
面试官当场让我手写Python异步爬虫,我写完直接拿到了32K的数据分析offer

前言:那场让我记忆犹新的面试
还记得去年秋天,我去面试一家互联网公司的数据分析岗位。前三轮技术面都挺顺利,从Python基础到pandas数据处理,从SQL到机器学习,聊得都还不错。到了第四轮,也就是总监面,我本以为会聊一些项目经历和职业规划,没想到面试官一上来就给我出了道手写代码题。
“给你30分钟,手写一个异步爬虫,爬取豆瓣电影TOP250的所有电影信息,包括电影名、评分、评价人数、上映年份。要求用asyncio+aiohttp,要有并发控制、重试机制、异常处理。”
面试官说完,把电脑推到我面前,就出去接电话了。
说实话,当时我心里咯噔一下。虽然平时也写过爬虫,但都是用requests写的同步爬虫,异步的只在教程里看过,从来没真正手写过一个完整的。
但转念一想,这不正是展示我学习能力和技术功底的好机会吗?我深吸一口气,开始在脑海里梳理思路:
-
异步爬虫的核心是asyncio事件循环
-
用aiohttp发送异步HTTP请求
-
需要用Semaphore控制并发数,不能把网站爬崩了
-
失败的请求要重试,最多重试3次
-
用BeautifulSoup解析HTML
-
最后把数据存到CSV里
我一边想一边写,从导入库开始,到定义协程函数,到设置信号量,再到重试装饰器,最后是主函数。中间遇到了几个小问题,比如aiohttp的Session怎么用,Semaphore的位置放哪里,不过都凭着印象和逻辑推理解决了。
大概25分钟的时候,我写完了。运行测试,虽然有几个小bug,但整体思路是对的。面试官回来后,我给他讲解了代码的结构和设计思路,又一起讨论了几个优化点。
一周后,我收到了offer——32K,14薪。
后来和同事聊天的时候才知道,那道手写异步爬虫的题,之前面了十几个人,能完整写出来的只有两个,我是其中之一。
很多人觉得异步爬虫很难,又是async又是await,还有事件循环、协程这些概念,听起来就很高深。但其实,只要你理解了核心原理,异步爬虫并没有那么难。
今天这篇文章,我就从最基础的概念讲起,带你从零手写一个工业级的Python异步爬虫。看完这篇文章,别说面试手写了,就算是工作中遇到真实的爬虫需求,你也能轻松应对。
第一章:同步爬虫的痛点——为什么我们需要异步?
在讲异步爬虫之前,我们先来看一下传统的同步爬虫有什么问题。
1.1 同步爬虫的工作方式
先来看一个最简单的同步爬虫:
import requests
import time
def fetch_url(url):
response = requests.get(url)
return response.text
def main():
urls = [
"https://www.example.com/page/1",
"https://www.example.com/page/2",
"https://www.example.com/page/3",
# ... 假设有100个URL
]
start = time.time()
for url in urls:
html = fetch_url(url)
print(f"已下载: {url}, 长度: {len(html)}")
end = time.time()
print(f"总耗时: {end - start:.2f}秒")
if __name__ == "__main__":
main()
这段代码很简单,就是依次下载每个URL的内容。
那它的性能怎么样呢?假设每个请求平均需要0.5秒,100个URL就是50秒。
等等,50秒?是不是太慢了?我们的CPU明明是8核的,为什么不能同时下载呢?
这就是同步爬虫的最大问题:大部分时间都在等网络响应,CPU闲着没事干。
1.2 性能瓶颈在哪里?
我们来分析一下,下载一个网页的过程中,时间都花在哪里了:
-
建立TCP连接:几毫秒到几十毫秒
-
发送HTTP请求:几毫秒
-
等待服务器响应:几百毫秒到几秒
-
接收响应数据:几毫秒到几十毫秒
-
解析HTML:几毫秒
你会发现,90%以上的时间都花在"等待"上——等服务器响应,等数据传输。而CPU在这段时间里,什么也没干,就在那儿闲着。
这就像你去餐厅吃饭,点了10道菜。如果是同步的方式,就是等第一道菜吃完了,再点第二道,第二道吃完了再点第三道… 大部分时间你都在等菜,而厨房明明可以同时做很多道菜。
这就是I/O密集型任务的特点:CPU很快,但I/O很慢,CPU大部分时间都在等待I/O完成。
而爬虫,就是典型的I/O密集型任务。
1.3 怎么提高效率?
既然CPU在等I/O的时候闲着,那能不能让它别闲着,同时处理多个请求呢?
当然可以。常见的方案有三种:
方案一:多线程
开多个线程,每个线程负责下载一个URL。这样,一个线程在等I/O的时候,其他线程可以继续工作。
import requests
import threading
import time
def fetch_url(url):
response = requests.get(url)
print(f"已下载: {url}")
def main():
urls = [...] # 100个URL
start = time.time()
threads = []
for url in urls:
t = threading.Thread(target=fetch_url, args=(url,))
t.start()
threads.append(t)
for t in threads:
t.join()
end = time.time()
print(f"总耗时: {end - start:.2f}秒")
多线程确实能提高效率,但也有问题:
-
线程的创建和销毁有开销
-
线程太多的话,线程切换的开销也很大
-
Python的GIL锁,导致多线程不能真正并行执行CPU密集型代码(不过对于I/O密集型,GIL会在I/O等待时释放,所以多线程还是有用的)
方案二:多进程
开多个进程,每个进程负责一部分URL。
import requests
import multiprocessing
import time
def fetch_url(url):
response = requests.get(url)
print(f"已下载: {url}")
def main():
urls = [...] # 100个URL
start = time.time()
with multiprocessing.Pool(10) as pool:
pool.map(fetch_url, urls)
end = time.time()
print(f"总耗时: {end - start:.2f}秒")
多进程的优点是能真正利用多核CPU,缺点是:
-
进程的开销比线程大得多
-
进程间通信比较麻烦
-
对于I/O密集型任务,有点杀鸡用牛刀的感觉
方案三:异步(协程)
这就是我们今天的主角——异步编程,或者说协程。
异步的思路是:在单线程里,当遇到I/O操作的时候,不阻塞等待,而是去做其他事情,等I/O完成了再回来继续处理。
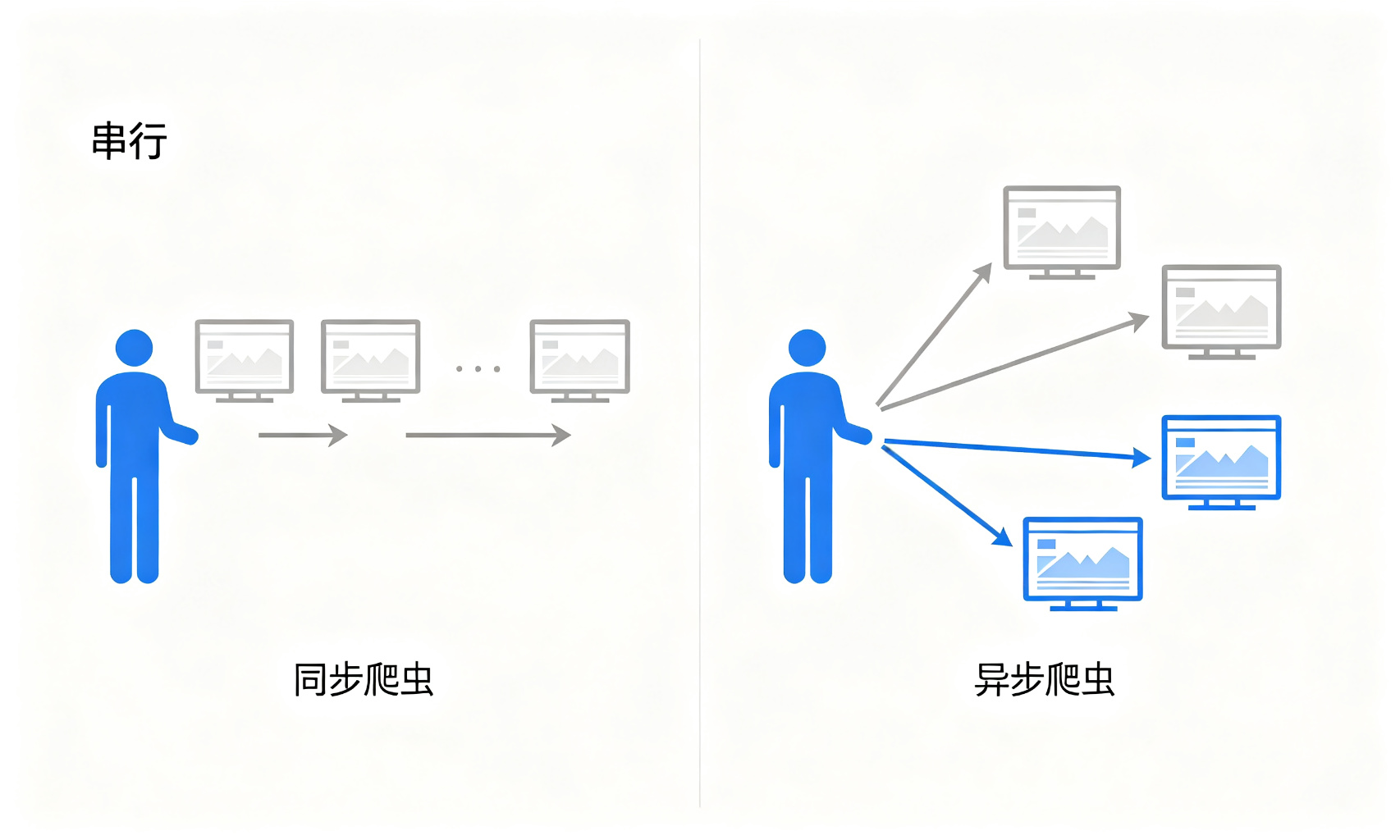
就像一个非常高效的服务员,他不会站在一桌旁边等客人点菜,而是把菜单给这桌,然后马上去服务下一桌。哪桌点好了,他就过去记下来,然后继续下一桌。
这样,一个服务员就能同时服务很多桌客人,效率非常高。
异步编程的优点:
-
单线程,没有线程切换的开销
-
并发数可以很高(几千甚至上万)
-
编程模型相对简洁(至少比多线程加锁简单)
对于爬虫这种I/O密集型任务,异步是非常合适的方案。
1.4 三种方案的对比
| 方案 | 并发模型 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|---|
| 同步 | 串行 | 简单任务、少量请求 | 简单易懂 | 效率极低 |
| 多线程 | 抢占式多任务 | I/O密集型、中等并发 | 相对简单,生态好 | 线程开销,GIL限制 |
| 多进程 | 多进程并行 | CPU密集型 | 真正并行,利用多核 | 进程开销大,通信复杂 |
| 异步(协程) | 协作式多任务 | I/O密集型、高并发 | 高效,高并发,资源占用少 | 需要异步库,编程思维转变 |
看完这个对比,你应该明白为什么异步爬虫这么受重视了——对于爬虫这种典型的I/O密集型任务,异步方案的效率是最高的,资源占用也是最少的。
这也是为什么面试官会把异步爬虫作为考察重点——它不仅考察你的Python功底,还考察你对并发编程的理解。
第二章:异步编程基础——理解asyncio
在写异步爬虫之前,我们得先搞懂Python的异步编程是怎么回事。
Python的异步编程核心是asyncio模块,它提供了事件循环、协程、任务等一系列工具。
2.1 什么是协程?
协程(Coroutine),可以理解为"可以暂停的函数"。
普通的函数,一旦开始执行,就会一直运行到return或者结束,中间不会暂停。
而协程不一样,它可以在执行到一半的时候暂停,把控制权交出去,等以后再从暂停的地方继续执行。
这听起来是不是有点像生成器(generator)?对,Python的协程最早就是用生成器实现的。不过现在有了专门的async/await语法,用起来更方便了。
2.2 async/await语法
Python 3.5引入了async和await关键字,让协程的写法变得非常简洁。
先来看一个最简单的例子:
import asyncio
async def hello():
print("Hello")
await asyncio.sleep(1)
print("World")
asyncio.run(hello())
这段代码会输出:
Hello
(等待1秒)
World
我们来逐行解释:
-
async def hello():用async def定义的函数,就是一个协程函数。调用它不会立即执行,而是返回一个协程对象。 -
await asyncio.sleep(1):await表示"等待"。遇到await的时候,协程会暂停在这里,把控制权交还给事件循环,等后面的操作完成了,再从这里继续执行。 -
asyncio.run(hello()):运行协程。asyncio.run()会创建一个事件循环,运行这个协程,直到它结束。
注意,await后面必须跟一个"可等待对象"(awaitable),比如协程、Task、Future等。普通的函数不能用await。
2.3 多个协程怎么并发执行?
一个协程没什么意思,我们来看多个协程怎么同时运行:
import asyncio
import time
async def say_after(delay, what):
await asyncio.sleep(delay)
print(what)
async def main():
start = time.time()
await say_after(1, "hello")
await say_after(2, "world")
end = time.time()
print(f"耗时: {end - start:.2f}秒")
asyncio.run(main())
你觉得这段代码会耗时多久?1秒?2秒?还是3秒?
答案是3秒。因为两个await是串行执行的——等第一个say_after执行完了,才会执行第二个。
那怎么让它们并发执行呢?用asyncio.create_task()把协程包装成Task:
import asyncio
import time
async def say_after(delay, what):
await asyncio.sleep(delay)
print(what)
async def main():
start = time.time()
task1 = asyncio.create_task(say_after(1, "hello"))
task2 = asyncio.create_task(say_after(2, "world"))
await task1
await task2
end = time.time()
print(f"耗时: {end - start:.2f}秒")
asyncio.run(main())
这次耗时是多少?2秒!
因为create_task会把协程包装成Task,提交给事件循环,然后立即返回,不会等待。所以两个Task是并发执行的,总耗时就是最长的那个的时间(2秒)。
这就是异步并发的核心思想:把多个任务都提交给事件循环,它们会在I/O等待的时候自动切换,充分利用等待时间。
2.4 事件循环(Event Loop)
事件循环是异步编程的核心。你可以把它理解为一个"调度器",负责管理和调度所有的协程任务。
事件循环的工作流程大概是这样的:
-
维护一个任务队列
-
从队列里取出一个任务,执行它
-
任务执行到
await的时候,暂停,把自己放回队列(或者注册I/O事件) -
继续取下一个任务执行
-
当某个任务等待的I/O完成了,把它重新放回就绪队列
-
如此循环,直到所有任务都完成
整个过程是在单线程里运行的,没有线程切换的开销,所以效率非常高。
你不需要自己实现事件循环,asyncio已经帮你实现好了。你只需要用asyncio.run()启动它就行了。
2.5 常用的asyncio API
除了create_task,asyncio还有很多常用的API:
asyncio.gather()
同时运行多个协程,等待所有都完成:
async def main():
results = await asyncio.gather(
say_after(1, "hello"),
say_after(2, "world"),
say_after(3, "!")
)
print(results)
gather会返回所有协程的结果,按顺序放在一个列表里。
asyncio.wait()
等待多个任务完成,可以设置超时或者只等第一个完成:
async def main():
tasks = [
asyncio.create_task(say_after(1, "hello")),
asyncio.create_task(say_after(2, "world")),
]
done, pending = await asyncio.wait(tasks, timeout=1.5)
print(f"已完成: {len(done)}个")
print(f"未完成: {len(pending)}个")
asyncio.Semaphore
信号量,用来控制并发数:
async def main():
sem = asyncio.Semaphore(10) # 最多10个并发
async def bounded_fetch(url):
async with sem:
return await fetch(url)
# 即使有1000个URL,也只会同时跑10个
tasks = [bounded_fetch(url) for url in urls]
await asyncio.gather(*tasks)
这个在爬虫里非常重要——你总不能同时开几千个请求把人家网站爬崩了吧?用Semaphore控制并发数,既高效又礼貌。
asyncio.Queue
异步队列,用来在协程之间传递数据:
async def producer(queue):
for i in range(10):
await queue.put(i)
await asyncio.sleep(0.1)
async def consumer(queue):
while True:
item = await queue.get()
print(f"消费: {item}")
queue.task_done()
生产者-消费者模式,在爬虫里也很常用。
2.6 异步编程的注意事项
学习异步编程,有几个点需要特别注意:
1. 异步函数不能直接调用
# 错误:这样只是创建了协程对象,不会执行
hello()
# 正确:用asyncio.run()运行
asyncio.run(hello())
直接调用async def的函数,只会返回一个协程对象,不会执行里面的代码。必须通过事件循环来运行。
2. await只能在async函数里用
# 错误:普通函数里不能用await
def func():
await asyncio.sleep(1)
# 正确:在async函数里用await
async def func():
await asyncio.sleep(1)
3. 不要在协程里调用阻塞函数
这是新手最容易犯的错误。如果你在协程里调用了阻塞函数(比如time.sleep()、requests.get()),整个事件循环都会被卡住,其他协程都没法运行了。
# 错误:time.sleep是阻塞的,会卡住整个事件循环
async def bad():
time.sleep(1)
# 正确:用asyncio.sleep,它是非阻塞的
async def good():
await asyncio.sleep(1)
同样的,requests库也是阻塞的,所以异步爬虫不能用requests,要用专门的异步HTTP库——也就是我们下一章要讲的aiohttp。
4. 异步是"协作式"的
异步编程是协作式多任务,不是抢占式的。也就是说,只有当协程主动await的时候,才会让出控制权。如果一个协程一直不await,一直在跑CPU密集型代码,那其他协程就只能等着。
所以,异步适合I/O密集型任务,不适合CPU密集型任务。如果有大量计算,还是用多进程吧。
第三章:aiohttp——异步HTTP请求库
了解了asyncio基础之后,我们来看一下异步爬虫的核心工具——aiohttp。
3.1 为什么是aiohttp?
我们平时写同步爬虫,用的是requests库,非常方便。但requests是阻塞的,不能在异步代码里用,不然会卡住整个事件循环。
那异步的HTTP库用什么呢?最常用的就是aiohttp。
aiohttp是一个基于asyncio的HTTP客户端/服务器库,功能非常强大,既可以用来写爬虫(客户端),也可以用来写Web服务器。
我们今天主要用它的客户端功能。
3.2 安装aiohttp
安装很简单,pip一下就行:
pip install aiohttp
如果速度慢,可以用国内镜像:
pip install aiohttp -i https://pypi.tuna.tsinghua.edu.cn/simple
3.3 第一个aiohttp请求
先来看一个最简单的例子:
import asyncio
import aiohttp
async def fetch_url(url):
async with aiohttp.ClientSession() as session:
async with session.get(url) as response:
html = await response.text()
return html
async def main():
url = "https://www.example.com"
html = await fetch_url(url)
print(f"页面长度: {len(html)}")
print(html[:500])
asyncio.run(main())
我们来逐行解释:
1. 创建ClientSession
async with aiohttp.ClientSession() as session:
ClientSession是aiohttp的核心,相当于requests的会话。它会管理连接池、cookie、认证等。
注意,ClientSession要用async with来创建,这样用完了会自动关闭。
最佳实践:整个程序尽量共用一个Session,不要每个请求都创建一个Session。 因为Session内部有连接池,复用Session可以复用TCP连接,大大提高效率。
2. 发送GET请求
async with session.get(url) as response:
session.get()发送GET请求,返回一个响应对象。同样用async with,确保响应体能被正确释放。
除了get(),还有post()、put()、delete()等方法,和requests类似。
3. 获取响应内容
html = await response.text()
response.text()获取响应的文本内容,需要await。
如果要获取二进制内容,用response.read();如果要获取JSON,用response.json()。
3.4 带参数的请求
URL参数
async def fetch_with_params():
params = {"key1": "value1", "key2": "value2"}
async with aiohttp.ClientSession() as session:
async with session.get("https://httpbin.org/get", params=params) as resp:
print(await resp.text())
POST请求
async def post_data():
data = {"username": "test", "password": "123456"}
async with aiohttp.ClientSession() as session:
async with session.post("https://httpbin.org/post", data=data) as resp:
print(await resp.json())
如果要发送JSON数据,用json参数:
async def post_json():
data = {"username": "test", "password": "123456"}
async with aiohttp.ClientSession() as session:
async with session.post("https://httpbin.org/post", json=data) as resp:
print(await resp.json())
3.5 设置请求头
很多网站会检查User-Agent,不设置的话可能会被反爬。
async def fetch_with_headers():
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8",
"Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8"
}
async with aiohttp.ClientSession(headers=headers) as session:
async with session.get("https://httpbin.org/headers") as resp:
print(await resp.text())
headers可以在创建Session的时候设置(全局生效),也可以在每次请求的时候设置(只对本次请求生效)。
3.6 超时设置
网络请求很容易超时,一定要设置超时时间,不然程序可能会卡很久。
async def fetch_with_timeout():
timeout = aiohttp.ClientTimeout(total=10) # 总超时10秒
async with aiohttp.ClientSession(timeout=timeout) as session:
try:
async with session.get("https://www.example.com") as resp:
html = await resp.text()
print(f"成功,长度: {len(html)}")
except asyncio.TimeoutError:
print("请求超时了!")
ClientTimeout可以设置多种超时:
-
total:总超时时间 -
connect:连接超时 -
sock_read:读取超时 -
sock_connect:socket连接超时
一般设置total就够了。
3.7 异常处理
网络请求可能会出各种问题:网络错误、超时、404、500等等。一定要做好异常处理。
async def safe_fetch(url):
try:
async with aiohttp.ClientSession() as session:
async with session.get(url) as resp:
if resp.status == 200:
return await resp.text()
else:
print(f"HTTP错误: {resp.status}")
return None
except aiohttp.ClientError as e:
print(f"请求出错: {e}")
return None
except asyncio.TimeoutError:
print("请求超时")
return None
常见的异常类型:
-
aiohttp.ClientError:所有客户端错误的基类 -
aiohttp.ClientConnectionError:连接错误 -
aiohttp.ClientResponseError:响应错误 -
asyncio.TimeoutError:超时
3.8 Cookie和会话保持
ClientSession会自动管理cookie,所以同一个Session的请求会自动保持会话,就像requests的Session一样。
async def login_and_fetch():
async with aiohttp.ClientSession() as session:
# 登录
login_data = {"username": "test", "password": "123456"}
async with session.post("https://example.com/login", data=login_data) as resp:
print(f"登录状态: {resp.status}")
# 登录后访问需要登录的页面
async with session.get("https://example.com/user/profile") as resp:
print(await resp.text())
两次请求用同一个Session,cookie会自动传递,所以第二次请求就是登录状态了。
3.9 代理支持
如果需要用代理IP,aiohttp也支持:
async def fetch_with_proxy():
proxy = "http://127.0.0.1:7890" # 代理地址
async with aiohttp.ClientSession() as session:
async with session.get("https://httpbin.org/ip", proxy=proxy) as resp:
print(await resp.text())
如果代理需要认证:
proxy_auth = aiohttp.BasicAuth("username", "password")
async with session.get(url, proxy=proxy, proxy_auth=proxy_auth) as resp:
...
3.10 aiohttp vs requests 对比
最后,我们来对比一下aiohttp和requests的常用功能,方便你快速上手:
| 功能 | requests | aiohttp |
|---|---|---|
| GET请求 | requests.get(url) |
session.get(url) (需要await) |
| POST请求 | requests.post(url, data=data) |
session.post(url, data=data) |
| URL参数 | params=params |
params=params |
| 请求头 | headers=headers |
headers=headers |
| 超时 | timeout=10 |
timeout=aiohttp.ClientTimeout(total=10) |
| 响应文本 | response.text |
await response.text() |
| 响应JSON | response.json() |
await response.json() |
| 响应状态码 | response.status_code |
response.status |
| 会话 | requests.Session() |
aiohttp.ClientSession() |
| 代理 | proxies=proxies |
proxy=proxy |
可以看到,aiohttp的API设计和requests非常像,如果你熟悉requests,上手aiohttp会很快。最大的区别就是,几乎所有操作都需要await。
第四章:从零手写一个异步爬虫
好了,基础概念讲得差不多了。现在,我们来真正手写一个异步爬虫。
我们的目标是:爬取豆瓣电影TOP250的所有电影信息。
4.1 需求分析
首先,我们来分析一下需求:
目标网站:豆瓣电影TOP250
-
URL: https://movie.douban.com/top250
-
共10页,每页25部电影
需要爬取的字段:
-
电影排名
-
电影名称
-
导演和主演
-
上映年份
-
国家/地区
-
类型
-
评分
-
评价人数
-
一句话简介
技术要求:
-
使用asyncio + aiohttp
-
并发控制(最多同时5个请求,礼貌爬取)
-
失败重试(最多重试3次)
-
异常处理
-
数据保存为CSV
4.2 网站分析
在写代码之前,我们先分析一下目标网站的结构。
豆瓣电影TOP250的URL格式是:
-
第1页:https://movie.douban.com/top250?start=0
-
第2页:https://movie.douban.com/top250?start=25
-
第3页:https://movie.douban.com/top250?start=50
-
…
-
第10页:https://movie.douban.com/top250?start=225
每页25部,start参数从0开始,每次加25。
然后我们看一下页面结构,用Chrome开发者工具看一下HTML。每部电影都在一个<div class="item">里面,里面包含了我们需要的所有信息。
解析HTML我们用BeautifulSoup,它和异步不冲突,因为解析是CPU操作,不涉及I/O。
4.3 基础版本:最简单的异步爬虫
我们先从最简单的版本开始,能跑通就行。
import asyncio
import aiohttp
from bs4 import BeautifulSoup
import csv
async def fetch_page(session, url):
"""下载页面"""
async with session.get(url) as response:
return await response.text()
def parse_html(html):
"""解析HTML,提取电影信息"""
soup = BeautifulSoup(html, "html.parser")
movies = []
items = soup.find_all("div", class_="item")
for item in items:
# 排名
rank = item.find("em").text
# 电影名
title = item.find("span", class_="title").text
# 评分
rating = item.find("span", class_="rating_num").text
# 评价人数
rating_num = item.find("div", class_="star").find_all("span")[-1].text
rating_num = rating_num.replace("人评价", "")
# 一句话简介
quote = item.find("span", class_="inq")
quote = quote.text if quote else ""
# 其他信息(导演、年份等)
info = item.find("div", class_="bd").find("p").text.strip()
movies.append({
"排名": rank,
"电影名": title,
"评分": rating,
"评价人数": rating_num,
"简介": quote,
"其他信息": info
})
return movies
async def main():
base_url = "https://movie.douban.com/top250?start={}"
urls = [base_url.format(i * 25) for i in range(10)]
# 创建Session
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"
}
async with aiohttp.ClientSession(headers=headers) as session:
# 创建任务
tasks = []
for url in urls:
task = asyncio.create_task(fetch_page(session, url))
tasks.append(task)
# 等待所有任务完成
pages = await asyncio.gather(*tasks)
# 解析所有页面
all_movies = []
for html in pages:
movies = parse_html(html)
all_movies.extend(movies)
# 按排名排序
all_movies.sort(key=lambda x: int(x["排名"]))
# 保存到CSV
with open("douban_top250.csv", "w", newline="", encoding="utf-8-sig") as f:
writer = csv.DictWriter(f, fieldnames=["排名", "电影名", "评分", "评价人数", "简介", "其他信息"])
writer.writeheader()
writer.writerows(all_movies)
print(f"成功爬取 {len(all_movies)} 部电影,已保存到 douban_top250.csv")
if __name__ == "__main__":
asyncio.run(main())
这就是一个最基础的异步爬虫了。我们来看看它的结构:
-
fetch_page:异步下载页面 -
parse_html:同步解析HTML(解析是CPU操作,不需要异步) -
main:主函数,创建Session,生成所有URL,创建任务,等待完成,解析,保存
这个版本已经能工作了,但还不够完善。比如:
-
没有并发控制,同时发10个请求(虽然不多,但如果是1000个呢?)
-
没有重试机制,网络波动导致失败就没了
-
异常处理不够完善
接下来我们一步步优化。
4.4 优化一:并发控制
首先,我们加上并发控制。用asyncio.Semaphore。
async def fetch_page(session, sem, url):
"""下载页面(带并发控制)"""
async with sem:
async with session.get(url) as response:
return await response.text()
async def main():
# ...
sem = asyncio.Semaphore(5) # 最多5个并发
tasks = []
for url in urls:
task = asyncio.create_task(fetch_page(session, sem, url))
tasks.append(task)
# ...
很简单,就是在fetch_page外面套一层async with sem。这样,同时最多只有5个请求在跑,其他的会等待。
为什么要控制并发?一方面是礼貌,不要给对方服务器太大压力;另一方面,很多网站有反爬,并发太高会被封IP。
4.5 优化二:重试机制
网络请求经常会失败,可能是网络波动,可能是服务器临时出错。这时候我们需要重试机制。
我们来写一个重试装饰器:
import functools
def retry(max_retries=3, delay=1):
"""重试装饰器"""
def decorator(func):
@functools.wraps(func)
async def wrapper(*args, **kwargs):
for i in range(max_retries):
try:
return await func(*args, **kwargs)
except Exception as e:
if i == max_retries - 1:
# 最后一次重试失败,抛出异常
raise
print(f"请求失败,第{i+1}次重试: {e}")
await asyncio.sleep(delay * (i + 1)) # 指数退避
return None
return wrapper
return decorator
这个装饰器的逻辑是:
-
最多重试
max_retries次 -
每次失败后等待一段时间,等待时间逐渐变长(指数退避)
-
最后一次还是失败,就抛出异常
然后我们把它用在fetch_page上:
@retry(max_retries=3, delay=1)
async def fetch_page(session, sem, url):
async with sem:
async with session.get(url) as response:
if response.status != 200:
raise Exception(f"HTTP错误: {response.status}")
return await response.text()
这样,如果请求失败了,会自动重试,最多3次。
4.6 优化三:完善异常处理
加上重试之后,还是有可能最终失败。我们需要在主函数里处理这种情况,不能因为一个页面失败,整个程序就崩了。
我们可以用return_exceptions=True参数,让gather把异常当作结果返回,而不是直接抛出:
async def main():
# ...
pages = await asyncio.gather(*tasks, return_exceptions=True)
all_movies = []
for url, page in zip(urls, pages):
if isinstance(page, Exception):
print(f"爬取失败: {url}, 错误: {page}")
continue
movies = parse_html(page)
all_movies.extend(movies)
# ...
这样,即使某个页面爬取失败了,其他页面还是能正常处理,不会影响整体。
4.7 优化四:限速
除了控制并发数,我们还可以在每个请求之间加一点延迟,更礼貌一些。
不过因为有Semaphore控制并发,而且豆瓣的反爬不算特别严,5个并发其实已经很温和了。但如果你要爬更敏感的网站,可以适当加延迟。
@retry(max_retries=3, delay=1)
async def fetch_page(session, sem, url):
async with sem:
await asyncio.sleep(0.5) # 每个请求前等0.5秒
async with session.get(url) as response:
if response.status != 200:
raise Exception(f"HTTP错误: {response.status}")
return await response.text()
4.8 完整的优化版本
把上面的优化都加进去,完整的代码是这样的:
import asyncio
import aiohttp
from bs4 import BeautifulSoup
import csv
import functools
def retry(max_retries=3, delay=1):
"""重试装饰器"""
def decorator(func):
@functools.wraps(func)
async def wrapper(*args, **kwargs):
for i in range(max_retries):
try:
return await func(*args, **kwargs)
except Exception as e:
if i == max_retries - 1:
raise
print(f"请求失败,第{i+1}次重试: {e}")
await asyncio.sleep(delay * (i + 1))
return None
return wrapper
return decorator
@retry(max_retries=3, delay=1)
async def fetch_page(session, sem, url):
"""下载页面(带并发控制和重试)"""
async with sem:
async with session.get(url) as response:
if response.status != 200:
raise Exception(f"HTTP错误: {response.status}")
return await response.text()
def parse_html(html):
"""解析HTML,提取电影信息"""
soup = BeautifulSoup(html, "html.parser")
movies = []
items = soup.find_all("div", class_="item")
for item in items:
rank = item.find("em").text
title = item.find("span", class_="title").text
rating = item.find("span", class_="rating_num").text
rating_num = item.find("div", class_="star").find_all("span")[-1].text
rating_num = rating_num.replace("人评价", "")
quote = item.find("span", class_="inq")
quote = quote.text if quote else ""
info = item.find("div", class_="bd").find("p").text.strip()
movies.append({
"排名": rank,
"电影名": title,
"评分": rating,
"评价人数": rating_num,
"简介": quote,
"其他信息": info
})
return movies
async def main():
base_url = "https://movie.douban.com/top250?start={}"
urls = [base_url.format(i * 25) for i in range(10)]
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"
}
timeout = aiohttp.ClientTimeout(total=10)
sem = asyncio.Semaphore(5) # 最多5个并发
async with aiohttp.ClientSession(headers=headers, timeout=timeout) as session:
tasks = []
for url in urls:
task = asyncio.create_task(fetch_page(session, sem, url))
tasks.append(task)
pages = await asyncio.gather(*tasks, return_exceptions=True)
all_movies = []
failed = 0
for url, page in zip(urls, pages):
if isinstance(page, Exception):
print(f"爬取失败: {url}, 错误: {page}")
failed += 1
continue
movies = parse_html(page)
all_movies.extend(movies)
all_movies.sort(key=lambda x: int(x["排名"]))
with open("douban_top250.csv", "w", newline="", encoding="utf-8-sig") as f:
writer = csv.DictWriter(f, fieldnames=["排名", "电影名", "评分", "评价人数", "简介", "其他信息"])
writer.writeheader()
writer.writerows(all_movies)
print(f"\n爬取完成!")
print(f"成功: {len(all_movies)} 部")
print(f"失败: {failed} 页")
print(f"已保存到 douban_top250.csv")
if __name__ == "__main__":
import time
start = time.time()
asyncio.run(main())
end = time.time()
print(f"总耗时: {end - start:.2f}秒")
这个版本就比较完善了,具备了工业级爬虫的基本要素:
-
异步并发下载
-
并发数控制
-
失败自动重试(指数退避)
-
超时设置
-
异常处理
-
数据解析和存储
4.9 性能对比:同步vs异步
最后,我们来对比一下同步和异步的性能。
假设每页下载需要0.5秒,10页:
-
同步:0.5 × 10 = 5秒
-
异步(5并发):约1秒(10页,5个并发,大概两轮)
实际测试的话,异步版本大概是同步的3-5倍速度,具体取决于网络情况和网站响应速度。
如果URL更多,比如100个、1000个,差距会更大。
第五章:异步爬虫进阶——工业级爬虫的必备功能
上面的版本已经能用了,但如果要应对更复杂的爬虫需求,还需要更多的功能。
这一章,我们来讲一些工业级爬虫的进阶技巧。
5.1 生产者-消费者模式
前面的例子中,我们是先把所有URL都生成好,然后一次性提交给事件循环。这种方式适合URL数量不多的情况。
但如果URL特别多,或者URL是动态生成的(比如从页面里提取新的URL),这种方式就不太合适了。
更好的方式是用生产者-消费者模式:
-
生产者:负责生成URL,放到队列里
-
消费者:从队列里取URL,下载、解析,可能还会产生新的URL
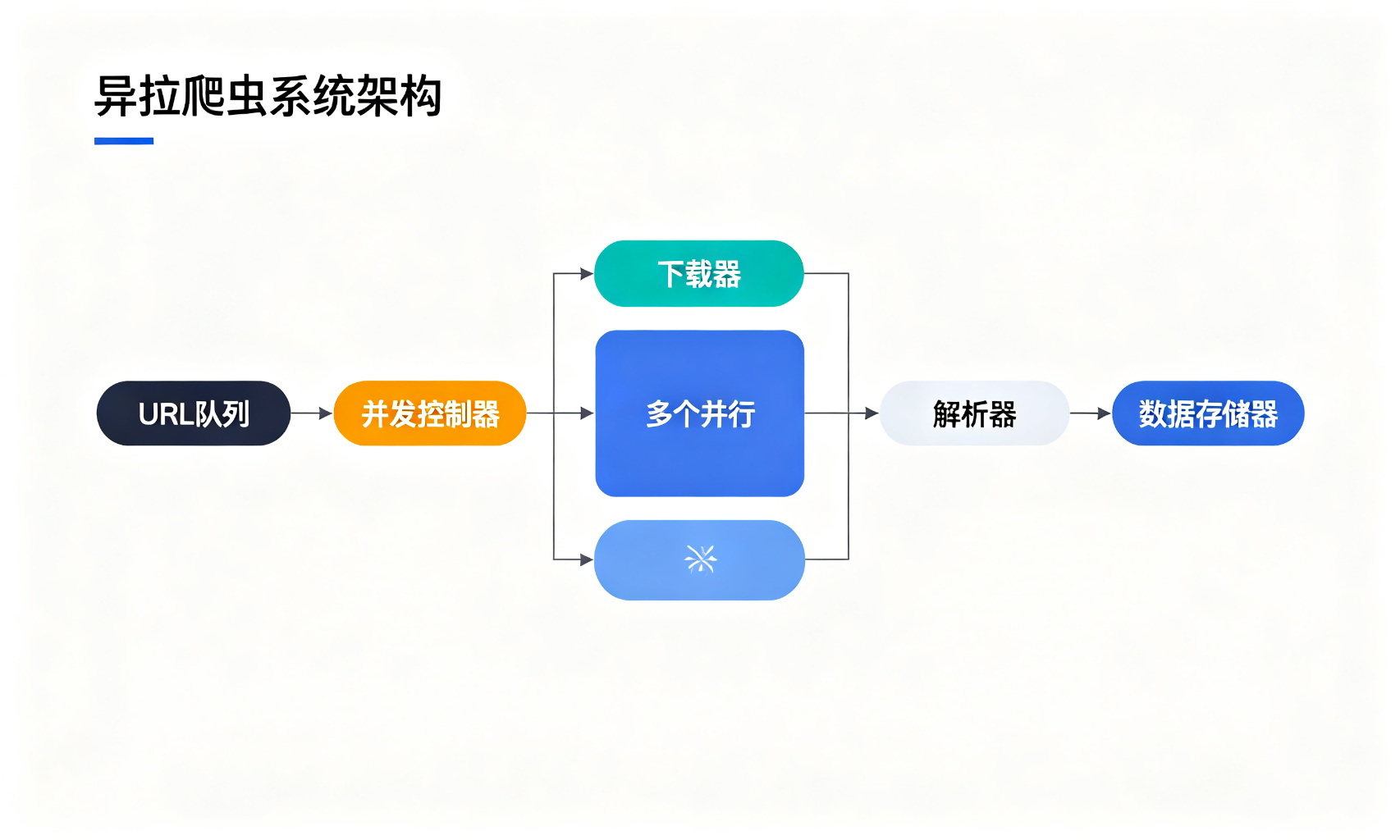
我们用asyncio.Queue来实现:
import asyncio
import aiohttp
from bs4 import BeautifulSoup
async def producer(queue):
"""生产者:生成URL"""
base_url = "https://movie.douban.com/top250?start={}"
for i in range(10):
url = base_url.format(i * 25)
await queue.put(url)
print(f"生产者添加URL: {url}")
async def consumer(queue, session, sem, results):
"""消费者:下载并解析"""
while True:
url = await queue.get() # 从队列取URL
try:
# 下载
async with sem:
async with session.get(url) as resp:
html = await resp.text()
# 解析
movies = parse_html(html)
results.extend(movies)
print(f"消费者处理完成: {url}, 获得{len(movies)}部电影")
except Exception as e:
print(f"处理失败: {url}, 错误: {e}")
finally:
queue.task_done() # 标记任务完成
async def main():
queue = asyncio.Queue(maxsize=20)
sem = asyncio.Semaphore(5)
results = []
headers = {"User-Agent": "..."}
async with aiohttp.ClientSession(headers=headers) as session:
# 启动生产者
producer_task = asyncio.create_task(producer(queue))
# 启动3个消费者
consumer_tasks = []
for _ in range(3):
task = asyncio.create_task(consumer(queue, session, sem, results))
consumer_tasks.append(task)
# 等待生产者完成
await producer_task
# 等待队列中所有任务都被处理完
await queue.join()
# 取消消费者(因为它们是无限循环)
for task in consumer_tasks:
task.cancel()
# 等待消费者退出
await asyncio.gather(*consumer_tasks, return_exceptions=True)
print(f"总共爬取了 {len(results)} 部电影")
生产者-消费者模式的好处:
-
URL可以动态生成,不需要一开始就全部生成好
-
可以控制队列大小,避免内存占用过大
-
消费者数量可以灵活调整
-
适合深度爬虫(从页面里发现新URL继续爬)
5.2 URL去重
在爬虫中,URL去重是非常重要的。不然同一个URL可能会被爬很多次,浪费资源,还可能陷入死循环。
最简单的去重方式是用一个集合(set):
seen_urls = set()
async def add_url(queue, url):
if url not in seen_urls:
seen_urls.add(url)
await queue.put(url)
但如果URL特别多(比如几百万个),set会占用大量内存。这时候可以用布隆过滤器(Bloom Filter),用少量内存换一定的误判率(只会误判重复,不会漏判)。
Python里有pybloom_live库可以用:
pip install pybloom_live
from pybloom_live import ScalableBloomFilter
seen_urls = ScalableBloomFilter(
initial_capacity=100000,
error_rate=0.001 # 0.1%的误判率
)
def is_duplicate(url):
if url in seen_urls:
return True
seen_urls.add(url)
return False
布隆过滤器的特点是:
-
占用内存极小(百万级URL只需要几MB)
-
有一定的误判率(可能把不重复的URL判断成重复的)
-
不会漏判(重复的URL一定会被识别出来)
对于爬虫来说,误判几个URL没关系,总比内存爆了好。
5.3 User-Agent轮换
很多网站会检查User-Agent,如果发现是爬虫的UA,就会封。所以我们需要准备多个UA,轮换使用。
import random
USER_AGENTS = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:89.0) Gecko/20100101 Firefox/89.0",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.1.1 Safari/605.1.15",
# ... 可以加更多
]
def get_random_headers():
return {
"User-Agent": random.choice(USER_AGENTS),
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8",
}
然后每次请求随机选一个UA。
不过aiohttp的Session是共享headers的。如果要每次请求用不同的UA,可以在请求的时候传headers参数:
async with session.get(url, headers=get_random_headers()) as resp:
...
5.4 代理IP池
如果爬取量比较大,单IP很容易被封。这时候就需要用代理IP了。
代理IP的来源:
-
免费代理:质量差,不稳定,适合学习用
-
付费代理:质量好,稳定,适合生产环境
代理池的实现思路:
-
维护一个代理IP列表
-
每次请求随机选一个代理
-
定期检测代理的可用性,剔除不可用的
-
不断补充新的代理
简单的代理池实现:
import random
PROXIES = [
"http://proxy1.example.com:8080",
"http://proxy2.example.com:8080",
"http://proxy3.example.com:8080",
# ...
]
def get_random_proxy():
return random.choice(PROXIES)
使用的时候:
proxy = get_random_proxy()
async with session.get(url, proxy=proxy) as resp:
...
当然,生产环境的代理池要复杂得多,需要考虑可用性检测、自动剔除、质量评分等。不过基本思路是这样的。
5.5 异步数据存储
爬下来的数据需要存起来。如果数据量不大,直接同步写文件或者数据库就行。
但如果数据量很大,同步写入可能会成为瓶颈。这时候可以用异步的数据库驱动。
比如,MySQL可以用aiomysql或者asyncmy,MongoDB可以用motor,Redis可以用aioredis。
以MongoDB为例:
import motor.motor_asyncio
async def save_to_mongo(movies):
client = motor.motor_asyncio.AsyncIOMotorClient("mongodb://localhost:27017")
db = client["movies"]
collection = db["top250"]
if movies:
await collection.insert_many(movies)
这样,数据库写入也是异步的,不会阻塞事件循环。
不过对于初学者来说,数据量不大的话,同步写入就够了,不用太纠结异步存储。
5.6 断点续爬
如果爬虫要跑很久(比如爬几天几夜),中途可能会因为各种原因中断。如果每次都从头开始爬,那就太浪费时间了。
所以,工业级爬虫一般都有断点续爬的功能。
实现思路:
-
把已经爬过的URL持久化(存到文件或者数据库)
-
爬虫启动的时候,先加载已经爬过的URL
-
只爬取没爬过的URL
-
每爬完一个URL,就把它标记为已爬取
简单的实现:
import json
# 加载已爬取的URL
try:
with open("crawled_urls.json", "r") as f:
crawled_urls = set(json.load(f))
except FileNotFoundError:
crawled_urls = set()
def save_crawled_urls():
with open("crawled_urls.json", "w") as f:
json.dump(list(crawled_urls), f)
# 爬取的时候
async def crawl(url):
if url in crawled_urls:
return
# ... 爬取逻辑 ...
crawled_urls.add(url)
save_crawled_urls() # 保存进度
这样,即使中途中断了,下次启动也能从上次的进度继续。
5.7 日志和监控
爬虫跑起来之后,你需要知道它跑得怎么样:爬了多少了?成功率多少?有没有出错?
所以,日志和监控很重要。
最简单的就是用print输出,但print太简单了,不够专业。推荐用Python的logging模块:
import logging
logging.basicConfig(
level=logging.INFO,
format="%(asctime)s - %(levelname)s - %(message)s"
)
logger = logging.getLogger(__name__)
# 使用
logger.info("开始爬取: %s", url)
logger.error("爬取失败: %s, 错误: %s", url, e)
如果是生产环境的爬虫,还可以加上监控告警,比如:
-
爬取速度低于阈值告警
-
失败率过高告警
-
程序异常退出告警
这些可以用Prometheus、Grafana,或者简单的钉钉/企业微信机器人来实现。
第六章:实战案例——完整的豆瓣电影TOP250爬虫
讲了这么多理论,我们来做一个完整的实战案例。
这一章,我们把前面讲的所有知识点整合起来,写一个功能完善的豆瓣电影TOP250异步爬虫。
6.1 功能清单
我们的爬虫将具备以下功能:
-
✅ 异步并发下载
-
✅ 并发数控制(可配置)
-
✅ 失败自动重试(指数退避)
-
✅ 超时设置
-
✅ User-Agent轮换
-
✅ 异常处理
-
✅ 数据解析(BeautifulSoup)
-
✅ 数据保存(CSV + JSON)
-
✅ 进度显示
-
✅ 性能统计
6.2 完整代码
import asyncio
import aiohttp
from bs4 import BeautifulSoup
import csv
import json
import time
import random
import functools
import logging
# ========== 配置 ==========
CONCURRENCY = 5 # 并发数
MAX_RETRIES = 3 # 最大重试次数
RETRY_DELAY = 1 # 重试基础延迟(秒)
TIMEOUT = 10 # 请求超时(秒)
# ========== 日志配置 ==========
logging.basicConfig(
level=logging.INFO,
format="%(asctime)s - %(levelname)s - %(message)s",
datefmt="%Y-%m-%d %H:%M:%S"
)
logger = logging.getLogger(__name__)
# ========== User-Agent池 ==========
USER_AGENTS = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:121.0) Gecko/20100101 Firefox/121.0",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/17.2 Safari/605.1.15",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36",
]
def get_random_headers():
"""获取随机请求头"""
return {
"User-Agent": random.choice(USER_AGENTS),
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8",
"Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8",
"Accept-Encoding": "gzip, deflate, br",
"Connection": "keep-alive",
}
# ========== 重试装饰器 ==========
def retry(max_retries=3, delay=1):
"""异步重试装饰器,支持指数退避"""
def decorator(func):
@functools.wraps(func)
async def wrapper(*args, **kwargs):
last_exception = None
for i in range(max_retries):
try:
return await func(*args, **kwargs)
except Exception as e:
last_exception = e
if i < max_retries - 1:
wait_time = delay * (2 ** i) # 指数退避:1, 2, 4秒
logger.warning(f"请求失败,{wait_time}秒后第{i+1}次重试: {e}")
await asyncio.sleep(wait_time)
raise last_exception
return wrapper
return decorator
# ========== 页面下载 ==========
@retry(max_retries=MAX_RETRIES, delay=RETRY_DELAY)
async def fetch_page(session, sem, url):
"""
下载页面
:param session: aiohttp会话
:param sem: 信号量,控制并发
:param url: 目标URL
:return: 页面HTML
"""
async with sem:
headers = get_random_headers()
async with session.get(url, headers=headers) as response:
if response.status != 200:
raise Exception(f"HTTP状态码错误: {response.status}")
return await response.text()
# ========== 页面解析 ==========
def parse_movie_item(item):
"""解析单个电影条目"""
try:
# 排名
rank = item.find("em").text.strip()
# 电影名(取第一个中文名)
title_tag = item.find("span", class_="title")
title = title_tag.text.strip() if title_tag else ""
# 评分
rating_tag = item.find("span", class_="rating_num")
rating = rating_tag.text.strip() if rating_tag else ""
# 评价人数
star_tags = item.find("div", class_="star").find_all("span")
rating_num = star_tags[-1].text.strip() if star_tags else ""
rating_num = rating_num.replace("人评价", "")
# 一句话简介
quote_tag = item.find("span", class_="inq")
quote = quote_tag.text.strip() if quote_tag else ""
# 详细信息(导演、主演、年份、国家、类型)
info_tag = item.find("div", class_="bd").find("p")
info_text = info_tag.get_text("\n", strip=True) if info_tag else ""
# 解析导演和主演
director = ""
actors = ""
year = ""
country = ""
genre = ""
lines = info_text.split("\n")
if lines:
first_line = lines[0]
if "导演:" in first_line:
parts = first_line.split("导演:")
if len(parts) > 1:
rest = parts[1]
if "主演:" in rest:
director_part, actors_part = rest.split("主演:", 1)
director = director_part.strip()
actors = actors_part.strip()
else:
director = rest.strip()
if len(lines) > 1:
second_line = lines[1]
parts = second_line.split(" / ")
if len(parts) >= 1:
year = parts[0].strip()
if len(parts) >= 2:
country = parts[1].strip()
if len(parts) >= 3:
genre = parts[2].strip()
return {
"排名": rank,
"电影名": title,
"导演": director,
"主演": actors,
"上映年份": year,
"国家/地区": country,
"类型": genre,
"评分": rating,
"评价人数": rating_num,
"一句话简介": quote,
}
except Exception as e:
logger.error(f"解析电影条目失败: {e}")
return None
def parse_html(html):
"""解析HTML页面,提取所有电影信息"""
soup = BeautifulSoup(html, "html.parser")
items = soup.find_all("div", class_="item")
movies = []
for item in items:
movie = parse_movie_item(item)
if movie:
movies.append(movie)
return movies
# ========== 数据保存 ==========
def save_to_csv(movies, filename="douban_top250.csv"):
"""保存到CSV文件"""
fieldnames = ["排名", "电影名", "导演", "主演", "上映年份", "国家/地区", "类型", "评分", "评价人数", "一句话简介"]
with open(filename, "w", newline="", encoding="utf-8-sig") as f:
writer = csv.DictWriter(f, fieldnames=fieldnames)
writer.writeheader()
writer.writerows(movies)
logger.info(f"数据已保存到 {filename}")
def save_to_json(movies, filename="douban_top250.json"):
"""保存到JSON文件"""
with open(filename, "w", encoding="utf-8") as f:
json.dump(movies, f, ensure_ascii=False, indent=2)
logger.info(f"数据已保存到 {filename}")
# ========== 主函数 ==========
async def main():
logger.info("=" * 50)
logger.info("豆瓣电影TOP250异步爬虫启动")
logger.info(f"并发数: {CONCURRENCY}, 最大重试次数: {MAX_RETRIES}")
logger.info("=" * 50)
start_time = time.time()
# 生成所有URL
base_url = "https://movie.douban.com/top250?start={}"
urls = [base_url.format(i * 25) for i in range(10)]
logger.info(f"共 {len(urls)} 个页面待爬取")
# 创建会话和信号量
timeout = aiohttp.ClientTimeout(total=TIMEOUT)
sem = asyncio.Semaphore(CONCURRENCY)
async with aiohttp.ClientSession(timeout=timeout) as session:
# 创建所有任务
tasks = []
for i, url in enumerate(urls, 1):
task = asyncio.create_task(fetch_page(session, sem, url))
tasks.append(task)
logger.info(f"添加任务 {i}/{len(urls)}: {url}")
# 等待所有任务完成
logger.info("开始爬取...")
results = await asyncio.gather(*tasks, return_exceptions=True)
# 处理结果
all_movies = []
success_count = 0
fail_count = 0
for url, result in zip(urls, results):
if isinstance(result, Exception):
logger.error(f"爬取失败: {url}, 错误: {result}")
fail_count += 1
else:
movies = parse_html(result)
all_movies.extend(movies)
success_count += 1
logger.info(f"爬取成功: {url}, 获得 {len(movies)} 部电影")
# 按排名排序
all_movies.sort(key=lambda x: int(x["排名"]))
# 保存数据
save_to_csv(all_movies)
save_to_json(all_movies)
# 统计信息
end_time = time.time()
total_time = end_time - start_time
logger.info("=" * 50)
logger.info("爬取完成!")
logger.info(f"成功页面: {success_count}/{len(urls)}")
logger.info(f"失败页面: {fail_count}/{len(urls)}")
logger.info(f"共爬取电影: {len(all_movies)} 部")
logger.info(f"总耗时: {total_time:.2f} 秒")
if success_count > 0:
logger.info(f"平均每页耗时: {total_time / success_count:.2f} 秒")
logger.info("=" * 50)
if __name__ == "__main__":
asyncio.run(main())
6.3 代码说明
这个爬虫虽然只有200多行代码,但功能已经很完善了。我们来梳理一下它的结构:
1. 配置区
-
所有可配置的参数都放在最上面,方便修改
-
包括并发数、重试次数、超时时间等
2. 日志配置
-
用logging模块替代print
-
输出带时间戳和日志级别,更专业
3. User-Agent池
-
准备了5个不同的UA
-
每次请求随机选一个,降低被封的概率
4. 重试装饰器
-
支持指数退避(1秒、2秒、4秒…)
-
最多重试3次
-
失败了会打warning日志
5. 页面下载
-
用Semaphore控制并发数
-
每次请求用随机的请求头
-
检查HTTP状态码,非200就抛异常
6. 页面解析
-
用BeautifulSoup解析
-
解析了排名、电影名、导演、主演、年份、国家、类型、评分、评价人数、简介等字段
-
解析过程有异常处理,不会因为一个电影解析失败就崩了
7. 数据保存
-
同时保存为CSV和JSON两种格式
-
CSV用utf-8-sig编码,Excel打开不会乱码
8. 主函数
-
生成所有URL
-
创建任务
-
并发执行
-
统计成功失败数量
-
排序
-
保存
-
输出性能统计
6.4 运行效果
运行这个爬虫,你会看到类似这样的输出:
2024-01-01 12:00:00 - INFO - ==================================================
2024-01-01 12:00:00 - INFO - 豆瓣电影TOP250异步爬虫启动
2024-01-01 12:00:00 - INFO - 并发数: 5, 最大重试次数: 3
2024-01-01 12:00:00 - INFO - ==================================================
2024-01-01 12:00:00 - INFO - 共 10 个页面待爬取
2024-01-01 12:00:00 - INFO - 添加任务 1/10: https://movie.douban.com/top250?start=0
...
2024-01-01 12:00:00 - INFO - 开始爬取...
2024-01-01 12:00:02 - INFO - 爬取成功: https://movie.douban.com/top250?start=0, 获得 25 部电影
...
2024-01-01 12:00:05 - INFO - 数据已保存到 douban_top250.csv
2024-01-01 12:00:05 - INFO - 数据已保存到 douban_top250.json
2024-01-01 12:00:05 - INFO - ==================================================
2024-01-01 12:00:05 - INFO - 爬取完成!
2024-01-01 12:00:05 - INFO - 成功页面: 10/10
2024-01-01 12:00:05 - INFO - 失败页面: 0/10
2024-01-01 12:00:05 - INFO - 共爬取电影: 250 部
2024-01-01 12:00:05 - INFO - 总耗时: 5.23 秒
2024-01-01 12:00:05 - INFO - 平均每页耗时: 0.52 秒
2024-01-01 12:00:05 - INFO - ==================================================
10个页面,5个并发,总共5秒左右,效率还是不错的。
如果用同步爬虫,大概需要10-15秒,异步快了2-3倍。如果页面更多,差距会更大。
第七章:异步爬虫的坑与避坑指南
异步爬虫虽然高效,但也有很多坑。新手很容易踩。
这一章,我来总结一下常见的坑和避坑方法。
7.1 坑一:在协程里调用阻塞函数
这是新手最最最容易犯的错误,没有之一。
很多人学了async/await,就觉得只要函数前面加个async,就是异步了。然后在里面照样用requests.get()、time.sleep()这些阻塞函数。
结果呢?程序不仅没快,反而可能更慢了。
为什么?因为阻塞函数会卡住整个事件循环。事件循环被卡住了,其他协程都没法运行,那还谈什么并发?
错误示例:
import asyncio
import requests
import time
async def bad_fetch(url):
# 错误!requests是阻塞的,会卡住整个事件循环
response = requests.get(url)
return response.text
async def bad_sleep():
# 错误!time.sleep是阻塞的
time.sleep(1)
正确做法:
-
网络请求用
aiohttp,不要用requests -
休眠用
asyncio.sleep(),不要用time.sleep() -
文件I/O用
aiofiles,不要用普通的open() -
数据库操作用异步驱动(如
aiomysql、motor),不要用同步驱动
如果实在要用阻塞函数怎么办?可以用asyncio.to_thread()把它放到线程里运行:
async def fetch_with_requests(url):
# 把阻塞的requests放到线程里跑
response = await asyncio.to_thread(requests.get, url)
return response.text
这样就不会阻塞事件循环了。但这只是权宜之计,能不用就不用,还是尽量用原生的异步库。
7.2 坑二:忘记await
第二个常见错误是忘记写await。
async def main():
# 错误:忘记await,协程不会执行
fetch_url(url)
# 正确
await fetch_url(url)
不写await的话,只是创建了一个协程对象,但不会执行它。而且Python还会给你一个警告:RuntimeWarning: coroutine 'xxx' was never awaited。
这个错误虽然低级,但真的很多人犯,特别是刚接触异步的时候。
7.3 坑三:每个请求都创建一个ClientSession
很多新手写aiohttp代码,会在每个请求里都创建一个新的ClientSession:
# 错误:每个请求都创建Session
async def fetch(url):
async with aiohttp.ClientSession() as session:
async with session.get(url) as resp:
return await resp.text()
这样写虽然能工作,但效率很低。因为ClientSession内部有连接池,复用Session可以复用TCP连接,减少握手开销。
正确做法:整个程序尽量共用一个Session,在主函数里创建,然后传给各个协程。
async def main():
async with aiohttp.ClientSession() as session:
# 所有请求都用这个session
tasks = [fetch(session, url) for url in urls]
await asyncio.gather(*tasks)
7.4 坑四:并发数开太大
有些人觉得异步就是要快,于是把并发数开得很大,比如1000、10000。
结果呢?要么把对方网站爬崩了,要么自己的程序崩了。
原因:
-
对目标服务器不友好:短时间大量请求,相当于DDoS攻击,很容易被封IP
-
连接数限制:操作系统对单个进程的文件描述符数量有限制,并发太高会报"Too many open files"错误
-
内存占用:每个连接都要占用内存,并发太高内存会爆
-
效率反而下降:并发太高,事件循环调度的开销也会变大,可能反而更慢
建议:
-
一般爬虫,并发数控制在10-50之间就差不多了
-
看目标网站的承受能力,小网站并发数要更低
-
慢慢往上加,找到一个平衡点
7.5 坑五:异常处理不完善
网络请求什么情况都可能发生:超时、连接错误、404、500、DNS解析失败…
如果异常处理不完善,很可能一个请求出错,整个程序就崩了。
建议:
-
每个请求都要有try-except
-
用
return_exceptions=True让gather不因为一个任务失败就全部终止 -
记录详细的错误日志,方便排查问题
-
加上重试机制,应对临时性的错误
7.6 坑六:不设置超时
网络请求一定要设置超时!
不然,如果某个请求一直没响应,你的程序就会一直卡在那里,永远等下去。
# 错误:没有超时
async with session.get(url) as resp:
...
# 正确:设置超时
timeout = aiohttp.ClientTimeout(total=10)
async with aiohttp.ClientSession(timeout=timeout) as session:
...
一般设置10-30秒的总超时就差不多了,具体看网站响应速度。
7.7 坑七:回调地狱
早期的异步编程都是用回调函数的,层层嵌套,形成"回调地狱",代码非常难读。
虽然Python的async/await已经很大程度上解决了这个问题,但如果你用不好,还是可能写出难读的代码。
建议:
-
尽量用async/await的写法,不要用回调
-
把复杂的逻辑拆分成小的协程函数
-
用
asyncio.gather()、asyncio.wait()等高层API,不要直接操作Future
7.8 坑八:CPU密集型任务用异步
异步只适合I/O密集型任务,不适合CPU密集型任务。
如果你的爬虫有大量的计算(比如复杂的图片处理、数据计算),那异步帮不了你,反而可能因为事件循环被卡住而更慢。
建议:
-
I/O密集型(网络请求、文件读写等):用异步
-
CPU密集型(大量计算):用多进程
-
两者都有:异步+多进程结合
7.9 坑九:调试困难
异步代码的调试比同步代码难,因为执行顺序不是线性的。出错的时候,堆栈信息可能不太好理解。
调试建议:
-
加详细的日志,记录每个步骤的开始和结束
-
先用少量URL测试,确认逻辑正确了再加大规模
-
用
asyncio.run()的debug=True模式,可以看到更多调试信息 -
可以用
aiomonitor等工具,实时监控事件循环的状态
7.10 坑十:忽略反爬
很多新手写爬虫,上来就咔咔咔猛爬,结果没爬几个就被封IP了。
异步爬虫速度快,更容易触发反爬机制。
反爬应对建议:
-
控制并发数,不要太快
-
加随机延迟,模拟人的操作速度
-
轮换User-Agent
-
使用代理IP
-
处理Cookie和Session
-
处理验证码(OCR或者打码平台)
-
遵守robots.txt,礼貌爬取
记住,爬虫是一把双刃剑,用好了能提高效率,用不好可能会惹上麻烦。一定要遵守法律法规,尊重网站的规则。
第八章:面试中关于异步爬虫的常见问题
回到我们开头的面试场景。面试官让你手写异步爬虫,其实不只是考你会不会写代码,更是考察你对异步编程、并发、网络编程的理解。
这一章,我整理了一些面试中常见的问题,以及回答思路。
8.1 什么是协程?和线程有什么区别?
回答思路:
协程是一种用户态的轻量级线程,也叫"微线程"。
和线程的区别:
-
调度方式不同:线程是抢占式调度,由操作系统控制;协程是协作式调度,由程序自己控制,只有主动让出(await)才会切换。
-
开销不同:线程的创建、切换开销比较大;协程非常轻量,切换开销极小。
-
并发数量不同:一个进程能开的线程数有限(几千个就很多了);协程可以开几万个甚至几十万个。
-
数据安全:多线程需要加锁,因为可能同时修改共享数据;协程是单线程的,在await之间不会被打断,所以共享数据的安全性更好。
-
适用场景:线程适合CPU密集型+I/O密集型;协程特别适合I/O密集型任务。
简单说,协程比线程更轻量、更高效,但只适合I/O密集型场景。
8.2 异步爬虫为什么比同步爬虫快?
回答思路:
异步爬虫快的核心原因是充分利用了I/O等待时间。
同步爬虫是串行的,发一个请求,等响应回来,再发下一个。大部分时间都在等网络响应,CPU闲着。
异步爬虫是并发的,发一个请求之后,不等响应回来,就可以发下一个请求。当某个请求的响应回来了,再去处理它。
这样,CPU就不会闲着,一直在工作,所以效率高。
举个例子:10个请求,每个响应需要1秒。
-
同步:10 × 1 = 10秒
-
异步:约1秒(几乎同时发,同时回来)
当然,实际情况不会这么理想,因为还有网络带宽、服务器处理能力等限制,但异步比同步快很多是肯定的。
8.3 异步爬虫和多线程爬虫哪个好?
回答思路:
这个问题没有绝对的答案,要看具体场景。
异步爬虫的优点:
-
效率更高,并发量更大
-
资源占用更少(单线程,没有线程切换开销)
-
没有线程安全问题,不需要加锁
-
代码相对简洁(async/await vs 线程+锁)
多线程爬虫的优点:
-
生态更丰富,很多库都是同步的(比如requests),可以直接用
-
可以利用多核CPU(虽然因为GIL,I/O密集型的时候差不多)
-
调试相对简单一些
-
对编程思维的要求低一些,更容易理解
总结:
-
如果追求高性能、高并发,用异步
-
如果项目比较简单,或者依赖很多同步库,用多线程也可以
-
对于爬虫这种典型的I/O密集型任务,异步是更好的选择
8.4 如何控制异步爬虫的并发数?
回答思路:
用asyncio.Semaphore(信号量)。
Semaphore就像一个"通行证",有固定的数量。每个协程要执行请求之前,先去获取通行证,如果通行证发完了,就等着。请求完成后,归还通行证,其他协程才能继续。
代码示例:
sem = asyncio.Semaphore(10) # 最多10个并发
async def fetch(url):
async with sem: # 获取通行证
async with session.get(url) as resp:
return await resp.text()
# 退出with块,自动归还通行证
为什么要控制并发数?
-
避免给目标服务器太大压力,礼貌爬取
-
避免被反爬封禁
-
避免自己的程序资源耗尽(文件描述符、内存等)
8.5 写爬虫的时候遇到过什么反爬?怎么应对的?
回答思路:
这是一个非常经典的面试题,考察你的实战经验。
可以从这几个方面回答:
1. User-Agent检测
-
现象:不设置UA或者用爬虫UA会被封
-
应对:准备UA池,随机轮换
2. IP封禁
-
现象:单个IP访问太频繁会被封
-
应对:用代理IP池,轮换IP;控制爬取速度
3. 验证码
-
现象:访问频繁了会出验证码
-
应对:降低速度;用OCR识别;用打码平台
4. Cookie/Session检测
-
现象:需要登录才能访问,或者Session有有效期
-
应对:模拟登录;维护Session;定期更新Cookie
5. 动态页面(JS渲染)
-
现象:内容是JS动态加载的,直接爬HTML看不到
-
应对:分析Ajax接口;用Selenium/Puppeteer等无头浏览器
6. 频率限制
-
现象:请求太快会返回429或者直接封
-
应对:加随机延迟;控制并发;用代理
回答的时候,最好结合自己的实际项目经历,说具体的例子,不要光说理论。
8.6 你写过的最复杂的爬虫是什么样的?
回答思路:
这个问题是考察你的项目经验和技术深度。
回答的时候,可以从这几个方面展开:
-
项目背景:爬什么网站?为什么要爬?数据用来做什么?
-
技术选型:为什么用异步?用了哪些库?
-
架构设计:生产者-消费者模式?分布式?断点续爬?
-
遇到的难点:反爬、数据量大、数据清洗等
-
解决方案:怎么解决这些难点的?
-
最终效果:爬了多少数据?效率怎么样?
如果你有真实的项目经验,就如实说。如果没有,也可以把我们今天讲的这个豆瓣爬虫包装一下,说清楚设计思路和技术细节。
重点是体现你的思考过程和解决问题的能力,而不是单纯罗列技术点。
8.7 异步爬虫怎么处理失败的请求?
回答思路:
-
重试机制:临时性的错误(网络波动、5xx错误)可以重试
-
最多重试N次(比如3次)
-
指数退避(每次重试等待时间翻倍)
-
只对特定错误重试,4xx错误一般不重试
-
-
异常捕获:每个请求都要有try-except,不要因为一个请求失败就崩了整个程序
-
失败记录:记录失败的URL和错误原因,方便后续排查和重爬
-
死信队列:重试多次还是失败的请求,放到死信队列,后面人工处理
代码示例就是我们前面写的重试装饰器,可以简单说一下实现思路。
8.8 什么是事件循环?它的工作原理是什么?
回答思路:
事件循环是异步编程的核心,是一个不断循环的调度器。
工作原理:
-
维护一个任务队列(或者说事件队列)
-
不断地从队列里取出任务执行
-
任务执行到await的时候,会暂停,把控制权交还给事件循环
-
事件循环继续执行下一个任务
-
当某个任务等待的I/O完成了(比如网络响应回来了),事件循环会把它重新放回就绪队列
-
如此循环,直到所有任务都完成
可以把它想象成一个高效的服务员,同时服务很多桌客人,哪桌需要服务就去哪桌,不会傻等。
在Python中,事件循环由asyncio模块提供,我们一般不需要自己实现,只要用asyncio.run()启动就行了。
8.9 asyncio.create_task() 和直接await有什么区别?
回答思路:
直接await一个协程,是串行执行的——等这个协程执行完了,才会继续往下走。
# 串行,总耗时2秒
await coro1()
await coro2()
而用asyncio.create_task()把协程包装成Task,是提交给事件循环并发执行——创建Task之后立即返回,不会等待。
# 并发,总耗时1秒
task1 = asyncio.create_task(coro1())
task2 = asyncio.create_task(coro2())
await task1
await task2
简单说:
-
await:等它完成,串行 -
create_task:提交任务,后台跑,并发
如果有多个独立的任务,用create_task或者asyncio.gather()让它们并发执行,效率更高。
8.10 你觉得异步爬虫的难点在哪里?
回答思路:
这个问题考察你对异步编程的理解深度。可以从这几个方面说:
-
编程思维的转变:从同步的线性思维,转到异步的并发思维,需要一个适应过程。新手很容易写出"同步式"的异步代码,白忙活。
-
调试困难:异步代码的执行顺序不是线性的,出错的时候堆栈信息比较复杂,调试起来比同步代码难。
-
生态不完善:很多常用的库都是同步的,不能直接在异步代码里用。需要找对应的异步版本,或者自己封装。
-
异常处理复杂:并发任务多了,异常处理也更复杂。哪个任务失败了?为什么失败?怎么重试?这些都需要考虑周全。
-
反爬应对:异步爬虫速度快,更容易触发反爬,需要更多的反反爬措施。
-
性能调优:并发数设多少合适?超时设多少?连接池多大?这些都需要根据实际情况调优,不是一蹴而就的。
回答的时候,可以结合自己的实际经历,说一些你踩过的坑,这样更真实可信。
总结:从入门到精通的学习路径
好了,讲到这里,这篇文章也接近尾声了。
不知道你看完之后,对异步爬虫有没有一个比较清晰的认识?
说实话,异步爬虫说难也难,说简单也简单。难的是思维方式的转变,简单的是一旦你理解了核心原理,写起来其实和同步爬虫差不了太多。
最后,我给大家总结一下异步爬虫的学习路径,希望对你有帮助。
第一步:打好Python基础
在学异步之前,先把Python基础打扎实:
-
函数、类、装饰器
-
生成器、迭代器
-
异常处理
-
文件操作
-
常用的标准库
这些都是基础,基础不牢,地动山摇。
第二步:学会同步爬虫
在学异步爬虫之前,先把同步爬虫搞明白:
-
HTTP协议基础
-
requests库的使用
-
HTML解析(BeautifulSoup、lxml)
-
正则表达式
-
数据存储(CSV、JSON、数据库)
-
基本的反爬应对
同步爬虫是异步爬虫的基础,同步的搞明白了,异步只是把请求部分换成异步的而已。
第三步:学习asyncio基础
然后开始学asyncio:
-
async/await语法
-
协程、Task、Future的概念
-
事件循环的原理
-
常用的API:gather、wait、Semaphore、Queue
-
异常处理
这部分是异步编程的核心,一定要理解透彻,不要只会抄代码。
第四步:学习aiohttp
接着学aiohttp:
-
ClientSession的使用
-
GET/POST请求
-
请求头、Cookie、代理
-
超时、异常处理
-
最佳实践(复用Session等)
aiohttp是异步爬虫的核心工具,必须熟练掌握。
第五步:实战项目
光看不练假把式。找几个网站,实际写几个爬虫:
-
从简单的静态页面开始
-
慢慢增加复杂度:登录、翻页、AJAX
-
加上各种优化:并发控制、重试、代理、UA轮换
-
尝试不同的架构:简单批量、生产者-消费者、分布式
实战是最好的老师,踩的坑多了,自然就熟练了。
第六步:深入进阶
如果想更深入,可以学习:
-
分布式爬虫(Scrapy-Redis等)
-
JavaScript渲染(Selenium、Playwright、Pyppeteer)
-
验证码识别
-
大规模数据存储和处理
-
爬虫监控和运维
这些都是进阶内容,可以根据自己的需求选择性学习。
写在最后
回到开头的面试故事。其实,面试官让我手写异步爬虫,考察的不只是我会不会写代码,更是考察我的学习能力、解决问题的能力,以及对技术的热情。
在这个技术飞速发展的时代,会什么技术其实没那么重要,重要的是学习能力。只要你愿意学,新技术很快就能上手。
希望这篇文章能帮你打开异步爬虫的大门。但这只是开始,真正的掌握还需要你自己去实践、去踩坑、去总结。
如果你觉得这篇文章对你有帮助,欢迎分享给更多的人。也欢迎你在评论区留言,说说你遇到过的爬虫坑,或者你想了解的爬虫技术。
最后,祝大家都能写出高效、稳定、礼貌的爬虫,也祝大家面试顺利,拿到心仪的offer!
更多推荐
 1
1 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)