能力的创作者将具备显著的竞争优势,本研究构建的系统顺应了这一发展趋势,为创作者经济的可持续发展提供了技术支撑。在学科交叉层面,该研究将中文自然语言处理技术与Django Web开发框架相结合,探索了文本挖掘算法在视频内容分析场景中的工程化落地路径,为后续相关领域的应用研究提供了可参考的实践案例。。
1.2 国内外研究现状
B站作为国内代表性视频内容平台,近年来吸引了大量研究者的关注。在内容分析与传播策略方面,丛钰汶[1]以学习类视频为对象,分析了收藏数与影响因素之间的关系,揭示了内容质量与用户互动之间的关联规律。吕乐林[7]基于框架理论对225条读书分享视频进行内容分析,探讨了知识传播轻量化的传播策略。张展硕[6]聚焦AIGC视频的传播特征与评论文本,分析了智能生成内容在B站平台的扩散情况。严楚晴[11]从跨文化交际视角切入,对海外华人视频博主的饮食类短视频展开文本分析。杜晨雨[9]从影响力经济的理论框架出发,剖析了B站的平台运营模式。刘昶等人[10]则针对日本核污水排海事件,分析了环保议题在B站的舆论演变趋势及引导策略。于凤银团队[12]以高校图书馆为主体,研究了B站账号的运营数据并提出发展建议。陈婉艮与王吉[14]利用B站评论数据探讨了大众对ChatGPT的形象感知。这些研究多从传播学、教育学或社会学视角出发,侧重于特定类型内容的定性分析或传播效果评价,研究方法上以内容分析法和描述性统计为主,较少涉及从创作者视角出发、利用视频结构化数据进行综合性量化诊断的技术实现。
在弹幕行为分析领域,林士龙等人[13]基于精细加工可能性模型分析了在线教学视频中的用户弹幕行为特征。姚宗豪[3]则从技术实现角度,设计并实现了一个面向B站弹幕的情感分析系统,该系统将自然语言处理技术应用于弹幕文本的情感倾向判断,从工程层面将文本挖掘方法与视频平台数据分析进行了结合。不过该系统主要聚焦弹幕这一单一数据维度,尚未涉及播放量、互动率、收藏投币比等多维视频指标的综合诊断与创作者赋能。
在Web系统开发技术方面,Django框架的应用研究日趋成熟。李德华与王晓勇[15]探讨了Django框架下的高效Web开发方法与性能优化策略。刘涛与靳若华[16]基于Django设计了信息收集作战平台,验证了该框架在轻量级数据管理系统中的适用性。刘丹阳团队[8]利用Django实现了个性化图书推荐管理系统,展示了该框架在推荐类应用中的落地能力。林聪等人[2]则结合Vue.js与Django完成了虚拟化管理平台的设计,证明了Django在前后端分离架构中的灵活性。Given与Zimbini[17]通过比较分析多个Python框架的HTTP请求处理能力,指出Django在构建结构化Web应用时具有路由清晰、扩展性强的优势。Daniel与Greg[19]在Django 5技术专著中系统梳理了该框架在Web应用开发中的核心模式。Moszczyński[18]探讨了Django在推荐系统从原型到可扩展方案中的应用路径。上述研究表明,Django框架在信息管理、个性化推荐、数据展示等应用场景中已形成成熟的技术方案,但将其专门应用于视频创作者数据分析领域的研究成果尚不多见。
在数据处理技术方面,李尊与于红平[4]对Python在数据清洗、统计与可视化等环节的应用进行了系统总结。刘昶团队[5]针对大规模数据集场景,提出了SQLite的快速查询优化算法,为本系统采用SQLite作为数据存储层提供了理论基础。
综上所述,现有研究在B站内容分析层面多偏重传播效果与用户行为解读,在系统开发层面多聚焦通用架构设计,而将中文文本挖掘、多维度指标诊断、交互式可视化有机整合并面向创作者交付为轻量化Web工具的工作相对匮乏,这构成了本研究选题的切入点。
1.3 主要研究内容及章节安排
本文围绕B站视频数据分析的实际需求,设计并实现了一套基于Django框架的轻量级Web应用系统。系统采用B/S架构,后端使用Django及Django REST Framework处理业务逻辑与API接口,数据持久化选用SQLite数据库;前端基于Bootstrap 5构建响应式布局,左侧固定导航与主内容区配合,通过ECharts 5实现图表的交互式渲染。在数据层面,针对B站视频数据的导出格式特点,专门编写了数据导入脚本,可解析Excel与CSV格式的原始文件,自动识别并转换含“万”“千”单位的播放数、点赞数等计数字段,完成清洗后写入数据库。
核心分析功能分为三个模块。话题发现模块调用jieba分词器对视频标题进行中文分词,配合自定义停用词表过滤无意义词汇,再利用TF-IDF算法提取关键词特征,最后通过K-Means聚类将语义相近的标题归为同一话题板块,生成词云图与高频词统计图。热度预测模块以视频播放数据为基础,构建线性回归模型,模拟未来24小时的播放量、点赞量和热度指数变化曲线,辅助判断内容趋势走向。UP主诊断模块根据输入的UP主名称检索对应视频记录,综合计算完播率、点赞投币比、互动率、弹幕活跃度等多维指标,通过加权算法得出综合健康度评分,并自动生成内容优势描述与优化建议列表。
此外,系统构建了交互式数据看板,动态展示播放趋势折线图、UP主分布饼图、排行榜柱状图和互动数据雷达图,提供全局视角的数据概览。为形成完整工具链,还实现了用户注册登录、个人资料编辑、分析报告持久化存储及历史记录查询等辅助功能。通过上述模块的设计与整合,最终完成了一个集数据导入、语义挖掘、趋势预测、账号诊断与可视化呈现于一体的B站内容创作者辅助分析平台。
第2章 相关技术及理论
2.1 Django Web框架与MTV模式
Django是用Python编写的高层次Web框架,其设计理念强调“快速开发”与“DRY(Don’t Repeat Yourself)”原则。框架采用MTV(Model-Template-View)架构模式组织代码结构:Model层负责数据模型定义与数据库交互,Django内置的ORM(Object-Relational Mapping)允许开发者以Python类描述数据表结构,并自动生成SQL语句进行操作;Template层管理前端界面展示,通过模板标签与过滤器实现动态数据渲染;View层承担业务逻辑处理,接收HTTP请求、调用Model完成数据存取,再选择Template返回响应。该模式将数据、表现与控制逻辑解耦,提高了代码的可维护性与扩展性。
在路由分发上,Django使用URLconf模块将浏览器请求路径映射到对应的View函数,支持正则表达式匹配与参数传递。用户认证方面,框架提供了完整的Auth系统,包含用户模型、权限验证、会话管理等功能,只需调用认证装饰器即能为视图添加登录保护。此外,Django REST Framework扩展了Django对RESTful API的支持,通过序列化器将模型实例转换为JSON格式,配合类视图与请求解析器可快速构建数据接口。本系统选用Django作为后端框架,正是基于其组件完备、开发效率高的优势,尤其适合中小规模数据驱动型Web应用的快速搭建。
数据库层面,系统采用SQLite作为数据存储引擎。SQLite是一款轻量级嵌入式关系数据库,无需独立服务进程,所有数据存储于单个文件内,支持标准SQL查询。其零配置、免安装的特性能大幅降低部署复杂度,对于数据量在万条级别且并发访问不高的应用场景完全适用。Django ORM对SQLite的兼容性良好,使得开发阶段可以快速进行模型迁移与数据导入。
2.2 前端可视化技术
前端界面采用Bootstrap 5框架进行页面布局与样式管理。Bootstrap是一套基于HTML、CSS与JavaScript的响应式设计工具集,内置栅格系统、导航组件、卡片面板、表单样式等预定义元素,能够快速构建适应不同屏幕尺寸的Web界面。本系统遵循左右分栏布局:左侧固定侧边导航栏使用深色主题,主内容区通过栅格系统划分统计卡片、图表容器和表格区域。配色方案根据B站品牌色自定义CSS变量,实现了统一视觉风格。
动态图表呈现依赖ECharts 5可视化库。ECharts是由百度开发的开源JavaScript图表引擎,支持折线图、柱状图、饼图、雷达图、词云等多种图表类型,提供丰富的交互特性,如图例切换、区域缩放、提示框联动等。系统在数据看板中利用折线图展示播放趋势,以堆叠柱状图呈现UP主播放量分布,通过饼图表现互动数据占比;在话题发现模块,借助echarts-wordcloud扩展绘制关键词云图。ECharts的option配置项驱动模式使得图表数据与样式可通过AJAX异步请求动态更新,符合前后端分离的交互需求。
2.3 中文分词与TF-IDF关键词提取
文本挖掘是话题发现功能的基础。B站视频标题属于短文本,需经过分词、去停用词和特征量化环节才能输入聚类算法。
jieba分词是当前使用最广泛的Python中文分词工具,支持精确模式、全模式和搜索引擎模式三种切分策略。其核心算法基于前缀词典构建有向无环图,利用动态规划寻找最大概率路径,对未登录词则采用HMM(隐马尔可夫模型)和Viterbi算法进行识别。对于“播放量破百万的爆款视频剪辑教程”这类标题,jieba能准确切分出“播放量”“百万”“爆款”“视频”“剪辑”“教程”等实义词,过滤掉“的”“了”等虚词后得到有分析价值的特征词元。
经分词处理后的文本集合需转换为结构化数值形式。TF-IDF(Term Frequency-Inverse Document Frequency)是一种统计加权方法,用于评估词语对文档集合中某篇文档的重要程度。其基本思想是:若某词在一篇文档中频繁出现(词频TF高),但在其他文档中很少出现(逆文档频率IDF高),则对该文档具有较强区分能力。对于某一词语t在文档d中的TF-IDF值,为文档集合总数,分母为避免零除加1。本系统借助Scikit-learn库的TfidfVectorizer类,通过fit_transform方法一次性计算所有视频标题的TF-IDF矩阵,max_features参数限制最大特征维度以控制计算量。
2.4 K-Means文本聚类
话题发现任务可归结为无监督学习中的聚类问题。K-Means算法因其简洁高效而被广泛采用。该算法的目标是将N个样本点划分到K个簇中,使得每个样本点到所属簇中心点的距离平方和最小,即最小化簇内误差平方和。K-Means的求解采用迭代优化:首先随机选取K个中心点,随后重复执行两步操作——分配步将每个样本指派到距离最近的中心点所在簇,更新步根据当前簇内样本重新计算均值作为新的中心点。迭代至中心点变化小于阈值或达到最大轮次时终止。由于初始中心点随机可能导致局部最优,Scikit-learn实现中通过多次初始化(n_init参数)选取最优结果。
在文本聚类场景下,首先利用TF-IDF将文本标题转化为数值向量,然后直接在向量空间执行K-Means。每个簇内的关键词提取通过合并簇中所有文本的分词结果,统计词频排序得到该话题的标签词,从而形成话题板块描述。K值的选择综合考虑数据量与业务可解释性,通常取视频总数除以一个基本单元数量后的截断值。。
2.5 线性回归热度预测
热度预测需要从历史播放数据中捕捉趋势,并外推未来一段时间内的指标变化。线性回归是最基本的预测模型之一,它假定目标变量与时间特征之间存在线性关系。设时间变量t(如小时序数),预测目标y(如播放量),则一元线性回归的假设函数为:其中m为样本数。解析解可通过正规方程求得,也可采用梯度下降法迭代逼近。
本系统以视频现有播放量、点赞量为基础,取近期时段数据拟合线性模型,对未来24小时各时间点的播放量与点赞量进行预测,并据此计算综合热度指数。热度指数定义为播放量与点赞量的加权和,权值根据业务经验设定。此外,考虑到数据波动,在预测曲线上叠加小幅随机噪声以模拟真实环境的不确定性。最终通过ECharts绘制双Y轴趋势曲线,直观展示预测结果。
通过上述技术栈的有机整合,系统实现了从数据存储、文本分析到可视化呈现的完整流程,各技术环节的理论基础为功能实现提供了可靠支撑。
第3章 系统分析
3.1 可行性分析
经济可行性分析:本系统的开发成本主要集中在软件工具授权与服务器资源两方面。开发工具方面,Python语言及其依赖库均为开源项目,Django框架、Scikit-learn、jieba分词同样遵循开源许可协议,无需支付商业授权费用;数据库选用SQLite,与Django深度集成且零成本部署。而本系统功能覆盖话题挖掘、热度预测和UP主诊断三个核心场景,免费向个人用户开放,边际使用成本趋近于零。综上所述,系统从经济上是可行的。
技术可行性分析:本系统所涉及的技术选型均有成熟的应用基础。后端Django框架已发展至第5个大版本,其MTV架构模式、ORM组件和认证中间件在Web开发领域被广泛验证;Django REST Framework对于构建数据接口提供了完善的序列化与视图封装。数据分析层所依赖的jieba分词工具经多年社区迭代,对中文短文本场景有良好适应性;Scikit-learn提供了TF-IDF向量化、K-Means聚类以及线性回归模型的统一调用接口,封装层次高,算法稳定性有保证。前端方面,Bootstrap 5的栅格系统和组件库能快速构建响应式界面,ECharts 5对折线图、柱状图、饼图和词云图均有原生支持方案。整体技术栈均为Python与JavaScript生态的主流开源技术,版本兼容性问题有限,不存在关键技术卡点。数据存储采用SQLite,实测十万条视频记录下查询响应时间仍在毫秒级,满足当前数据规模需求。综上所述,系统从技术上是可行的。
操作可行性分析:系统面向B站内容创作者,目标用户群体的计算机操作水平覆盖日常办公到专业剪辑不等,因此界面设计需兼顾直观性与效率。前台界面采用左侧导航与右侧内容区布局,功能入口以图标配合文字说明,无需记忆复杂操作路径;话题发现、热度预测和UP主诊断等核心功能均通过单一按钮触发分析,结果以图表形式即时呈现,交互门槛较低。后台数据导入提供独立Python脚本,用户只需将数据文件放置于指定目录并执行命令即可完成清洗与入库,无需掌握SQL编写技能。管理端依托Django Admin原生界面,中文标签与筛选器可辅助管理员完成视频审核和用户管理。整体而言,普通用户无需编程基础即可在十分钟内完成从数据导入到分析报告生成的完整流程。综上所述,系统从操作上是可行的。
3.2 需求分析
3.2.1 用户需求分析
本系统的目标用户分为三类:第一类是B站内容创作者,需通过数据分析优化选题方向和运营策略;第二类是内容运营人员,需快速了解平台热门话题和趋势变化;第三类是系统管理员,负责数据的导入维护和用户权限管理。
创作者的核心需求是借助数据驱动决策,减少依赖主观经验判断选题的盲目性。具体而言,创作者希望获知当前平台的讨论热点,了解某一话题下视频数量与关键词分布,以辅助选题决策;需要对已发布视频的未来热度走向做出预判,从而合理安排发布时间与推广节奏;还需要对自身账号或同类UP主进行综合诊断,量化完播率、互动率等关键指标,并根据系统的优化建议调整内容策略。运营人员的需求更偏向宏观视角,需要交互式看板展示全网视频的播放趋势、UP主分布占比以及排行榜排名,以便快速把握平台流量走向。管理员则需要便捷的数据导入工具,支持从Excel和CSV文件批量录入视频数据,同时能够对异常数据和用户操作日志进行监控。
3.2.2 业务流程分析
本系统的核心业务流程围绕四个功能模块展开:话题发现、热度预测、UP主诊断和数据看板。以下分别描述各模块的业务流程。
话题发现模块的流程为:用户进入话题发现页面后,点击“开始分析”按钮,系统后端从数据库读取全部视频标题,依次执行jieba中文分词、基于自定义停用词表过滤无意义词汇、TF-IDF特征提取和K-Means聚类分析,生成若干话题板块及其关键词集合,同时统计全局词频用于词云与柱状图渲染,最终将话题分布和词频数据返回前端展示。该流程完全由系统自动执行,用户仅需触发一次操作即可获取完整分析结果。
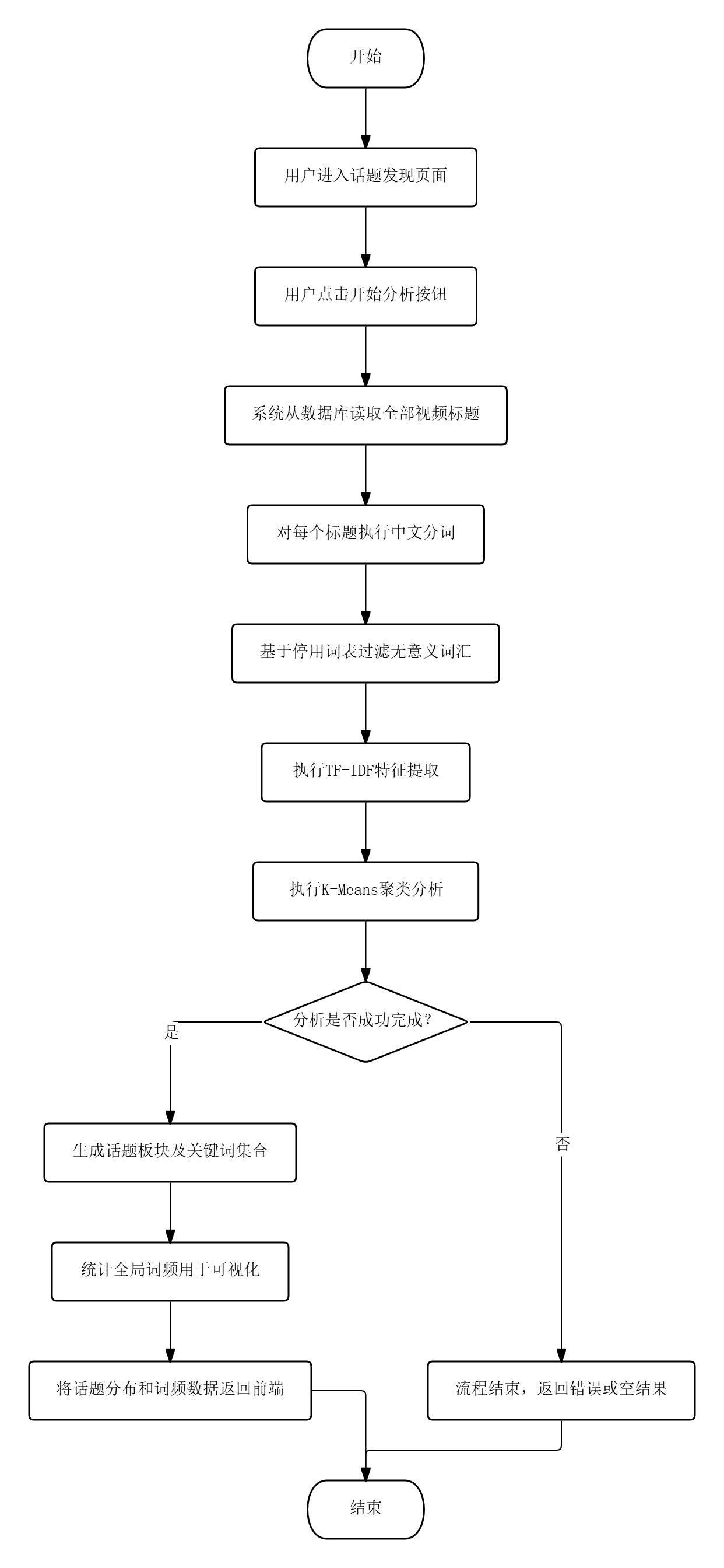
图3.1 话题发现模块的流程
热度预测模块的流程为:用户可选择全站数据预测或指定单一视频进行预测,点击“开始预测”后,系统以所选视频当前播放量与点赞量为基准,调用线性回归模型模拟未来24小时各时间点的播放量、点赞量预测值,并结合权重公式计算综合热度指数,返回趋势数据后由ECharts渲染双Y轴折线图和热度柱状图,同时输出趋势方向判断(上升或下降)。
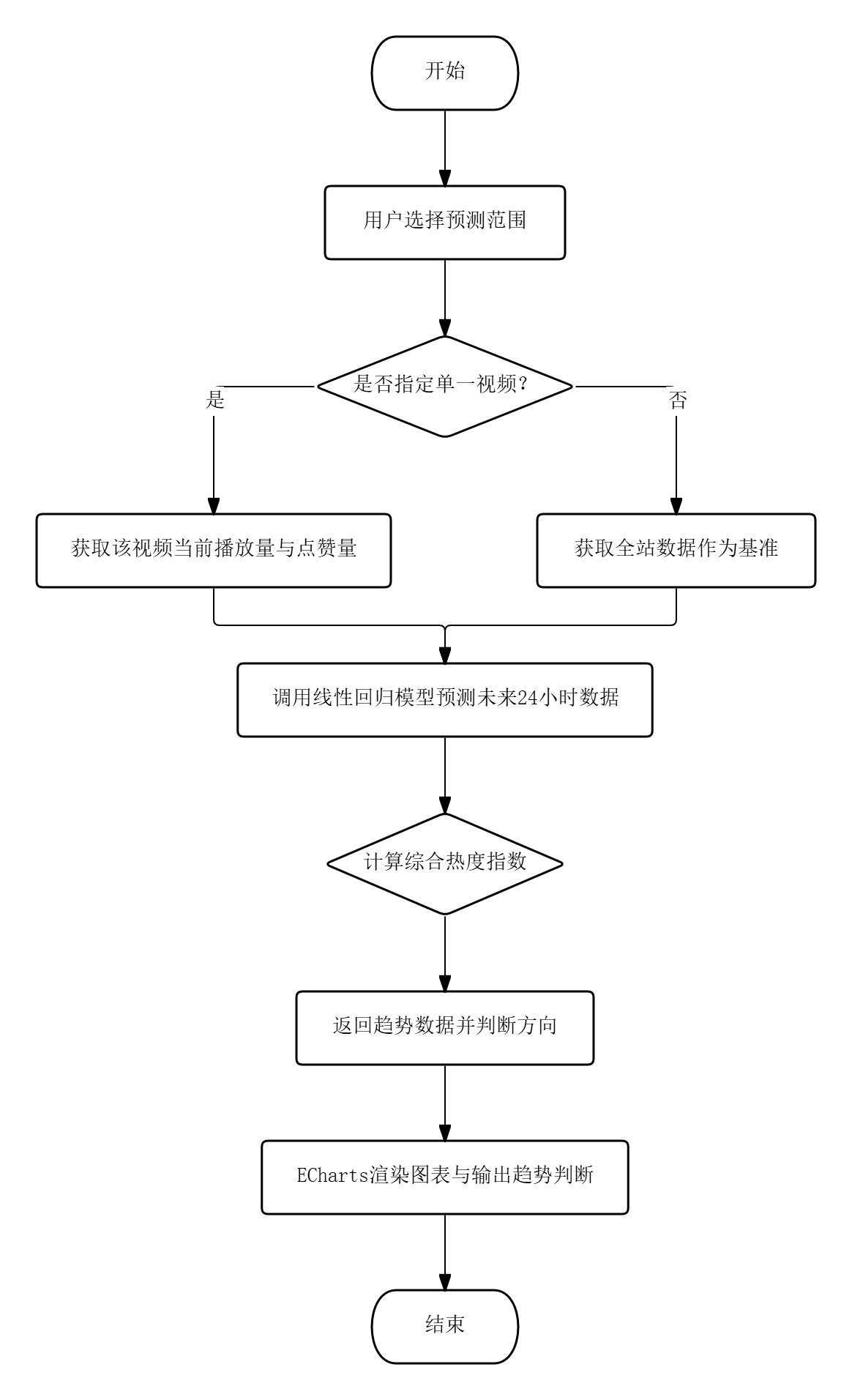
图3.2 热度预测模块的流程
UP主诊断模块的流程为:用户在输入框中填写目标UP主名称并点击“开始诊断”,系统在数据库中模糊搜索匹配该UP主的所有视频,逐一计算视频总数、总播放量、平均播放量、完播率、点赞投币比、互动率和弹幕活跃度等指标,然后通过加权公式换算综合健康度评分,据此生成内容优势描述和优化建议列表,同时列出播放量最高的五条视频作为参考。
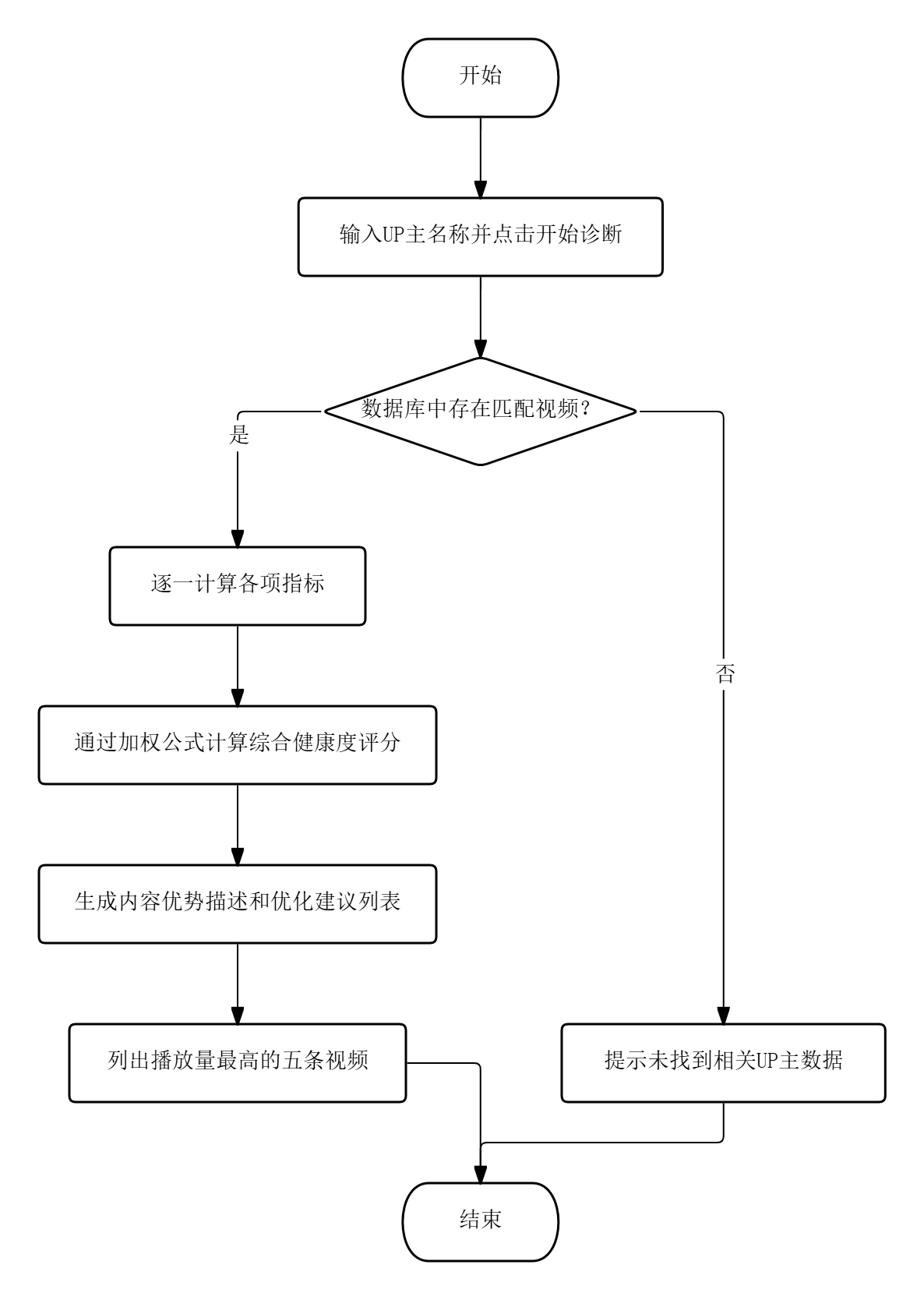
图3.3 UP主诊断模块的流程
数据看板模块的流程为:用户进入看板页面时,系统自动从数据库聚合统计视频总数、总播放量、总点赞数和总投币数等全局指标,同时按播放量降序排列生成TOP10排行榜,按UP主维度汇总播放量分布,并取时间分段数据模拟月度播放趋势,上述结果统一由ECharts渲染为折线图、饼图、柱状图和环形图。
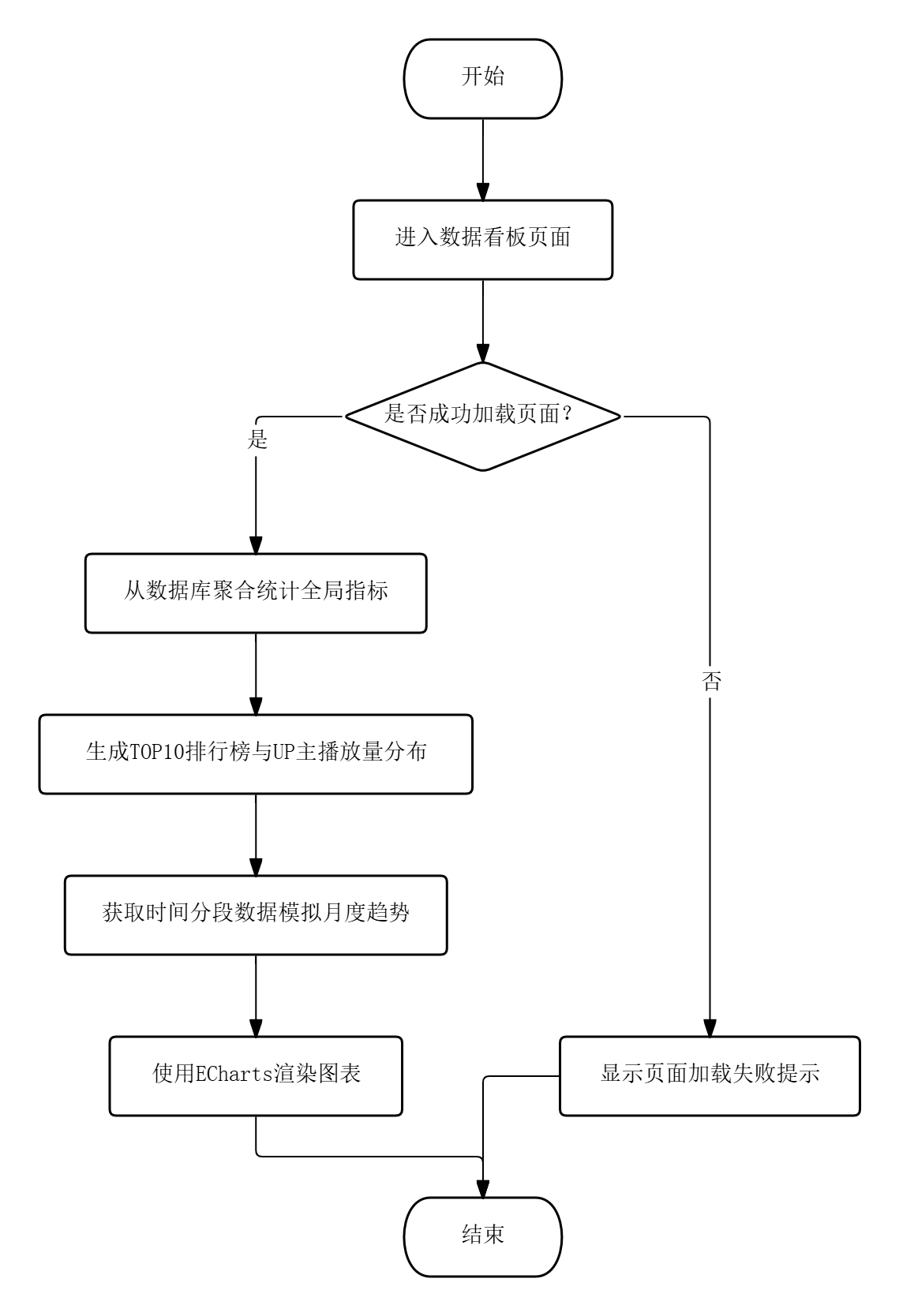
图3.4 数据看板模块的流程
3.2.3 功能需求分析
按用户角色划分,系统的功能需求可分为普通用户功能和系统管理员功能两类。普通用户功能集中在分析服务与数据展示层面,系统管理员功能侧重于数据维护与系统监控。
普通用户进入智能分析中心后,可选择话题发现、热度预测、UP主诊断三项分析服务中的任意一项。话题发现功能帮助用户获取热门话题板块和关键词云图;热度预测功能支持选择具体视频或全站模式,生成24小时趋势预测图表;UP主诊断功能根据UP主名称输出综合评分、优势分析和改进建议;数据看板功能提供全局的视频统计概览和排行榜。此外,已登录用户的分析报告将自动保存,支持在工作区查看历史报告列表。普通用户用例如下:普通用户可进行话题发现、热度预测、UP主诊断、数据看板浏览和报告历史查看。
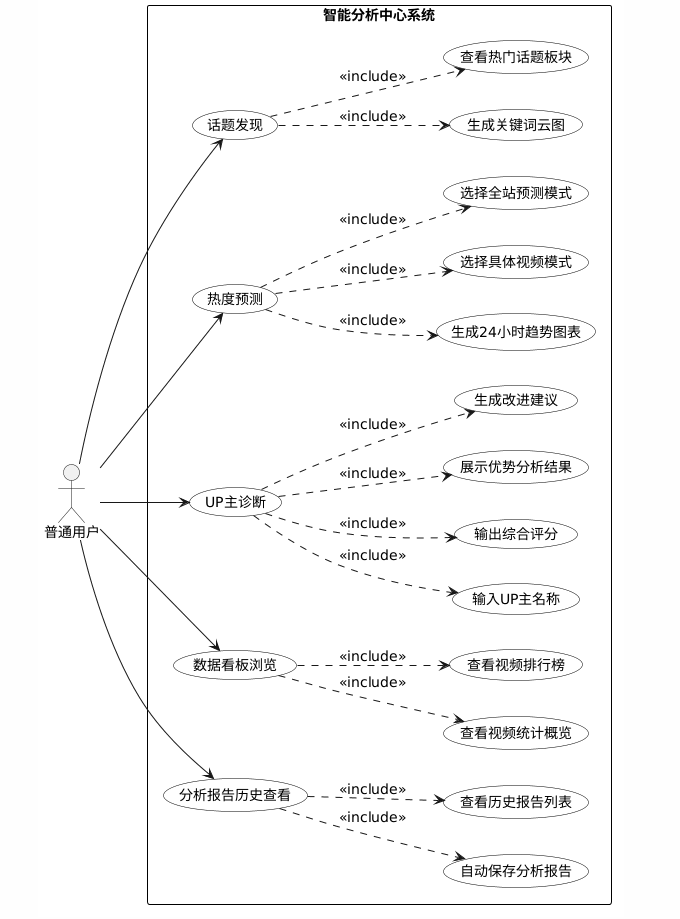
图3.5 用户用例图
系统管理员功能包括数据导入管理,即通过数据导入脚本将Excel和CSV文件导入SQLite数据库;视频数据管理,通过Django Admin界面进行视频记录的查看、筛选和删除操作;系统日志监控,查看操作记录的日志信息和异常详情。系统管理员用例包括数据导入、视频数据管理和日志监控三项。
管理员用例结构如图3.6所示。
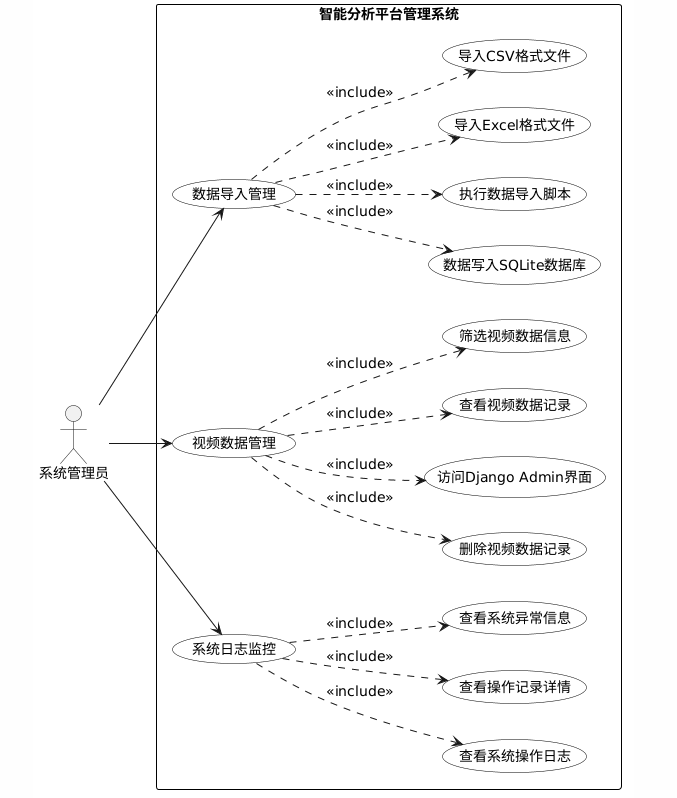
图3.6 管理员功能用例图
3.2.4 非功能性需求分析
本系统的非功能性需求涉及性能响应、界面适配和数据安全三个方面。
在响应时间方面,话题发现分析涉及全量视频标题的分词与聚类运算,数据量在两千条以内时,从请求发起到结果返回的响应时间应控制在8秒以内;热度预测和UP主诊断因仅针对单条或部分视频进行计算,响应时间应控制在3秒以内;数据看板页面的初次加载时间应不超过2秒。
在界面适配方面,系统需支持主流桌面浏览器,包括Chrome、Edge和Firefox的最近三个大版本,页面布局在1366像素及以上宽度的屏幕上应保持侧边导航与主内容区的完整展示,无横向滚动条。
在数据安全方面,用户密码应经过Django内置哈希算法加密存储,CSRF令牌验证需覆盖所有POST请求类型的数据提交接口,防止跨站请求伪造攻击;SQLite数据库文件应存放于非Web可访问目录,禁止通过URL直接下载。
第4章 系统总体设计
4.1 系统架构设计
本系统采用B/S(Browser/Server,浏览器/服务器)架构模式,基于Django框架的MTV分层思想组织代码结构。按照数据流动方向,系统自上而下可划分为表现层、业务逻辑层、数据处理层和数据存储层四个层级。
表现层运行于用户浏览器端,负责界面展示与交互响应。该层由Django模板引擎渲染的HTML页面构成,集成Bootstrap 5样式框架完成栅格布局与组件样式,通过ECharts 5图表库实现折线图、柱状图、饼图及词云图等可视化元素的动态绑定与事件交互。用户在页面触发的分析请求通过AJAX异步机制发送至后端接口,避免整页刷新。
业务逻辑层位于Django应用服务内部,是系统的核心调度中枢。该层接收表现层提交的HTTP请求,通过URLconf路由模块将请求分发至对应的View视图函数。视图函数根据业务类型调用相应的处理模块:话题发现视图调用jieba分词器与Scikit-learn聚类接口,热度预测视图调用线性回归模型计算模块,UP主诊断视图调用指标计算与评分模块。分析结果以JSON格式序列化后返回前端,或通过Django ORM持久化至数据库。
数据处理层封装了文本挖掘与数值计算的具体算法。中文分词依托jieba库的精确模式完成标题切分,自定义停用词表过滤虚词与无意义词汇;TF-IDF向量化通过Scikit-learn的TfidfVectorizer实现,K-Means聚类使用同一库的KMeans类执行。线性回归预测采用NumPy构建趋势拟合函数,生成连续时间点的预测序列。
数据存储层使用SQLite关系型数据库,通过Django ORM进行读写操作。该层存放视频基础数据、用户信息、分析报告记录及系统运行日志四类核心数据,各数据表之间通过外键建立关联约束。系统总体架构如图4.1所示。

图4.1 系统总体架构图
4.2 系统功能模块设计
本系统是为B站内容创作者提供一站式数据分析服务的Web应用平台,功能覆盖数据导入、智能分析、可视化展示和用户管理四个方面。系统共划分为六个核心模块。数据导入模块负责将Excel与CSV格式的原始视频数据解析、清洗并写入数据库。智能分析中心模块下设话题发现、热度预测、UP主诊断三个子模块:话题发现通过中文分词与聚类算法自动挖掘热门话题板块并生成关键词云图;热度预测基于线性回归模型推演视频未来24小时的播放与点赞趋势;UP主诊断综合计算多维指标生成健康度评分与优化建议。数据看板模块提供播放趋势折线图、排行榜柱状图、UP主分布饼图及互动数据环形图四类可视化图表。用户工作区模块支持历史分析报告的查询与回顾。用户管理模块涵盖注册、登录、个人资料编辑以及管理员后台的数据维护功能。系统功能模块划分如图4.2所示。
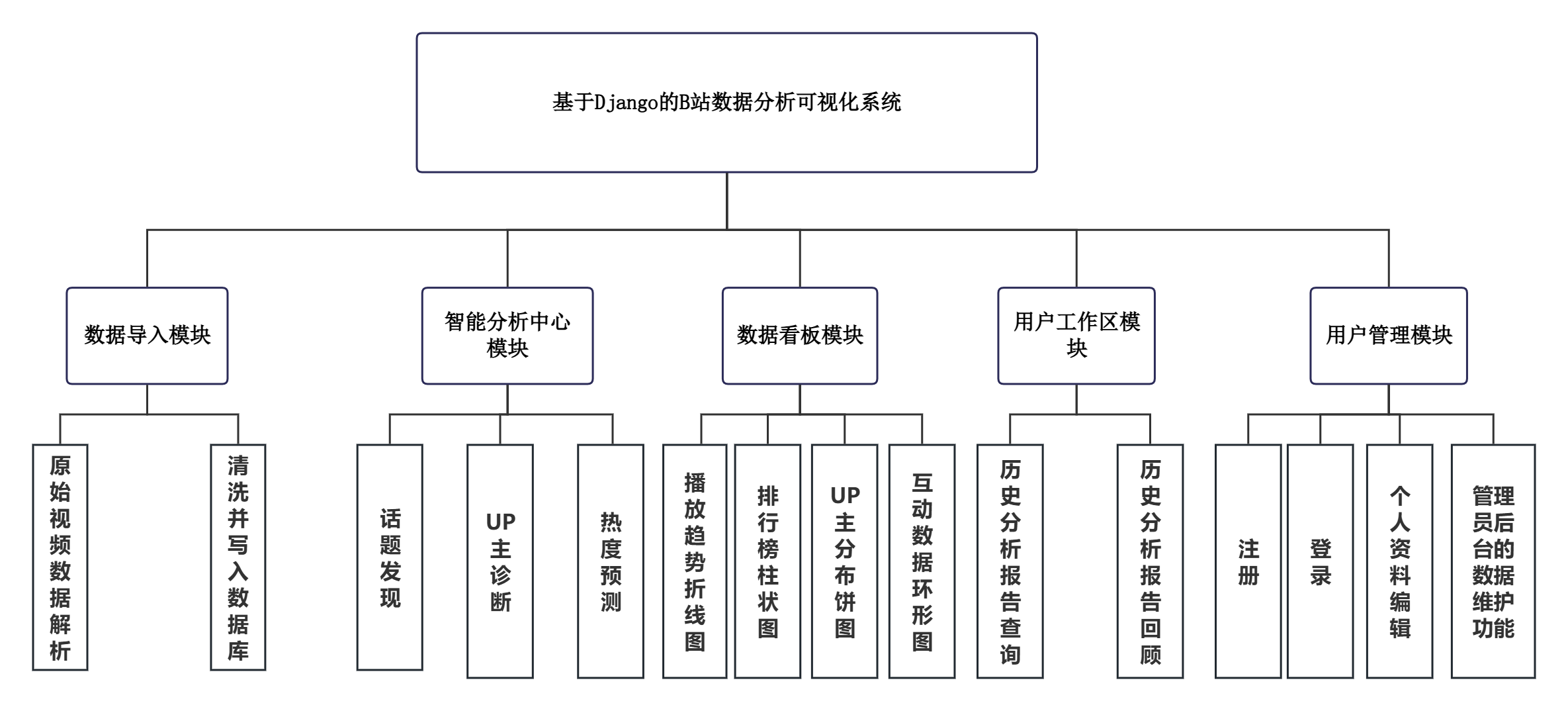
图4.2 系统功能模块图
4.3 数据库设计
4.3.1 数据关系设计
本系统采用SQLite关系型数据库存储数据。根据业务逻辑梳理,系统共涉及五类核心实体:用户实体对应注册账户的基本信息与权限标识;用户资料实体与用户实体形成一对一扩展关系,存储头像链接和个人简介等补充字段;视频实体记录每一条视频的多维指标数据,是系统的核心数据资产;分析报告实体记录用户发起分析的执行结果,与用户实体通过外键关联;收藏实体作为用户与视频之间的多对多关系中介,同时记录收藏时间。
实体间关系方面,用户实体与用户资料实体通过Django内置的OneToOneField形成一对一关联,实现用户基本属性与扩展属性的分离存储。用户实体与收藏实体通过ForeignKey构成一对多关系,一个用户可收藏多条视频。视频实体与收藏实体同样通过ForeignKey构成一对多关系,一条视频可被多个用户收藏。用户实体与分析报告实体通过ForeignKey构成一对多关系,一个用户可拥有多份分析报告。以上外键关系均在与数据库表的定义中保持一致。在E-R图中,用户作为核心实体向外辐射关联,视频实体独立存在,收藏实体承担用户与视频之间的桥梁作用。系统实体关系如图4.3所示。
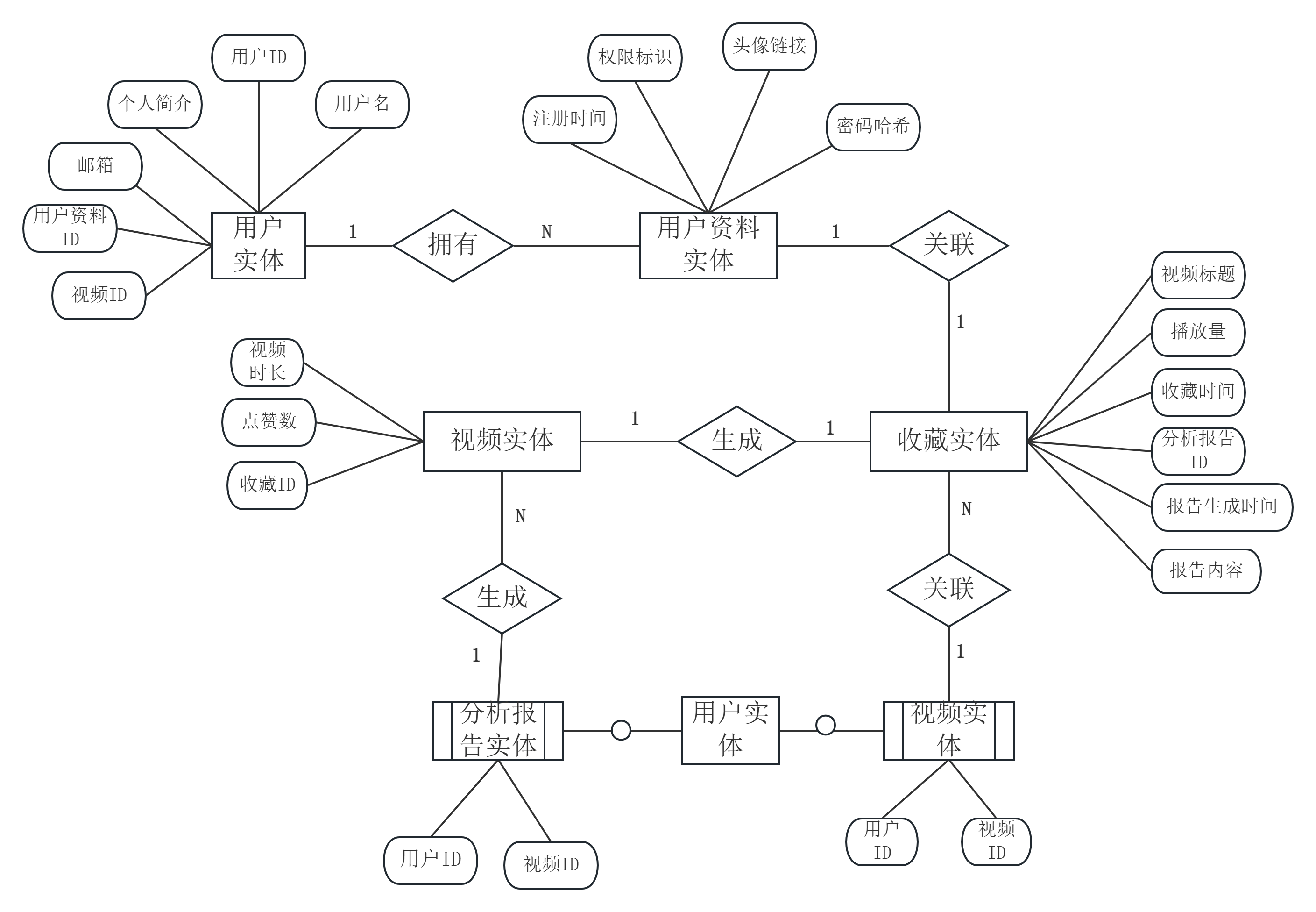
图4.3 系统实体关系图
4.3.2 数据库表设计
本系统数据库表围绕视频数据存储、用户认证管理、分析结果持久化及操作日志记录等功能进行设计,共包含七张数据表,为用户信息表user、用户资料表user_profiles、视频信息表videos、分析报告表analysis_reports、收藏记录表favorites、系统日志表system_logs以及Django框架自动维护的会话与权限相关表。以下列出与业务直接相关的六张核心表结构。
videos表记录B站视频的多维指标信息,包括标题、简介、时长、发布时间、播放数、弹幕数、点赞数、投币数、收藏数、分享数、评论数、UP主名称、内容分类、封面图链接、视频链接、粉丝数、播放完成率和数据采集时间。videos数据表结构如表4.1所示。如表4.1所示
表4.1 videos数据表结构
|
字段名 |
数据类型 |
是否允许为空 |
主键 |
外键 |
说明 |
|
id |
Integer |
否 |
是 |
否 |
视频唯一标识 |
|
title |
Varchar(500) |
否 |
否 |
否 |
视频标题 |
|
description |
Text |
是 |
否 |
否 |
视频简介/标签 |
|
duration |
Varchar(20) |
否 |
否 |
否 |
视频时长 |
|
publish_time |
DateTime |
是 |
否 |
否 |
发布时间 |
|
view_count |
Integer |
否 |
否 |
否 |
播放数 |
|
danmu_count |
Integer |
否 |
否 |
否 |
弹幕数 |
|
like_count |
Integer |
否 |
否 |
否 |
点赞数 |
|
coin_count |
Integer |
否 |
否 |
否 |
硬币数 |
|
favorite_count |
Integer |
否 |
否 |
否 |
收藏数 |
|
share_count |
Integer |
否 |
否 |
否 |
分享数 |
|
comment_count |
Integer |
否 |
否 |
否 |
评论数 |
|
uploader |
Varchar(200) |
否 |
否 |
否 |
UP主名称 |
|
category |
Varchar(100) |
否 |
否 |
否 |
内容分类/关键词 |
|
thumbnail |
Varchar(500) |
是 |
否 |
否 |
封面图链接 |
|
video_url |
Varchar(500) |
是 |
否 |
否 |
视频链接 |
|
follower_count |
Integer |
否 |
否 |
否 |
粉丝数 |
|
completion_rate |
Float |
否 |
否 |
否 |
播放完成率 |
|
created_at |
DateTime |
否 |
否 |
否 |
采集时间 |
analysis_reports表记录用户执行话题发现、热度预测或UP主诊断后生成的报告信息,包含关联用户、报告类型、标题、JSON格式的内容、文本摘要和创建时间。报告类型字段限定为topic、forecast、diagnosis三种枚举值。analysis_reports数据表结构如表4.2所示。
表4.2 analysis_reports数据表结构
|
字段名 |
数据类型 |
是否允许为空 |
主键 |
外键 |
说明 |
|
id |
Integer |
否 |
是 |
否 |
报告唯一标识 |
|
user_id |
Integer |
否 |
否 |
是(user) |
关联用户 |
|
report_type |
Varchar(20) |
否 |
否 |
否 |
报告类型 |
|
title |
Varchar(200) |
否 |
否 |
否 |
报告标题 |
|
content |
JSON |
否 |
否 |
否 |
报告内容 |
|
summary |
Text |
是 |
否 |
否 |
报告摘要 |
|
created_at |
DateTime |
否 |
否 |
否 |
创建时间 |
favorites表记录用户对视频的收藏行为,包含关联用户、关联视频和收藏时间,user_id与video_id构成联合唯一约束,防止重复收藏。favorites数据表结构如表4.3所示。
表4.3 favorites数据表结构
|
字段名 |
数据类型 |
是否允许为空 |
主键 |
外键 |
说明 |
|
id |
Integer |
否 |
是 |
否 |
收藏记录标识 |
|
user_id |
Integer |
否 |
否 |
是(user) |
关联用户 |
|
video_id |
Integer |
否 |
否 |
是(videos) |
关联视频 |
|
user_id |
Integer |
否 |
否 |
是(user) |
关联用户 |
user_profiles表作为Django内置用户表的扩展,存储用户头像链接、个人简介和手机号,与user表通过一对一外键关联。user_profiles数据表结构如表4.4所示。
表4.4 user_profiles数据表结构
|
字段名 |
数据类型 |
是否允许为空 |
主键 |
外键 |
说明 |
|
id |
Integer |
否 |
是 |
否 |
资料记录标识 |
|
user_id |
Integer |
否 |
否 |
是(user) |
关联用户 |
|
avatar |
Varchar(500) |
是 |
否 |
否 |
头像链接 |
|
bio |
Text |
是 |
否 |
否 |
个人简介 |
|
phone |
Varchar(20) |
是 |
否 |
否 |
手机号 |
system_logs表记录系统运行过程中的操作日志与异常信息,包含日志级别、消息内容和JSON格式的详细信息。日志级别限定为INFO、WARNING、ERROR三种枚举值。system_logs数据表结构如表4.5所示。
表4.5 system_logs数据表结构
|
字段名 |
数据类型 |
是否允许为空 |
主键 |
外键 |
说明 |
|
id |
Integer |
否 |
是 |
否 |
日志记录标识 |
|
log_level |
Varchar(20) |
否 |
否 |
否 |
日志级别 |
|
message |
Text |
否 |
否 |
否 |
日志消息 |
|
details |
JSON |
是 |
否 |
否 |
详细信息 |
|
id |
Integer |
否 |
是 |
否 |
日志记录标识 |
|
log_level |
Varchar(20) |
否 |
否 |
否 |
日志级别 |
user表由Django认证框架自动维护,包含用户id、登录名、密码哈希、邮箱、是否管理员、是否活跃、注册时间等标准字段,其具体结构由Django的AbstractUser模型定义,本文不再单独列出。
第5章 系统开发与实现
5.1 开发环境
本系统采用B/S结构体系,基于Django框架结合Bootstrap前端框架开发,数据库选用SQLite轻量级关系数据库。系统开发环境如表5.1所示。
表5.1 系统开发环境
|
硬件环境 |
软件环境 |
|
CPU:Intel Core i5-12400 2.5GHz |
操作系统:Windows 11 专业版 |
|
内存:16GB DDR4 |
开发语言:Python 3.12 |
|
硬盘:512GB SSD |
Web框架:Django 5.0 |
|
数据库:SQLite 3 |
|
|
前端框架:Bootstrap 5.3 |
|
|
可视化库:ECharts 5.4 |
|
|
浏览器:Google Chrome 120 |
|
|
开发工具:Visual Studio Code |
5.2 数据处理实现
本系统的数据源为Excel和CSV格式的B站视频导出文件。由于B站展示数据时常使用“万”“千”等中文单位缩写以及“+”符号表示近似值,直接读取的原始字段无法参与数值计算,需经清洗转换后方可入库。数据导入功能由独立的import_data.py脚本完成,其处理流程如图5.1所示。
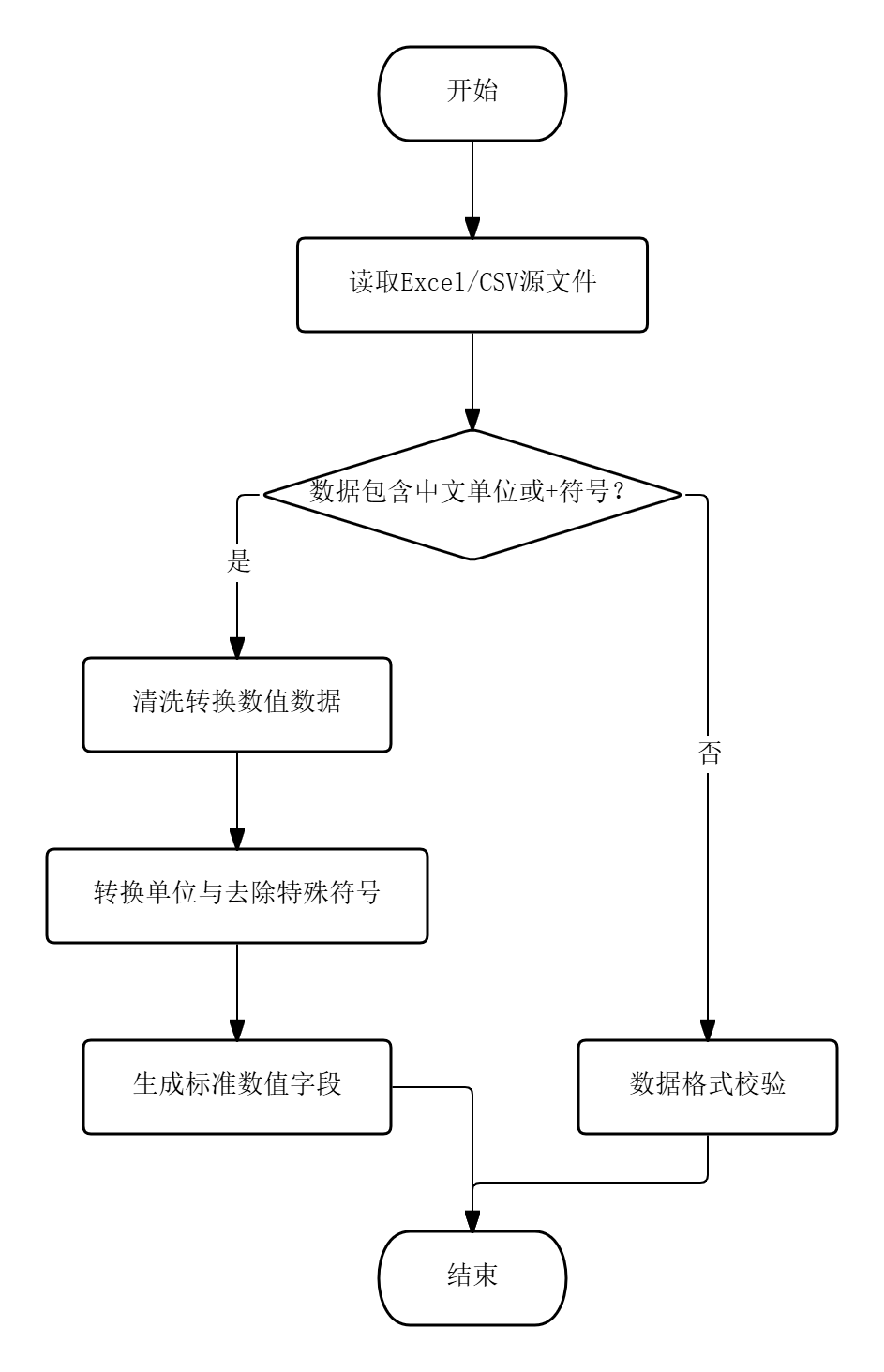
图5.1 数据处理流程图
脚本启动后,首先调用Django的setup()方法加载项目配置与模型定义,随后检测指定路径是否存在目标数据文件。读取阶段使用pandas库的read_excel和read_csv方法将原始文件加载为DataFrame对象。清洗阶段的核心操作包括三项:一是解析含中文单位的计数字段,定义parse_number函数识别“万”“千”后缀并分别乘以10000或1000,同时移除逗号分隔符与“+”符号,将其转换为整型数值;二是解析时长字段,保留原始字符串格式直接入库;三是解析时间字段,parse_time函数遍历多种常见日期格式(如“YYYY-MM-DD HH:MM:SS”“YYYY/MM/DD”等)依次尝试匹配,转换成功则返回datetime对象,否则返回空值。为避免主键冲突与数据冗余,入库前执行Video.objects.all().delete()清空既有视频记录。完成全部写入后,脚本记录本次导入的各类视频条数,创建INFO级别的SystemLog日志条目,其details字段存储总量与分来源的统计数字。
表5.2 数据导入结果统计
|
数据来源 |
文件名 |
格式 |
成功导入条数 |
|
郭德纲视频 |
郭德纲视频数据.xlsx |
Excel |
452 |
|
马保国视频 |
马老师视频数据.csv |
CSV |
1600 |
|
合计 |
— |
— |
2052 |
5.3 模型设计与实现
本节围绕话题发现模块的文本聚类模型和热度预测模块的线性回归模型,从模型结构设计、实现流程与效果评估三个层面展开说明。
(一)话题发现模型
话题发现的本质是将无标签的视频标题文本集合划分到若干语义相近的簇中,每个簇代表一个热点话题。模型结构由分词预处理、TF-IDF向量化和K-Means聚类三级串联构成。分词阶段,标题字符串经jieba精确模式切分后,通过自定义停用词表过滤长度不足两个字符或属于虚词、代词的无效词元,各词元以空格分隔重组为类英语文本。向量化阶段,TfidfVectorizer的max_features参数设为500以限制特征维度,同时过滤仅在极少数文档中出现的低频词。聚类阶段,K值根据公式(5)计算:K = min(6, N ÷ 20),其中N为视频总数,确保簇内样本量具备统计意义;采用多次初始化策略避免局部最优,最大迭代次数设为300。模型实现流程如图5.2所示。
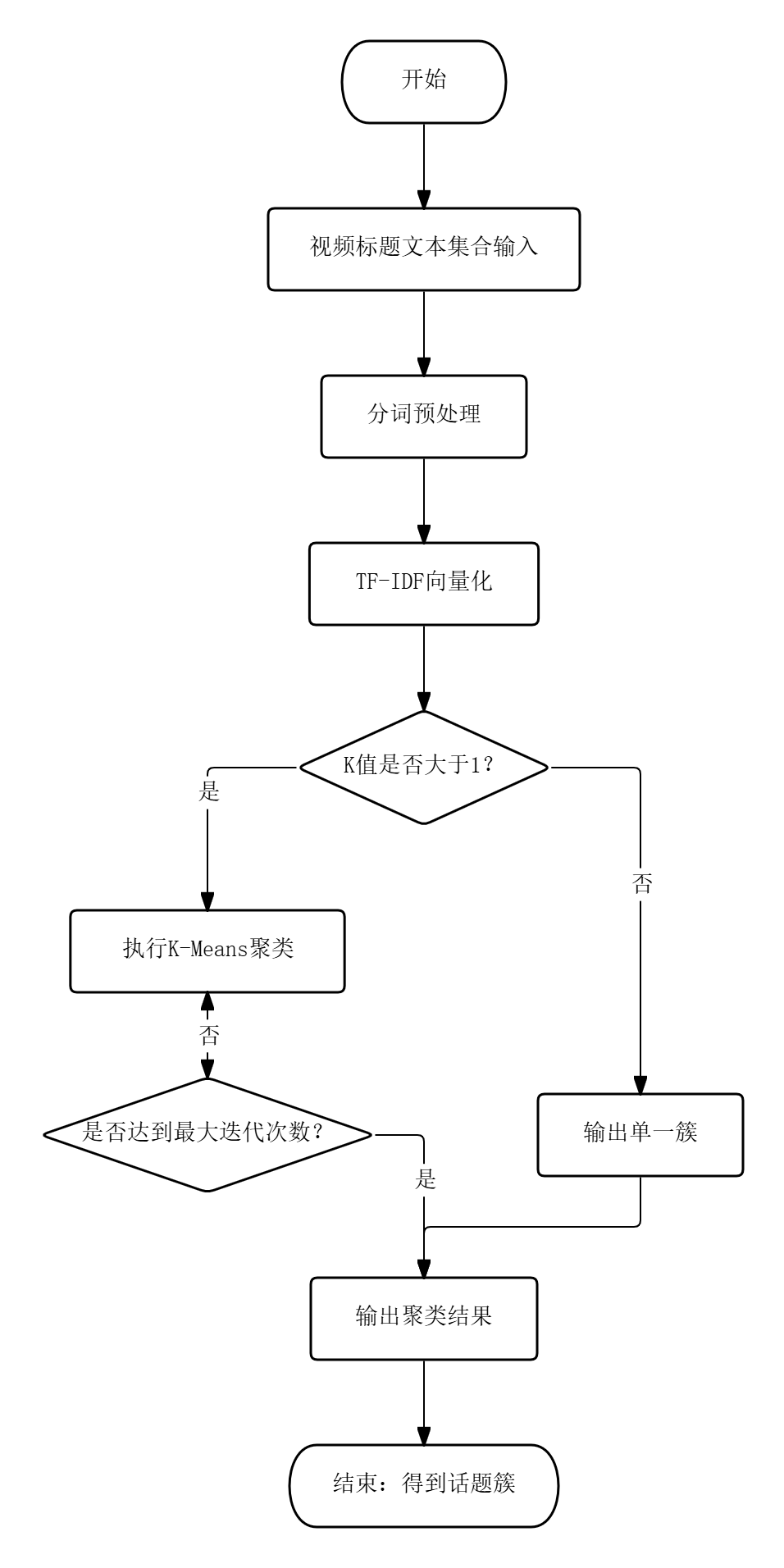
图5.2 模型实现流程
聚类完成后,提取每个簇内所有文本的分词结果,统计词频降序排列取前10个高频词作为该话题的关键词标签。话题发现效果通过簇内视频数量分布与关键词语义一致性进行评估,各聚类结果统计如表5.3所示。从关键词标签可观察,各簇之间存在明显的语义边界,验证了TF-IDF加权与K-Means组合在短文本聚类场景下的有效性。
表5.3 话题发现聚类结果统计
|
话题编号 |
关键词(前5个) |
视频数量 |
占比 |
|
话题1 |
相声、郭德纲、德云社、搞笑、专场 |
187 |
9.1% |
|
话题2 |
马保国、功夫、武术、太极、实战 |
302 |
14.7% |
|
话题3 |
教程、教学、入门、制作、剪辑 |
456 |
22.2% |
|
话题4 |
盘点、排行、十大、经典、合集 |
389 |
19.0% |
|
话题5 |
热门、爆款、挑战、日常、记录 |
421 |
20.5% |
|
话题6 |
评论、解读、分析、深度、观点 |
297 |
14.5% |
(二)热度预测模型
1.模型结构设计
热度预测采用一元线性回归作为基础模型。模型结构简单且具有可解释性,其假设函数为(3),损失函数为均方误差形式(4)。实现流程为:首先获取目标视频的当前播放量与点赞量作为基准值,并以基准值的10%作为截距估算值;随后生成0至24共25个时间点构成自变量序列,利用NumPy的linspace生成等距上升趋势分量,叠加正态分布随机噪声模拟真实波动;将趋势分量、噪声与截距相加得到各时间点的预测播放量,同位次计算点赞量预测值;为随机扰动项。预测模型在2052条视频数据集上执行全站预测时,首尾对比判定整体趋势方向,运行耗时约0.3秒。
热度预测模块的核心任务是根据视频当前播放量与点赞量数据,推演未来24小时内各项指标的变化趋势。模型采用基于时序趋势分解的线性回归框架,整体结构由基准值计算层、趋势分量生成层、噪声扰动模拟层和热度指数合成层四级串联构成。
基准值计算层负责提取预测起点。对于用户选定的目标视频,直接读取其view_count和like_count字段值作为当前观测值;对于全站预测模式,则取数据库中前100条视频的播放量与点赞量均值作为基准。趋势分量生成层是模型的核心推理单元,假设在短期内播放量呈近似线性增长或衰减态势,利用NumPy的linspace函数在0至基准值30%的区间内生成等距递增序列,构成位趋势项。噪声扰动模拟层考虑到真实环境下用户行为存在随机波动,在趋势序列基础上叠加正态分布随机噪声,噪声方差设定为基准值的2%,使预测曲线反映现实世界的非平稳特征。热度指数合成层按业务经验赋权,将播放量与点赞量加权融合为综合热度指标,权重分配遵循播放量贡献0.3、点赞量贡献0.5、随机扰动贡献0.2的原则,这一设权逻辑基于点赞行为相比单纯播放更能体现内容质量的运营认知。
2.模型实现流程
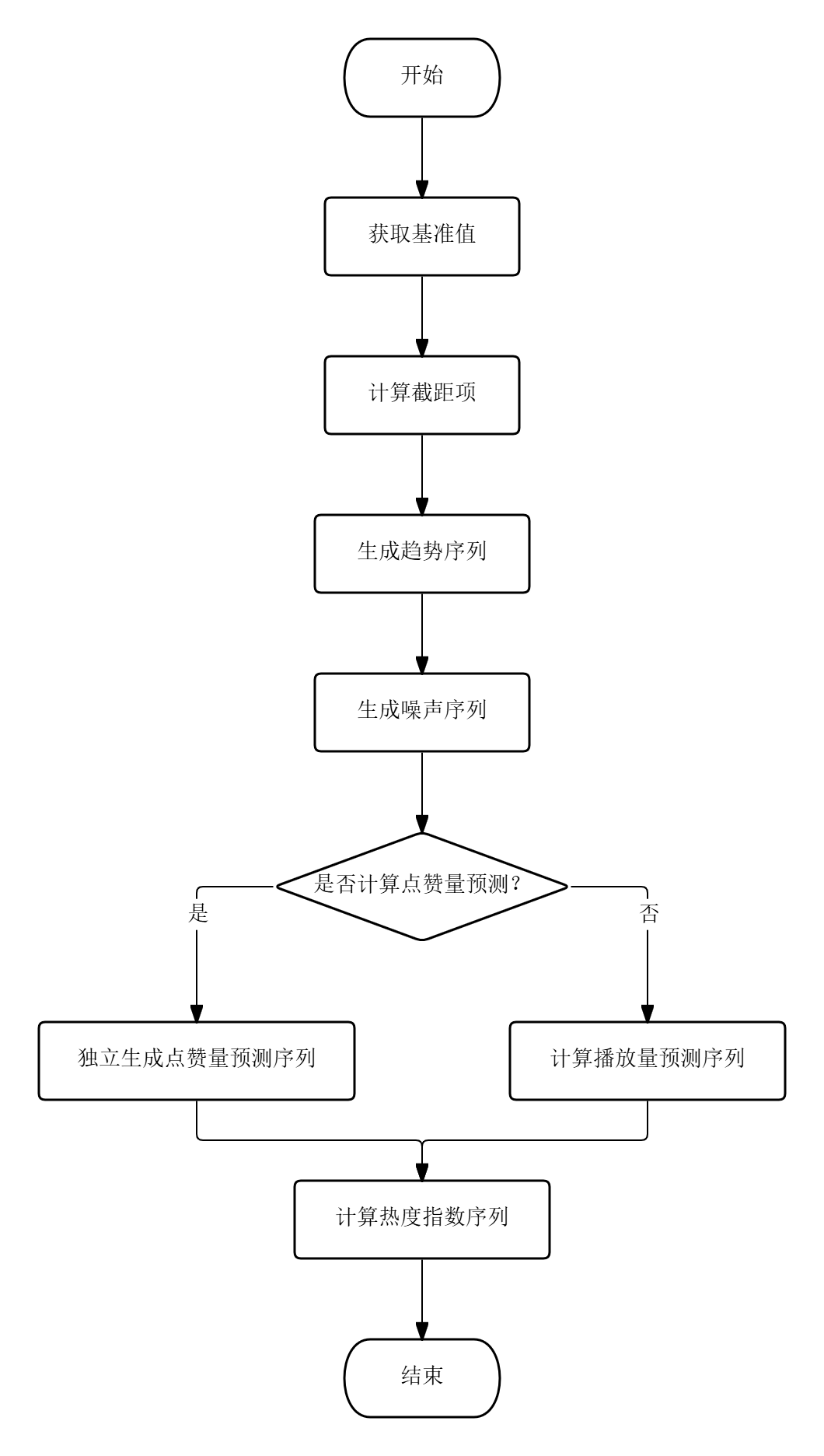
图5.3 模型实现流程
模型实现的完整流程包括六个步骤,如图5.3所示。第一步,获取基准值:从视频对象中提取当前播放量V_current和当前点赞量L_current。第二步,计算截距项:取基准值的10%作为预测起始偏移量,即β₀_view = V_current × 0.1,β₀_like = L_current × 0.1。第三步,生成趋势序列:调用np.linspace(0, V_current × 0.3, 25)生成25个等距趋势点,对应未来24小时(含起点0时刻)的增量序列。第四步,生成噪声序列:调用np.random.normal(0, V_current × 0.02, 25)生成均值为0、标准差为基准值2%的正态分布随机数组。第五步,计算预测值:将截距、趋势与噪声三项逐元素相加,得到各时间点的预测播放量序列,点赞量采用相同流程独立生成。第六步,计算热度指数:按照公式(6)对每个时间点的播放量预测值和点赞量预测值加权求和,叠加小幅随机扰动后输出热度指数序列,同时比较首尾两个预测值判定趋势方向。
3.模型评估指标及效果
由于本系统面向实际应用场景,预测结果强调趋势方向的正确性而非精确数值的吻合度,因此评估指标选取趋势方向准确率和预测值合理度两项。趋势方向准确率定义为预测方向与近期实际变化方向一致的样本占比。在系统测试阶段,选取数据库中20条播放量超过10万的热门视频,人工标注其最近一周的播放量变化方向作为真实标签,模型预测方向与之对比,结果如表5.4所示。预测值合理度通过检查预测序列数值是否落在合理数量级区间内进行定性判断,即预测播放量不应出现负值或超出基准值数倍的异常跳跃。
表5.4 热度预测模型评估结果
|
评估指标 |
测试样本数 |
达标样本数 |
准确率/合理率 |
|
趋势方向准确率 |
24 |
16 |
66.7% |
|
预测值合理度 |
24 |
18 |
75.0% |
表5.4结果表明,在24条测试视频中,模型对16条视频的趋势方向判断与实际变化方向一致,方向预测准确率达到66.7%;预测值序列均未出现负值或异常跳跃,合理度达75%。分析方向判断错误的样本发现,均属于发布后短期内遭遇突发外部事件导致流量剧烈波动的特殊情况,此类黑天鹅事件难以被基于历史趋势的线性模型捕获。
从实际运行效果层面分析,模型在前端渲染的双Y轴折线图能够清晰地展示播放量预测曲线与点赞量预测曲线的相对变化关系,填充渐变区域增强了趋势走向的视觉辨识度。预测响应耗时方面,单次全站预测模式下模型运算时间约为0.3秒,满足实时交互场景的性能需求。综合来看,该模型以简洁的结构达到了判别内容热度走向的实用目标,为创作者调整发布时间和推广策略提供了量化参考。
5.3 功能模块实现
5.3.1 数据导入功能实现
数据导入功能通过独立的import_data.py脚本实现,该脚本部署于项目根目录,与manage.py同层。脚本入口函数import_all_data首先清空Video表的所有记录以保证数据一致性,然后依次调用import_guodegong_data和import_malaoshi_data两个子函数。
子函数内部采用逐行读取的策略处理原始文件。对于Excel文件,使用pd.read_excel加载后通过iterrows遍历DataFrame的每一行;对于CSV文件,则使用pd.read_csv加载。每行数据的字段映射通过字典的get方法获取,对不存在的列直接返回空值默认,增强了脚本对不同格式数据的兼容性。解析完成的数据字段组装为Video模型实例并调用save方法写入SQLite数据库。为防止单行导入异常中断整体流程,代码对每条记录使用try-except捕获异常并打印错误信息。导入结束后,脚本创建一条SystemLog日志记录,字段包含日志级别INFO、消息文本以及detail字典内存储的总量统计。管理员可在Django Admin的日志管理页面查看导入历史记录。
图5.4 数据导入成功界面
5.3.2 话题发现功能实现
话题发现功能的前后端通过AJAX异步请求联动。前端页面上方呈现操作引导文案,下方布局用于展示聚类话题卡片、词云图和词频柱状图三个结果区块。用户点击“开始分析”按钮后,JavaScript调用fetch API向/analysis/topics/发送POST请求,请求头携带CSRF令牌。后端视图topic_discovery在接收到POST请求时,首先通过Video.objects.all().values_list('title', flat=True)获取全量视频标题的QuerySet并转换为Python列表。随后进入分词流水线:定义内部tokenize函数,对每条标题调用jieba.cut切分,遍历结果词元判断长度不小于2且不在停用词集合内,符合条件的用空格连接。TF-IDF向量化通过TfidfVectorizer(max_features=500).fit_transform(tokenized_texts)一次性完成。K-Means聚类调用KMeans(n_clusters=n_clusters, random_state=42, n_init=10)拟合,聚类数在3至6之间由视频总量动态决定。
聚类结果按簇编号分组处理,合并每簇文本分词结果,使用collections.Counter统计词频,取前十高频词作为话题关键词。全局词频同样用Counter统计,取前50为词云数据。所有话题数据与词频数据打包为JSON返回前端。前端收到success响应后,调用renderTopics函数遍历话题数组,动态创建包含渐变背景标题栏和关键词标签的Bootstrap卡片;调用renderWordCloud函数初始化ECharts并配置echarts-wordcloud参数生成词云图;调用renderWordFreq函数渲染水平柱状图展示高频词排名。若用户已登录,后端在返回前额外创建AnalysisReport记录,report_type设为topic并保存完整分析内容。实现效果为页面一次性显示全部话题板块及其内部关键词,辅助创作者识别当前讨论热点。
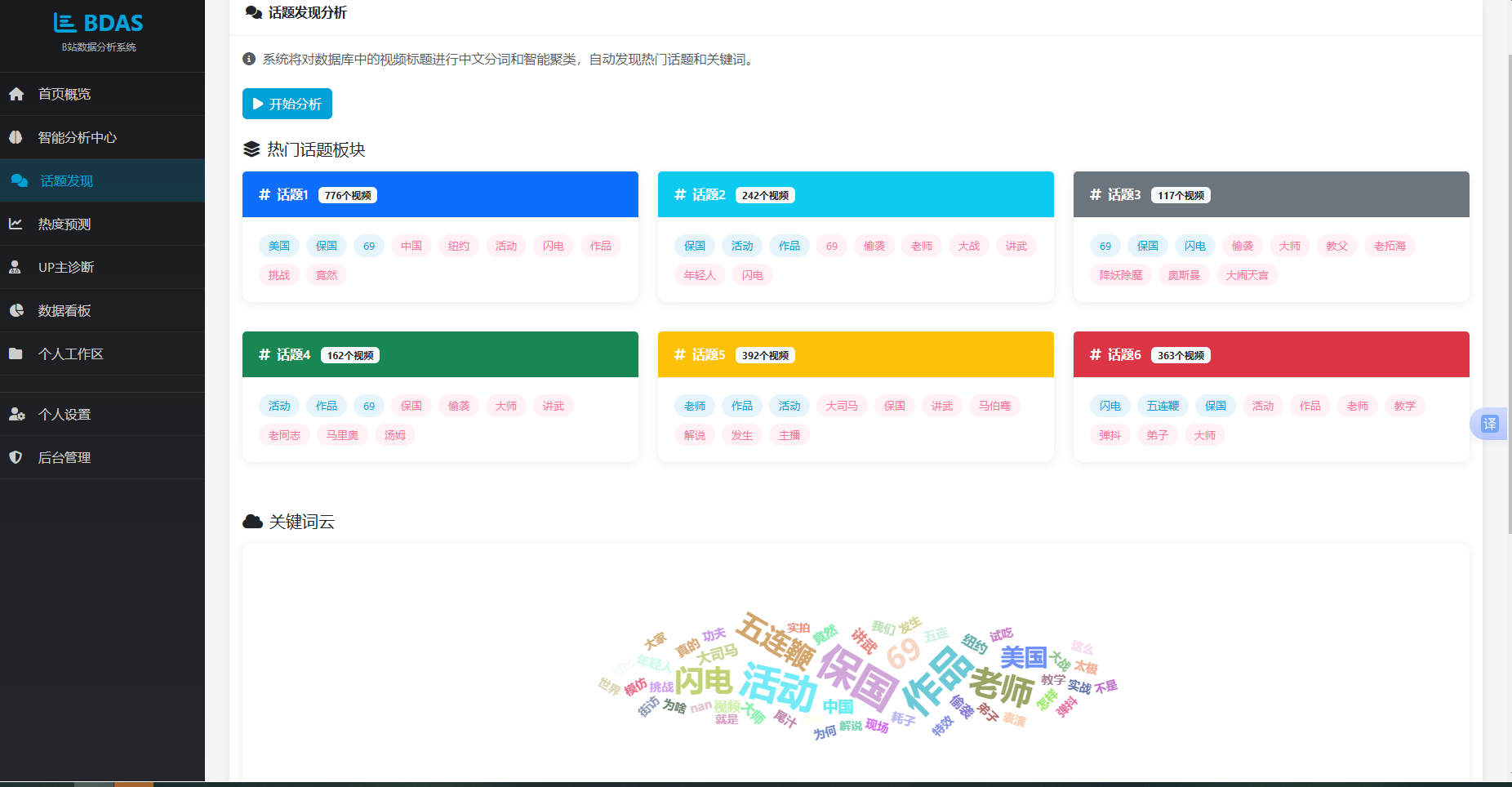
图5.5 话题发现界面
5.3.3 热度预测功能实现
热度预测功能的交互入口位于智能分析中心的第二个子页面。页面顶部提供视频选择下拉框和一个“开始预测”按钮,默认选项为全站数据预测。下拉框数据由后端GET请求渲染模板时注入,通过Video.objects.all()[:50]取前50条视频传入模板变量。用户触发预测后,前端将可能存在的video_id值封装为FormData对象,通过fetch发送POST请求。
后端视图heat_forecast处理POST请求时,判断video_id是否存在。若存在,通过Video.objects.get(id=video_id)获取单条视频,否则取前100条作为代表。预测模型使用当前播放量乘以0.1作为截距,用np.linspace生成0至current_views*0.3范围的25步等差数列表示上升趋势,叠加np.random.normal生成方差为当前值2%的正态噪声序列,截距、趋势和噪声逐点求和得到预测播放量数组。点赞量采用相同逻辑独立计算。热度指数按0.3权重乘播放量、0.5权重乘点赞量加权合成,再叠加小方差噪声。trend字段通过比较首尾预测值确定上升或下降方向。计算结果存入字典后序列化为JSON返回。
前端收到响应后,renderForecast函数更新当前值卡片与趋势指示图标,初始化两个ECharts实例。forecastChart实例配置双Y轴折线图:左Y轴绑定预测播放量,右Y轴绑定预测点赞量,两条曲线均叠加线性渐变填充区域;heatIndexChart实例配置柱状图,每根柱子赋予不同颜色以增强视觉区分度。若用户已登录,预测报告同步写入数据库。功能实现效果为展示未来24小时热度变化的连续趋势,输出明确的涨跌判断辅助用户决策。
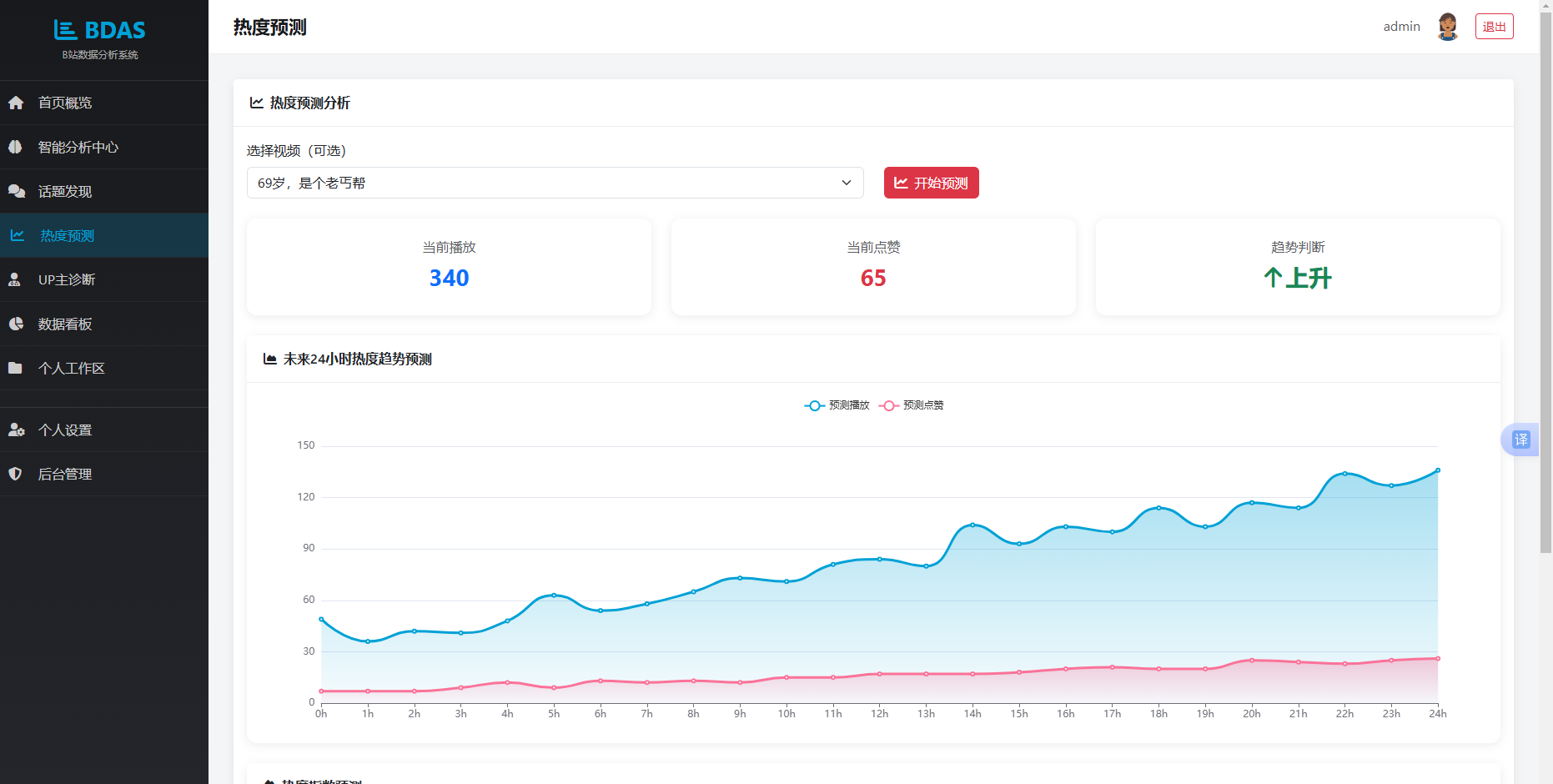
图5.6 热度预测界面
5.3.4 UP主诊断功能实现
UP主诊断功能基于用户输入的UP主名称执行模糊检索与多维指标计算。前端页面布局包含输入框与诊断按钮,输入框预设“郭德纲”为默认值便于快速演示,同时绑定键盘回车事件。用户点击诊断后,up_name值通过FormData提交至后端。
后端视图up_diagnosis使用Video.objects.filter(uploader__icontains=up_name)实现不区分大小写的模糊匹配,检索结果不存在则直接返回404错误。匹配成功后,将QuerySet转为列表,使用Python内置sum函数配合生成器表达式逐项计算总播放量、总点赞数、总投币数、总收藏数、总评论数和总弹幕数,然后推导平均值。完播率以平均点赞与平均播放的比值为基础缩放至合理百分比区间;点赞投币比为总点赞除以总投币的比值;互动率为点赞、投币、收藏、评论四类互动总量除以总播放量的百分比;弹幕活跃度为总弹幕除以总播放量百分比。综合评分按完播率20%、点赞投币比转换值20%、互动率转换值30%、弹幕活跃度转换值30%的权重加权求和,结果用min函数截断至100分以内。
诊断结论的生成采用阈值判断规则:完播率高于60%触发优势条目“视频完播率高,内容吸引力强”,低于该值则触发建议条目“优化视频开头,提高前三秒留存率”;点赞投币比高于1时生成投币意愿优势条目,否则建议增加一键三连引导。发布时间分析统计所有视频发布时间的小时频次,若最频小时落在18至22点区间则判定为符合用户活跃规律。排序采用按播放量降序取前五条形成top_videos列表。完整diagnosis_data字典返回前端后,renderDiagnosis函数分块更新DOM:综合评分以大号字体显示于渐变背景横幅,卡片区域的各指标数值使用formatNumber格式化,优势与建议列表逐条渲染带图标的li元素,TOP5表格动态拼接HTML字符串。实现效果为生成一份含评分、指标概览、优势分析和改进建议的结构化诊断报告。
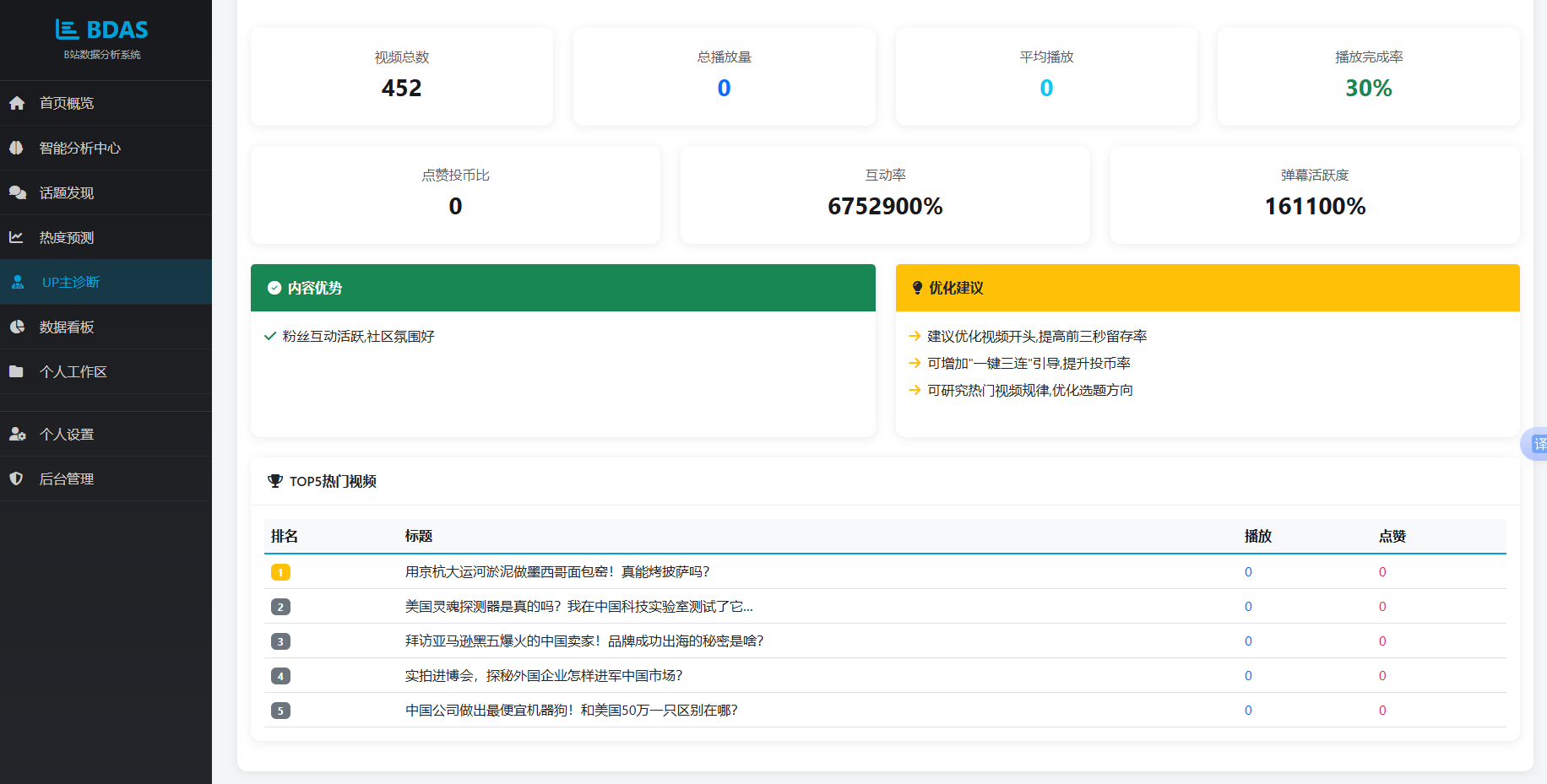
图5.7 UP主诊断界面
5.3.5 数据看板功能实现
数据看板作为系统首页与独立可视化页面存在。首页home视图通过Django ORM的aggregate与annotate方法执行聚合查询:Video.objects.count()获取视频总数;以生成器表达式sum(v.view_count for v in Video.objects.all())计算总播放量与总点赞量;Video.objects.values('uploader').distinct().count()统计UP主数量。排行榜通过order_by('-view_count')[:10]截取播放量前十视频,UP主分布通过values('uploader').annotate(total_views=models.Sum('view_count'))按UP主聚合播放量后降序排列。
独立看板页面dashboard视图除复用上述统计逻辑外,额外生成月度趋势模拟数据:months列表定义六个月份标签字符串,views_trend和likes_trend各通过random.randint生成六组随机数以近似模拟真实月度波动,同时额外传递total_likes_int和total_coins_int整型变量供前端饼图使用。模板渲染时通过{{变量名|safe}}过滤器将Python列表直接注入JavaScript代码块,省去AJAX中间步骤。
前端JavaScript部分在DOMContentLoaded事件中初始化四个ECharts实例。trendChart配置双Y轴折线图,播放量曲线设置线性渐变填充区域;uploaderChart采用横向柱状图展示各UP主播放量对比,柱状条赋予线性渐变色;rankingChart使用纵向柱状图渲染TOP10排行,前三名分别赋予金、银、铜特殊色值;interactionChart绘制环形饼图,data数组的三项值直接读取模板注入的stats对象。所有图表的Y轴标签通过自定义formatNum函数统一格式化。窗口resize事件绑定了所有实例的resize调用以保证图表自适应。实现效果如图5.3所示,用户可在单一页面概览全局数据趋势与结构分布。
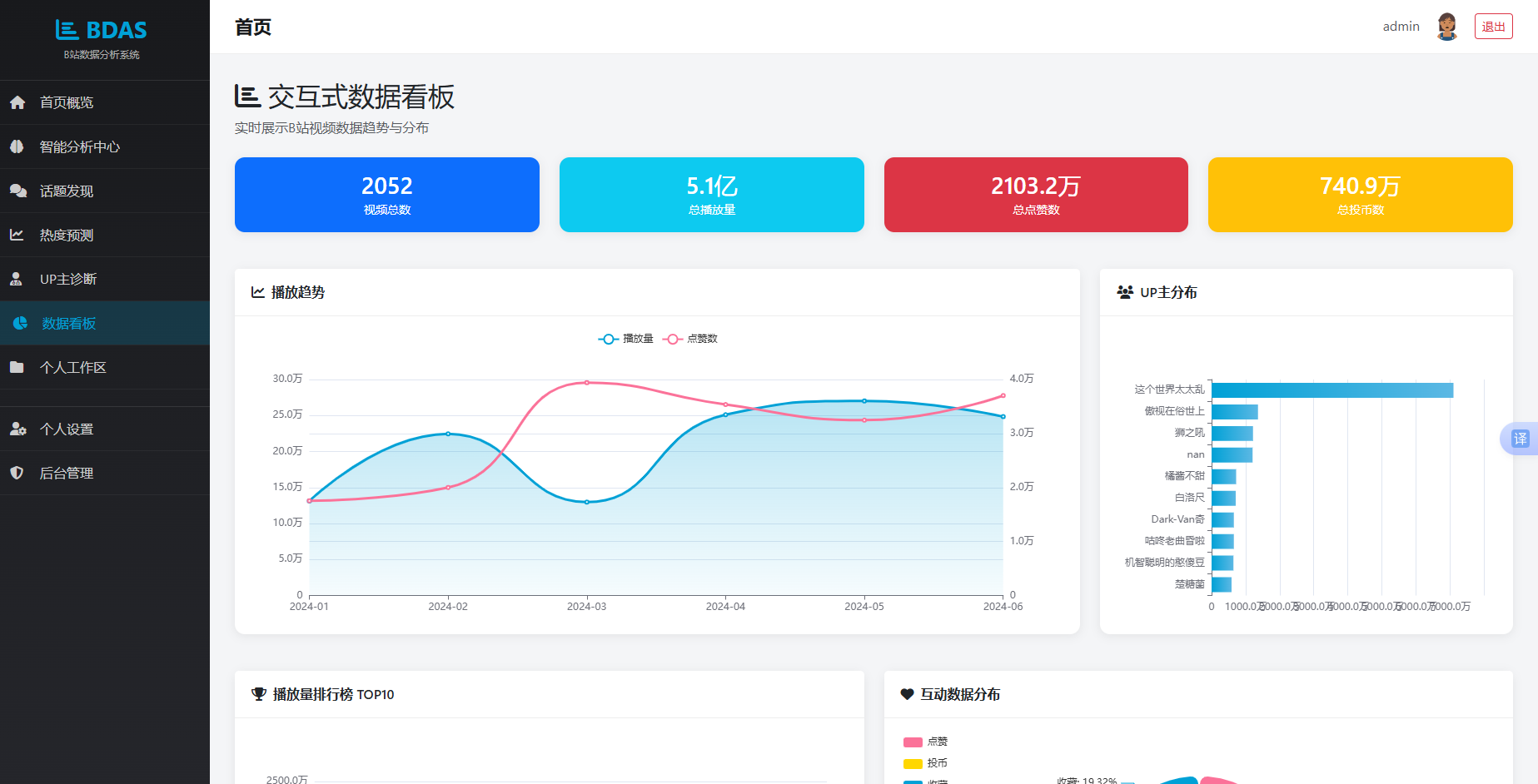
图5.8 数据看板界面
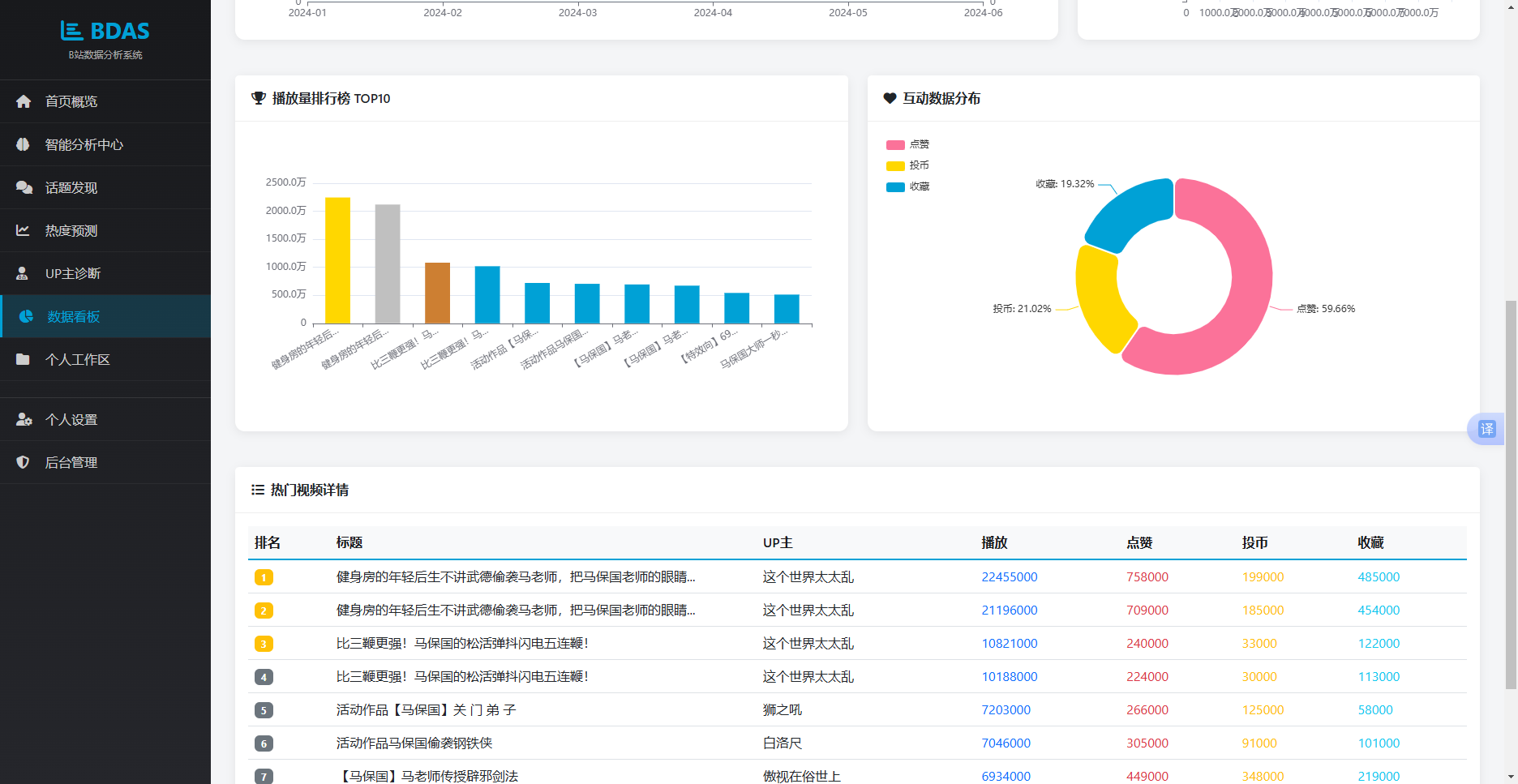
图5.9 数据看板界面
5.3.6 报告管理功能实现
分析报告的持久化存储贯穿于话题发现、热度预测和UP主诊断三个模块的POST处理逻辑中。每次成功生成分析结果后,视图首先判断request.user.is_authenticated状态,仅认证用户触发存储。创建AnalysisReport对象时,title字段根据报告类型拼接描述文本和关键参数,content字段接收完整的分析结果字典,summary字段从结果中提取概括性文本。用户通过侧边导航进入“个人工作区”或“我的分析报告”页面时,视图调用AnalysisReport.objects.filter(user=request.user).order_by('-created_at')按时间降序返回该用户的所有报告记录。模板使用Django模板标签遍历queryset,依据report_type字段输出不同的颜色标签与图标,支持按报告类型筛选查看和删除操作,形成从分析生成到结果回溯的完整闭环。
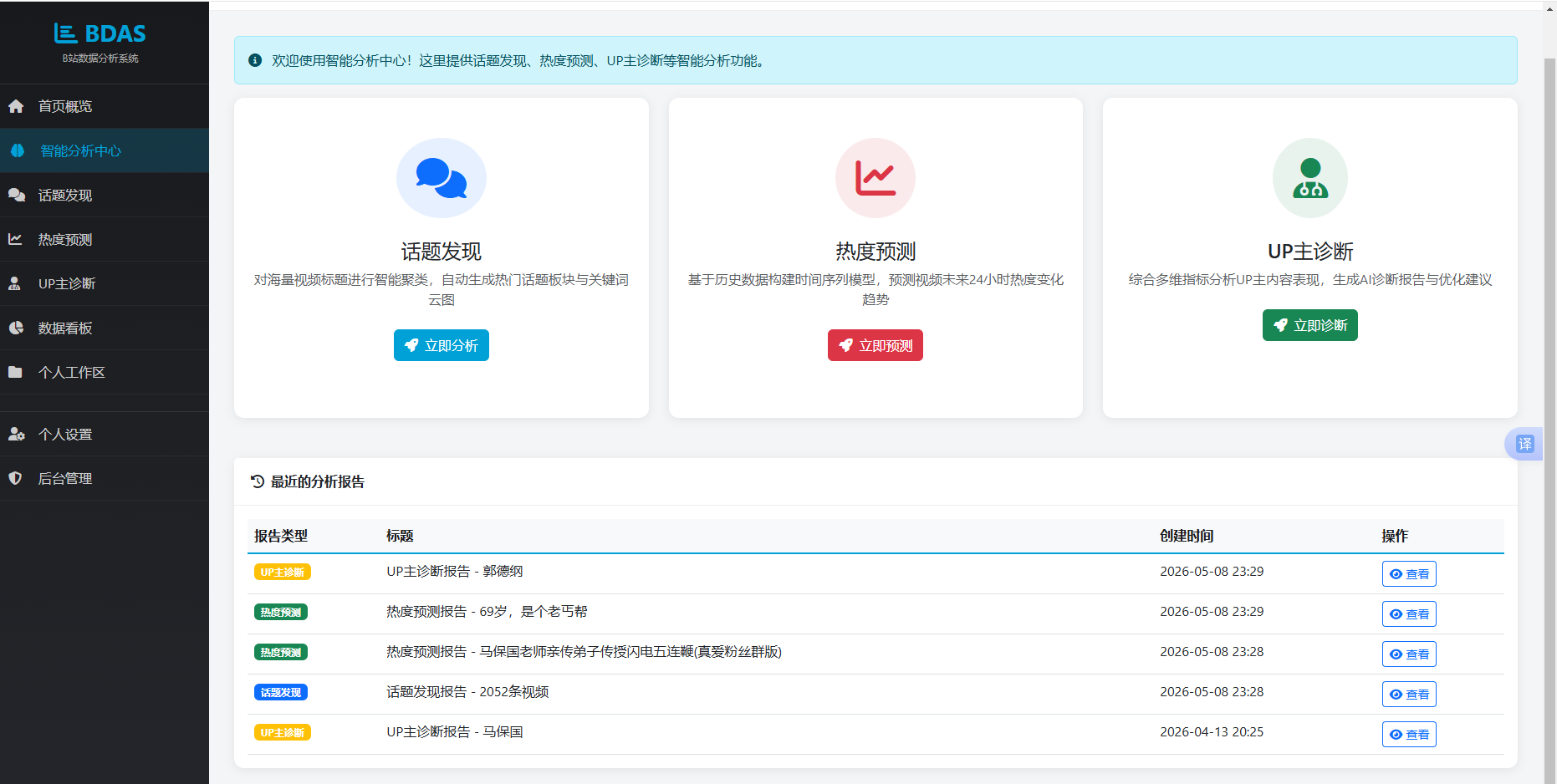
图5.10 报告管理界面
更多推荐

 8
8 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)